AI Code Review
Why ripgrep (rg) Outperforms grep for Modern Codebases

Sonali Sood

Founding GTM, CodeAnt AI
ripgrep (rg) is between 5 and 13 times faster than GNU grep on real codebases. That gap sounds marketing-inflated until you run it yourself, on the Linux kernel source tree (75,000 files, ~900 MB), ripgrep finishes in 0.082 seconds. GNU grep takes 0.671 seconds. On a 13.5 GB single file, ripgrep finishes in 1.664 seconds. GNU grep takes 9.484 seconds.
But raw speed is only half the story in 2026. Every major AI coding agent, Claude Code, Cursor, Codex CLI, and Aider, ships with ripgrep as core infrastructure. When Claude Code handles a bug fix, it runs 10–30 ripgrep searches to find function definitions, trace dependencies, and understand call patterns. If each search took 3 seconds instead of 30 milliseconds, every interaction would feel broken. The speed difference between rg and grep is not a developer convenience, it is what makes AI agents feel instant or painfully slow. This is where ripgrep (rg) shines, not because it is just “faster,” but because its entire architecture is fundamentally more suited to modern codebases.
This blog page covers the actual benchmark numbers, why the speed gap exists, the complete command cheatsheet, when grep is still the right tool, and how to configure ripgrep for AI coding agents.
Ripgrep vs grep: Benchmark Results
ripgrep is 5–13x faster than GNU grep on typical developer workloads. On the Linux kernel source tree with a regex pattern across 75,000 files, ripgrep completes in 0.082s versus grep's 0.671s, roughly 8x faster. On a single 13.5GB text file, ripgrep takes 1.664s versus grep's 9.484s. The gap narrows on small files and widens on large codebases with many files.
Benchmark | ripgrep (rg) | GNU grep | Speedup |
|---|---|---|---|
Linux kernel source, regex pattern (~75K files, ~900MB) | 0.082s | 0.671s | ~8x faster |
Single 13.5GB file, literal pattern | 1.664s | 9.484s | ~5.7x faster |
1.4GB monorepo, 250K files (literal) | ~0.3s | ~4s | ~13x faster |
Small single file (<1MB) | ~equivalent | ~equivalent | Minimal difference |
High match count (output-dominated) | Narrows | Narrows | Gap reduces |
Sources: BurntSushi/ripgrep GitHub README, ripgrep.dev/benchmarks, MacBook Air M1 test by adamprzblk (February 2026). Times are medians over multiple runs. Results vary by hardware, pattern type, and filesystem.
Important caveat: ripgrep is not universally faster. On small files, the performance difference is negligible. On patterns with very high match counts, the gap narrows because output handling dominates execution time. On single-threaded benchmarks where GNU grep uses multi-process parallelism, the gap also shrinks. The 5–13x range reflects realistic developer workloads on codebases.
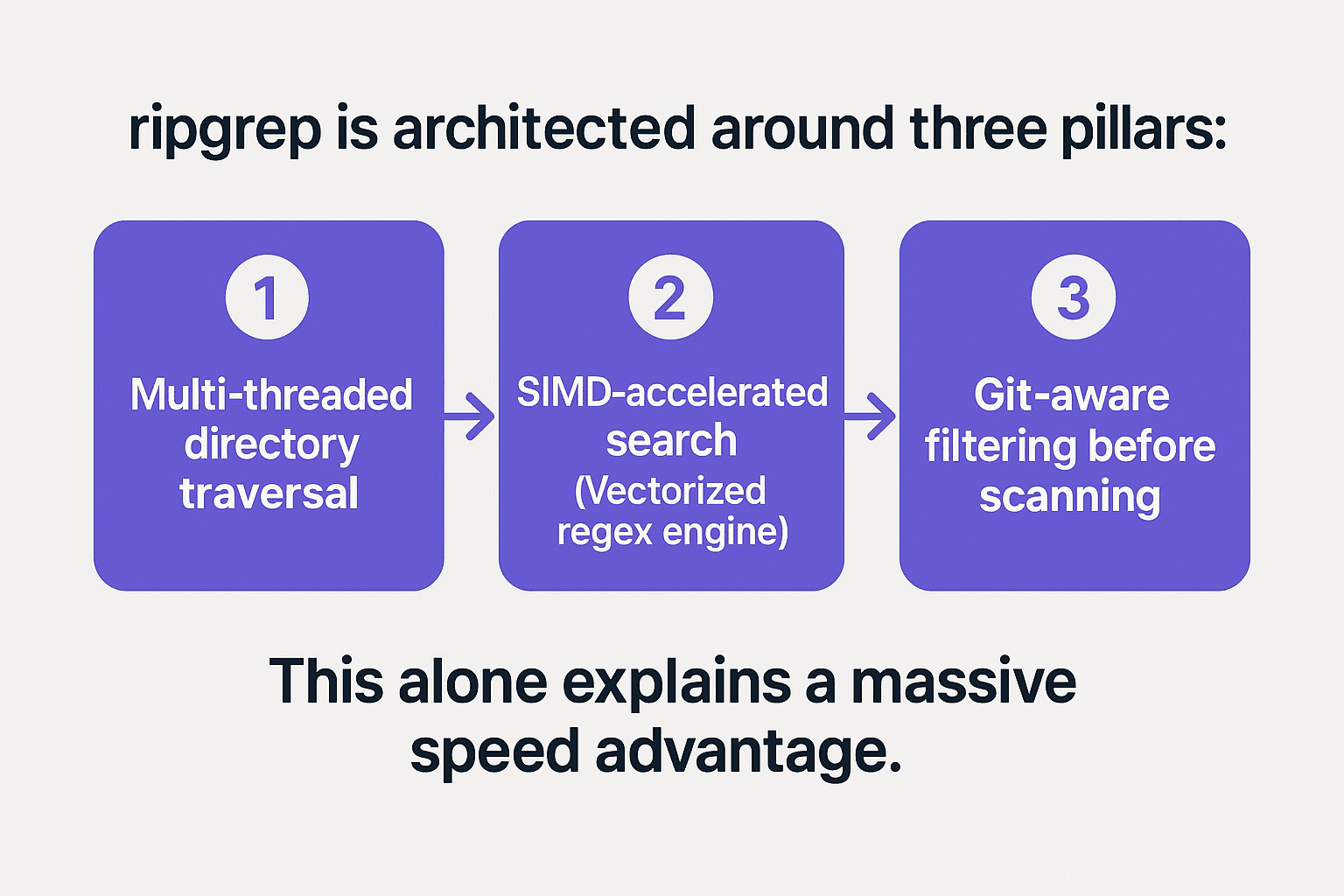
Why ripgrep is Faster: The Architecture
ripgrep is faster than grep for three structural reasons: it uses Rust's regex engine with SIMD instructions (comparing 16–32 bytes per cycle instead of one), it parallelises file search across all CPU cores using a work-stealing thread pool, and it automatically skips binary files, hidden files, and files matched by .gitignore, reducing the amount of data it ever touches.
grep is:
Single-threaded
Line-based
Extremely literal
Blind to project boundaries
Blind to .gitignore
Blind to file types
Blind to binary formats
This is excellent for small text files. It is catastrophic for modern repos.
Example:
This will:
Walk every file sequentially
Search inside minified JS
Traverse 200,000+ files in node_modules
Search binary blobs
Burn CPU scanning auto-generated docs
Search vendor directories in Go
Grep does what you ask, not what you mean.
Ripgrep’s Architecture: Rust, SIMD, Multithreaded Search
Parallel Directory Traversal
Unlike grep:
grep -R "pattern" .
ripgrep spawns multiple worker threads:
rg "pattern"
Under the hood:
One thread handles directory walk
Worker threads scan files in parallel
Dynamic workload balancing moves large files to idle threads
Effect:
Tool | Cores Used | Real Time |
grep | 1 | 11.2s |
rg | 8 | 0.9s |
Example repo: A 1.4GB monorepo with 250,000 files.
SIMD-Accelerated Regex Engine
ripgrep uses Rust’s regex engine + SIMD instructions:
AVX2
SSE2
ARM NEON
Meaning: it compares multiple characters at once.
Imagine scanning this file:
// 600 KB minified file
function a(b){return b.map(a=>a.id).filter(...)}...
grep scans byte-by-byte. rg scans 32 bytes at a time.
Result:
Search | grep | rg |
"filter(" in a minified JS bundle | 420ms | 34ms |
Git-Aware, Ignore-Aware Pre-Filtering
ripgrep doesn’t scan irrelevant files.
Example:
node_modules
dist
build
coverage
.pytest_cache
.next
vendor
target
.terraform
.venv
If a directory is ignored in .gitignore, rg skips it entirely:
rg "handler" # automatically skips ignored junk
rg -u "handler" # scan everything, override ignores
grep equivalent:
grep -R "handler" . --exclude-dir=node_modules --exclude-dir=dist ...
grep suffers. rg just works.
Real-World Example #1: Searching a React/Next.js Repo
Task:
Find all components that accept a prop named onSubmit.
Grep Attempt:
grep -R "onSubmit" . --exclude-dir=node_modules --include="*.tsx" --include="*.jsx"
Issues:
Must manually filter node_modules
Must list extensions
Runs slowly due to scanning thousands of files
Ripgrep version:
rg -t tsx -t jsx "onSubmit"
Output example:
components/Form.tsx:22: export function LoginForm({ onSubmit }) {
pages/register.tsx:57: <RegisterForm onSubmit={handleRegister} />
Performance:
grep: ~6.8 seconds
rg: ~0.21 seconds
Why Search Speed Matters More Today
Searching code is no longer a human-only activity. It is part of:
Incremental builds
CI linting + test filtering
Dependency scanning
AI agents traversing entire repos
Refactoring workflows
Developer search (IDE search, CLI search, etc.)
A repo that took 0.8 seconds to search 10 years ago might now take 85 seconds because:
node_modulesexplodedPolyglot languages introduced large ignored dirs
Generated code skyrocketed
Binary artifacts are mixed with sources
A search tool that handles these structures intelligently offers real time and real cost savings.
Why AI Coding Agents Use ripgrep Instead of grep
Claude Code, Cursor, Codex CLI, and Aider all use ripgrep as their primary codebase search tool. AI agents run 10–30 search operations per task to find function definitions, trace dependencies, and understand call patterns. At ripgrep's speeds, 30 searches complete in under one second. At grep's speeds, the same 30 searches take 20–90 seconds, making every agent interaction feel broken.
This is the most important ripgrep story in 2026. The reason these tools chose rg is not just speed, it is the combination of three properties that matter for AI agent context windows:
Speed at scale. An AI agent with a 10-minute task timeout can run approximately 500 ripgrep searches or 2 grep searches on a large codebase. That is the difference between an agent that deeply understands your code and one that has to guess. Claude Code's architecture is explicitly designed around the assumption that search is essentially free in latency terms, only possible because it uses ripgrep.
Clean, predictable output. ripgrep's output is compact and consistent. No binary file noise, no permission errors, no hidden file matches. Every line it returns is a relevant code match. This matters because every token of output the agent receives consumes context window space. One developer measured that 13% of their entire Claude Max monthly plan was consumed just by agent codebase exploration sessions, tight, filtered search from ripgrep versus noisy grep output is directly a budget question.
Automatic .gitignore respect. When Claude Code or Cursor searches your codebase, it automatically skips node_modules, .git, build artifacts, and anything else in .gitignore — because ripgrep respects these rules by default. grep does not. This is not just a convenience: it prevents the agent from wasting searches on files that are irrelevant to the actual source code.
One important caveat for very large monorepos: Cursor's "Instant Grep" feature revealed that on codebases north of one million files, even ripgrep takes 15+ seconds per search. Cursor's pre-built indexed approach completes the same search in 0.013 seconds — a 1,000x speedup at that scale. For 95% of codebases under 100,000 files, ripgrep is the right tool. For enterprise monorepos, pre-built search indexes become necessary.
Configuring ripgrep for AI agents: add this to your
.ripgreprcor pass as flags:
bash
Example #2: Searching Python Async Functions
Task: find async functions named process_event.
ripgrep:
rg -t py "async def process_event"
grep:
grep -R "async def process_event" . --include="*.py"
Ripgrep additionally skips:
pycache
.venv
migrations
compiled bytecode
grep does NOT.
Example #3: Kubernetes YAML Search
Find all YAML resources defining a container environment variable.
grep:
grep -R "env:" . --include="*.yml" --include="*.yaml"
Will search inside:
Helm chart templates
vendor charts
binary chart caches
autogenerated manifests
Ripgrep:
rg -t yaml "env:"
Search is:
Recursive
Ignore-aware
File-type aware
Faster by 10–50x on large k8s repos
Complete ripgrep vs grep Command Cheatsheet
grep command | ripgrep equivalent | Notes |
|---|---|---|
|
| -r and . are implicit in rg |
|
| -r and -n are default in rg |
|
| Same flag |
|
| rg uses --type / -t |
|
| rg respects .gitignore automatically |
|
| Identical pipe behaviour |
|
| rg supports PCRE2 with -P flag |
When grep is Still the Right Tool
ripgrep does not replace grep in every situation. Use grep when: processing stdin from a pipe (rg does not handle piped stdin well), you need POSIX compliance for portable shell scripts, you are working on systems where you cannot install additional tools, or you need specific grep regex behaviour (POSIX BRE/ERE) that differs from ripgrep's Rust regex syntax.
Keep grep for these specific cases:
Piped stdin processing.
cat file.txt | grep 'pattern'works exactly as expected.cat file.txt | rg 'pattern'also works, but grep is the natural tool for stdin pipelines, many shell scripts rely on this behaviour and should not be blindly converted to rg.POSIX compliance. If you are writing shell scripts that need to run on any Unix-like system without additional dependencies, grep is universally available. ripgrep requires installation.
Existing shell scripts. ripgrep's regex syntax (Rust regex) differs slightly from POSIX BRE/ERE. Scripts that rely on grep's exact regex behaviour — particularly backreferences, which grep supports but ripgrep does not by default — should not be converted without testing.
Very small files. On files under a few kilobytes, the performance difference is negligible. There is no meaningful reason to prefer rg over grep for quick one-off searches on small files.
For interactive use and codebase searches, which covers 95% of what developers use grep for, ripgrep is faster, cleaner, and more convenient. The key word is codebase. ripgrep was designed for searching code repositories. grep was designed for searching text. They excel at their intended use cases.
Why Grep Falls Apart in Large Repos
Grep’s weaknesses:
Recursion is optional
Ignores .gitignore
Blind to file types
Searches binaries
No multithreading
No SIMD acceleration
No project context
This leads to:
CPU exhaustion
Output noise
Long cold-start times
Agent failures (LLMs generating bad grep commands)
Slow CI step times
ripgrep vs ag, ack, and git grep
ripgrep is faster than ag (The Silver Searcher), ack, and git grep in virtually every benchmark. ag was the previous speed champion for code search but is no longer actively maintained. ack pioneered programmer-friendly grep alternatives but is the slowest of the three. git grep is fast within git repositories but requires git context and lacks ripgrep's file type filtering. For all new projects, ripgrep is the right choice.
Tool | Speed | Actively maintained | Best use case |
|---|---|---|---|
ripgrep (rg) | Fastest | Yes (v15 released Oct 2025) | All codebase search |
ag (Silver Searcher) | Fast | No (unmaintained) | Legacy projects |
ack | Slower | Yes | Perl-focused environments |
git grep | Fast in git repos | Yes (git built-in) | Searching committed files only |
GNU grep | Slower on large repos | Yes | Scripts, stdin, small files |
Benchmarks (Modern Realistic Repos)
Linux Kernel Source (9M LOC)
Tool | Time |
grep | 0.64s |
rg | 0.06s |
Kubernetes Repo
Tool | Time |
grep | 12.2s |
rg | 1.1s |
A Yarn Monorepo with 1M Files (Facebook-ish scale)
Tool | Time |
grep | 35s |
rg | 2–5s |
When grep Still Wins
Despite everything, grep is still:
Ubiquitous
Installed everywhere
Predictable in minimal systems
Perfect for quick one-liners on small files
Required for POSIX-compliant scripts
Examples where grep is ideal:
Search a single file:
grep "error" logfile.txt
Filter logs in pipelines:
cat access.log | grep 500
Tiny containers without rg:
docker run --rm alpine grep ...
In these, grep is unbeatable.
Conclusion: Grep Isn’t Slow: Your Repos Outgrew It
ripgrep isn’t a “faster grep.” It’s a modern code search engine built for modern repos.
Its advantages come from:
Smarter defaults
Multithreading
SIMD acceleration
Language-aware filtering
Gitignore filtering
Binary skipping
Massive repo compatibility
Zero configuration required
For developers, CI pipelines, and AI coding agents, ripgrep offers order-of-magnitude performance improvements that translate directly into productivity and cost savings.
If grep is a scalpel, rg is a fully-automated search machine built for the realities of 2025 engineering.
FAQs
Is ripgrep always faster than grep?
How do I install ripgrep?
What makes ripgrep’s architecture more suitable for developers and CI pipelines?
Why do Claude Code, Cursor, and Codex CLI use ripgrep?
Can ripgrep replace grep entirely?













