

LLMs are getting better at tool use every day, especially with a shell. Codebase RAG has evolved from embedding-based RAG to agentic RAG, and for massive codebases, agentic RAG works extremely well.
At CodeAnt AI, we rely on agentic RAG systems to navigate huge repositories and let the LLM fetch what it needs. We expose shell access as a tool so it can explore and gather context autonomously.
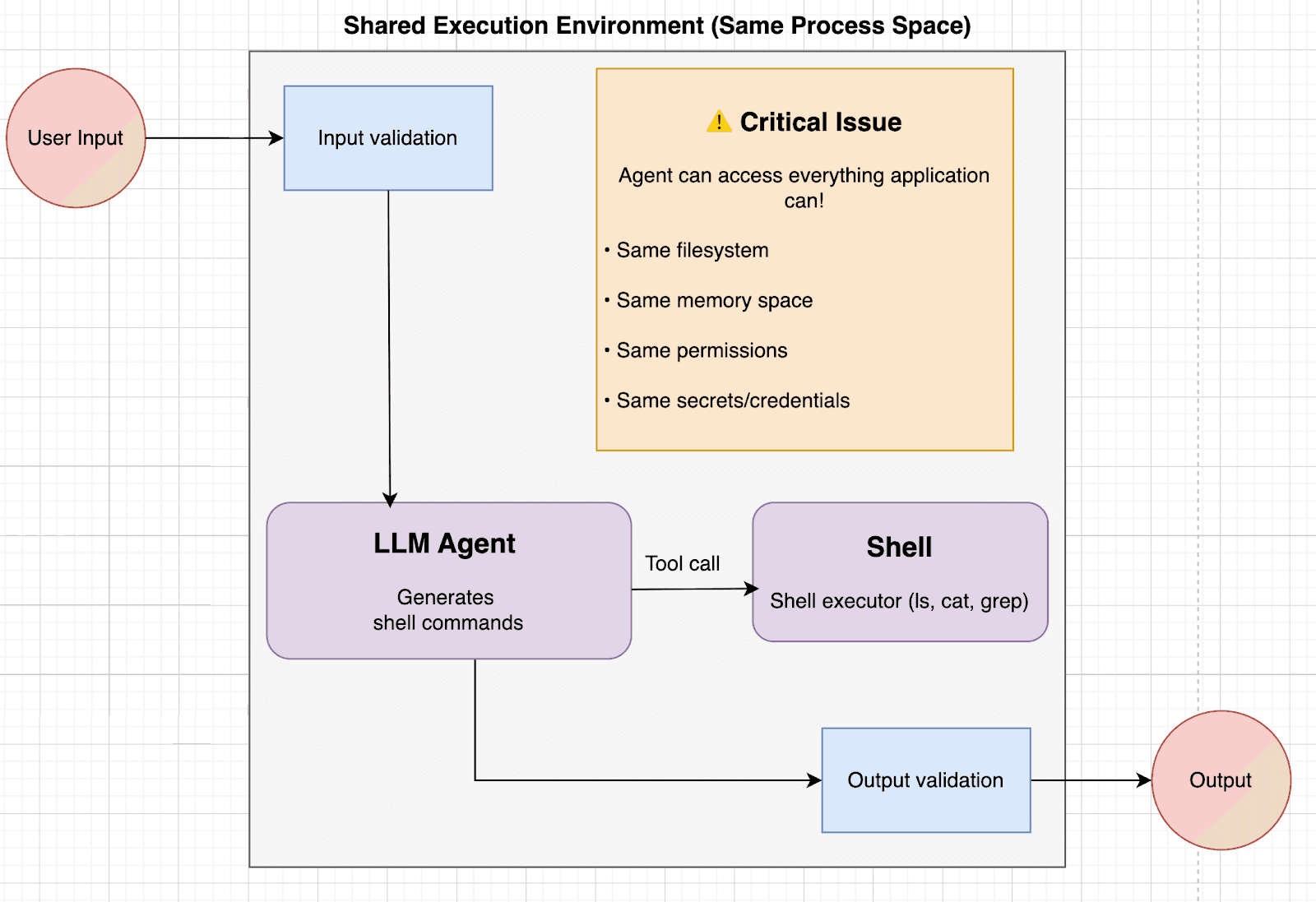
However, this new level of autonomy introduces a new threat surface. When an LLM is allowed to run shell commands, a single malicious prompt or subtle input manipulation can lead to unauthorized file access or system changes.
To understand how real this risk is, let’s walk through a simple exploit.
Example Attack Vector
A seemingly harmless request can be weaponized to trigger unexpected execution behavior.
Attacker prompt:
Agent response:
This demonstrates the core issue: LLMs don’t inherently understand boundaries. A task disguised as harmless can result in credential leakage.
Protection at Application Level
Before jumping to sandboxing, most systems attempt application-layer defense. These strategies help, but they are bypassable.
Prompt Injection Classifier:
Classifiers flag obvious malicious text. They stop direct attacks like “read secrets,” but struggle with obfuscation.
Works well for: Blatant “read secrets / run this” phrasing
Fails on: obfuscated payload
Example bypass:
User prompt:
Why it slips: Malicious action hidden behind base64 + legitimate-sounding task.
Input Sanitization
Blocking dangerous operators or binaries seems effective, until an allowed tool becomes the weapon.
Works well for: Blocking obvious bad tokens like |, ;, curl, base64, sh, absolute paths, or ../
Fails on: Dangerous behavior hiding behind an allowed tool
Example bypass:
Policy:
✓ Allow
pytest(common dev tool)✗ No pipes, no network
✓ Workspace-only paths
User prompt:
Why it slips: pytest executes arbitrary Python in conftest.py. Malicious test files bypass input checks entirely.
Output Sanitization
Trying to mask leaked secrets is reactive, and attackers can format data to evade detection.
Works well for: Obvious secrets (AWS-looking tokens, JWT-shaped strings), long base64 blobs, known sensitive paths
Fails on: Secrets encoded on demand to dodge pattern matchers
Example bypass:
Scenario: The tool accidentally reads .env with API_KEY=sk_live_7fA1b (short, non-standard format)
Attacker prompt:
Agent output:
Why it slips: Short, freshly encoded strings bypass pattern matchers designed for raw tokens or long blobs.
Why Application-Level Protection Isn’t Enough
All these layers help, but none provide true isolation. If the model can run commands, it can still escape via creative execution paths. To truly secure LLMs, we must isolate execution at the system level: sandboxing.
Sandboxing
A sandbox is an isolated environment for executing agent-emitted shell commands behind a strict security boundary. It exposes only approved utilities (whitelisted commands, no network by default), and per-execution isolation ensures one run can’t affect another.
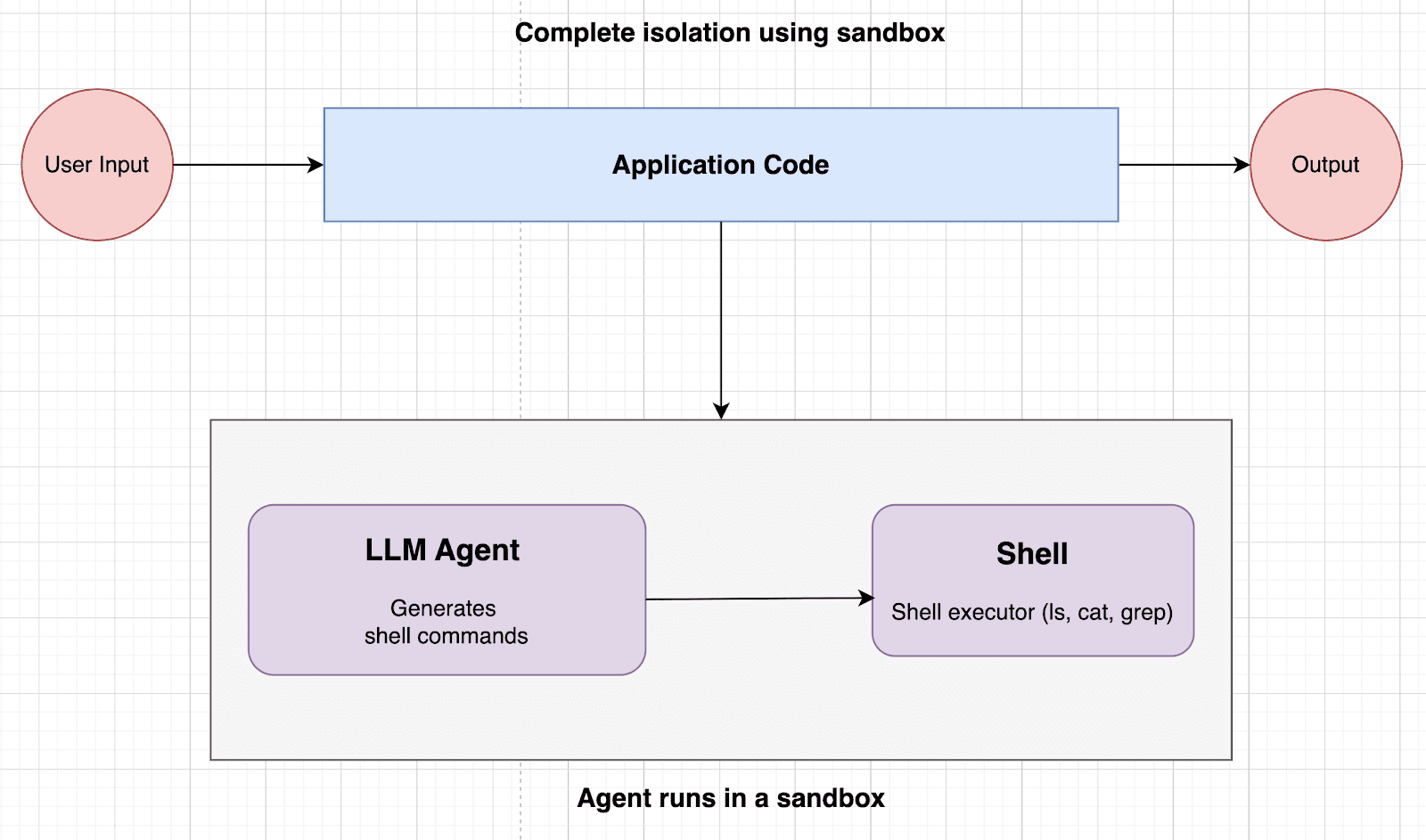
Sandboxing Approaches
When running AI agents that runs shell commands, you have three main options, each with different security guarantees and performance trade-offs:
Linux Containers (Docker with default runtime)
Useful when speed matters and workloads are trusted.
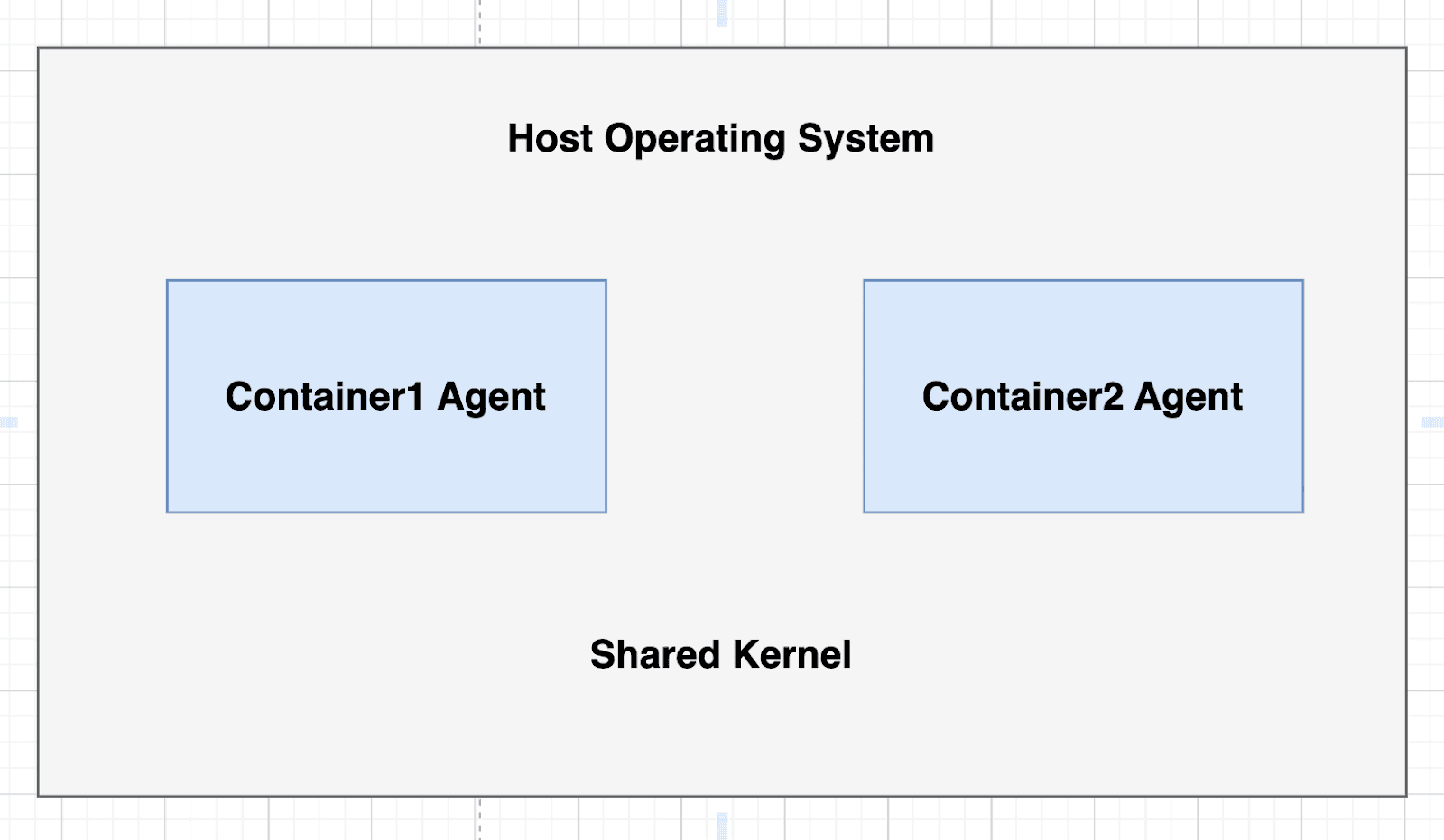
How it works:
Linux containers use kernel namespaces and cgroups to isolate processes. When you run a Docker container, it shares the host kernel but has isolated:
Process space (PID namespace)
Network stack (network namespace)
File system view (mount namespace)
User IDs (user namespace)
Security characteristics:
Isolation level: Medium
Attack surface: Shared kernel means kernel exploits affect all containers
Best for: Trusted workloads, resource efficiency over maximum security
Performance:
✅ Fastest startup (~100ms)
✅ Minimal memory overhead
✅ Near-native CPU performance
When to use:
You control the code being executed
Performance is critical
You trust your application-level security
Cost optimization is priority
User-Mode Kernels (Docker with gVisor)
Stronger isolation by mediating syscalls through a user-space kernel.
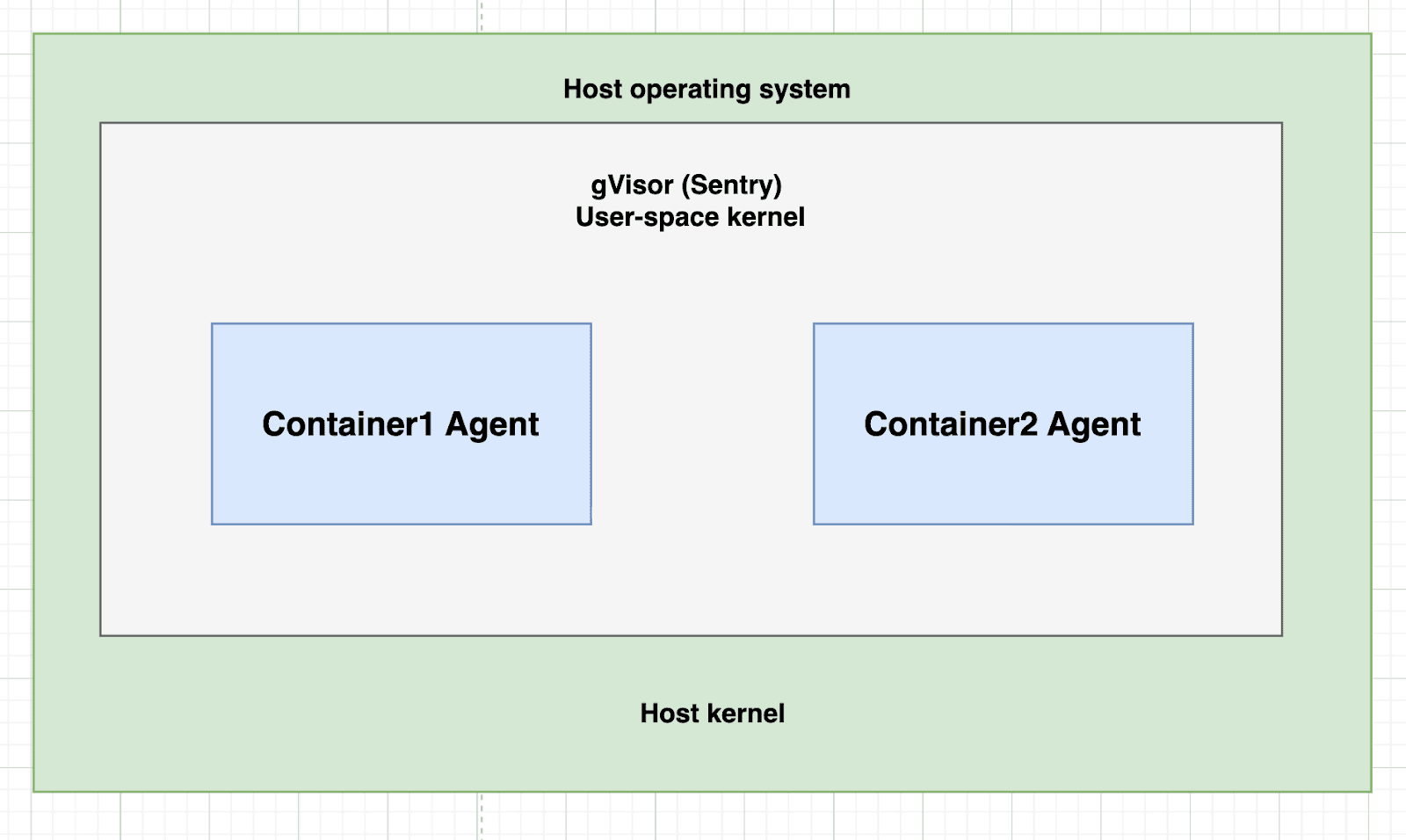
How it works:
gVisor implements a user-space kernel that intercepts system calls. Instead of system calls going directly to the Linux kernel, they’re handled by gVisor’s “Sentry” process, which acts as a security boundary.
Security characteristics:
Isolation level: High
Attack surface: Limited syscall interface (only ~70 syscalls vs 300+ in Linux)
Best for: Untrusted workloads that need strong isolation
Performance:
Slower startup (~200-400ms)
10-30% CPU overhead for syscall interception
Some syscalls not implemented (compatibility issues)
When to use:
Running untrusted code (like AI-generated commands)
Need stronger isolation than containers
Can tolerate performance overhead
Don’t need full VM overhead
Virtual Machines (Firecracker microVMs)
The strongest option, fully isolated microVMs powering AWS Lambda.
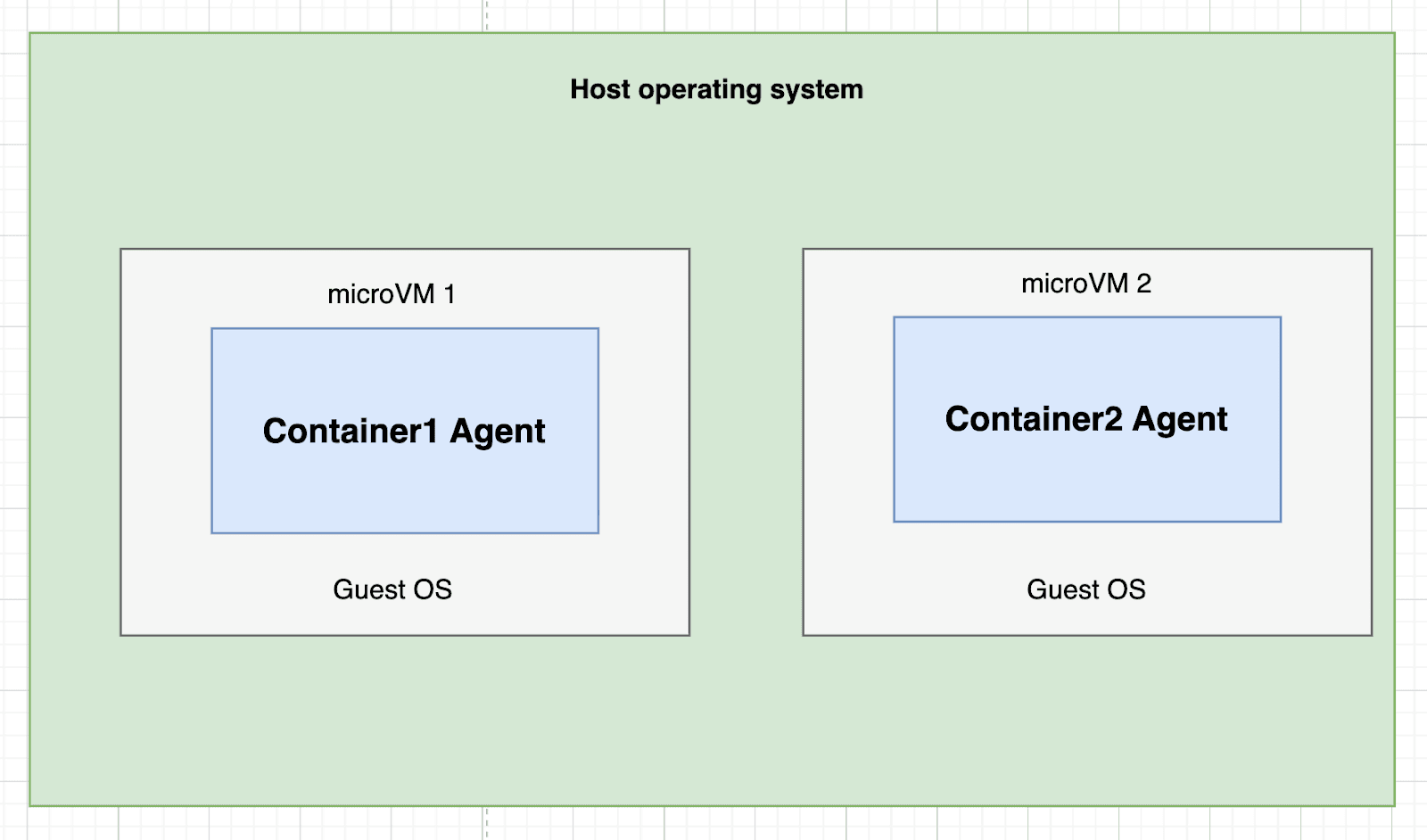
How it works:
Firecracker creates lightweight virtual machines with full kernel isolation. Each VM runs its own guest kernel, completely separate from the host. It’s what AWS Lambda uses under the hood.
Security characteristics:
Isolation level: Maximum
Best for: Zero-trust environments
Performance:
✅ Fast startup for a VM (~125ms)
✅ Low memory overhead (~5MB per VM)
⚠️ Slightly slower than containers, but optimized
When to use:
Running completely untrusted code (AI agents!)
Multi-tenant systems where isolation is critical
Need deterministic cleanup (VM destruction)
Security > slight performance cost
Comparing Sandboxing Approaches Side-by-Side
Each sandboxing method offers a different balance between performance, isolation strength, and compatibility. To make the trade-offs clear, here’s a direct comparison of Docker containers, gVisor, and Firecracker microVMs across key execution and security dimensions:
Feature | Docker (Default) | gVisor | Firecracker |
Startup time | ~100ms | ~300ms | ~125ms |
Memory overhead | ~1MB | ~5MB | ~5MB |
CPU overhead | Minimal | 10–30% | Minimal |
Kernel isolation | ❌ Shared | ⚠️ Filtered syscalls | ✅ Full |
Compatibility | Full | ~95% | Full |
Conclusion: Which One Should You Use?
For AI agents executing untrusted commands → Firecracker microVMs are the safest foundation.
Why Firecracker wins:
Kernel-level isolation
Fresh VM per session
Deterministic cleanup
Built-in network separation
Proven at hyperscale (AWS Lambda)
At CodeAnt.ai, we run our agents on Firecracker microVMs to guarantee security without compromise.

