AI Code Review
How AI Reviews Can Surface Compute-Cost Amplification Bugs

Sonali Sood

Founding GTM, CodeAnt AI
Ever watched your cloud bills spike 10x overnight from code that seemed perfectly fine? Compute-cost amplification bugs lurk in loops, recursions, and scaling logic, turning efficient apps into resource hogs. This article shows you exactly how AI code reviews surface these hidden threats early, helping teams like yours reclaim 25-40% of wasted compute spend.
When “Correct” Code Becomes Financially Broken
Software bugs are usually categorized by functionality, something works, or it doesn't. But there is a more insidious category of defect that functions correctly while silently draining your budget: the compute-cost amplification bug. These aren't just logic errors; they are financial vulnerabilities that turn standard operations into expensive cloud bills.
When a filter is ignored or a loop goes unbounded, the code might still return the correct result, but at 10x or 100x the intended resource cost. As infrastructure scales, these inefficiencies scale with it.
"Most defects end up costing more than it would have cost to prevent them. Defects are expensive when they occur, both the direct costs of fixing the defects and the indirect costs because of damaged relationships, lost business, and lost development time."
We need to treat cost as a first-class risk in code review, moving beyond simple correctness to architectural efficiency.
What Are Compute-Cost Amplification Bugs?
Compute-cost amplification bugs occur when a specific code path triggers a disproportionate consumption of resources, CPU, memory, or I/O, relative to the task's value. Unlike a crash, which is loud and obvious, these bugs are often silent. The application returns "200 OK," but behind the scenes, it may have scanned an entire database instead of a single partition or retried a heavy operation endlessly.
In the context of modern AI code reviews, these issues fall under the Performance & Cost impact area. They represent a specific type of failure where the logic holds up, but the execution semantics create a blast radius that affects your bottom line.
Defining the Problem
The core issue is often a disconnect between the developer's intent and the actual execution flow. A developer might write a query expecting it to hit a cache or filter by a tenant ID, but a missing parameter causes a full table scan.
These errors are incredibly expensive to fix once deployed. Data shows that the cost to fix an error after release is 4-5x higher than during design, and up to 100x more than during maintenance. By the time you notice the spike in your AWS or Azure bill, the damage is already done.
Common Types and Examples
These bugs typically manifest in predictable patterns that manual review often misses. Here are the most frequent offenders:
Ignored Filters: An API accepts
include/excludeparameters but fails to pass them to the scanner, causing a full-repo walk.Unbounded Loops: A retry mechanism that wraps a heavy side-effect (like a DB write) without exponential backoff.
Hot-Path Caching Failures: Removing caching from a frequently called policy loader, causing a database query for every single request.
Deep Traversal: Recursive functions that don't respect depth limits, amplifying compute on complex inputs.
Why Compute-Cost Bugs Are a Growing Threat
As teams move toward microservices and serverless architectures, the "pay-per-use" model turns inefficient code into direct financial loss. A single inefficient loop in a monolithic server might just slow things down; in a serverless function, it directly multiplies your invoice.
The risk isn't just accidental; it's also an attack path. If an endpoint allows a caller to submit a "narrow scan" but the code ignores it and forces a full scan, a bad actor (or a buggy internal service) can exploit this to amplify impact. Repeated requests can degrade system stability and spike costs.
Poor software quality costs the U.S. economy billions annually, and a significant portion of that comes from flawed processes that let these inefficiencies slip through (National Institute of Standards and Technology).
How AI Code Reviews Surface These Hidden Issues
Traditional AI tools often act like a "second developer," flooding you with unprioritized suggestions. To catch cost bugs, AI must instead act as a quality gate. This means moving from vague claims to testable engineering statements.
Effective AI review tools, like CodeAnt AI, use a structured approach:
Parse + Index: Identify endpoints, handlers, and service functions.
Flow-Tracing: Follow the call chain from entry point to downstream services.
Risk Pattern Detection: Identify ignored inputs, dead fields, and retries with side effects.
Impact Tagging: Map issues specifically to "Performance & Cost."
Advanced Pattern Recognition
AI reviews excel at identifying risk patterns that humans gloss over. For example, an AI can detect when a retry() block wraps a function that emits an event or writes to a database.
It recognizes this as a Reliability and Cost risk: if the transient failure happens after the write but before the return, the retry loop repeats the side effect. The AI flags this not just as "bad code," but as a specific severity level, often Critical or Major depending on the blast radius.
Static Analysis for Complexity Traps
Static analysis in this context goes beyond linting. It involves flow-tracing to verify contract adherence.
If a request DTO (Data Transfer Object) includes a sort_by field or a tenant_id, the AI traces that variable through the execution path.
Entry Point:
POST /endpointreceives the request.Parsing: Handler extracts fields.
The Gap: The AI notices that while
tenant_idwas parsed, it was never passed into the repository query builder.The Result:
SELECT * FROM Xexecutes without the tenant constraint.
This trace proves that the code is technically "working" (no syntax errors) but functionally broken regarding cost and security.
Dynamic Simulation and Cost Projections
While static analysis finds the bug, dynamic simulation logic helps assign Severity. The AI evaluates the blast radius and likelihood of failure.
Critical 🚨: Security exposure or outages (e.g., cross-tenant data leak).
Major ⚠️: Consumer-facing bugs or silent wrong output (e.g., full table scan on a public endpoint).
Minor 🧹: Maintainability improvements.
By calculating the "cost-of-inaction," the AI can predict that a caching regression on a hot path isn't just a style issue, it's a Major performance risk that requires immediate blocking of the PR.
Key Benefits of AI-Driven Detection
The primary benefit of using AI for cost bugs is the shift from claims to proof. Developers are skeptical of tools that just say "this looks wrong." They trust tools that show why.
AI reviews that provide Steps of Reproduction change the conversation.
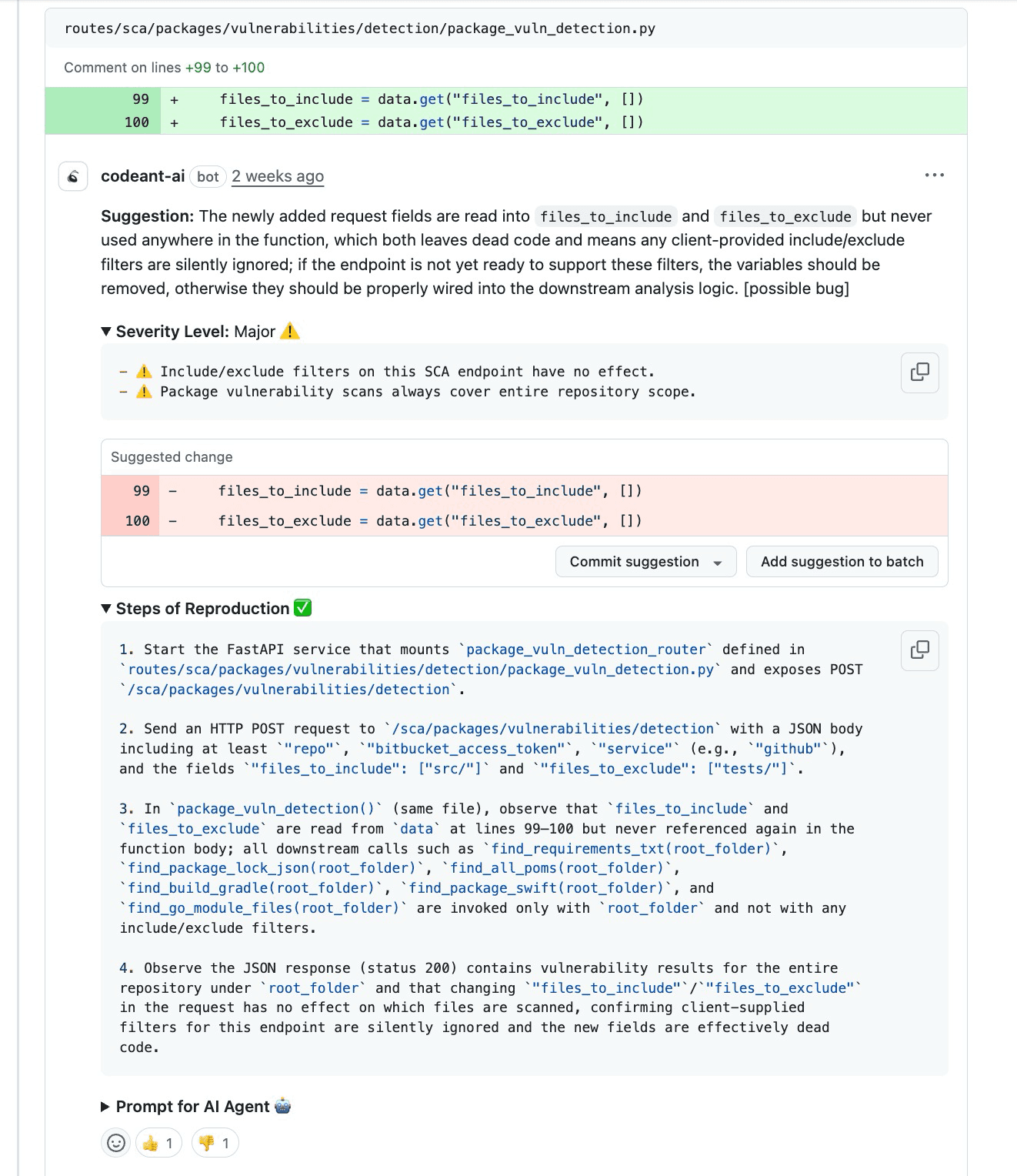
Instead of arguing about theory, the AI provides a deterministic checklist:
Trigger: Send payload X.
Control-flow evidence: See where input is ignored.
Observable output: Response returns success but violates contract.
This reduces the cost of fixing bugs significantly. That said, finding these issues at the PR stage costs roughly $100, compared to $10,000 if discovered in production.
Implementing AI Code Reviews in Your Workflow
To make AI reviews effective for cost control, they must be integrated deeply into your development lifecycle, not bolted on as an afterthought. The goal is to catch impact amplification logic before it merges.
Integrating with CI/CD Pipelines
AI reviews should function as a blocking gate in your CI/CD pipeline. When a PR is opened, the AI scans the diff against the repo context, call graphs, dependency graphs, and symbol indexes.
It validates runtime assumptions. For example, if a developer adds a heavy library or a new database call in a loop, the AI checks this against the known constraints of your infrastructure. It looks for "silent wrong output," like a request that accepts configuration filters but ignores them, returning a "200 OK" while performing a full scan in the background.
Customizing Rules for Your Stack
Every team has unique domain rules. You might have a policy that "all public endpoints must support pagination" or "no direct database calls from the view layer."
You can configure the AI to enforce these specific architectural standards. If your team uses a specific pattern for tenant isolation, the AI can be trained to flag any query that lacks the tenant_id predicate. This customization ensures the AI isn't just checking generic Python or Java syntax, but is actually reviewing your application's specific logic and cost constraints.
Best Practices for Maximizing Detection Accuracy
Accuracy in AI reviews comes from context. The more information the AI has about the execution flow, the better it can predict cost impacts.
Combining AI with Human Oversight
AI is the detector; the human is the verifier. The AI provides the Trace + Attack Path, laying out exactly how the bug travels through the system.
The AI says: "Here is the execution path. The
files_to_includeparameter is extracted but never passed to the scanner."The Human verifies: "Yes, I see the gap in the call chain."
This collaboration works best when the AI output is structured as a testable engineering statement.
Monitoring and Iterating on Findings
Treat your AI review results as data. Monitor which Impact Areas are flagging the most issues. Are you seeing a spike in Performance & Cost warnings? This suggests a systemic issue in how your team handles data retrieval or loops.
Use the Observability impact area to ensure that when cost bugs do slip through, you have the logs to catch them. The AI should flag "swallowed exceptions" or missing metrics on critical paths, ensuring you aren't flying blind on costs.
Common Mistakes to Avoid
The biggest mistake teams make is treating AI reviews as a "linter on steroids" rather than a logic analyzer.
Ignoring Severity Levels: treating a Major cost risk the same as a Minor style suggestion.
Skipping the Trace: Developers often look at the suggestion line but ignore the Trace + Attack Path. The trace explains how the bug propagates. Without reading it, you might fix the symptom but miss the root cause.
Lack of Reproduction: Accepting a fix without verifying the Steps of Reproduction. The AI generates these steps to prove the bug exists; use them to prove the fix works.
Overlooking "Silent" Failures: Assuming that because the build passed and the tests are green, the code is efficient. AI specializes in finding "silent wrong output," code that works but is wastefully expensive.
Real-World Examples from Engineering Teams
To understand the value of trace-based AI reviews, let's look at how they surface actual bugs that standard tests often miss.
Example A: The Performance Regression
Finding: Caching was removed from a frequently called policy loader.
Trace: Request $\rightarrow$ Policy Fetch $\rightarrow$ DB Query per request $\rightarrow$ Latency spike.
Severity: Major ⚠️
Repro: Load test shows query count explosion.
Result: The team prevented a massive database load spike that would have taken down the auth service.
Example B: The Tenant Data Leak
Finding: A repository query was missing the
tenant_idfilter.Trace: API $\rightarrow$ Auth $\rightarrow$ Query Builder $\rightarrow$
SELECT * FROM X(missing constraint).Attack Path: A token from Tenant A can retrieve Tenant B's metadata.
Severity: Critical 🚨
Result: Caught a severe security and compliance violation before deployment.
Example C: Knight Capital Group
While not caught by modern AI, this is the historical benchmark for compute-cost disasters. Faulty software caused unintended stock trades, costing the company nearly half a billion dollars in 45 minutes. It highlights the ultimate cost of unchecked execution logic.
Your Partner in Cost Bug Prevention
CodeAnt AI is designed to catch these specific types of amplification bugs. We don't just lint your code; we analyze the Trace + Attack Path to show you exactly how a minor code change can spiral into a major cost issue.
Our platform behaves like a quality gate, offering:
Severity Scoring: Distinguishing between Critical risks and Minor cleanup.
Impact Areas: Clearly labeling issues as Performance & Cost or Security.
Steps of Reproduction: Giving you a checklist to verify the bug immediately.
By providing evidence-first reviews, CodeAnt AI helps you fix financial vulnerabilities before they hit your cloud bill.
Conclusion
The era of reviewing code solely for syntax and style is over. In a cloud-native world, code quality is directly tied to operational cost. Compute-cost amplification bugs, those silent killers that multiply resource usage—, are the new "critical" defects.
By leveraging AI that provides deep flow-tracing, severity scoring, and reproduction steps, engineering teams can move from guessing to knowing. It's about building a trust stack where every review comment is backed by a testable engineering statement. This doesn't just save time; it saves budget, reputation, and sanity.
FAQs
How do you fix an ignored filter bug in code?
What tools detect unbounded loops besides AI reviews?
How much can serverless amplify compute-cost bugs?
What's the setup time for AI reviews in CI/CD?
How do teams measure AI review ROI on cost bugs?













