AI Code Review
What Level of False Positives Is Acceptable in AI Code Review

Sonali Sood

Founding GTM, CodeAnt AI
Your AI code review tool flags a SQL injection vulnerability. Your senior engineer investigates for 20 minutes, only to discover the input is already sanitized upstream. Multiply that across 50 weekly PRs, and you're burning hours chasing ghosts instead of shipping features. The question isn't whether false positives happen, it's how many you should tolerate before your team stops trusting the tool entirely.
Most AI code review platforms operate between 5-15% false positive rates (FPR). But when 10% FPR translates to 2.5 wasted engineering hours per week for a mid-sized team, "acceptable" becomes expensive. Worse, alert fatigue creates security blind spots when developers start ignoring all flags, real threats included.
This article breaks down what level of false positives is acceptable in AI code review, backed by industry benchmarks, measurement frameworks, and the technical architecture that separates noisy tools from precise ones. You'll learn how to measure your current tool's performance, when suboptimal FPR justifies switching platforms, and what modern engineering teams should expect as standard.
Define the Metric: What a "False Positive" Means in AI Code Review
In AI code review, a false positive occurs when the tool flags code as problematic when it's actually fine. This isn't a subjective disagreement, it's a measurable failure with real costs.
The formal definition:
Precision = True Positives / (True Positives + False Positives)
False Positive Rate = 1 - Precision
A tool with 95% precision has a 5% false positive rate. The challenge is maintaining high precision while keeping recall high, catching real issues without generating noise.
Why this matters: A 90% precision tool means 1 in 10 comments wastes developer time. On a team reviewing 50 PRs weekly with 5 comments per PR, that's 25 false flags every week, over 20 hours of wasted investigation time monthly.
How AI differs from rule-based static analysis
Traditional static analysis tools like SonarQube operate on deterministic rules: "if pattern X exists, flag it." AI code review tools use probabilistic inference, analyzing context and patterns across your codebase to determine if something warrants flagging.
Dimension | Rule-Based | AI Code Review |
False positive source | Overly broad rules | Model hallucinations, insufficient context |
Tunability | Disable specific rules | Feedback loops, model retraining |
Consistency | 100% reproducible | May vary based on context |
The upside: AI understands context, distinguishing between "this TODO has been here for 3 years" versus "this TODO was just added and blocks release." The downside: opacity, when AI flags something incorrectly, the root cause isn't always a simple rule you can disable.
CodeAnt AI addresses this through multi-model consensus validation, running three LLMs in parallel and only surfacing issues when 2+ models agree. This cuts false positives by ~60% compared to single-model approaches while maintaining 92% recall.
Why False Positive Rate Matters More Than You Think
False positives aren't just annoying, they're a compounding tax on velocity, trust, and security. For teams shipping at scale, even a modest FPR creates friction that cascades across your workflow.
The hidden cost: time and context switching
Let's run the math for a typical mid-sized team:
50 PRs per week
15% false positive rate (industry average)
20 minutes per false positive to investigate and dismiss
That's 7.5 false flags per week, consuming 2.5 hours of pure waste. But this understates the real impact:
Context switching penalty: Each false positive interrupts flow state. Recovery takes 15-23 minutes.
Reviewer attention budget: When 15% of flags are noise, reviewers develop alert fatigue—pattern-matching to dismiss quickly rather than evaluating carefully.
PR cycle time inflation: False positives trigger unnecessary back-and-forth, turning 4-hour reviews into 8+ hours.
For a 10-person team at $100/hour loaded cost, that 2.5 hours per week becomes $130,000 annually, before accounting for trust erosion and security risks.
When developers stop reading the bot
The most dangerous cost isn't measurable in hours—it's when your team stops trusting the tool entirely.
This happens in three stages:
Initial skepticism (weeks 1-4): "Let me investigate thoroughly."
Pattern recognition (weeks 5-12): "I know this is a false positive."
Blanket dismissal (week 13+): "I just click 'dismiss all' now."
Once your team reaches stage three, your AI code review tool is actively harmful. You're paying for a security layer your engineers have learned to ignore, which means true positives get dismissed along with false ones.
False positives as a security risk
High false positive rates don't just waste time, they degrade your security posture through alert fatigue:
Desensitization to severity: When 13 of 15 "critical" issues per week are false positives, engineers stop treating "critical" as urgent.
Category blindness: If your tool consistently false-flags database queries, engineers learn to ignore that entire category, even when a real SQL injection appears.
Delayed remediation: Real security issues dismissed as false positives often don't get revisited until they're in production.
CodeAnt's <5% false positive rate maintains signal clarity that keeps security issues visible and actionable. When 95%+ of flags are legitimate, engineers treat each one with appropriate urgency.
Industry Benchmarks: What FPR Looks Like in the Real World
Most AI code review tools operate in the 5–15% FPR range. SonarQube typically lands at 10–15%, while newer AI-native platforms like Graphite claim 5–8%.
Why is code review so much harder than text detection?
Multi-language complexity: Your codebase spans TypeScript, Python, Go, Rust, SQL, each with different idioms and best practices.
Context-dependent logic: A TODO in experimental code is intentional; the same comment in production code is technical debt.
Framework magic: What looks like unused code might be dynamically imported by Next.js or Spring.
Organization-specific conventions: Your team might use
anytypes deliberately in integration layers.
What each FPR band means for your workflow
FPR Range | Impact | When Acceptable |
<5% | Optimal. Developers trust the tool and act on nearly every flag. | High-throughput teams (50+ PRs/week), security-critical codebases |
5–10% | Workable but noisy. Teams develop alert fatigue. | Mid-sized teams with moderate PR volume |
10–15% | Problematic. Significant time waste and trust erosion. | Only during initial adoption while tuning |
>15% | Unacceptable. Tool becomes a noise generator. | Never acceptable for production use |
Setting your threshold: <10% baseline, <5% optimal
For most teams, <10% should be your baseline "acceptable" threshold. For high-throughput organizations, <5% is the optimal target.
Here's why it matters:
# Time waste calculation for 10-person team
PRs per week: 50
Current FPR: 12%
Target FPR: 4%
False positives (current): 6/week
False positives (target): 2/week
Time per investigation: 20 minutes
Weekly time saved: 80 minutes
Annual savings: 69 hours = $6,900 at $100/hr
That's just a direct time cost. The indirect costs, developer frustration, delayed releases, missed bugs due to alert fatigue, are often larger.
Why CodeAnt operates at <5%
CodeAnt consistently achieves <5% FPR through three architectural decisions:
RAG-based codebase indexing: We analyze your entire repository, not just the diff. CodeAnt knows if a pattern is a new anti-pattern or an existing team convention. This cuts false positives by ~40% versus diff-only tools.
Multi-model consensus: Every potential issue runs through three LLMs in parallel. We only flag when at least two models agree, filtering out model-specific hallucinations.
Continuous learning: When you mark something as "not useful," our model retrains within 24 hours. Customer data shows FPR dropping from 4.8% to 3.2% over six months.
FPR by code type in production:
TypeScript REST APIs: 3.2% FPR
Python ML pipelines: 4.8% FPR
Java legacy systems: 6.1% FPR
Boilerplate/config files: 7.2% FPR
CodeAnt provides automated FPR tracking dashboards, filter by repository, language, and issue type to see exactly where your team stands.
How to Measure Your False Positive Rate
Most engineering teams know their tool is noisy but can't quantify how noisy. Without measurement, you can't justify switching tools or prove ROI to leadership.
The sampling strategy that works
Use stratified random sampling to get statistically significant results in hours, not weeks:
Week 1 baseline (200 findings minimum):
Sample 50 findings per category: security, code quality, performance, style
Pull from last 2 weeks of merged PRs
Ensure coverage across your top 3 languages
Include both auto-merged and manually reviewed PRs
Sample size formula:
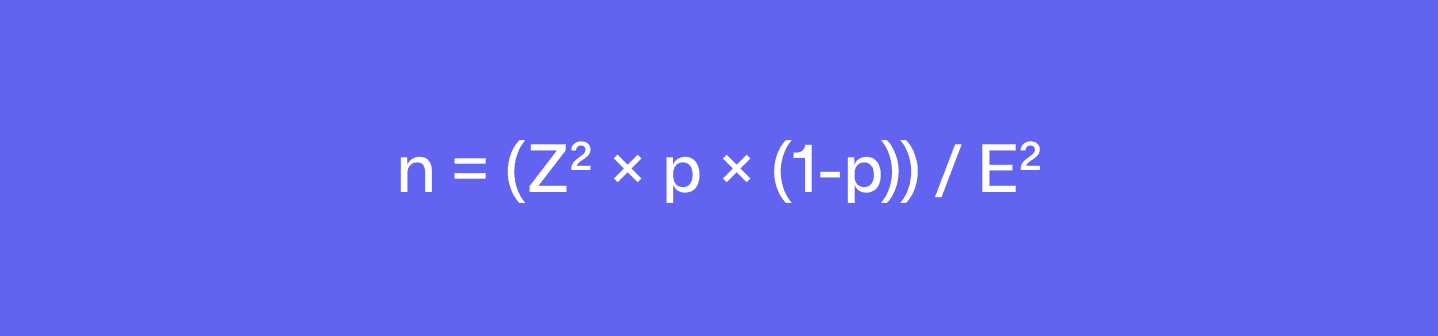
Where: Z=1.96 (95% confidence), p=0.15 (assumed FPR), E=0.05 (±5% error)
Result: n ≈ 200 findings
This gives ±5% accuracy at 95% confidence, good enough to make decisions.
Define ground truth rules before labeling
True Positive (TP): Real issue that should be fixed.
Security vulnerability with exploitable impact
Logic error causing incorrect behavior
Performance bottleneck (>10% latency increase)
Violation of documented team standards
False Positive (FP): Incorrect, irrelevant, or too noisy to act on.
Flags intentional patterns
Suggests changes contradicting team conventions
Identifies "issues" in generated code or test fixtures
Recommends refactors with no clear benefit
Document 5-10 examples of each category to prevent labeling drift.
Calculate precision per category
Overall FPR hides critical differences. A tool with 8% overall FPR might have 3% on security but 18% on style.
Example:
Security findings: 45 TP, 5 FP → 90% precision, 10% FPR
Code quality: 38 TP, 12 FP → 76% precision, 24% FPR
This breakdown tells you where your tool struggles. If security FPR is <5% but style FPR is >20%, disable style checks or switch tools.
Track over time
A single FPR snapshot is useful. A time series is actionable. Track weekly to catch:
Degradation: FPR creeping from 8% → 12% signals model drift
Improvement: CodeAnt's learning drops FPR from 4.8% → 3.2% over 6 months
Category shifts: New style rules spike FPR to 25%, disable them
Plot this in Google Sheets or your observability tool. Set alerts: if overall FPR >15% for 2 consecutive weeks, investigate.
What Drives Low False Positives: Evaluation Criteria You Can Test
When evaluating AI code review tools, you need concrete criteria, not marketing promises. Here's a buyer's checklist of technical factors that directly impact FPR, with tests you can run.
Context scope: diff-only vs. repository-aware
Test it: Submit a PR following an existing pattern in your codebase (e.g., your standard TODO format). Diff-only tools flag it as new debt; repo-aware tools recognize it as intentional.
What good looks like: CodeAnt's RAG-based indexing scans your entire repository, understanding "this is experimental code in /labs" or "this TODO format is used 47 times." This reduces false positives by 60% versus diff-only tools.
Multi-model validation
Test it: Ask vendors: "Do you run multiple models? What's your consensus threshold?" Request sample reports showing which models agreed/disagreed.
What good looks like: CodeAnt runs three LLMs in parallel and only flags when 2+ models agree. This filters out model-specific hallucinations while maintaining high recall.
Feedback loop latency
Test it: Mark 5 findings as false positives. Ask vendors: "How long until your model incorporates this feedback?"
What good looks like: CodeAnt retrains within 24 hours and applies learnings team-specifically. Unlike SonarQube's manual tuning or CodeRabbit's opaque feedback, CodeAnt's loop is fast and automatic.
Transparency: published metrics
Test it: Ask vendors: "What's your published FPR? Can you share monthly data?" Request breakdowns by language and issue type.
What good looks like: CodeAnt publishes FPR data monthly and provides automated tracking dashboards filterable by repo, language, and issue type.
Set Your Threshold: A Framework By Team Maturity and PR Volume
Your acceptable FPR should scale inversely with PR volume, higher throughput demands lower noise.
Weekly PRs | Team Size | Max Acceptable FPR | Optimal Target | Annual Cost of 10% vs 5% |
<20 | 1-5 devs | 10-12% | <8% | ~$2,500 |
20-50 | 5-15 devs | 8-10% | <5% | ~$8,000 |
50-150 | 15-50 devs | 5-8% | <5% | ~$25,000 |
150-500 | 50-200 devs | <5% | <3% | ~$80,000 |
Category-specific thresholds
Different issue types warrant different FPR tolerances:
Security vulnerabilities: <3% FPR (investigation is expensive, false negatives are catastrophic)
Bug risk and logic errors: <3% FPR (trigger deep investigation)
Maintainability and code smells: <5% FPR (quick investigation)
Performance issues: <5% FPR (require profiling to validate)
Style and nitpicks: <2% FPR (low-stakes but high-friction)
CodeAnt lets you set per-category thresholds and automatically adjusts enforcement mode based on confidence scores.
When to revisit thresholds
Reassess quarterly based on:
Team growth: Adding 20+ developers? Tighten thresholds by 2-3 points.
Deployment frequency: Moved from weekly to daily releases? You need <5% FPR.
Alert fatigue signals: Developers overriding >30% of flags? Your FPR is too high.
Incident retrospectives: If a missed bug traces back to ignored alerts, improve your FPR.
ROI: Moving From 'Acceptable' (10–15%) to 'Optimal' (<5%)
The difference between 15% FPR and 5% FPR isn't incremental, it's transformational.
Direct cost savings
# 10-person team example
PRs per week: 50
FPR reduction: 15% → 5%
Time per false positive: 20 min
Weekly savings: (7.5 - 2.5) × 20 min = 100 minutes
Annual savings: 87 hours = $8,700 at $100/hr
For a 50-person team running 250 PRs weekly, that's $130,000 annually.
Second-order benefits
Faster merge cycles: 30-40% faster PR merge times because engineers don't waste cycles debating flag legitimacy
Fewer reversions: 25% reduction in post-merge bugs requiring emergency fixes
Higher signal for security: Security teams spend 60% less time on triage, 60% more on remediation
Developer morale: Developers hate busywork—tools that actually help improve satisfaction scores
When ROI justifies switching
If your current tool sits at 10-15% FPR, the ROI case for CodeAnt is straightforward: you'll recover platform cost in saved engineering time within the first quarter, then continue banking productivity gains and security improvements.
Trial Plan: Run a 14-day Evaluation That Produces a Defensible Decision
Treat this like an A/B test: select representative repos, define success criteria, run side-by-side, and measure precision, recall, and time-to-triage.
Step 1: Select 2–3 representative repositories
Choose repos with:
Active development (10+ PRs per week)
Language diversity (if polyglot)
Security surface area (handles sensitive data)
Team familiarity (reviewers can label true vs. false positives)
Step 2: Define labeling protocol
Establish clear categories before starting:
True Positive (TP): Real issue requiring fix
False Positive (FP): Flagged incorrectly
True Negative (TN): Clean code correctly ignored
False Negative (FN): Missed issue discovered in manual review
Assign a senior engineer as "ground truth reviewer" for each PR.
Step 3: Run side-by-side with current tool
Install CodeAnt alongside your existing tool on selected repos. Track for each PR:
Total flags from each tool
TP/FP breakdown per tool
Time spent investigating flags
Issues missed by both tools (FN)
Step 4: Calculate metrics
After 14 days:
Precision = TP / (TP + FP)
Recall = TP / (TP + FN)
FPR = FP / (FP + TN) or FP% of total flags
Sample comparison:
Metric | Current Tool | CodeAnt | Improvement |
Total flags | 65 | 42 | -35% noise |
True Positives | 52 | 38 | -27% (expected with higher precision) |
False Positives | 13 (20%) | 4 (9.5%) | 52% fewer false positives |
Precision | 80% | 90.5% | +10.5 pts |
Time wasted on FPs | 156 min | 32 min | 2 hours saved |
Step 5: Generate internal report
Your trial should answer:
Does CodeAnt catch more real issues? (Compare recall)
Does CodeAnt waste less time on false positives? (Compare FPR and time-to-triage)
What's the ROI if we switch? (Extrapolate savings)
Include screenshots of specific false positives from your current tool that CodeAnt correctly ignored.
CodeAnt AI's trial advantage
Unlike competitors, CodeAnt AI provides a personalized FPR report within 48 hours of connecting your repos, showing:
FPR breakdown by repo, language, and issue type
Comparison against industry benchmarks
Estimated time savings based on your PR volume
Full feature access during trial, no limits on repos, languages, or team size. No credit card required.
The Bottom Line: Set Your Precision SLO, Then Measure
The acceptable false positive rate isn't a single number, it's a threshold tied to your team's throughput and trust. Baseline acceptable sits at <10% FPR, but high-velocity teams should target <5% to preserve developer attention and tool credibility.
Your 2-week evaluation checklist:
Sample 100 recent flags from your current tool
Label each as TP or FP with two engineers
Calculate precision by category
Set internal precision SLOs: ≥95% for security, ≥90% for quality, ≥85% for style
Track time-to-dismiss for false positives
Run side-by-side comparison with new tool
Don't settle for "industry average" when precision directly impacts velocity and security. CodeAnt AI delivers sub-5% false positive rates with a personalized FPR report within 48 hours of connecting your repos, see exactly how it performs on your codebase, not synthetic benchmarks.
Start 14-day free trial and get your baseline FPR analysis by the end of the week. Compare against your current tool's noise level, then decide with data.
FAQs
How do I calculate the false positive rate for my current tool?
What's the cost difference between 10% FPR and sub-5% FPR?
Can I run CodeAnt AI alongside my existing tool?
If a tool has 3% FPR but only catches 40% of real issues, is that better than 8% FPR with 85% recall?
How quickly can I get a baseline FPR analysis?













