AI Code Review
What KPIs Matter for AI Code Review Rollout?

Sonali Sood

Founding GTM, CodeAnt AI
Your exec team wants proof that AI code review delivers ROI, but most engineering leaders track metrics that actively mislead. Teams measure PR velocity or commit volume, only to discover three months later that they've optimized for throughput while quality quietly eroded. The real challenge isn't whether AI helps developers work faster; it's knowing which KPIs actually predict long-term success versus which ones just look good in quarterly slides.
Traditional DORA metrics weren't designed for AI-assisted development. Cycle time calculations miss prompt-crafting overhead. Defect density doesn't distinguish AI-generated commits from human-written code. And when your team uses Copilot, Cursor, and Qodo simultaneously, attributing improvements to any single tool becomes impossible.
This guide breaks down a four-pillar KPI framework that separates successful AI rollouts from expensive experiments. You'll learn which metrics matter at each stage, when to scale beyond pilots, and how to quantify the non-code value, debugging efficiency, knowledge transfer, requirements clarity, that traditional dashboards completely miss.
Why Traditional Metrics Fail During AI Adoption
When engineering leaders roll out AI-assisted code review, classic throughput and velocity indicators get distorted by AI's unique workflow patterns, making it impossible to separate signal from noise without rethinking your instrumentation.
The Hidden Overhead That Breaks Cycle Time
Traditional cycle time tracking assumes developers spend their time writing code, submitting PRs, and responding to reviews. AI introduces an invisible phase: prompt crafting and iteration. Senior engineers now spend 15-20% of their coding sessions refining context, testing AI suggestions, and rejecting hallucinations before a single line hits version control.
What looks like "slower velocity" in week one is often engineers learning to prompt effectively, an investment that pays off in weeks 3-6 when their AI-assisted commits require 40% fewer review cycles. But if you're measuring only PR-open-to-merge time, you'll see an initial dip and potentially kill the rollout before the learning curve flattens.
The attribution problem compounds this: when a developer uses Copilot for boilerplate, Cursor for refactoring, and Qodo for test generation in the same PR, which tool gets credit for the 30% cycle time improvement? Most teams lack the telemetry to answer this.
When "More PRs" Signals Quality Erosion
AI code generation creates a volume paradox: teams ship more PRs, but that throughput increase often masks declining code health.
AI multiplies junior-level submissions. Developers who previously hesitated to submit complex changes now lean on AI to generate plausible-looking implementations. PR count rises, but so does the percentage requiring multiple revision rounds because the AI produced syntactically correct but architecturally fragile code.
Review bottlenecks shift, not disappear. Pre-AI, your constraint was "developers writing code." Post-AI, it's "senior engineers reviewing AI-generated code that looks correct but violates domain invariants." You miss that your principal engineers now spend 60% of their time catching AI hallucinations instead of mentoring juniors.
Defect density lags by 4-8 weeks. Bugs introduced by over-reliance on AI suggestions don't surface until production. By the time your incident rate spikes, you've already scaled the rollout based on misleading "velocity gains."
The Baseline Problem
Most engineering orgs lack pre-rollout baselines for the metrics that actually matter:
AI Contribution %: GitHub/GitLab don't distinguish AI-generated code from human-written
Prompt→Commit Success Rate: IDEs don't log which AI suggestions were accepted vs. rejected
Pre-Review Fix Rate: Code review platforms see only the final PR, not AI-caught issues before submission
Context Fetch Time: No tooling tracks how long engineers spend understanding legacy code with AI assistance
Without these baselines, you're comparing post-AI metrics to a phantom pre-AI state. CodeAnt AI's 360° code health view establishes baselines even if AI adoption started months ago by scanning existing repos to calculate historical defect density, complexity trends, and review patterns.
The Four-Pillar KPI Framework

Measuring AI code review impact requires a layered approach that connects adoption signals to delivery outcomes. This framework organizes metrics into four pillars, each building on the last to give you a complete rollout picture without metric overload.
Pillar 1: Adoption Metrics
Adoption indicators tell you within the first sprint whether engineers trust the tool, integrate it into their workflow, and see value worth repeating.
% Daily Active AI Users
Track the percentage of your engineering team actively using AI code review tools each day. Target 70%+ weekly usage in pilot phase (Months 1-3), scaling to 80%+ across expanded teams (Months 4-6). Low adoption after 4-6 weeks signals friction—poor IDE integration, irrelevant suggestions, or workflow disruption.
AI-Assisted Commit %
Measures what percentage of commits include AI-generated or AI-modified code. Expect 30-40% in pilot phase, scaling to 50-65% at maturity. This is your primary "AI is doing real work" indicator. Plateaus below 30% often mean AI suggestions are too generic or miss your org's coding standards.
Prompt→Commit Success Rate
Tracks how often AI suggestions make it into committed changes without significant rework. Pilot teams should hit 40-50% success rate, scaling to 60-70% as engineers master prompt engineering. Rising success rates prove engineers are getting better at collaborating with AI; stagnant or declining rates signal prompt fatigue or poor context retrieval.
Suggestion Acceptance Rate
Break down what engineers do with AI suggestions: accepted as-is, modified, or rejected. Healthy distribution at scale: 50-60% accepted, 25-35% modified, 10-15% rejected. Watch for 80%+ acceptance with rising incident rates, engineers may be rubber-stamping AI output without critical review.
CodeAnt auto-instruments these via IDE telemetry, no manual Git hooks or developer self-reporting required. The platform aggregates signals from all AI sources (Copilot, Cursor, Qodo) into unified metrics, eliminating multi-tool attribution problems.
Pillar 2: Velocity Gains Without Quality Trade-Offs
Speed only matters if you're not accumulating technical debt. Track cycle time improvements alongside quality guardrails.
PR Cycle Time Delta
Compare 3-month pre-rollout baseline to post-rollout (target 15-25% reduction). Watch for initial dip in weeks 1-4 as engineers learn prompting, then acceleration in weeks 5-12. If cycle time stays flat or regresses after 90 days, diagnose whether the issue is context quality or over-reliance without validation.
Review Speed
Time from PR open to first review and final merge. AI pre-review should enable sub-24-hour targets. CodeAnt's pre-review layer catches 80% of mechanical issues (formatting, linting, basic security patterns) before human reviewers engage, letting them focus on architecture and logic.
Rework Percentage
Lines modified post-review as a fraction of total PR size. Healthy rework stays under 15%; above 30% indicates AI is producing plausible-but-wrong code that passes initial review but fails in real-world use.
Pre-Review Fix Rate
Percentage of issues caught by AI before human reviewers see the PR. This is your leading indicator of AI maturity, rising pre-review fix rates mean engineers trust AI suggestions and incorporate them into their workflow. CodeAnt averages 80%+ on security, quality, and standards violations.
Critical warning: Avoid AI LOC inflation. More code doesn't equal more value. Track test coverage per LOC, cyclomatic complexity per function, and code churn rate to ensure velocity isn't masking quality erosion.
Pillar 3: Quality & Security Signals
AI-assisted code introduces new risk vectors, hallucinations, phantom imports, API mismatches. Track these explicitly.
Defect Density Delta
Compare bug rates in AI-assisted vs. non-AI commits. Should be neutral or better. If defect density rises 10%+ in AI-assisted commits, pause rollout and improve context models or prompt training.
AI-Touched Security Findings
Vulnerabilities introduced in AI-assisted commits, tracked separately from human-written code. Monitor OWASP Top 10 violations, secrets exposure, and dependency risks. If 60% of security findings come from AI-assisted PRs representing only 40% of commits, you have a prompt engineering or model selection problem.
Complexity Trend
Track cyclomatic complexity and maintainability index over time. AI tools often generate verbose, repetitive implementations that violate DRY principles. Rising complexity on AI-assisted files signals quality debt accumulation.
AI Confidence Score
CodeAnt's proprietary metric flags low-confidence suggestions for extra human scrutiny. Suggestions below 70% confidence trigger automatic review gates, preventing low-quality AI output from consuming reviewer bandwidth.
Post-2025 SOC 2 and ISO 42001 frameworks require audit trails for AI decision provenance. CodeAnt logs which suggestions were accepted, modified, or rejected—compliance-ready out of the box.
Pillar 4: Business Impact
Connect technical metrics to outcomes executives care about: delivery predictability, cost per feature, revenue velocity.
Deployment Frequency
DORA metric, AI should enable more frequent, smaller releases. If cycle time drops 20% but deployment frequency stays flat, you're optimizing the wrong bottleneck.
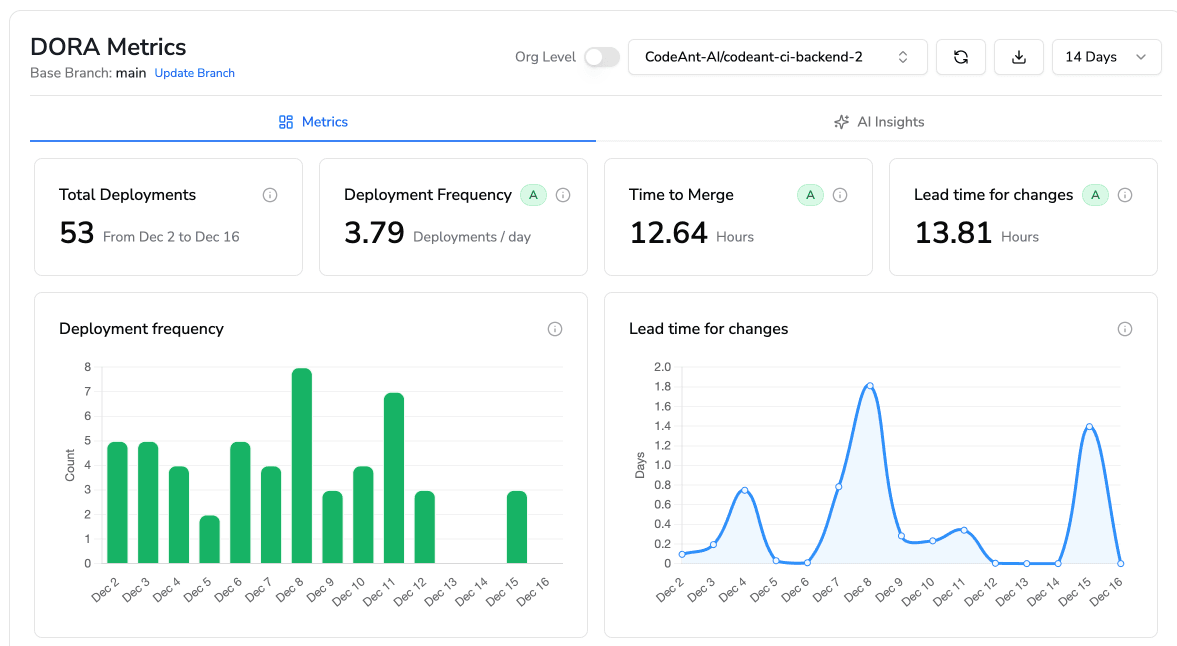
Change Failure Rate
Percentage of deployments causing incidents. Should remain stable or improve. Rising CFR despite faster cycle time means you're trading speed for reliability.
Mean Time to Recovery (MTTR)
AI-assisted debugging should shorten incident resolution. Track time from incident detection to root-cause identification. Teams using CodeAnt's AI-powered incident correlation see 40-60% MTTR reduction on P1/P2 issues.
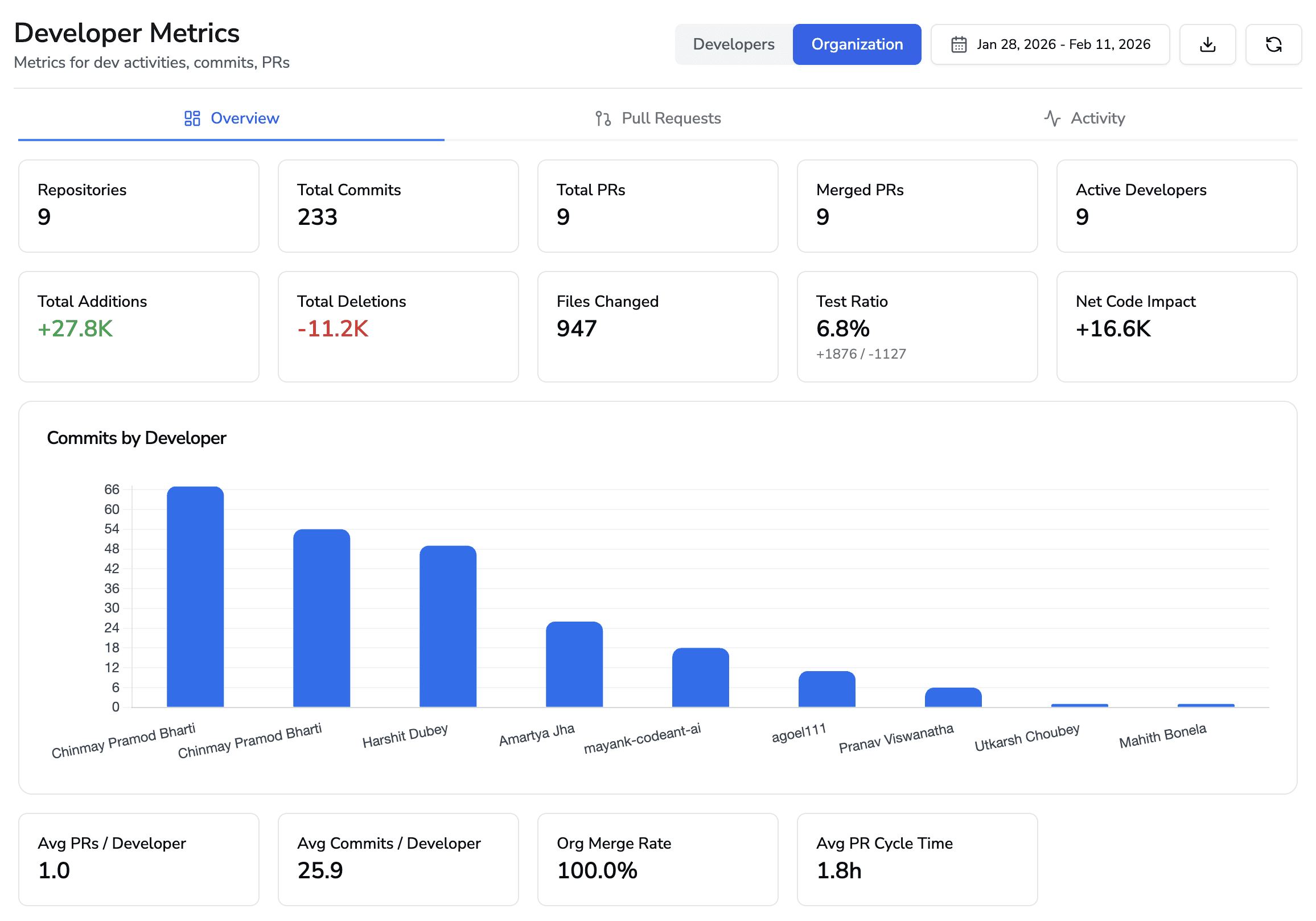
Cost per Commit
Engineering hours divided by commits shipped. Captures efficiency gains beyond raw throughput. Calculate as:

Cost savings = time savings × fully-loaded engineer cost ($85/hr for $175K engineer)
Conservative quarterly ROI for 50-engineer team: $108K-$435K in time savings.
Hidden ROI: The highest-value AI use cases, debugging assistance, codebase comprehension, requirements clarification, don't produce "more lines of code." CodeAnt's Context Fetch Time metric quantifies hours saved understanding legacy code, a capability competitors don't track.
Measuring Non-Code Value
The most transformative AI-assisted workflows don't produce more lines of code, they produce better decisions, faster comprehension, and shorter paths to resolution. When your senior engineer uses AI to trace a race condition through six microservices in 20 minutes instead of three hours, that's real ROI. But it won't show up in your commit velocity dashboard.
Context Fetch Time (CFT)
Measures how long it takes an engineer to locate the relevant code, documentation, or ownership information needed to complete a task. Baseline without AI: seniors average 15-25 minutes per context fetch; juniors 45-90 minutes. AI-assisted target: sub-5-minute CFT for 80% of queries.
CodeAnt tracks CFT through its context engine, which aggregates IDE telemetry, codebase graph analysis, and historical change patterns. When an engineer asks "where is rate limiting implemented," the platform measures time-to-answer and correlates it with subsequent code quality.
Mean Time to Resolve (MTTR) on Incidents
AI accelerates root-cause analysis by correlating error patterns across logs, metrics, and recent deployments; suggesting likely culprit commits based on stack traces; and generating hypotheses for edge cases or race conditions.
Track MTTR delta between AI-assisted and non-AI incidents over rolling 30-day windows. The difference isn't that AI writes the fix—it's that AI eliminates the "needle in a haystack" debugging phase.
Onboarding Velocity
AI compresses the 3-6 week "learning the codebase" phase dramatically. Track:
Time-to-First-Merged-PR: Days to first PR that touches core business logic with >80% test coverage (target: 21-30 days vs. 45-60 traditional)
Skill Progression: Monitor whether AI dependency ratio (% commits where AI contributed >50% of code) declines from 70-80% in month one to 30-40% by month six
Review Iteration Count: Should average 1.5-2 rounds for AI-assisted junior PRs, down from 2.5-3 baseline
Requirements Analysis Impact
AI's role in requirements analysis, turning ambiguous product asks into crisp acceptance criteria, edge cases, and API contracts, saves weeks of rework but looks like "slower" initial velocity. Track:
Requirements Iteration Count: Cycles between product and engineering before implementation starts (target: 2 vs. 5 without AI)
Post-Launch Requirement Defects: Issues filed as "not what we asked for" within 30 days of release (target: 35% reduction)
Design Doc Completeness: Percentage including error handling, performance considerations, rollback plans (target: 80% vs. 40% baseline)
Stage Gates: When to Scale Your AI Rollout
Knowing your KPIs is only half the equation, the other half is knowing when those metrics signal you're ready to expand.
Stage 1: Pilot Success Criteria (Weeks 1-8, 10-20 engineers)
Don't expand until you hit these thresholds:
Adoption Stability:
AI-Assisted Commit % ≥ 40% for two consecutive sprints
Prompt→Commit Success Rate ≥ 60%
Week-over-week variance in AI usage < 15%
Quality Baseline:
Defect Density Delta ≤ 0% (AI commits introduce no more bugs than human-written)
Rework Percentage < 20%
Security Finding Escape Rate unchanged or improved
Velocity Signal:
PR Review Speed improvement ≥ 15%
Context Fetch Time reduction ≥ 25%
CodeAnt's Rollout Maturity Model tracks these thresholds automatically, surfacing a "Pilot Readiness Score" that aggregates adoption, quality, and velocity signals into a single go/no-go indicator.
Stage 2: Team-Level Expansion (Months 3-6, 50-100 engineers)
Expand to 2-3 additional teams once pilot proves sustainable:
Pilot team maintains ≥ 50% AI-Assisted Commit % for 4 weeks post-expansion
New teams reach ≥ 30% AI-Assisted Commit % within 2 sprints
Variance in Defect Density across teams < 10%
Decision Logic for Conflicting Metrics:
Velocity Trend | Quality Trend | Action |
PR Speed ↑ 20% | Defect Density ↓ 10% | Proceed to org-wide rollout |
Cycle Time ↓ 25% | Rework % ↑ 30% | Pause; enable AI Confidence Score filtering |
PR Speed ↑ 15% | Defect Density unchanged | Continue; quality gains lag velocity by 1-2 sprints |
Cycle Time unchanged | AI-Assisted % < 25% | Diagnose prompt quality and training gaps |
Stage 3: Org-Wide Scaling (Months 7+, 100+ engineers)
Expanding beyond 100 engineers introduces compliance and governance requirements:
Consistent Quality Across 80%+ of Teams (defect density variance < 15%)
Audit Trail Completeness: 100% of AI-assisted commits tagged with contribution lineage
Anomaly Detection Active: Real-time alerts when AI usage correlates with quality regressions
CodeAnt's Anomaly Detection monitors rolling 2-week windows for AI-touched security finding spikes (≥20%), complexity trend reversals, and test coverage declines in AI-heavy modules. When anomalies trigger, the platform surfaces specific files, engineers, or suggestion types driving the regression.
Avoid the Premature Scale Trap: If week-over-week AI usage variance exceeds 10%, you're still in the "novelty phase." Scaling now creates org-wide confusion as some teams embrace AI while others ignore it.
Implementation: Instrument KPIs Without Creating Metric Debt
Define Your Metric Dictionary
Create a shared vocabulary before instrumenting anything:
AI-Assisted Commit %: Commits where AI generated ≥30% of the diff
Prompt→Commit Success Rate: Percentage of AI suggestions accepted without modification
Pre-Review Fix Rate: Issues caught by AI review before human eyes see the PR
Context Fetch Time: Average time engineers spend locating relevant code/docs
CodeAnt auto-generates a metric dictionary based on your Git provider, CI system, and issue tracker integrations, with calculation logic and data provenance for every metric.
Establish Cohorts to Isolate AI Impact
Define cohorts that let you isolate variables:
Pilot vs. Control Teams: 10-20 engineers using AI vs. matched teams without
AI-Assisted vs. Human-Only Commits: Tag commits by authorship method
Time-Based Cohorts: Pre-rollout baseline (3-6 months before AI) vs. post-rollout windows
Complexity Cohorts: Greenfield features vs. legacy refactors vs. bug fixes
Avoid tracking "all engineers" as a single group, aggregated metrics hide adoption patterns and quality signals.
Connect Systems to Build Unified Pipeline
AI rollout KPIs span Git providers, CI pipelines, issue trackers, security scanners, and IDE telemetry. CodeAnt provides native connectors for 15+ platforms, automatically correlating Git commits with CI results, issue tracker tickets, and security findings, no custom ETL required.
The platform tracks AI contribution metadata from multiple IDE tools (Copilot, Cursor, Qodo) simultaneously, solving the multi-tool attribution problem.
Set Reporting Cadence
Establish a two-tier reporting rhythm:
Weekly Rollout Dashboard (for engineering leads):
AI adoption rate by team
Prompt→Commit success rate trend
Pre-review fix rate
Anomaly alerts
Monthly Executive Readout (for VPs/C-suite):
Cycle time delta (before/after AI rollout)
Defect density comparison
Developer productivity index
ROI projection (time saved × avg engineer cost)
CodeAnt's alerting engine enforces escalation policies automatically and generates executive-ready summaries that translate technical KPIs into business impact.
Conclusion: Your Rollout-Ready Scorecard
Successful AI code review rollouts don't happen by accident, they're built on deliberate measurement. Start your pilot with 3 adoption KPIs (tool engagement, commit percentage, prompt success rate), 2 velocity KPIs (review cycle time, pre-review fix rate), and 2 quality KPIs (defect density delta, security finding resolution time).
Establish baselines before rollout, run weekly dashboards with cohort comparisons, and set explicit stage gates before you scale beyond the pilot team. Most importantly, instrument the workflows where AI delivers invisible ROI, context retrieval, debugging, onboarding, requirements analysis, because that's where 60% of the value lives.
The challenge most teams face isn't measuring AI code review, it's doing it without metric fragmentation across tools, retroactive baseline gaps, and missing AI-specific quality signals. CodeAnt AI eliminates this complexity by unifying adoption tracking, velocity metrics, security/quality KPIs, and compliance-grade audit trails in a single platform.
Ready to measure what matters?Start your 14-day free trial and get your rollout scorecard running in under 10 minutes, no credit card required.
FAQs
How do I detect which code was AI-assisted vs. human-written?
Can I establish baselines if my AI rollout has already started?
How do I prevent teams from gaming AI adoption metrics?
What if velocity improves but defects increase?
How do I measure impact when using multiple AI tools simultaneously?













