AI Code Review
The Cognitive Load Problem in Code Reviews: Why Diffs Are Not Enough

Sonali Sood

Founding GTM, CodeAnt AI
You're staring at a 400-line diff, and somewhere around line 150, you realize you've already forgotten what the first file was doing. That's not a focus problem, it's a fundamental constraint of how human memory works.
Diffs show you what changed, but they hide almost everything else: the intent behind the change, the dependencies it affects, and the context you'd naturally have if you wrote the code yourself. This article breaks down why traditional diff-based reviews overwhelm developers, what cognitive load actually costs your team, and how AI-augmented workflows can bridge the gap.
What Is Cognitive Load in Code Reviews
Code reviews are essential for software quality, but the standard diff often fails to give reviewers enough context to understand what's actually happening. You're looking at changed lines in isolation, mentally piecing together how they fit into the broader system. That process is inefficient and error-prone.
Two concepts matter here:
Cognitive load: the mental effort your brain spends understanding, evaluating, and remembering code changes
Working memory: the limited mental space where you hold context while reading a diff
Your working memory holds roughly four to seven items at once. When a diff exceeds that capacity, you start forgetting earlier details, missing connections, and making mistakes. This isn't about skill or experience, it's a fundamental human constraint that affects every reviewer.
Types of Cognitive Load That Affect Reviewers
Cognitive load theory breaks mental effort into three types. Each one shows up differently during code review, and recognizing them helps you understand where reviews break down.
Intrinsic Load from Code Complexity
Intrinsic load comes from the code itself. Nested conditionals, unfamiliar algorithms, and deep inheritance hierarchies demand mental effort no matter how well they're presented. Some problems are genuinely hard, and that difficulty doesn't disappear just because the diff is clean.
Extraneous Load from Poor Tooling and Process
Extraneous load is the unnecessary burden added by bad tooling, unclear PR descriptions, and missing context. This type of load has nothing to do with the actual code. Standard diffs contribute heavily here because they strip away the surrounding context you'd naturally have while writing the code yourself.
Germane Load and Building Mental Models
Germane load is the productive effort spent forming understanding. When you build an accurate mental model of how code works, that's a germane load at work. Good reviews help you develop accurate mental models. Bad reviews waste effort on distractions instead.
Why Diff-Based Reviews Overwhelm Developers
Diffs are powerful for comparison but poor for understanding. They present a low-level view that requires significant mental effort to elevate into a complete picture of what actually changed and why.
Working Memory Limits and Large Changesets
A 500-line diff doesn't just take longer to review. It fundamentally exceeds what your brain can process coherently. Reviewers catch fewer defects per line as PR size increases, and after a few hundred lines, effectiveness drops sharply. The math works against you.
Context Switching Between Pull Requests
Jumping between PRs forces mental resets. Each switch costs cognitive resources as you rebuild context from scratch. If you're reviewing five PRs in a morning, you're paying that tax five times, and each review suffers for it.
The Knowledge Gap Between Author and Reviewer
The author spent hours or days building context. The reviewer sees only the diff. This asymmetry creates strain because reviewers reconstruct intent from fragments while authors wonder why obvious things get questioned. Neither side is wrong—the tooling just doesn't bridge the gap.
Pattern Recognition Failures in Unfamiliar Code
Experienced reviewers rely on recognizing familiar patterns. "This looks like a factory." "That's a retry loop." Unfamiliar codebases or unconventional styles disrupt pattern recognition, forcing slower, more deliberate processing that drains cognitive resources faster.
The Context Missing from Standard Diffs
Diffs show what changed but hide almost everything else. Here's what reviewers typically lack when they open a pull request.
Business Logic and Intent
Why did this change happen? Diffs rarely answer that question. Reviewers deduce purpose from commit messages or external communication, and both are often incomplete or ambiguous. The what is visible; the why is not.
Hidden Dependencies Across Files
A change in one file may affect behavior elsewhere. Standard diffs don't visualize relationships between files, so reviewers manually trace dependencies or miss them entirely. Cross-file impact is invisible by default.
Historical Context and Related Changes
Reviewers don't see previous iterations, related PRs, or how the code evolved over time. They review in isolation, missing patterns that would be obvious with historical context. Every PR looks like it appeared from nowhere.
Security and Performance Implications
Diffs don't flag potential vulnerabilities or performance regressions automatically. Catching security issues or performance problems requires specialized knowledge and deliberate attention, both of which are scarce resources during review.
How Cognitive Overload Impacts Review Quality
When cognitive load exceeds capacity, review quality suffers in predictable ways. The effects compound over time and across teams.
Increased Defect Escape Rates
Overwhelmed reviewers miss bugs. Defect detection rates drop when reviewers face large, complex changesets. The bugs that escape are often the subtle ones—exactly the kind reviews are supposed to catch.
Superficial Reviews and Rubber-Stamping
When overloaded, reviewers skim and approve without deep analysis. Rubber-stamping—approving without meaningful review—becomes the path of least resistance. The review process continues, but the value disappears.
Reviewer Burnout and Team Bottlenecks
Chronic overload leads to fatigue. Senior reviewers become bottlenecks when they're the only ones who can handle complex PRs. Meanwhile, they're drowning in review requests and falling behind on their own work.
Longer Cycle Times and Technical Debt
Slow reviews delay releases. Missed issues accumulate as technical debt that compounds over time. What starts as cognitive overload becomes organizational drag that affects everyone.
Strategies to Reduce Cognitive Load in Code Reviews
You can reduce cognitive burden with process changes that don't require new tools. Here are five approaches that work.
Keep Pull Requests Small and Focused
Smaller PRs reduce the information reviewers hold in working memory at once. Aim for PRs that address a single logical change—something a reviewer can understand in one sitting without losing track of earlier details.
Write Descriptive Summaries and Commit Messages
Good descriptions reduce the knowledge gap between author and reviewer. Explain the problem, the approach, and any non-obvious decisions. A few sentences of context save minutes of confusion later.
Use Review Checklists to Guide Focus
Checklists offload memory. Reviewers don't have to remember what to check—they follow the list. This frees cognitive resources for deeper analysis of the actual code.
Establish Clear Code Standards
Consistent standards reduce extraneous load by making code predictable. When everyone follows the same patterns, reviewers spend less effort parsing unfamiliar styles and more effort evaluating logic.
Rotate Reviewers to Distribute Cognitive Burden
Spreading reviews prevents burnout and builds broader codebase familiarity across the team. Rotation also catches issues that a single reviewer might consistently miss due to blind spots.
How AI and Automation Augment Traditional Diffs
Process improvements help, but they don't solve the fundamental limitation: diffs lack context. AI-powered tools address this gap directly by adding information that diffs can't provide on their own.
AI-Generated Change Summaries
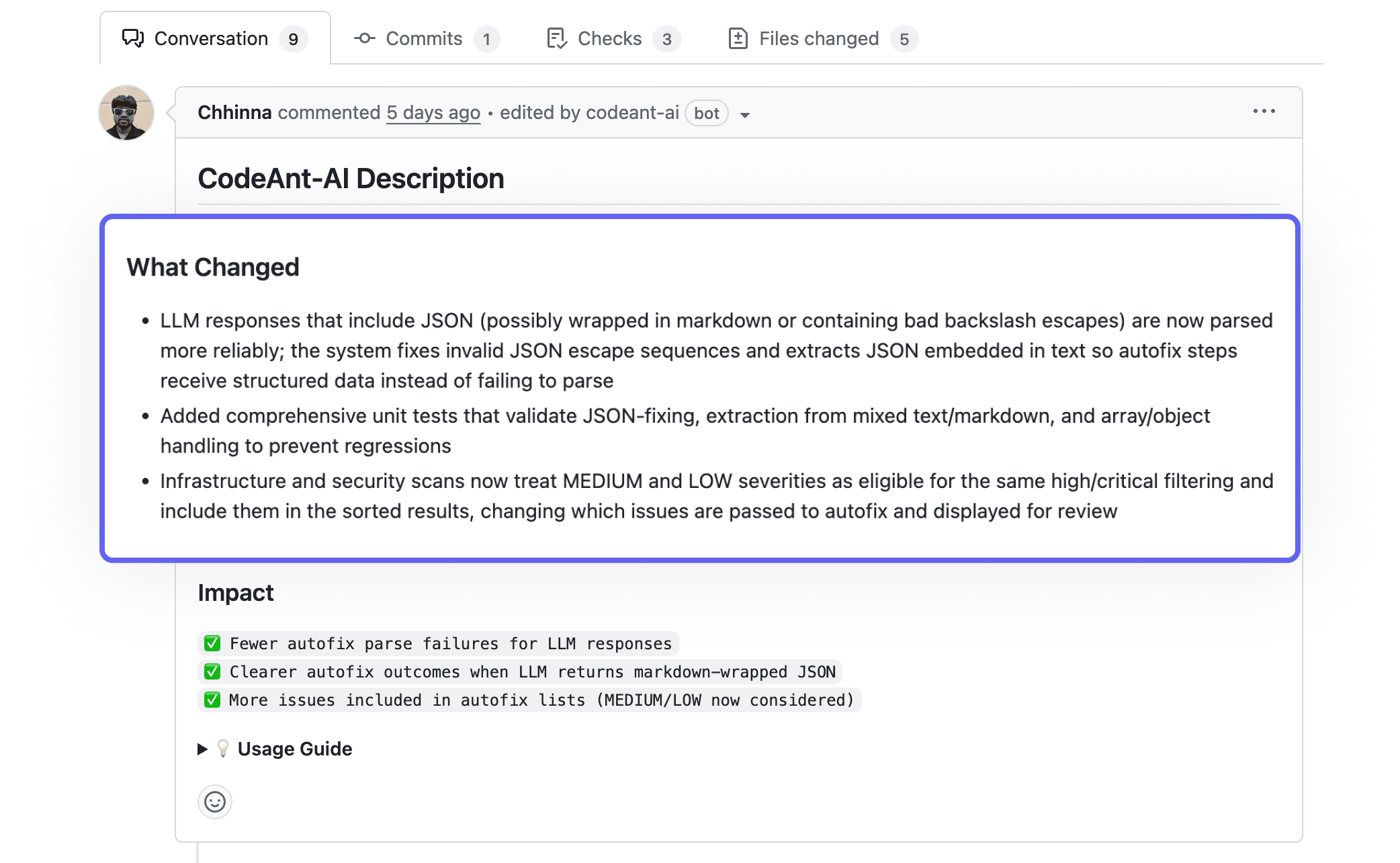
AI can synthesize PR changes into plain-language summaries, reducing the effort to understand intent. CodeAnt AI automatically generates summaries for every pull request, giving reviewers a high-signal overview before they dive into the diff.
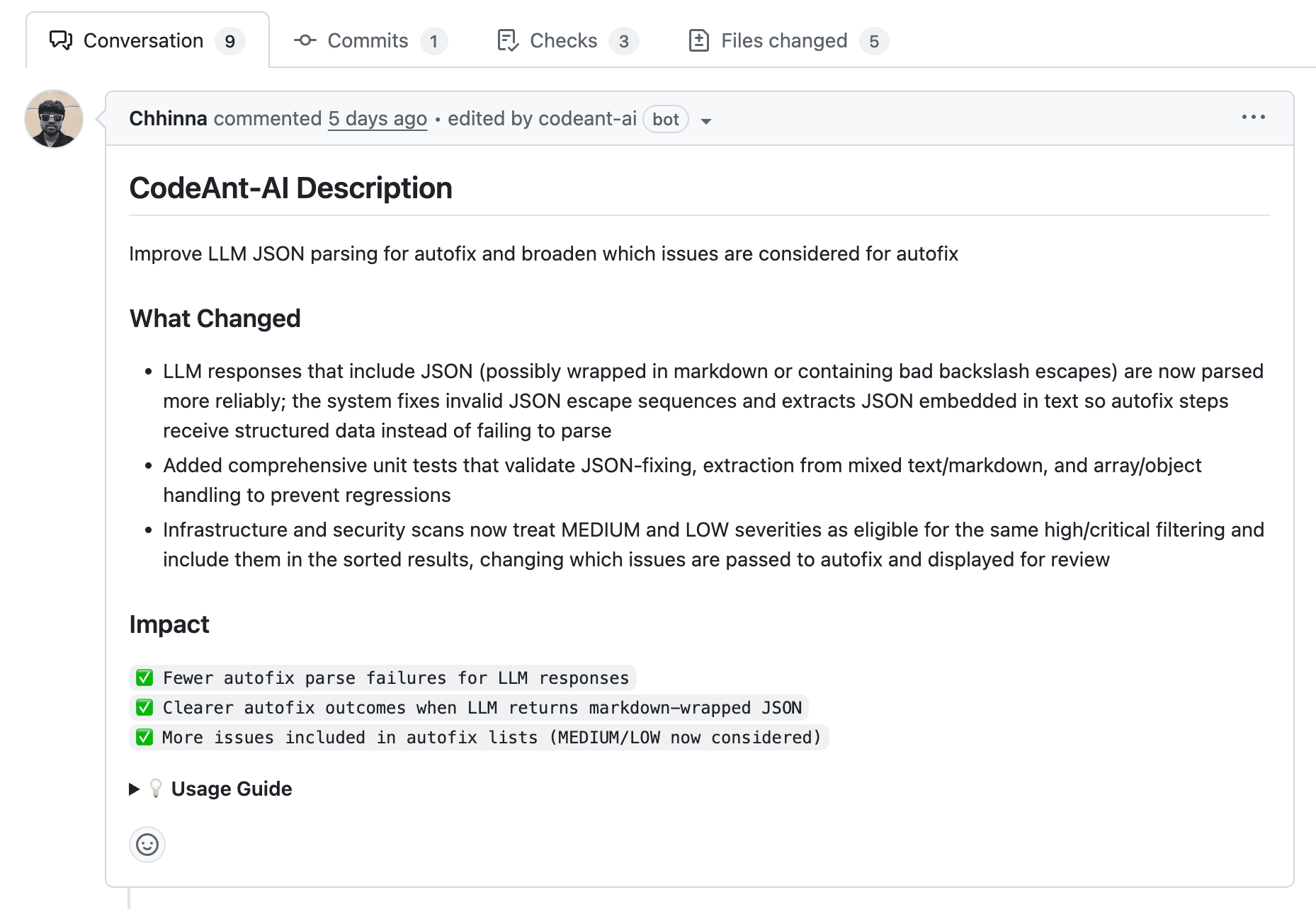
Automated Security and Quality Checks
Static analysis and SAST (Static Application Security Testing) tools flag issues before human review begins. This reduces what reviewers catch manually, letting them focus on logic and design rather than syntax and known vulnerability patterns.
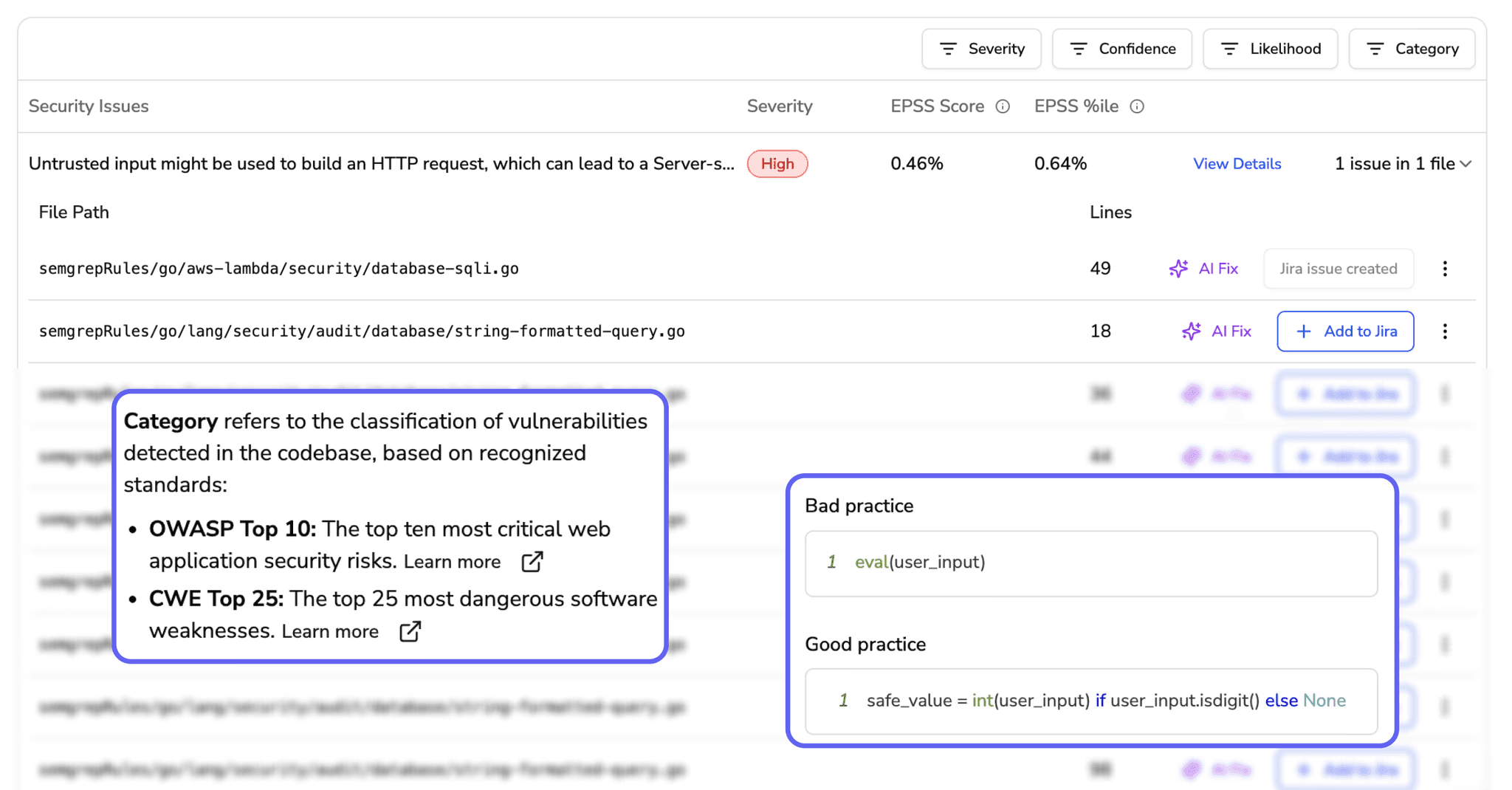
Contextual Code Explanations
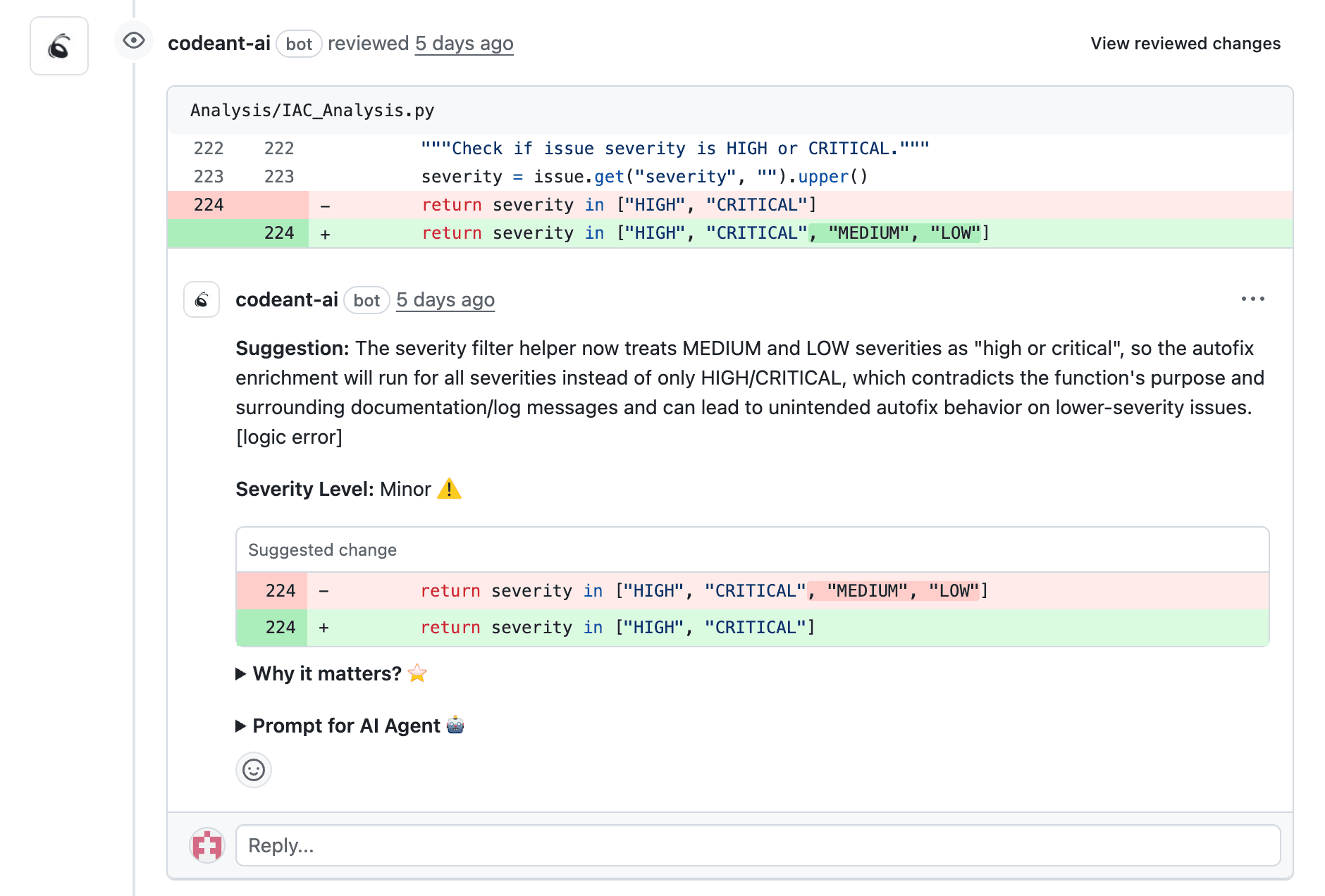
AI can explain unfamiliar code patterns or highlight why a change matters. This bridges the knowledge gap between author and reviewer without requiring lengthy documentation that nobody writes anyway.
Suggested Fixes That Reduce Back-and-Forth
AI-suggested fixes let reviewers approve improvements instantly. Instead of writing a comment, waiting for updates, and reviewing again, reviewers accept a fix in one click. The feedback loop shrinks from hours to seconds.
Capability | Traditional Diffs | AI-Augmented Reviews |
Change summary | Manual | Auto-generated |
Security scanning | Separate tool | Integrated |
Context explanation | None | AI-provided |
Fix suggestions | Comment only | One-click apply |
For every PR, CodeAnt AI generates sequence diagrams that capture the core runtime flow introduced or modified by the change. Reviewers get a one-shot, high-signal glance at what the PR actually does—which modules interact, in what order, and where the key decision points happen—without mentally simulating the code across multiple files.
Metrics That Reveal Cognitive Load Problems
How do you know if your team suffers from cognitive overload? Four metrics provide signals worth tracking.

Review Time per Lines of Code
Unusually long review times relative to PR size suggest cognitive strain. If small PRs take as long as large ones, something's wrong with the process or tooling.
Defect Escape Rate Post-Merge
High escape rates indicate reviewers are missing issues. Track bugs found in production that review could have caught—this is often a sign of overload.
Reviewer Comment Density
Very low comment density may signal rubber-stamping. Very high density may indicate unclear code or process issues. Neither extreme is healthy.
PR Pickup Time and Queue Depth
Long queues and slow pickup times suggest reviewers are overwhelmed or avoiding complex PRs. Monitor queue depth to spot bottlenecks before they become crises.
How to Build a Review Workflow Beyond Diffs
Diffs are a starting point, not the whole solution. Modern review workflows combine human judgment with automated assistance:
Integrate AI-driven code review tools into your existing Git workflow
Automate security and quality gates so reviewers focus on logic and design
Track code review metrics to identify cognitive load hotspots
Adopt a unified code health platform that combines review, security, and quality in one view
The goal isn't to replace human reviewers. It's to reduce the cognitive burden so they can focus on what matters: understanding intent, evaluating design decisions, and catching the subtle issues that automation misses.
If you are fucked up with this cognitive load shit in your code reviews, we recommend you trying out CodeAnt.ai. Your nervous system will thank you a lot. To know more, check out our product at app.CodeAnt.ai or to get a deep divebook your 1:1 with our experts today!
FAQs
What is the ideal pull request size to minimize cognitive load?
How long can a reviewer stay effective before fatigue sets in?
Can pair programming replace code reviews to reduce cognitive load?
How do you train new developers to review code without overwhelming them?
What is cognitive load in code reviews?













