AI Code Review
What Makes an AI Code Review Finding Trustworthy

Sonali Sood

Founding GTM, CodeAnt AI
AI code review tools promised to reduce review load, catch more bugs, and move teams faster.
In practice, most of them failed to earn trust.
Not because the models were weak, but because the output wasn’t auditable.
Most AI reviewers behave like a second developer in the PR:
they generate many suggestions
few are prioritized
some are impossible to prove
reviewers still have to manually validate everything
The result is predictable: review fatigue, slower merges, and eventual tool abandonment.
At CodeAnt AI, we took a different approach.
Instead of producing opinions, our AI is designed to emit testable engineering statements, the same kind senior engineers expect when deciding whether to block or approve a change.
This is what we call evidence-first AI code review.
From “AI Suggestions” to Quality Gates
A useful code review system does not just suggest improvements. It answers four questions reviewers ask instinctively:
How risky is this?
What breaks if we ship it?
Can I prove this issue exists?
How exactly does the bug propagate through the system?
To answer those questions consistently, every finding we generate includes four primitives:
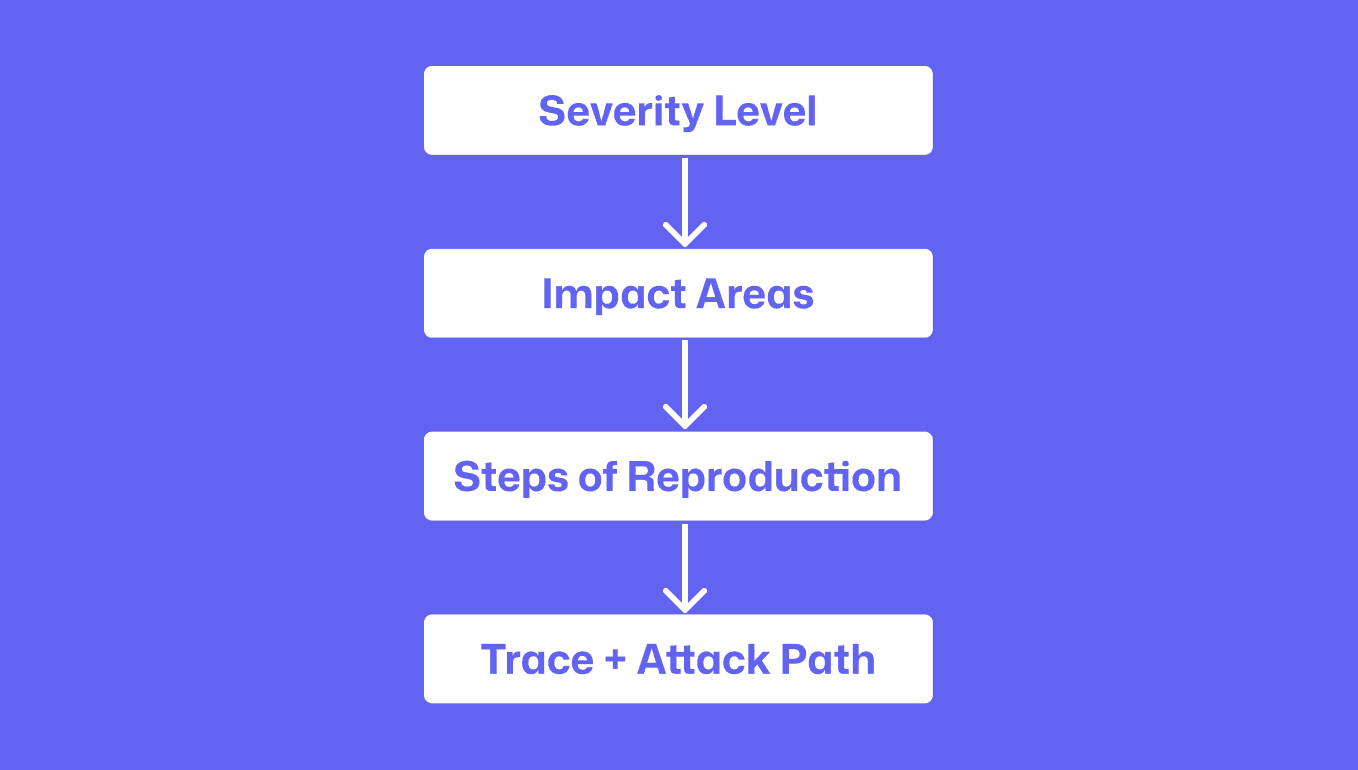
Severity Level: urgency and risk
Impact Areas: consequence and blast radius
Steps of Reproduction: proof, not guesswork
Trace + Attack Path: how the bug flows and amplifies
Together, they turn AI output from claims into engineering-grade evidence.
1. Severity Level: Risk Compressed into a Decision Signal
Severity is not a label. It is a compressed risk score derived from multiple dimensions:
likelihood of failure
blast radius
runtime, user, or security impact
detection difficulty (silent vs loud failures)
cost of inaction (incidents, regressions, compute burn)
Severity levels used in reviews
Critical: Security exposure, tenant boundary violations, data corruption, outages
Major: Silent incorrectness, consumer-facing bugs, broken contracts, wrong outputs
Minor: Maintainability issues, refactors, low-risk cleanup
Severity tells reviewers how urgently they must act, but on its own, it’s never enough.
2. Impact Areas: Why Severity Is Never Shown Alone
A “Major” issue without context creates debate, not clarity. That’s why every finding is also tagged with impact areas, the category of failure it represents.
Common impact areas surfaced in reviews
Consumer-Facing API Behavior: Contract mismatches, wrong responses, unexpected payloads
Correctness / Business Logic: Ignored filters, missing validation, wrong rules
Security: Authorization bypasses, tenant isolation failures, token leakage
Reliability: Retry loops, duplicate side effects, cleanup gaps, race conditions
Performance & Cost: Full scans, hot-path DB spikes, unbounded loops
Observability: Missing logs, swallowed exceptions, invisible failures
Impact areas explain what kind of damage this issue causes, making severity defensible and actionable.
3. Steps of Reproduction: Proof Instead of Opinion
Trust collapses when engineers cannot reproduce a finding. Every high-confidence issue includes explicit reproduction steps, a deterministic checklist that proves the bug exists.
A strong reproduction block contains
the entry point (API route, job, event consumer)
the trigger condition (payload, headers, flags)
control-flow evidence (where input is ignored or misrouted)
observable outputs (responses, logs, artifacts)
expected vs actual behavior
verification steps after the fix
This removes guesswork and replaces debate with validation.
4. Trace + Attack Path: The Missing Trust Layer in AI Reviews
This is the most important element, and the one most AI tools skip. Instead of explaining what is wrong, we show how the bug travels through the system.
“Here is the exact execution path.
Here is where input should have influenced behavior.
Here is where it didn’t.
And here is what the system outputs as a result.”
What Trace + Attack Path includes
Entry point (API / event / CLI)
Request parsing and DTO extraction
Validation that exists vs validation that’s missing
Downstream calls and service boundaries
The precise point where the contract breaks
Final observable output
Abuse or amplification logic (attack path)
This is not limited to security. It applies equally to correctness, cost, and reliability failures.
Example: API Contract Violation with Cost Amplification
Trace (runtime flow)
POST /scanreceives requesthandler parses
files_to_includescanning pipeline invoked
filters never passed to scanning functions
scanner traverses entire repository
response returns success but violates request contract
Attack path
caller submits narrow scans but forces full scans repeatedly
compute costs amplify
results include unintended files
trust in API behavior erodes
This is not hypothetical, it is provable behavior.
5. What It Takes to Build Evidence-First Reviews
Generating these outputs requires more than a prompt.
Inputs the AI must reason over
PR diffs
repository call graphs and dependency graphs
execution semantics (side effects, retries, IO)
API contracts
domain-specific rules
runtime assumptions (CI, infra, cost models)
Deterministic processing stages
Parse + Index: Identify entry points, handlers, and edited symbols
Flow Tracing: Follow execution paths and detect broken propagation
Risk Pattern Detection: Silent failures, retries with side effects, missing auth, full scans
Impact Area Tagging: Map issues to correctness, security, reliability, cost, observability
Severity Scoring: Weighted by blast radius, detectability, likelihood, exposure
Reproduction + Trace Synthesis: Minimal triggers, runtime flow, and amplification logic
This structure is what makes the output auditable.
Why Trace + Reproduction Changes Adoption
Without trace, engineers ask:
“Is this actually reachable?”
“Is this theoretical?”
“Where exactly does it break?”
With trace and repro, they see:
entry point → downstream calls → failure point
expected vs actual behavior
a two-step way to confirm the bug
a clear signal when the fix works
The conversation shifts from:
❌ “Is the AI right?”
to
✅ “This fix is valid.”
That is the difference between noise and signal.
The Trust Stack (What Makes AI Reviews Usable)
Evidence-first AI reviews work because they stack trust in layers:
Severity → prioritization
Impact Areas → consequence clarity
Reproduction Steps → verification
Trace + Attack Path → propagation proof
Together, they deliver:
fewer false positives
faster reviews
less debate
measurable confidence
outputs engineers can audit
Conclusion: AI Reviews Only Work When They Are Verifiable
AI code reviews fail when they behave like opinionated teammates. They succeed when they behave like quality gates. By grounding every finding in severity, impact, reproduction, and trace, evidence-first AI reviews turn automated analysis into decisions engineers can trust, without slowing teams down or adding cognitive load.
If your team wants AI reviews that reduce risk instead of creating debate, the standard has to change. Stop reviewing claims. Start reviewing evidence.
👉 See how CodeAnt.AI turns AI findings into verifiable engineering decisions by learning directly from our experts.
FAQs
How is evidence-first AI code review different from traditional AI reviewers?
Why is severity alone not enough in code reviews?
What makes steps of reproduction critical for AI findings?
How does trace help engineers trust AI code reviews?
Are attack paths only relevant for security issues?













