Code Security
Why Rule-Based SAST Can't Survive the Age of AI-Generated Code

Sonali Sood

Founding GTM, CodeAnt AI
The era of rule-based static analysis is ending.
With AI now generating nearly half of all production code, and 45% of that code containing security vulnerabilities, the tools enterprises have relied on for two decades are structurally incapable of keeping pace.
Claude Code Security's February 2026 launch validated what the industry already suspected: AI-native code security isn't a feature upgrade. It's a category replacement.
The Industry Inflection Point: AI-Generated Code Has Rewritten the Threat Model
The statistics are stark.
Dario Amodei, CEO of Anthropic, expects AI to write 90% of all code within months. GitHub Copilot already serves over 20 million developers, and 90% of Fortune 100 companies use it. Jellyfish data shows AI code review agent adoption surged from 14.8% in January to 51.4% by October 2025.
Almost half of companies now have at least 50% AI-generated code in their repositories, up from 20% at the start of 2025.
This velocity creates security problems that compound at machine speed.
OX Security's "Army of Juniors" report captures the dynamic precisely: AI-generated code isn't necessarily more vulnerable per line, but software that once took months to build can now be completed and deployed in days. Apiiro's research found 322% more privilege escalation paths and a 153% increase in architectural flaws in AI-assisted codebases.
When developers generate complete functions with AI, they review for "does this do what I want?" not "is this secure?" That cognitive gap, multiplied by AI's production velocity, creates risks that static rules cannot see.
The vulnerability patterns are distinctive
Veracode found that large language models make insecure choices in nearly half of coding tasks, with Java failing at rates above 70%.
AI-generated code commonly introduces:
Missing input sanitization
Hardcoded secrets
Insecure default configurations (like CORS policies allowing all origins)
"Slopsquatting" where AI suggests packages that don't exist, creating supply chain attack vectors
Veracode also found 86% of AI-generated code failed to defend against XSS and 88% was vulnerable to log injection. These aren't edge cases. They're systematic failures baked into how language models generate code.
The application security testing market, now valued at $5.1 billion, stands at an inflection point, where pattern-matching gives way to semantic reasoning.
Why Rule-Based SAST is Structurally Limited
To understand why traditional tools fail here, you need to understand their architecture.
Rule-based SAST works by parsing code into Abstract Syntax Trees, Control Flow Graphs, and Data Flow Graphs, then applying predefined rules that match against known insecure patterns. A SQL injection rule looks for unsanitized user input flowing into database queries. An XSS rule looks for unescaped output in HTML contexts.
This approach has three fatal constraints in the AI era.
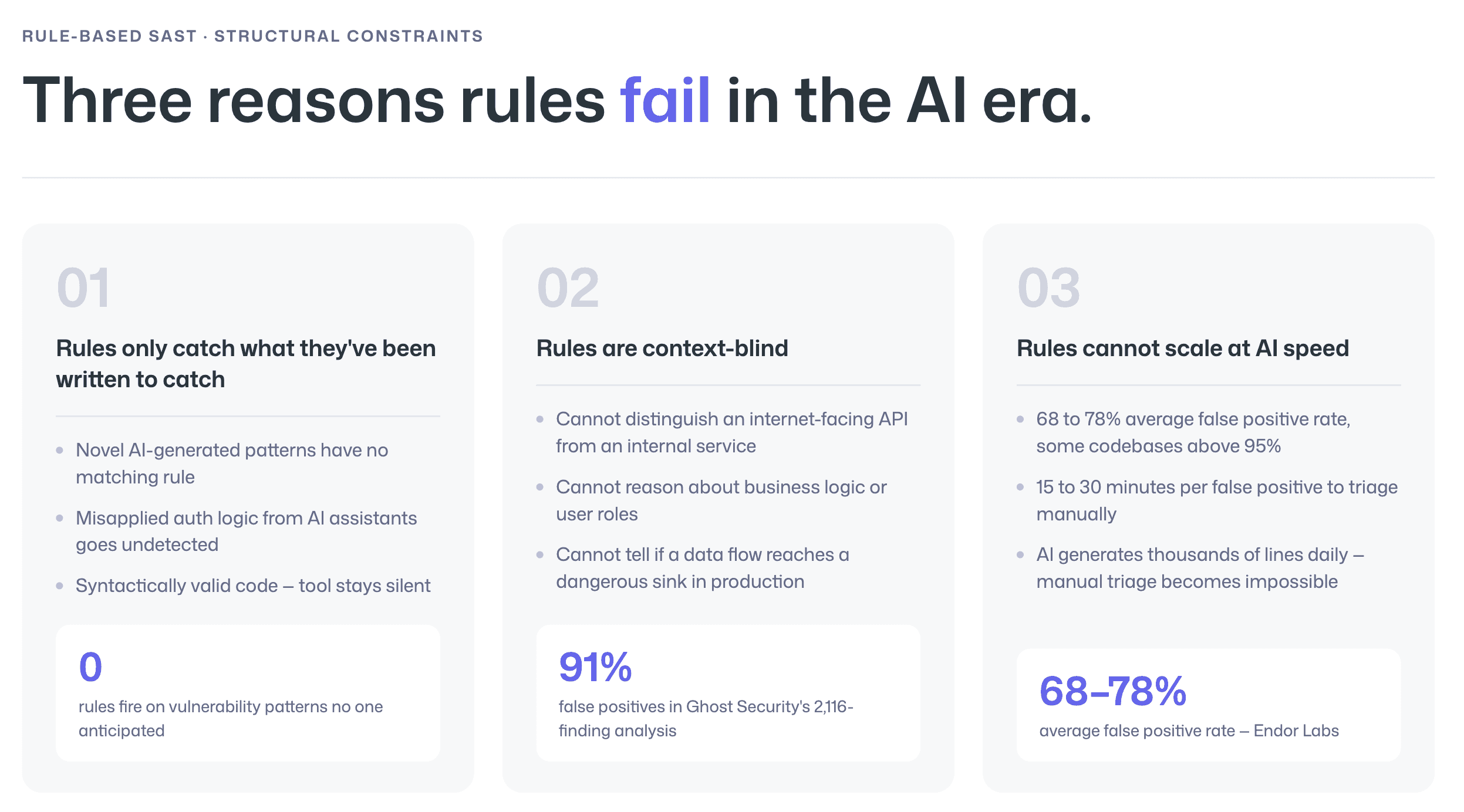
Constraint 1: Rules only catch what they've been written to catch
When AI generates novel vulnerability patterns, broken access control through misunderstood auth flows, copy-pasted authorization logic applied in wrong contexts, or architectural designs that subtly violate security invariants, no existing rule fires.
The tool sees syntactically valid code and stays silent.
That said, "traditional SAST tools struggle to capture complex and emerging vulnerabilities due to their reliance on rule-based matching."
Constraint 2: Rules are context-blind
They cannot distinguish between a vulnerable code path in an internet-facing API and the same pattern in a locked-down internal service.
They cannot reason about business logic, understand user roles, or evaluate whether a data flow actually reaches a dangerous sink in production.
This produces the false positive catastrophe that plagues every enterprise SAST deployment.
Constraint 3: Rule-based tools cannot scale at AI speed
Ghost Security analyzed 2,116 findings from traditional SAST and found that only 180 were real vulnerabilities, roughly 91% were false positives.
Endor Labs reports legacy SAST tools experience 68–78% false positive rates on average, with some production codebases seeing rates above 95%. Security teams spend 15–30 minutes triaging each false positive.
When AI is generating thousands of lines per day, the math breaks. Manual triage becomes physically impossible.
SonarQube, Snyk, and Checkmarx Face an Architectural Ceiling
The three dominant players in static analysis each confront this limitation differently, but none have escaped it.

SonarQube
SonarQube operates on the most traditional architecture: over 6,000 deterministic rules organized into Quality Profiles, with pattern matching, control-flow analysis, and taint analysis forming the detection engine.
Its quality gate system is genuinely mature, the "Sonar Way" default enforces zero new bugs, zero new vulnerabilities, and minimum 80% coverage on new code.
SonarQube has bolted AI onto this foundation through AI CodeFix (LLM-generated fix suggestions) and AI Code Assurance (a dedicated quality gate for AI-generated code). But the detection engine itself remains rule-based.
AI CodeFix helps developers fix what SonarQube finds. It doesn't help SonarQube find what its rules miss.
The architectural limitation persists beneath the AI veneer.
Snyk Code
Snyk Code comes closest to an AI-native detection engine among legacy vendors.
Its DeepCode AI engine, developed over eight years, combines symbolic AI (rule-based structure analysis) with neural machine learning trained on millions of lines of open-source code. This hybrid approach lets Snyk learn patterns from real-world repositories rather than relying solely on manually written rules.
The limitation is in workflow depth.
Snyk's PR checks are optional by default, with blocking enforcement delegated to the source control platform's branch protection rules. Compliance-specific features remain limited compared to enterprise SAST platforms, and the tool lacks the governance depth that regulated industries require.
Checkmarx
Checkmarx represents the enterprise end of the spectrum.
Its CxQL (Checkmarx Query Language) is a proprietary C#-derivative language that queries an internal code graph, the only major SAST vendor offering full query customization. This flexibility lets security teams add custom sanitizers to eliminate false positives and map scans to compliance frameworks like PCI-DSS, HIPAA, and NIST SP 800-53.
Checkmarx has added AI aggressively, including Developer Assist agents and an AI Query Builder that generates CxQL from natural language.
But CxQL itself is still a query language over a rule-based graph. The AI agents accelerate workflows around the detection engine. They don't replace the detection engine's fundamental pattern-matching architecture.
The bottom line across all three
Each vendor is racing to add AI capabilities, but the core problem persists.
AI features bolted onto rule-based engines improve triage and remediation without solving the detection gap. An InfoWorld study quantified this precisely: Semgrep (rule-based) alone achieved 35.7% precision; GPT-4 alone reached 65.5%; a hybrid SAST-plus-LLM approach hit 89.5%.
The detection improvement comes from AI reasoning, not from better rules.
Claude Code Security: What It Proves About AI-Native Scanning, And Where It Stops
Anthropic's Claude Code Security launch on February 20, 2026 sent cybersecurity stocks tumbling, CrowdStrike dropped 8%, Okta fell 9.2% and for good reason.
It demonstrated that an AI model can do what rule-based tools cannot: reason about code the way a human security researcher would.
What makes it genuinely different
Anthropic's own framing draws the contrast explicitly:
"Static analysis is typically rule-based, meaning it matches code against known vulnerability patterns. That catches common issues, but often misses more complex vulnerabilities, like flaws in business logic or broken access control. Rather than scanning for known patterns, Claude Code Security reads and reasons about your code the way a human security researcher would: understanding how components interact, tracing how data moves through your application, and catching complex vulnerabilities that rule-based tools miss."
Powered by Claude Opus 4.6, the tool performs full codebase scanning by connecting to GitHub repositories, traces data flows across files and components, and uses multi-stage adversarial verification, Claude re-examines each finding, attempting to disprove its own results.
Anthropic's Frontier Red Team claims to have found over 500 vulnerabilities in production open-source codebases, bugs that survived decades of expert review and traditional scanning.
Where it stops
Claude Code Security is explicitly not an enterprise security platform. It is a limited research preview built into Claude Code on the web, not a standalone product.
The product page FAQ states directly: "Claude Code Security complements your existing tools by catching what they might miss."
It does not offer:
Native CI/CD pipeline gating
Automated build blocking
Compliance gating
Structured audit trails
Governance controls
CFRA's analyst note was titled "Displacement Concerns Are Premature" for a reason.
SiliconANGLE captured the gap directly: "Enterprise software teams use CI/CD pipelines... Many established cybersecurity companies already offer such a capability," referring to automated blocking that Claude Code Security does not provide.
Why it still matters enormously
What Claude Code Security proves is the viability and superiority of AI-native scanning as a detection methodology.
What it does not provide is the enterprise infrastructure, CI/CD enforcement, quality gates, compliance automation, audit trails, that turns detection into governance.
The gap between "AI can find vulnerabilities" and "enterprises can govern their code security posture" is where the market's real value lies.
Why the AI That Writes Code Cannot Be Trusted to Audit It
Claude Code Security's architecture reveals a deeper structural issue enterprises must confront.
The entity generating code has an inherent conflict of interest in auditing that same code. This isn't a theoretical concern.
Researchers at Carnegie Mellon tested GitHub Copilot's code review feature specifically for security vulnerability detection and found it "currently ineffective for detecting a wide range of known security vulnerabilities." Comments were infrequent, inconsistent, and largely unrelated to known CWEs.
The review model lacked semantic understanding of execution flow, data propagation, and contextual policy enforcement.
The separation of duties principle
The principle of separation of duties, a foundational internal control mandated by SOX, PCI-DSS, and ISO 27001, requires that no single entity controls all parts of a critical process.
As Ping Identity's security framework states: "Allowing them to audit their own work would create a conflict of interest and reduce accountability. Instead, an independent security auditor should review."
Nature Machine Intelligence published a governance framework proposing independent audit of AI systems as central to responsible deployment.
The specific conflict with AI code security
When Anthropic builds a code-writing AI and then builds a security scanner powered by the same model family, the structural parallel to a company auditing its own financial statements is unavoidable.
Claude Code Security scans code that Claude Code may have generated. Even with adversarial self-verification, the model's training data, reasoning patterns, and blind spots are correlated.
Independent AI auditing, where security analysis comes from a separate entity than code generation, isn't a nice-to-have. It's a compliance requirement for any enterprise operating under regulatory oversight.
This is why Legit Security found that 17% of repositories have developers using AI tools without proper branch protection or code review. And why 98% of security professionals say teams need better controls over how GenAI is used in development.
The industry needs AI-native detection paired with independent governance.
The Enterprise Requirement: More Than Detection
For regulated enterprises, detecting vulnerabilities is necessary but insufficient.
The security stack must enforce policy automatically, produce auditable evidence of compliance, integrate into existing workflows, and provide governance controls that satisfy regulators.
In practice, this means:
CI/CD integration that actually blocks insecure code: not as an optional status check, but as an enforced gate that prevents vulnerable code from reaching production.
Quality gates with configurable thresholds: preventing merges when security standards aren't met, with per-repository granularity to match different risk tolerances across teams.
Compliance workflows: that map findings to frameworks like SOC 2, HIPAA, and PCI-DSS, with structured audit trails documenting every decision for every pull request.
Governance controls: role-based access, centralized policy management, and deployment flexibility spanning cloud, on-premises, and air-gapped environments.
Traditional SAST vendors built much of this infrastructure over decades. SonarQube's quality gates, Checkmarx's compliance presets and ASPM dashboards, and Snyk's policy manager all represent genuine enterprise workflow depth.
But their detection engines — the foundation everything else sits on, are hitting the architectural ceiling described above.
The enterprise requirement is clear: an AI-native detection engine wrapped in production-grade governance infrastructure.
How CodeAnt.ai Closes the Gap
CodeAnt.ai's code security platform occupies the specific gap the market has opened: AI-native detection methodology combined with the CI/CD enforcement, compliance automation, and governance controls that enterprises require for production deployment.
AI-native detection that understands AI-generated code
The scanning architecture uses a proprietary language-agnostic AST engine that performs analysis across files, modules, and repositories, not just line-by-line pattern matching.
Coverage spans SAST, secret scanning, Infrastructure-as-Code analysis (Terraform, Docker, CloudFormation, ARM Templates, Kubernetes Helm charts), Software Composition Analysis, and SBOM generation across 30+ programming languages.
Custom security policies are defined in plain English rather than DSLs or YAML configuration files, a meaningful improvement when security teams need to encode organization-specific standards without learning a query language like CxQL.
The platform learns from past PRs and accepted or rejected suggestions, improving accuracy through reinforcement learning, removing 90% less noise than traditional scanners.
Workflow enforcement that doesn't rely on developers to act
The platform integrates natively with GitHub, GitLab, Azure DevOps, or Bitbucket.
PR-native findings surface directly as inline comments with one-click fix suggestions. Quality gates enforce configurable security baselines across every repository, blocking merges and failing builds when standards aren't met.
This is enforced policy, not optional status checks delegated to branch protection rules.
Granular controls let teams enable or disable SAST, secrets, IaC, and dependency analysis per repository, matching different risk tolerances across the organization.
Enterprise compliance and governance built in
CodeAnt.ai holds SOC 2 Type II certification and HIPAA compliance.

Audit-ready reports are generated for every pull request, covering security, quality, and policy violations in a single view. Custom governance rules, naming conventions, design guidelines, compliance standards, are enforced automatically across repositories with clear audit trails.
Deployment options span cloud SaaS, VPC (AWS, GCP, Azure), on-premises, and air-gapped environments, proven with Commvault's 800-developer deployment, where review cycles dropped from days to minutes.
Structural independence as a compliance feature
Critically, CodeAnt.ai operates as an independent auditor. It does not generate code, which eliminates the conflict of interest inherent in platforms that both write and review code.
This structural independence satisfies separation-of-duties requirements that regulated enterprises cannot waive.
The Full Comparison: Where Each Platform Stands
Capability | SonarQube | Snyk Code | Checkmarx | Claude Code Security | |
Detection architecture | Rule-based (6,000+ rules) | Hybrid AI (symbolic + ML) | Query-based graph (CxQL) | AI-native (LLM reasoning) | AI-native (AST + AI) |
Semantic AI scanning | No (AI for fixes only) | Partial (DeepCode hybrid) | No (AI assists queries) | Yes (full semantic reasoning) | Yes (cross-file/module AI) |
AI-generated code handling | Dedicated quality gate | Risk scoring, reachability | Preset-based scanning | Designed for AI code patterns | Learns from AI code patterns |
CI/CD integration | Jenkins, GitHub Actions, GitLab, Azure DevOps, Bitbucket | CLI-based, GitHub Actions | Plugins for 8+ CI platforms | GitHub Action (legacy only) | GitHub, GitLab, Bitbucket, Azure DevOps native |
PR blocking | Quality gate + PR decoration | Optional (delegated to branch rules) | Policy-based blocking | Not available | Enforced quality gates |
Quality gates | Mature, configurable | Severity thresholds via CLI | Security gates with risk states | Not available | Per-repo granular controls |
Compliance workflows | NIST, OWASP, CWE mapping | Limited | PCI-DSS, HIPAA, NIST presets | Not available | SOC 2 Type II, HIPAA, audit reports |
Audit trails | Audit-ready reports | Reporting dashboards | ASPM with audit history | Not available | Per-PR audit reports, governance logs |
Independent auditing | Yes (third-party tool) | Yes (third-party tool) | Yes (third-party tool) | No (same vendor as code gen) | Yes (does not generate code) |
Enterprise production readiness | Mature (20+ years) | Mature (enterprise tier) | Mature (enterprise tier) | Limited research preview | Production-deployed (Fortune 1000) |
Deployment options | Self-hosted or cloud | SaaS (with Broker) | Cloud, on-prem, hybrid | Cloud only (Claude platform) | Cloud, VPC, on-prem, air-gapped |
Plain-English policies | No | No | AI Query Builder for CxQL | N/A | Yes (native) |
The Future of AI-Native Code Security
The future of this market isn't primarily about detection models.
Detection capability is rapidly commoditizing. Anthropic, OpenAI (with Aardvark), and Google (with CodeMender) have all demonstrated that frontier AI models can find vulnerabilities traditional tools miss. As these models improve and competition intensifies, the detection layer becomes a baseline, not a differentiator.
What won't commoditize is the governance infrastructure that turns detection into enterprise security posture.
CI/CD enforcement, compliance automation, audit trails, quality gates, deployment flexibility, and organizational policy management represent years of integration work with the tools and workflows enterprises actually use.
Gartner's 2025 guidance on Application Security Posture Management reflects this: the future connects scattered signals across the SDLC into a single view, enforces policy, and prioritizes based on context, cutting alert fatigue while connecting code issues to runtime impact.
Three forces that will define the next several years
AI-generated code will become the majority of production code, making AI-native detection non-optional. Rule-based SAST that misses business logic flaws, broken access control, and novel vulnerability patterns will produce increasingly dangerous false confidence.
Separation of duties will become a regulatory requirement, not just a best practice. As AI-generated code scales, regulators will demand that the entity auditing code be structurally independent from the entity generating it. This creates a permanent market for independent AI code auditors.
Workflow integration depth will determine adoption. Security tools that require developers to leave their existing environments, manually export findings, or configure blocking through separate branch protection rules will lose to platforms that enforce policy natively within the development workflow.
The 52% of developers who admit to cutting security measures to meet deadlines won't adopt tools that add friction. They'll adopt tools that enforce security invisibly.
Conclusion: The Architecture of Code Security Has Permanently Shifted
Rule-based SAST served the industry well for two decades. It brought discipline, standards, and automated enforcement to a process that was previously ad hoc.
But its architectural assumptions, that vulnerabilities follow known patterns, that code is written by humans at human speed, that false positive triage can scale linearly, no longer hold.
Claude Code Security proved that AI-native scanning detects vulnerability classes rule-based tools structurally cannot reach. Its limitations, no CI/CD enforcement, no compliance automation, no audit trails, no production readiness as a standalone platform, define exactly the enterprise requirements the next generation of security tools must meet.
CodeAnt.ai closes that gap: AI-native detection combined with workflow enforcement, compliance infrastructure, and structural independence that enterprises require.
As AI-generated code accelerates toward becoming the default, not the exception, organizations that pair AI-native scanning with production-grade governance will maintain security at the speed their development teams now operate.
Those still relying on 6,000 static rules to catch vulnerabilities in code written by models trained on billions of parameters will find their security posture defined not by what their tools detect, but by everything they miss.
Book a 15-minute architecture walkthrough or start a live evaluation to see how AI-native SAST performs against real AI-generated code in your repositories.
The shift has already happened. The only question is whether your security stack has.
FAQs
What is AI-native code security?
Why does rule-based SAST struggle with AI-generated code?
Is AI-native SAST enough without CI/CD enforcement?
What is the separation of duties issue in AI code security?
Will AI-native SAST replace traditional SAST completely?













