AI Code Review
Input vs Output vs Reasoning Tokens: What Actually Impacts Cost (2026 Guide)

Sonali Sood

Founding GTM, CodeAnt AI
Your AI bill just tripled and you're not sure why. You added one feature, maybe a code review assistant or a chat integration, and suddenly token costs are eating your budget.
The culprit is usually hiding in plain sight: output and reasoning tokens cost two to six times more than input tokens, and most teams don't realize how quickly they add up. This guide breaks down exactly how input, output, and reasoning tokens affect your costs, and what you can do to control them.
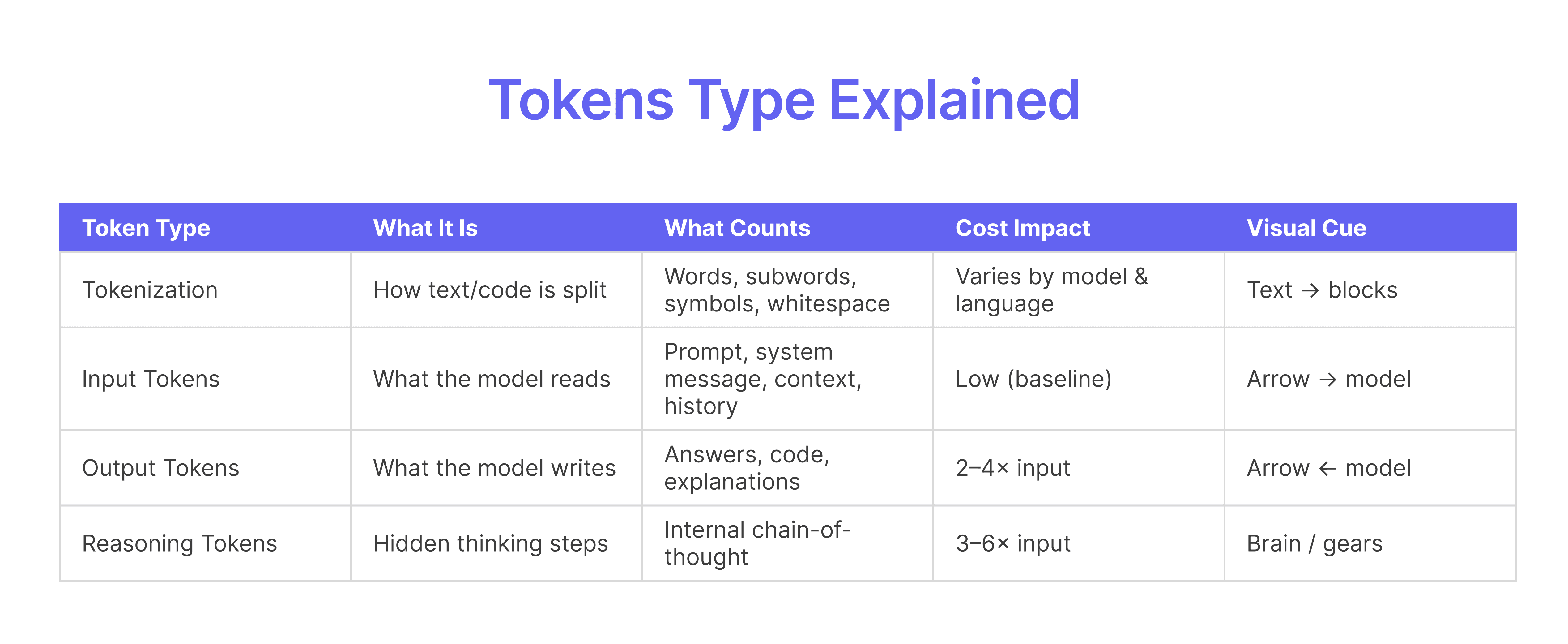
What are Input, Output, and Reasoning Tokens?
Output tokens cost more than input tokens because generating content is computationally intensive. Each output token requires sequential processing and memory use, while input tokens process in parallel during a single forward pass. Reasoning tokens add another layer: they represent internal "thinking" steps that inflate total token counts, even when the visible output is short.
Tokens are the fundamental units LLMs use to process text and code. Every API call you make gets broken into tokens, and your bill reflects how many tokens flow through each category.
How AI Models Tokenize Text and Code
Tokenization breaks text into smaller pieces, words, subwords, or characters—that the model can process. A simple sentence like "The quick brown fox" might become four tokens. Code tokenizes differently because symbols, whitespace, and syntax all affect token counts.
A Python function with short variable names uses fewer tokens than equivalent Java code with verbose class declarations. For example, a simple def add(a, b): return a + b might tokenize into roughly 15 tokens, while the same logic in Java could exceed 40 tokens due to boilerplate.
Input Tokens
Input tokens include everything you send to the model: your prompt, system instructions, context, and conversation history. You pay for every token the model "reads," even if it doesn't use all of it.
Long system prompts, detailed instructions, and extensive code context all count as input tokens. The more context you provide, the higher your input costs, though better context often improves output quality.
Output Tokens
Output tokens represent everything the model generates in response. This includes the full response text, code suggestions, explanations, and any generated content.
Output tokens typically cost two to four times more than input tokens. A verbose response with detailed explanations costs more than a concise answer, even if both solve the same problem.
Reasoning Tokens
Reasoning tokens are the newest category, introduced with models like OpenAI's o1 series. They represent internal chain-of-thought processing, the model "thinks through" a problem before producing visible output.
You pay for reasoning tokens even though they don't appear in the response. A complex coding problem might generate hundreds of reasoning tokens internally, then produce a short answer.
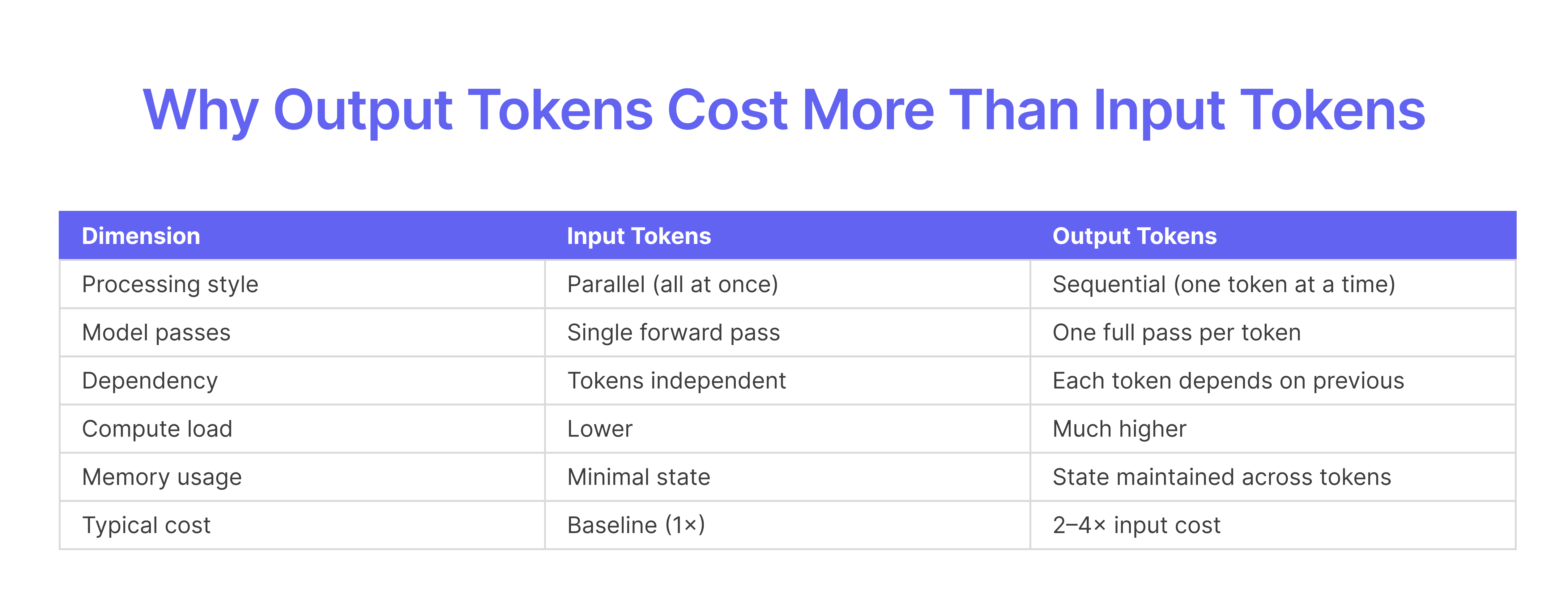
Why Output Tokens Cost More Than Input Tokens
The price difference comes down to how models process each token type. Input tokens process in parallel, the model runs one forward pass through all your input simultaneously. Output tokens require autoregressive generation, meaning the model runs once per token, sequentially.
Think of it this way: reading a document takes one pass, but writing a response requires generating each word one at a time, with each new word depending on all previous words.
Here's what drives the cost difference:
Parallel vs. sequential processing: Input tokens process together; output tokens generate one at a time
Compute intensity: Each output token requires a full model inference pass
Memory overhead: The model maintains state across all generated tokens, consuming GPU memory
Typical cost ratio: Output tokens generally cost 2–4x more than input tokens across major providers
This asymmetry has practical implications. A prompt with 1,000 input tokens and 100 output tokens might cost less than a prompt with 100 input tokens and 1,000 output tokens, even though the total token count is similar.
What Are Reasoning Tokens and Why They Cost the Most
Reasoning tokens combine the expense of output-style generation with extended computation. The model generates hidden tokens internally, works through the problem step by step, then produces the final answer.
How Reasoning Works in Models Like OpenAI o1 and Claude
When you send a complex problem to a reasoning model, it doesn't jump straight to the answer. Instead, it generates internal chain-of-thought tokens, breaking down the problem, considering approaches, and validating its logic.
You pay for both the reasoning and the output. A math problem might generate 500 reasoning tokens internally, then produce a 50-token answer. Your bill reflects all 550 tokens, even though you only see 50.
When Reasoning Tokens Apply to Your Workflows
Reasoning tokens only apply to specific model tiers with chain-of-thought capabilities. Standard chat models like GPT-4o don't use reasoning tokens, they generate output directly.
Reasoning matters most for:
Complex coding tasks requiring multi-step logic
Code review analysis that evaluates architecture and patterns
Security vulnerability assessment with detailed explanations
Mathematical or algorithmic problem-solving
If you're using AI for simple tasks like formatting or basic Q&A, standard models without reasoning overhead are more cost-effective.
Typical Cost Multipliers for Reasoning
The pricing hierarchy follows a clear pattern: reasoning tokens are most expensive, followed by output tokens, with input tokens being least expensive.
Token Type | Relative Cost | Processing Style |
Input | 1x (baseline) | Parallel, single pass |
Output | 2–4x input | Sequential, autoregressive |
Reasoning | 3–6x input | Sequential + extended computation |
Reasoning-heavy tasks can increase costs dramatically compared to standard completions. A complex code review using a reasoning model might cost 5–10x more than the same review with a standard model.
Hidden Factors That Drive Token Costs
Beyond the obvious input/output split, several factors quietly inflate your token spend. Teams often overlook these when budgeting for AI features.
Context Window Creep
Context windows grow over time as conversations continue or as you add more repository context. Each API call includes the full context, so longer contexts mean more input tokens per request.
A code review that starts with 500 tokens of context might grow to 5,000 tokens as you add file history, related files, and conversation history. This is one of the biggest hidden cost drivers for AI-powered development tools.
System Prompts and Custom Instructions
System prompts are sent with every request. A detailed 500-token system prompt multiplies across all API calls, if you make 1,000 requests per day, that's 500,000 tokens just for instructions.
Brevity in system prompts pays off. Every word you remove saves tokens across every request.
Conversation History and Multi-Turn Interactions
Each turn in a conversation resends the entire history as input tokens. A 10-turn conversation doesn't cost 10x a single turn, it costs closer to 55x (1+2+3+...+10) because each turn includes all previous turns.
Multi-turn chats compound costs quickly. Consider summarizing or truncating history for long conversations.
Code File Size and Repository Context
Large code files and extensive repo context inflate input token counts significantly. AI code review tools that analyze entire files or multiple files per PR consume substantial input tokens.
A 1,000-line file might tokenize into 10,000+ tokens. If your tool analyzes five related files
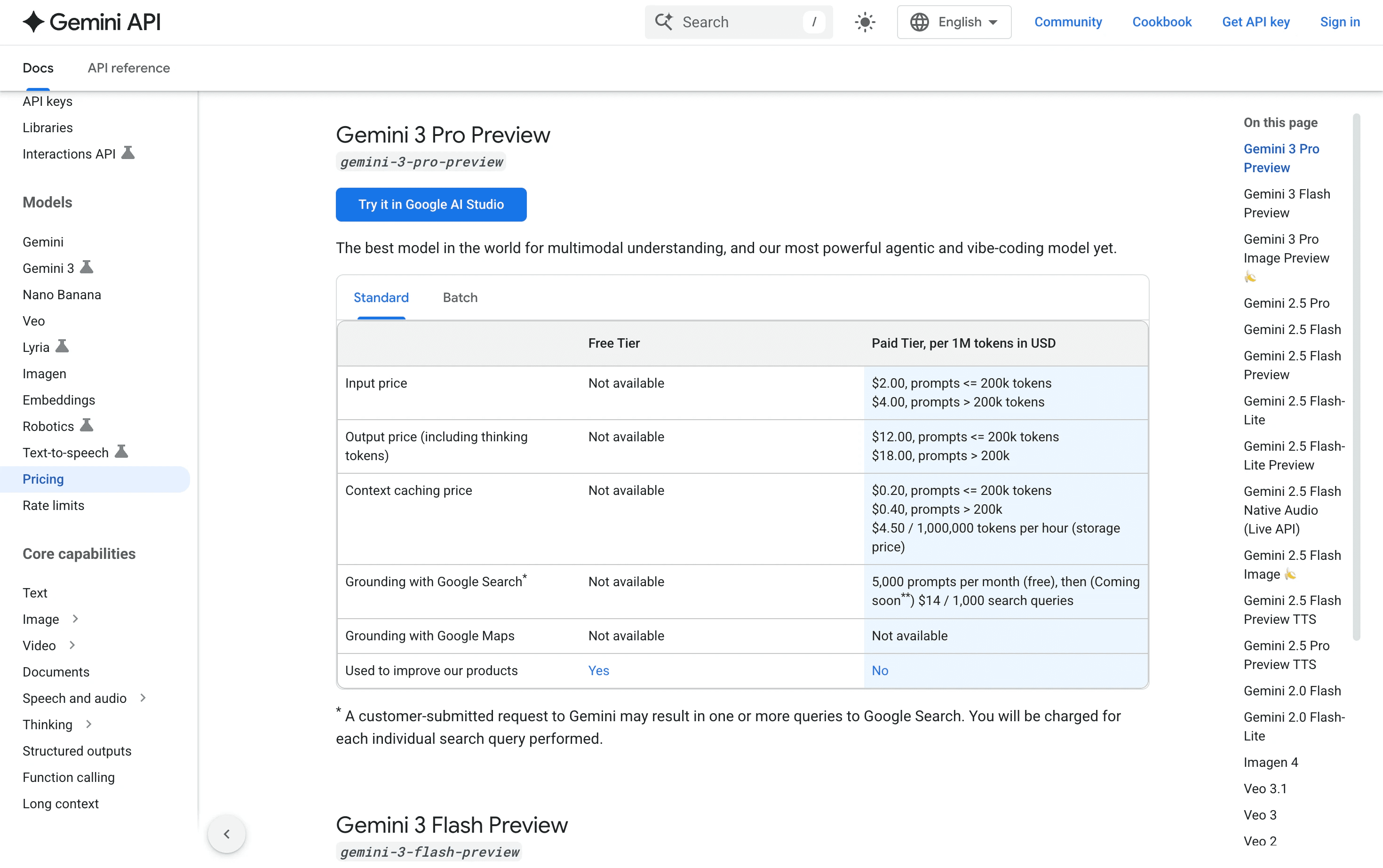
Token Pricing Across Models and Providers
Pricing structures vary by provider, but the pattern is consistent: input tokens cost less than output tokens, and reasoning tokens (where available) cost the most.
Provider | Input Tier | Output Tier | Reasoning Available | Notes |
OpenAI | Lower | 2–4x input | Yes (o1 models) | Tiered by model capability |
Anthropic Claude | Lower | 2–3x input | Yes (extended thinking) | Sonnet vs. Opus pricing varies |
Google Gemini | Lower | 2–3x input | Yes (select models) | Competitive input pricing |
Azure/AWS/GCP | Markup on base | Markup on base | Depends on model | Enterprise wrapper adds 10–30% |
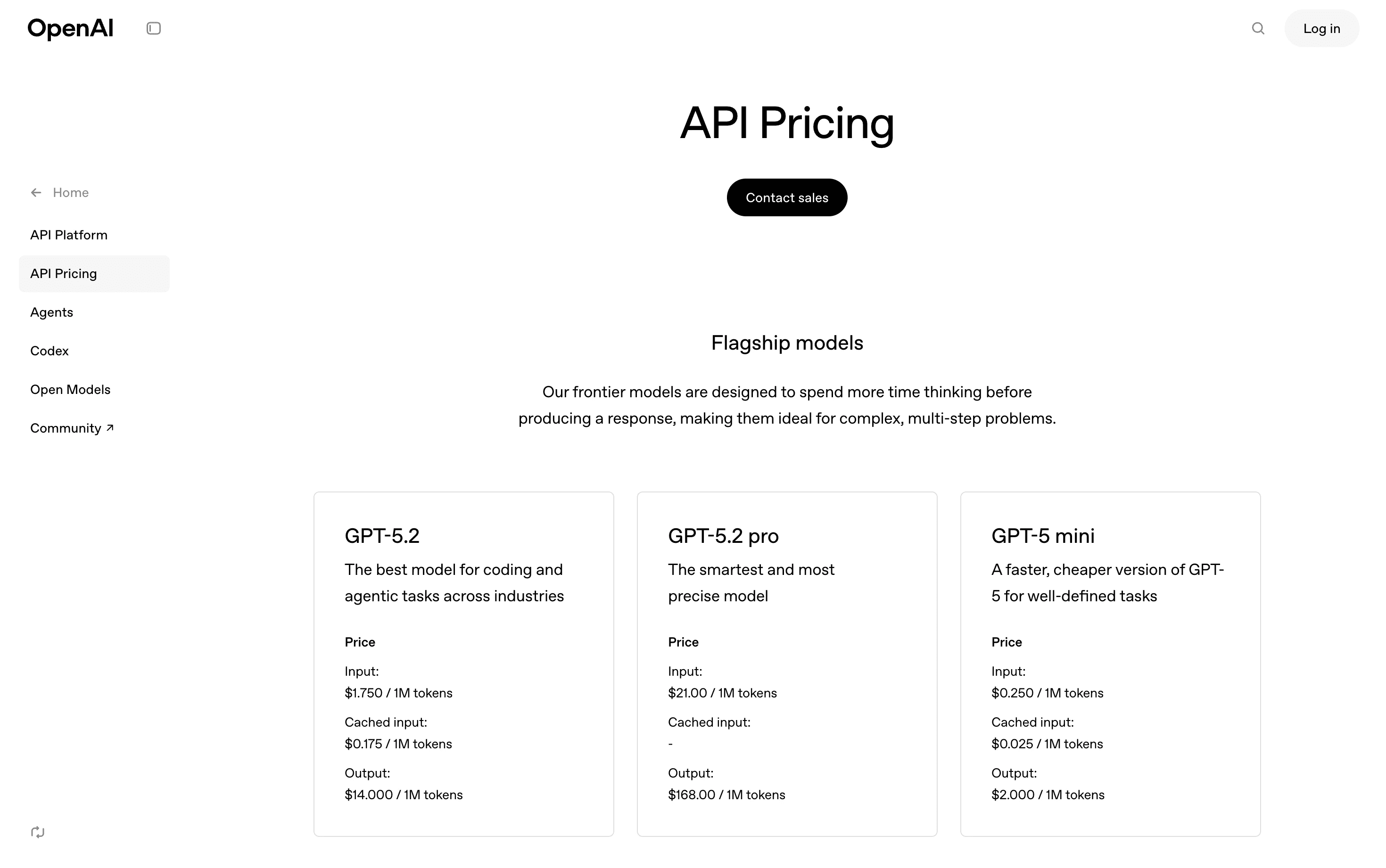
OpenAI GPT Models
OpenAI offers multiple tiers, GPT-4o, GPT-4 Turbo, and o1 reasoning models—each with different input/output/reasoning rates. The o1 models introduce reasoning tokens as a distinct cost category, making them significantly more expensive for complex tasks.
Anthropic Claude Models
Claude's tiered approach (Haiku, Sonnet, Opus) provides different cost profiles. Claude 3.5 Sonnet offers a balance of capability and cost for most use cases. Claude's extended thinking feature has its own token costs, similar to OpenAI's reasoning tokens.
Google Gemini Models
Gemini's pricing structure includes Flash, Pro, and Ultra tiers. Flash offers competitive input token pricing for high-volume, simpler tasks. Pro and Ultra provide more capability at higher per-token costs.
Direct API vs. Cloud Provider Markup
Using AI models through Azure OpenAI, AWS Bedrock, or Google Cloud adds a markup over direct API pricing, typically 10–30%. Enterprise features like SLAs, compliance certifications, and dedicated support come at a cost premium.
For teams already on cloud platforms, the convenience and compliance benefits often justify the markup. For cost-sensitive applications, direct API access saves money.
Proven Strategies to Reduce LLM Costs
Token costs add up quickly at scale. Here are practical ways to reduce spend without sacrificing quality.
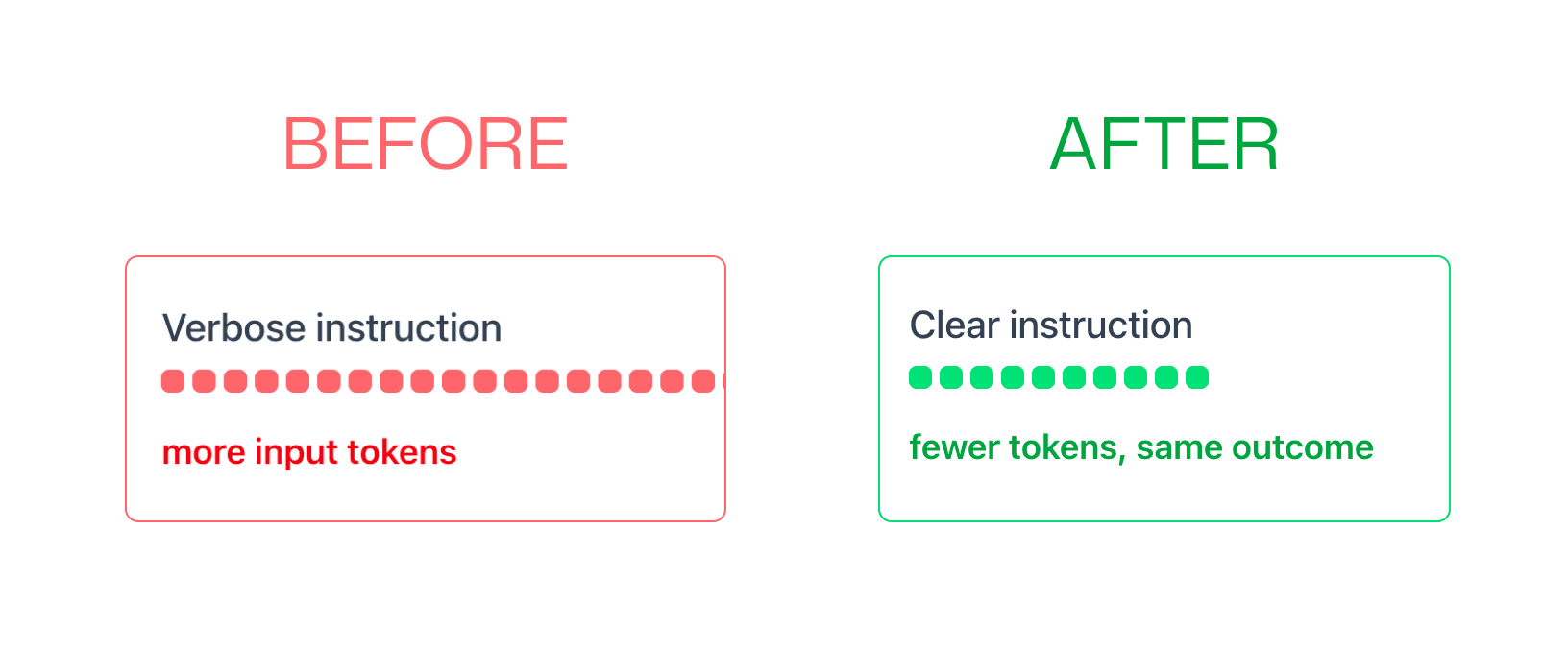
1. Optimize Prompt Length and Structure
Shorter prompts mean fewer input tokens. Remove redundant instructions, use concise language, and avoid over-explaining context the model doesn't need.
Before: "Please analyze the following code and provide a detailed review of any issues you find, including bugs, security vulnerabilities, and code quality problems..."
After: "Review this code for bugs, security issues, and quality problems:"
2. Implement Prompt Caching
Prompt caching stores and reuses common prompt prefixes to reduce repeated token processing. Many providers now offer native prompt caching features.
If your system prompt is identical across requests, caching can reduce input token costs by 50–90% for that portion.
3. Use Semantic Caching for Repeated Queries
Semantic caching stores responses based on query meaning, not exact text match. When similar questions come in, the cache returns the stored answer without calling the API.
This works well for common questions in documentation, support, or FAQ-style interactions.
4. Batch Similar Requests Together
Batch processing groups multiple requests into a single API call where possible. This reduces per-request overhead and can qualify for batch pricing discounts.
OpenAI's batch API, for example, offers 50% discounts for non-time-sensitive requests.
5. Select the Right Model for Each Task
Use smaller, cheaper models for simple tasks. Reserve expensive reasoning models for complex analysis. Implement model routing based on task complexity.
A simple code formatting task doesn't need GPT-4o—GPT-3.5 Turbo handles it at a fraction of the cost.
Why the Cheapest Model is Not Always the Best Value
Cheaper models may require more tokens to achieve the same result. More back-and-forth, longer prompts for clarity, and lower success rates all add up.
A more capable model might solve a problem in fewer tokens, resulting in lower total cost despite higher per-token pricing. Consider:
Task completion rate: Cheaper models may fail more often, requiring retries
Output quality: Lower-quality output may need regeneration or manual correction
Token efficiency: More capable models often produce concise, accurate responses in fewer tokens
For AI code review, a capable model that catches issues on the first pass costs less than a cheaper model that misses problems and requires multiple iterations.
How to Monitor and Forecast Token Spend
Visibility into token usage is essential for managing AI budgets. Without tracking, costs can spiral unexpectedly.
Key Metrics for Token Cost Management
Track these metrics to understand your token spend:
Tokens per request: Average input and output tokens per API call
Cost per use case: Segment spending by feature (code review, chat, search)
Reasoning token ratio: For teams using o1 or similar models, track reasoning overhead
Cache hit rate: Percentage of requests served from cache vs. API
Setting Token Budgets by Use Case
Budget by feature or workflow rather than total spend. AI code review, security scanning, and chat assistants have different token profiles.
Set alerts when specific use cases exceed expected consumption. A sudden spike in one feature is easier to investigate than a general cost increase.
Tools for Token Usage Visibility
Most providers offer usage dashboards with daily and monthly breakdowns. Third-party observability tools can aggregate across providers for teams using multiple models.
Integrate token tracking into existing engineering metrics and dashboards. Treat token spend like any other infrastructure cost.
Building Cost-Effective AI into Your Development Workflow
Input tokens are cheap, output tokens cost more, and reasoning tokens cost the most. Hidden factors like context window creep and system prompt length can quietly inflate costs.
The good news: you don't have to manage all this manually. There are ample tools available that can help you optimize token usage behind the scenes, teams get AI-powered code review, security scanning, and quality analysis without managing token budgets directly.
Ready to add AI to your code review process without surprise costs?Try our self-hosted platform today!
FAQs
How do I estimate token costs before deploying an AI-powered feature?
Do different programming languages use more tokens than others?
Can I set spending limits or caps on token usage with AI providers?
How often do AI providers change their token pricing?
Are there volume discounts available for enterprise token usage?













