AI Code Review
How Reproduction Steps Make AI Code Review Findings Verifiable

Sonali Sood

Founding GTM, CodeAnt AI
AI code review tools are getting better at spotting possible problems. They are not getting better at proving them. That gap is where trust breaks.
The Familiar Failure Mode
Your AI code reviewer flags a potential SQL injection vulnerability in a critical authentication flow.
The finding looks plausible:
it references the correct file
it mentions user input
it warns about database queries
A senior engineer spends 45 minutes tracing data flow, testing edge cases, and reviewing sanitization logic, only to discover the input is already validated three layers up the stack.
Meanwhile:
two other “high-severity” findings sit untouched
no one knows which issues are real
review velocity slows to a crawl
This scenario plays out daily across teams adopting AI-assisted code review.
The tools are getting smarter, but without concrete reproduction steps, findings remain expensive to verify and easy to dismiss.
Why This Becomes a Velocity Tax
For SaaS teams shipping multiple times per day, this trust gap is not a minor annoyance — it’s a compounding cost.
When AI-generated findings lack executable evidence:
no failing test
no proof-of-concept payload
no clear “run this and observe that”
they force your scarcest resources, senior engineers and security specialists, into triage loops instead of shipping products.
Industry data reflects this clearly. While AI code tool adoption has surged, with the market projected to grow from roughly $4-5B to over $25B by 2030, developers consistently cite accuracy and trust as the primary blockers to relying on AI findings in production workflows.
The gap between:
“The AI said it’s broken”
And
“We’ve verified that it’s broken”
is where review cycles stall and alert fatigue begins.
What This Guide Covers
This guide is written for engineering leaders who want AI code review to actually scale.
You’ll learn:
why reproduction steps are the operational foundation of trusted AI code review
how evidence-based workflows reduce triage time and false positives
what “actionable” really means in modern PR pipelines
which policies teams use to turn AI from a noisy assistant into a quality gate
We’ll also look at how leading platforms are moving toward reproducibility-first reviews, and what you can standardize today, regardless of tool choice.
Why Developers Don’t Trust Automated Findings
AI-driven code review promises faster, safer delivery, but it faces a fundamental trust problem.
When automated findings lack:
context
verification
clear reproduction steps
developers treat them as noise rather than actionable intelligence.
This trust gap doesn’t just slow teams down. It directly impacts:
security posture improvements
the cost of false positives in code review
day-to-day pull request throughput
See, it’s pretty clear that developers want evidence-based findings, not vague vulnerability claims that require manual reconstruction by senior engineers. So, offer them, that’s the only way out!
Common Trust Barriers in Automated Code Review
Four recurring gaps prevent teams from acting on AI-generated findings with confidence.
1. Missing Context
Findings often reference:
incorrect file paths
outdated library semantics
misunderstood sanitization or validation logic
Without precise anchors, file, symbol, line range, and environment details like runtime versions, feature flags, or deployment topology, even legitimate issues stall in triage queues.
2. Severity Ambiguity
A label like “critical SQL injection” means very little without:
exploit conditions
affected assets
existing mitigating controls
Developers need severity grounded in real impact, not theoretical vulnerability categories, to prioritize fixes against roadmap commitments.
3. Remediation Uncertainty
Guidance such as “sanitize user input” leaves teams guessing:
which sanitization method?
where exactly should it be applied?
how do we confirm the fix worked?
Actionable findings must include concrete remediation paths, ideally with code-level guidance that can be validated locally.
4. No Validation Path
When AI tools produce plausible but unverifiable claims, hallucinated data flows, incorrect CVE mappings, misidentified race conditions, teams end up debating the AI instead of fixing code.
Reproduction steps solve this by acting as operational evidence:
run this
observe that
confirm the issue exists
Connecting Risk Realism to Exploit Conditions
The trust problem deepens when automated findings ignore real-world exploitability.
CVSS scoring principles exist for a reason. They evaluate vulnerabilities based on:
attack vector
complexity
privileges required
user interaction
When AI findings skip this analysis, two failure modes emerge.
First, severity inflation. Every SQL injection or XSS pattern is treated as equally critical, regardless of authentication, rate limiting, or environment isolation. Alert fatigue follows, and mean time to remediation (MTTR) increases as AppSec teams re-triage everything manually.
Second, missed context-aware analysis. A deserialization flaw in an internal microservice that only consumes trusted messages is not equivalent to the same flaw in a public API. Reproduction steps that encode preconditions, authentication state, topology, required payloads, help teams distinguish real risk from low-probability edge cases.
The Operational Cost of Low-Trust Findings
When the AI code review trust gap persists, the cost compounds across DORA metrics.
Code review cycle time increases as engineers ask for proof
Change failure rate rises when unverified findings delay merges
MTTR suffers because teams can’t separate signal from noise during incidents
The market is responding.
Platforms are shifting toward policy-driven workflows, audit trails, and higher-precision findings anchored in deterministic analysis rather than free-form model output.
Best practices for actionable security findings now require:
exact code location
environment assumptions
reproduction commands
expected vs observed behavior
confidence levels
This shift from “AI said so” to “AI provided reproducible proof” sets up the next question engineering leaders must answer:
What does actionable actually mean, and how do you enforce it?
What Makes Reproduction Steps Different From “Better Explanations”
Many AI code review tools try to solve the trust problem by improving explanations: longer comments, more reasoning, or natural-language walkthroughs of why something “might” be broken.
That helps readability, but it does not solve verifiability.
A well-written explanation still leaves the same unanswered questions:
Can this actually happen in our environment?
Under what inputs or conditions does it break?
How do I prove this without reverse-engineering the system?
Reproduction steps answer those questions directly by changing the unit of output from opinion to procedure.
Instead of: “This may lead to incorrect behavior under certain conditions.”
You get:
entry point
trigger condition
observable output
expected vs actual
confirmation of fix
That shift is subtle but profound. It moves AI code review from descriptive to operational.
Reproduction Steps as a Quality Gate, Not a Suggestion Engine
One of the biggest reasons early AI code review tools struggled with adoption is that they behaved like an always-on advisor. They produced ideas, hints, and warnings, but left prioritization and validation entirely to humans.
Reproduction-first systems behave differently.
They act like quality gates.
A quality gate does not ask, “Do you want to consider this?” It asks, “Does this behavior meet the contract?”
When an AI finding includes deterministic reproduction steps, the question in code review changes from:
“Do we agree with AI?”
to:
“Do we accept this behavior?”
That distinction matters because engineering teams already know how to answer the second question. It’s the same logic used in:
failing tests
contract violations
regression checks
SLO breaches
Reproduction steps align AI output with existing engineering decision frameworks instead of introducing a new one.
How Reproduction Steps Reduce False Positives in Practice
False positives are not just incorrect findings, they are expensive interruptions.
Without reproduction steps, a single false positive often requires:
reading unfamiliar code
reconstructing execution flow
checking configs and defaults
debating edge cases in comments
looping in senior reviewers
With reproduction steps, false positives collapse quickly.
If the steps don’t reproduce the issue, the finding is dismissed with evidence.
This creates two powerful second-order effects:
Noise drops naturally: Findings that cannot be reproduced are filtered out early, either by the tool or by fast validation.
Trust compounds over time: Engineers stop assuming the AI is wrong by default because past findings have been provable.
Over weeks, teams don’t just see fewer false positives, they spend dramatically less time arguing about them.
Reproduction Steps Change How Teams Review Code
Once reproduction steps are present, code review behavior shifts in measurable ways.
Reviews become parallelizable
Junior engineers can validate findings independently by running steps, instead of waiting for senior reviewers to reason through them.
Discussions become shorter and more concrete
PR comments shift from long speculative threads to short confirmations:
“Confirmed via repro”
“Fixed, repro now passes”
“Not reproducible, closing”
Fix validation becomes trivial
The same reproduction steps become the acceptance criteria for the fix. No new tests need to be invented to prove correctness, the proof already exists.
This is why teams that adopt reproduction-first reviews often see improvements in:
review cycle time
mean time to remediation (MTTR)
reviewer fatigue
confidence in automated tooling
Why Severity Alone Is Never Enough
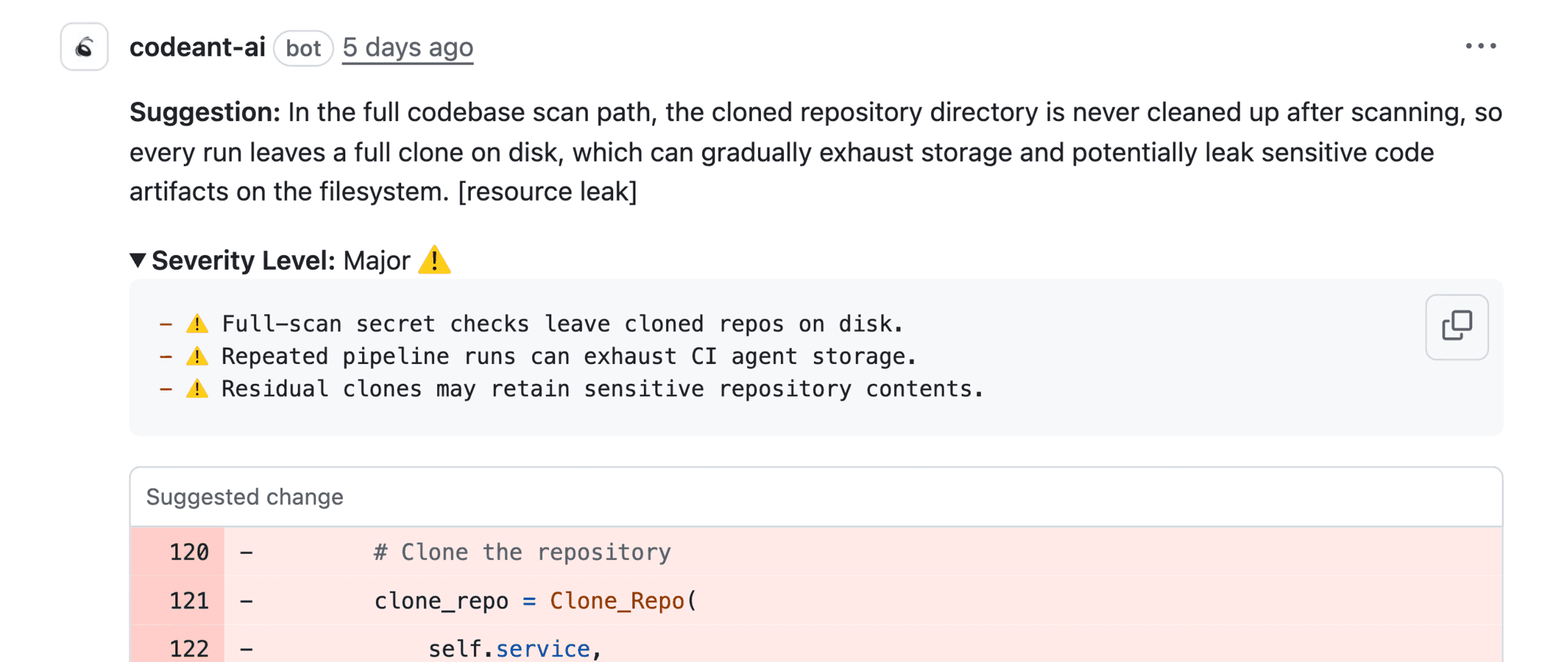
Severity labels without reproduction steps are blunt instruments.
Calling something “Critical” or “High” without showing how it manifests forces teams to either trust blindly or ignore defensively.
Reproduction steps provide the missing context severity needs to be meaningful:
how easy it is to trigger
who can trigger it
what breaks when it happens
whether it fails loudly or silently
This is especially important for silent incorrectness, cases where systems return 200 OK but behave wrong.
These issues are often more damaging than crashes, but they are harder to trust without proof. Reproduction steps make silent failures visible and defensible.
When Reproduction Steps Are Hard (and What Good Tools Do Instead)
Not every issue is easily reproducible.
Some failures depend on:
race conditions
distributed timing
rare load patterns
external dependencies
In these cases, the absence of reproduction steps should not mean the absence of rigor.
Good systems respond by:
lowering confidence levels
clearly stating assumptions
explaining why reproduction is probabilistic
showing partial traces or evidence paths
escalating severity only when impact is high
The key is transparency.
Engineers are comfortable with uncertainty when it’s explicit. What they reject is confident claims without proof.
What Engineering Leaders Should Standardize
For leaders adopting AI code review at scale, the question is not which tool is “smartest.”
It’s which outputs are operationally safe to trust.
A practical standard looks like this:
Every high-severity finding must include:
a clear entry point
explicit trigger conditions
observable behavior
expected vs actual outcome
a way to confirm the fix
If any of these are missing, the finding is informational, not blocking.
This single policy change does more for adoption than tuning prompts or models ever will.
Conclusion: Trust Comes From Proof, Not Intelligence
The future of AI code review is not about smarter suggestions. It’s about verifiable outputs.
Reproduction steps are the bridge between detection and trust. They turn AI from a speculative reviewer into a reliable quality gate, one that engineers can audit, validate, and act on without debate.
When every finding comes with a clear path to reproduction, teams move faster not because they trust AI more, but because they don’t have to.
Audit your current AI code review pipeline this week.
Take 10 recent findings and ask:
Could a new engineer reproduce this issue in under 10 minutes?
Is the severity defensible based on observable behavior?
Is the fix easy to validate once applied?
If the answer is no, the problem isn’t your team, it’s the evidence.
Start by requiring reproduction steps for high-impact findings, and measure what changes. Most teams are surprised by how quickly review velocity and confidence improve once proof becomes the default.
FAQs
What are reproduction steps in AI code review?
Why aren’t explanations alone enough?
Do reproduction steps slow down reviews?
What about issues that can’t be reliably reproduced?
Are reproduction steps only useful for security issues?













