AI Code Review
What Types of Issues Should AI Code Review Not Handle?

Sonali Sood

Founding GTM, CodeAnt AI
Your AI code reviewer just approved a critical payment processing PR. Three days later, you're debugging a production incident, the code was syntactically perfect but functionally broken. It charged customers before validating inventory, violating a business rule any senior engineer would have caught instantly.
This scenario plays out daily across teams treating all AI code review tools as equal. Generic LLM-based reviewers excel at syntax errors and common vulnerabilities, but consistently fail at issues requiring business context, architectural judgment, or domain expertise. The problem isn't AI itself, it's understanding where it falls short and how context-aware platforms bridge the gap.
This guide identifies five critical issue categories where AI review needs human oversight, explains why false positive rates matter more than issue counts, and introduces a four-tier framework for deploying AI review effectively. You'll learn exactly when to trust automation, when to require human judgment, and how to build a review strategy that improves both speed and quality.
Defining AI Code Review in 2026
When discussing AI code review limitations, distinguish between two fundamentally different approaches:
Generic LLM-based tools (ChatGPT, GitHub Copilot for PRs):
Trained on public code with no organization-specific context
Generate PR comments via pattern matching and general best practices
Lack understanding of your business logic, compliance requirements, or architectural decisions
Produce 30-40% false positive rates in production environments
Context-aware platforms (CodeAnt AI, advanced scanners):
Learn from your team's historical PRs, coding standards, and architectural patterns
Enforce organization-specific rules automatically (e.g., "admin overrides only in test files")
Integrate continuous scanning across all branches, not just new code
Deliver <3% false positive rates through codebase-aware analysis
The difference matters. Generic AI might approve syntactically correct code that violates your fintech app's payment order-of-operations. A context-aware platform learns that validateBalance() must precede processWithdrawal() from previous PRs—and flags violations automatically.
Why Understanding AI Boundaries Matters
When teams over-trust generic AI reviewers, they ship logic regressions, miss compliance violations, and generate review noise that actually slows down developers. Understanding boundaries isn't limiting AI's value, it's deploying it strategically to maximize velocity and quality.
The real cost of blind spots:
Logic regressions slip through: A fintech team ships a withdrawal bug because their generic reviewer validated syntax and security but couldn't understand the business rule requiring balance checks before processing fees.
Review throughput decreases: When AI generates 15 alerts per PR with 40% false positives, developers spend more time triaging noise than automation saves. One team's review cycle increased from 4 to 6 hours after adopting a generic tool.
Defect escape rate climbs: A healthcare SaaS discovered their AI approved 12 PRs exposing PHI in logs. The AI understood general security patterns but had no context about HIPAA-specific data handling.
Code review spans five distinct layers:
Syntax and style: AI excels. Linting, formatting, naming, pattern-matching problems with clear rules.
Semantic correctness and vulnerabilities: AI performs strongly on OWASP Top 10, SQL injection, XSS. Effectiveness varies: generic LLMs miss org-specific patterns; context-aware AI learns from historical PRs.
Business logic and domain rules: Generic AI breaks down. Can't understand payment processing order-of-operations or domain-specific workflows without business context.
Architectural decisions: AI surfaces patterns and anti-patterns but can't weigh business priorities, team capacity, or technical debt tolerance.
Compliance and product intent: Organization-specific HIPAA, SOC2, GDPR requirements. Generic AI doesn't know your audit trail needs or data handling policies.
Teams implementing tiered review strategies see 80% reduction in review time with <3% false positives by using context-aware AI where it works and human expertise where it matters most.
The 5 Critical Issue Types AI Should Not Handle Alone
1. Business Logic and Domain-Specific Rules
Generic AI can't understand that "premium users can refund within 30 days, but only if the order hasn't shipped" without explicit domain training. Consider this payment processing code:
Generic AI validates syntax and type signatures. It won't catch that this violates a critical business invariant: withdrawals must be authorized before ledger entries. The correct order requires authorization → ledger entry → balance update with rollback semantics.
Context-aware AI changes the game by learning from your organization's codebase. After analyzing 47 previous PRs, CodeAnt understands authorization patterns must precede ledger operations, flagging violations automatically with business context.

Decision criteria: Does this require understanding product business rules, user roles, or workflow sequencing? Require human review or encode the rule explicitly.
2. Compliance and Regulatory Context
Compliance isn't pattern detection, it's enforcing your organization's specific interpretation of regulatory requirements. Generic AI might flag "potential PII exposure," but can't tell if that data meets your classification model or violates your retention policies.
Real compliance failures AI misses:
Your HIPAA controls permit patient_id in logs (de-identified key), but diagnosis in distributed tracing violates your BAA because traces are retained for 18 months and exported to a non-BAA vendor.
CodeAnt AI bridges the gap by learning organization-specific compliance rules and applying them consistently:
Define rules like "PHI fields cannot appear in logs outside HIPAA-approved services"
Automatic enforcement across every repository with traceability
Measurable coverage with audit trails for compliance reporting
Decision criteria: Does this involve regulatory requirements, audit trails, or data handling policies specific to your industry? Gate with compliance review and encode approved patterns.
3. Architectural Decisions and Strategic Trade-offs
AI can spot code smells but can't make judgment calls defining your system's long-term viability. Should you split your monolith? Where do you draw service boundaries? AI identifies coupling but can't assess whether your team has operational maturity for microservices.
Decisions AI can't make:
Service boundaries: AI detects high coupling but doesn't know your on-call rotation is stretched thin or deployment pipeline isn't built for multi-service orchestration.
Consistency models: AI flags race conditions but can't decide if your payment flow tolerates 200ms latency for strict serializability or accepts stale reads.
Caching strategy: AI detects cache stampedes but can't weigh operational cost of Redis Cluster versus in-memory caching simplicity.
CodeAnt AI adds strategic value by providing insights for confident decisions: tracks complexity hotspots, flags anti-patterns, shows coupling trends, but humans own the strategic call.
Decision criteria: Does this involve system design, performance trade-offs, or long-term maintainability? Require senior engineer or architect approval.
4. Complex State Management and Workflow Integrity
Diff-based review excels at localized issues but modern applications fail from workflow integrity violations: race conditions between async handlers, missing idempotency allowing duplicate charges, or state transitions executing in wrong order.
Why workflow bugs slip through:
The diff shows two async calls. What it doesn't show: charge_customer and reserve_items execute concurrently. If inventory fails, you're issuing refunds instead of preventing charges. The correct pattern, reserve first, then charge, requires understanding business workflow.
CodeAnt AI's continuous scanning helps surface workflow issues:
Cross-file analysis detects missing idempotency patterns
Severity prioritization by business impact and reachability
Historical context from previous incidents
But correctness guarantees still require human judgment and comprehensive testing.
Decision criteria: Does this affect state management across services, introduce timing dependencies, or modify shared infrastructure? Require integration testing and cross-team review.
5. UX Decisions and User Experience
AI-driven review excels at technical UX violations, missing ARIA labels, non-debounced API calls, hardcoded strings, but can't judge if your checkout flow feels intuitive or error messaging aligns with brand voice.
What AI automates effectively:
Accessibility compliance (missing alt attributes, color contrast, ARIA roles)
Internationalization hygiene (hardcoded strings, untranslated errors)
Performance patterns (non-debounced handlers, missing lazy loading)
Common anti-patterns (disabled buttons without feedback, form validation issues)
Where human judgment is essential:
Interaction design trade-offs (confirmation dialogs vs. conversion impact)
Microcopy and tone (helpful vs. condescending error messages)
Flow and information architecture (right place in user journey)
Visual hierarchy beyond contrast rules
Decision criteria: Does this impact user experience, accessibility beyond technical compliance, or product design decisions? Require product/design review alongside technical checks.
The 4-Tier AI Code Review Framework

Match review rigor to actual risk using automation where it excels and requiring human judgment where it matters:
Tier 1: Fully Automated (Zero Human Intervention)
What belongs: Formatting violations, linting errors, OWASP patterns (SQL injection, XSS), hardcoded secrets, unused variables.
Why it works: Objectively correct answers. No architectural trade-off in fixing a missing semicolon or exposed API key.
Merge gate: PRs cannot merge until resolved. No exceptions. CodeAnt auto-fixes 80% with one-click remediation.
Tier 2: AI-Assisted (Human Approval with Context)
What belongs: Code smells (high complexity, duplication), suspicious auth changes, risky config deltas, dependency CVEs, business logic pattern violations.
Why human oversight matters: Requires judgment. Is complexity justified by domain problem? Does auth change align with zero-trust architecture?
Example: PR modifies payment order. Generic AI sees valid syntax. CodeAnt flags it because it learned from 47 PRs that your team always reserves inventory before charging, preventing overselling.
Merge gate: Requires one senior engineer approval after reviewing AI-flagged concerns.
Tier 3: Human-Led with AI Support (Architecture & Design)
What belongs: Architectural changes (service boundaries, data models), performance trade-offs, security design decisions, cross-cutting concerns.
Why AI supports but doesn't decide: Requires understanding business priorities, team capacity, maintenance burden. AI identifies anti-patterns and suggests alternatives but can't weigh "ship faster now vs. refactor for scale later."
CodeAnt's role: Provides architectural insights based on codebase evolution, flags similar patterns, highlights pitfalls, surfaces documentation. Humans make the decision.
Merge gate: Requires two senior engineer approvals, completed threat model, performance test evidence, documented decision rationale.
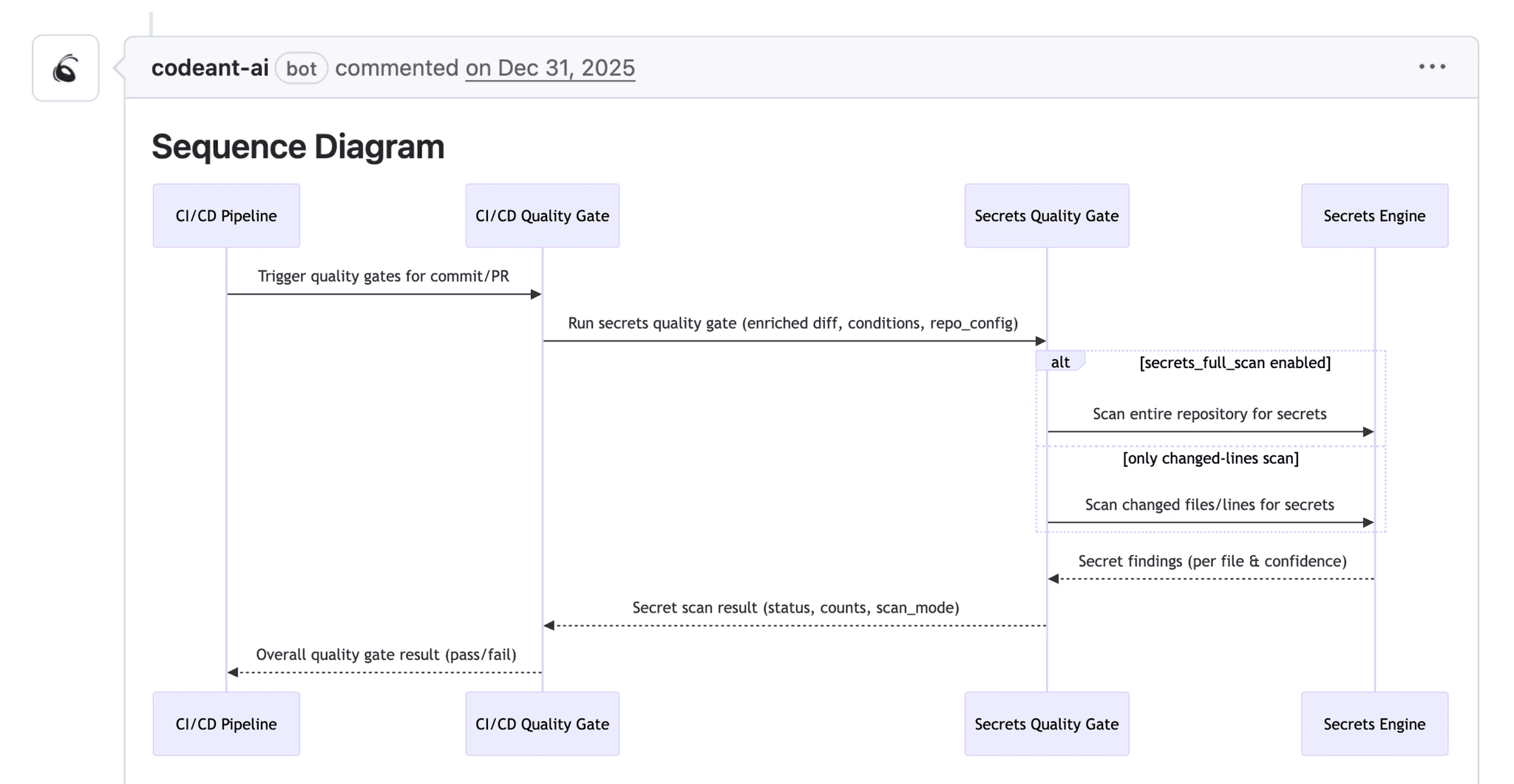
Tier 4: Human-Only (Product & Strategic)
What belongs: Product strategy in code (feature prioritization, UX flows), business logic encoding competitive advantage, compliance requiring legal review, user experience decisions.
Why AI doesn't belong: Requires understanding customer needs, market positioning, regulatory nuance no AI model possesses.
Merge gate: Product manager approval for user-facing changes, legal review for compliance, design review for UI/UX, executive approval for core metrics changes.
Enforcement in Practice
Tier | Auto-Block? | Required Reviewers | Resolution Time |
Tier 1 | Yes | None (auto-fix) | < 5 minutes |
Tier 2 | Conditional | 1 senior engineer | 15-30 minutes |
Tier 3 | Yes | 2+ senior engineers | 2-4 hours |
Tier 4 | Yes | PM + Legal/Design | 1-2 days |
CodeAnt AI accelerates Tiers 1-2 by 80%, freeing senior engineers to focus on Tiers 3-4 where their expertise creates most value. Teams report 60% faster PR cycles while improving defect escape rates by 40%.
Measuring AI Code Review Effectiveness
Track these five metrics instead of vanity "issues found" counts:
1. Review Latency and Throughput
Mean time to first review (MTTR)
PR cycle time (open to merge)
Review capacity (PRs per day/week)
CodeAnt provides real-time latency tracking showing end-to-end impact, including how AI-suggested fixes reduce back-and-forth iterations.
2. False Positive Rate
Industry benchmarks: Generic LLM tools 30-40%, static analysis 15-25%, CodeAnt AI <3%.
CodeAnt learns from your codebase patterns, delivering <3% false positives. Dashboard shows FPR trends over time.
3. Defect Escape Rate
Bugs reaching production despite AI review, tracked by severity:
Critical: Security vulnerabilities, data loss, outages
High: Functional bugs in core features
Medium: Performance degradation, edge cases
Low: Minor UX issues
CodeAnt's continuous scanning catches issues across all branches, not just new code in PRs.
4. Fix Rate (Accepted Suggestions)
Percentage of AI-suggested fixes developers accept and merge.
Targets: Syntax/formatting 90%+, security patches 70-80%, quality improvements 50-60%, architecture 20-30%.
CodeAnt tracks acceptance per category, learning to deprioritize consistently rejected suggestions.
5. Coverage and Developer Satisfaction
Repository coverage (% active repos with AI review)
PR coverage (% PRs receiving feedback)
Branch coverage (% branches scanned)
Developer NPS scores and engagement
CodeAnt AI provides unified reporting with DORA integration, connecting code health to business outcomes.
Why Context-Aware AI Outperforms Generic LLMs
Context isn't a buzzword, it's the difference between flagging every eval() call and understanding that your team approved it in the analytics sandbox but banned it everywhere else.
Effective context includes:
Repository history (past PRs, review comments, merge decisions)
Coding standards and policy configuration
Service ownership and team boundaries
Dependency graph and architecture topology
Prior incident learnings
PR outcome signals (which findings were fixed vs. dismissed)
Side-by-side comparison:
Dimension | Generic LLM-Based Review | CodeAnt AI (Context-Aware) |
Findings per PR | 15–18 comments | 3–6 comments |
Triage time | ~20 minutes | ~4 minutes |
Signal-to-noise ratio | Low – many vague or irrelevant flags | High – only actionable issues |
False positives | “Potential SQL injection” on parameterized queries | Correctly approves safe query usage |
Actionability | “Function complexity is high” with no guidance | Points to exact pattern violation and fix |
Business context | None – treats all code generically | Learns org-specific rules from past PRs |
Severity prioritization | Flat list of warnings | 🔴 Critical → ⚠️ Medium → ℹ️ Low |
Root-cause linkage | Not provided | References similar past incidents |
Fix guidance | Generic suggestions | One-click fixes aligned to standards |
Reviewer confidence | Low – engineers must re-verify everything | High – reviewers trust surfaced issues |
Outcome | Developers ignore or bulk-dismiss | Developers fix and merge faster |
Example Output Contrast (What Developers Actually See)
Generic LLM | CodeAnt AI |
“Potential SQL injection” (false positive) | 🔴 Critical: Transaction state validation missing |
“Consider adding error handling” (vague) | ↳ Pattern violation from PR #1847 |
“Function complexity is high” (not actionable) | ↳ Similar incident #2891 caused duplicate refunds |
“Magic number: 10000” (regulatory limit) | ↳ One-click fix available |
…10 more low-value comments | ⚠️ Medium: Regulatory limit must use named constant |
ℹ️ Low: Suggest shared validation (used in 3 services) | |
✓ Approved: Parameterized query matches standard |
Measurable difference:
Metric | Generic LLM | CodeAnt AI |
Alerts per PR | 12-18 | 3-6 |
False positive rate | 30-40% | <3% |
Critical issues missed | 15-20% | <2% |
Developer fix rate | 40-50% | 85-92% |
Implementation Checklist: Rolling Out Safely
Phase 1: Baseline and Pilot (Week 1-2)
Select 1-2 active repos (10+ PRs/week) with senior engineers for feedback
Measure baseline: review time, defect escape rate, developer satisfaction
Map CODEOWNERS for domain-specific rule routing
Phase 2: Tier 1 Automation in CI (Week 2-4)
Enable non-blocking checks first: syntax, style, OWASP Top 10
Configure as informational, not blocking
Tune rules to <3% false positives before blocking
Set weekly digests for low-severity issues
Phase 3: Security and Compliance with Gating (Week 4-8)
Enable Tier 2 checks with blocking enforcement
Configure gating policies by severity and age
Integrate with approval workflows
Prevent bypassing via branch protection
Phase 4: Scale with Continuous Scanning (Week 8-12)
Enable scanning across all branches
Deploy org-wide dashboards for leadership
Roll out to remaining teams in cohorts
Share success metrics and host office hours
Success metrics at 12 weeks:
80% reduction in PR review time
<3% false positive rate
60% decrease in security vulnerabilities reaching production
1.5+ point increase in developer satisfaction
Conclusion: Build a Hybrid Strategy That Works
AI code review isn't failing, it's being deployed without boundaries. The five issue types we've covered aren't AI weaknesses, they're signals that generic, context-free tools can't replace judgment from understanding your codebase, standards, and priorities.
The 4-tier framework delivers:
Tier 1 (Automated): Syntax, style, OWASP, AI with <3% false positives
Tier 2 (AI-assisted): Security patterns, smells, AI flags, developers validate
Tier 3 (Human-led): Architecture, design, AI insights, humans decide
Tier 4 (Human-only): Strategy, UX, AI stays out
CodeAnt AI's context-aware approach learns from historical PRs, enforces organization-specific rules, and continuously scans beyond PR-time checks. Teams achieve 80% faster reviews, <3% false positives, and one-click fixes that turn detection into resolution.
Your next steps:
Audit current AI usage, measure false positives, defect escapes, developer satisfaction
Define merge gates by tier, map requirements to the 4-tier framework
Instrument metrics that matter, track velocity, escapes, coverage, fix rate, NPS
Adopt context-aware review, move beyond PR-only checks to continuous monitoring
See the difference in your codebase. Start your 14-day free trial on a production repository and measure signal-to-noise improvement in your first sprint.
FAQs
Can AI replace human reviewers entirely?
How do we prevent AI from approving insecure code?
What about private code and IP?
How do we tune false positives without constant configuration?
How do we handle regulated environments (HIPAA, SOC2)?













