AI Code Review
The Hidden Cost of Mental Simulation in Code Reviews: A Developer's Burden

Sonali Sood

Founding GTM, CodeAnt AI
You're three PRs deep into your morning, and your brain already feels like it ran a marathon. The code looks fine. The tests pass. But something nags at you—did you actually trace that edge case, or did you just convince yourself you did?
This invisible work is mental simulation: the cognitive effort of executing code in your head, predicting outcomes, and catching problems before they hit production. It's exhausting, it doesn't show up in any dashboard, and it's quietly draining your team's capacity. Below, we'll break down why code reviews are so mentally taxing, what it costs your organization, and how to reduce the burden without sacrificing quality.
What Is Mental Simulation in Code Reviews
Mental simulation is the cognitive process where reviewers mentally execute code paths, trace logic, and predict outcomes without actually running the code. The hidden cost here refers to the significant cognitive load, mental fatigue, and anxiety developers experience as they build internal models of how code behaves. This invisible effort drains energy, slows teams down, and often leads to missed defects.
When you review a pull request, you're not just reading syntax. You're constructing an internal representation of how the entire system behaves, then imagining what happens under various conditions.
Here's what mental simulation involves:
Logic tracing: following execution paths through conditionals, loops, and function calls
State tracking: holding variable values and object states in working memory
Outcome prediction: imagining what the code produces under different inputs
Impact assessment: evaluating how changes ripple through the broader codebase
This cognitive work happens silently. It doesn't show up in metrics or dashboards, yet it consumes a substantial portion of a reviewer's mental bandwidth on every single PR.
Why Code Reviews Are So Mentally Draining

You might wonder why reviewing someone else's code feels harder than writing your own. The answer lies in how our brains process unfamiliar information, and the sheer number of mental tasks happening simultaneously during a review.
Context Switching Between Writing and Reviewing
Shifting from your own code to evaluating someone else's work requires a complete mental reset. You abandon your current context and load an entirely new one. This switching cost depletes cognitive resources before the review even begins.
Tracing Logic Through Unfamiliar Codebases
When you didn't write the code, you lack the implicit knowledge the author has. You don't know why they chose a particular approach, what edge cases they considered, or how this change fits into the larger system. Building that mental model from scratch takes effort. You're essentially reverse-engineering someone else's thought process while simultaneously evaluating whether it's correct.
Evaluating Edge Cases and Failure Scenarios
The "what if" work is where mental simulation gets exhausting. You're not just understanding what the code does. You're imagining what it does when things go wrong. What happens if this input is null? What if the network times out? What if two requests arrive simultaneously? Holding multiple hypothetical scenarios in working memory at once pushes cognitive limits quickly.
Verifying Security, Compliance, and Standards
On top of logic evaluation, reviewers often check code against organizational rules, security policies, and coding standards. This adds another cognitive layer where you're holding requirements in memory while simultaneously tracing execution paths.
The Hidden Costs of Review Fatigue on Productivity
Individual cognitive burden compounds into team-level and organizational consequences. These costs rarely appear in sprint retrospectives, but they shape delivery speed, quality, and retention.
Visible Costs | Hidden Costs |
Time spent reviewing | Declining accuracy over time |
PR queue length | Missed defects that escape to production |
Meeting hours | Developer burnout and attrition |
Declining Review Accuracy Throughout the Day
Cognitive fatigue causes reviewers to miss issues as the day progresses. A reviewer who catches subtle bugs at 9 AM might skim through similar code at 4 PM. Tired reviewers default to surface-level checks rather than deep simulation.
Higher Defect Escape Rates
When reviewers lack mental energy for thorough simulation, defects pass undetected. Bugs that reach production cost significantly more to fix than issues caught during review.
Slower Cycle Times and PR Bottlenecks
Exhausted reviewers delay reviews, creating PR queues that block other developers. The bottleneck compounds as more PRs pile up, reviewers feel more pressure, and quality drops further.
Developer Burnout and Turnover
Sustained cognitive burden leads to burnout. Developers who spend excessive mental energy on reviews have less capacity for creative work. Over time, this contributes to attrition, especially among senior engineers who often carry disproportionate review loads.
Why Reducing Code Review Burden Often Fails
Teams frequently try to fix review problems but struggle to make lasting improvements. Understanding why helps you avoid the same traps.
Psychological Resistance to Changing Review Habits
Developers stick to familiar review patterns even when inefficient. Line-by-line manual review feels thorough, even when it's not. Changing habits requires conscious effort that fatigued teams rarely have bandwidth for.
Misaligned Team Incentives and Metrics
If teams measure "PRs reviewed" without quality signals, reviewers rush through simulations. Speed gets rewarded while thoroughness doesn't. This creates shortcuts that undermine the entire purpose of code review.
Over-Reliance on Senior Reviewers
Organizations often concentrate review responsibility on senior developers. This creates bottlenecks and burns out experienced team members, the very people whose expertise you want to preserve.
Can AI Code Review Tools Reduce Cognitive Fatigue
AI-assisted code review has become a common response to review burden. However, the results vary widely depending on implementation. Some tools genuinely reduce mental simulation costs while others simply shift the burden elsewhere.
How AI Automates Repetitive Code Review Tasks
AI handles routine checks like style, syntax, security vulnerabilities, and standards compliance. This frees human reviewers to focus on logic and architecture.
What AI can automate effectively:
Style and formatting checks: consistent code appearance without human effort
Security vulnerability detection: automated SAST scanning on every PR
Standards compliance: organization-specific rules enforced automatically
Dependency risk assessment: flagging outdated or vulnerable packages
CodeAnt AI takes this further by generating sequence diagrams for each PR.
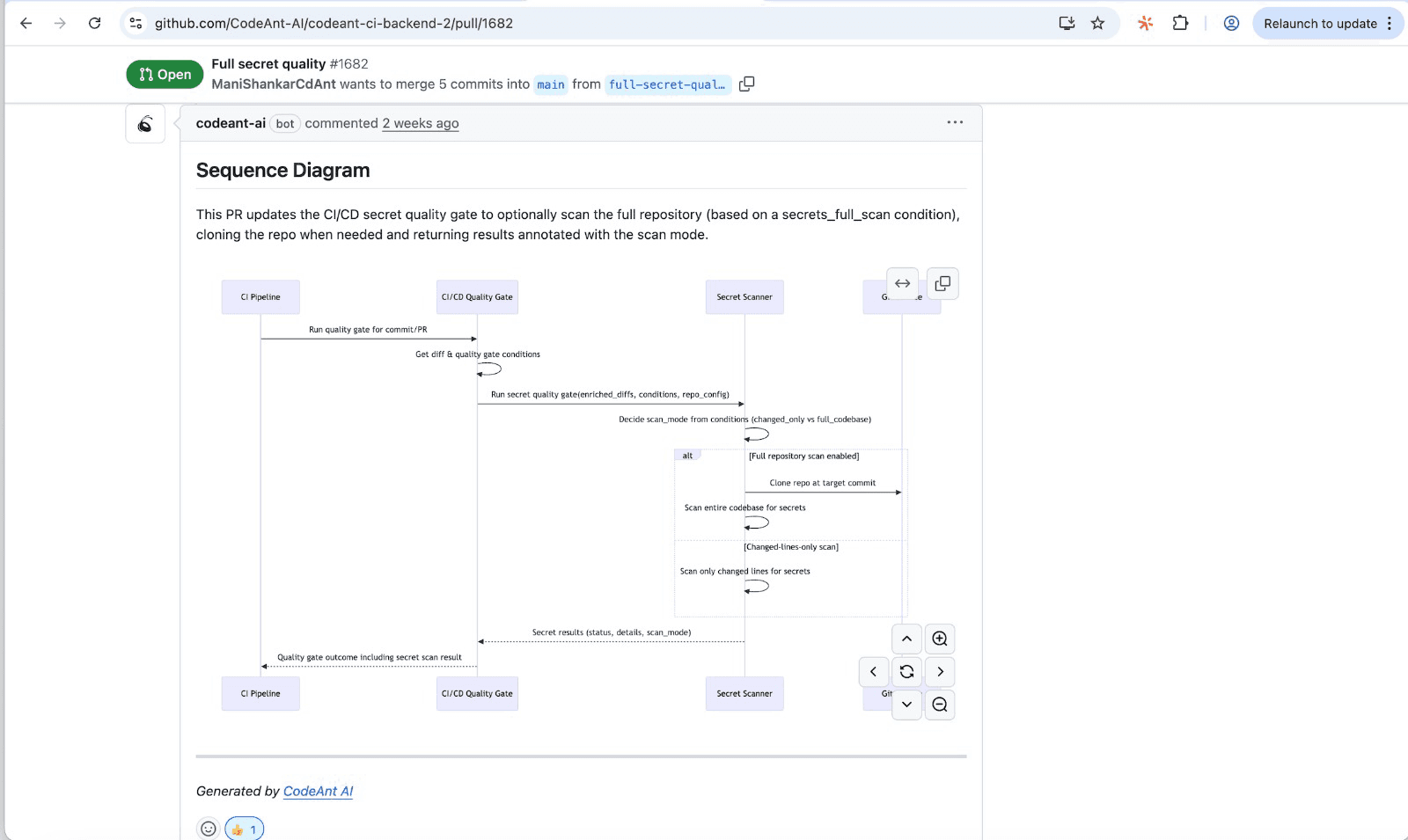
These visual representations of the runtime flow let reviewers understand changes at a glance without mentally simulating every code path.
When AI Shifts Burden Instead of Removing It
Poorly implemented AI tools create noise. False positives, irrelevant suggestions, and recommendations that require human verification add cognitive load rather than reducing it. If you spend more time evaluating AI suggestions than you would reviewing the code directly, the tool isn't helping.
What Effective AI-Assisted Code Reviews Look Like
Effective AI reduces the scope of mental simulation rather than adding to it. Look for tools that provide contextual understanding, learn from your organization's patterns, and surface high-signal issues rather than flooding you with alerts.
CodeAnt AI's approach uses line-by-line reviews with organization-specific learning. The platform understands your codebase and provides actionable summaries that highlight what actually matters.
Practical Ways to Minimize Mental Load During Reviews
Here are tactics that help teams reduce cognitive burden immediately. Each one targets a specific aspect of mental simulation.
1. Keep Pull Requests Small and Focused
Smaller PRs reduce the scope of mental simulation. Reviewers can hold a focused change in working memory more easily than sprawling modifications across multiple files. Aim for PRs that do one thing well. If a change touches more than 400 lines, consider splitting it.
2. Automate Style, Security, and Standards Checks
Remove routine verification from human reviewers entirely. Let tools handle what tools do best: consistent, tireless enforcement of rules that don't require judgment. Platforms like CodeAnt AI consolidate these checks into a single automated layer, so reviewers see only the issues that require human evaluation.
3. Use Structured PR Templates with Context
Good PR descriptions reduce the effort to understand changes. Include why the change was made, what it affects, and how to test it.
A simple template format:
What changed: brief summary of modifications
Why: business or technical rationale
How to test: steps to verify the change works
Risks: potential side effects or areas to watch
4. Schedule Dedicated Review Time Blocks
Batching reviews into focused time windows protects deep work time. Reviewers perform better when they're not constantly interrupted by incoming PR notifications. Try blocking 30 to 60 minutes in the morning specifically for reviews, when cognitive resources are freshest.
5. Pre-Flag Issues with AI Before Human Review
Let AI surface problems first so humans focus on what AI can't evaluate: architecture decisions, business logic correctness, and design tradeoffs. CodeAnt AI's automated PR summaries and sequence diagrams give reviewers a one-shot, high-signal view of what the PR actually does before they dive into the diff.
How to Measure Mental Simulation Costs
Engineering leaders can track concrete metrics to quantify review burden. These signals help identify when cognitive fatigue is affecting your team.
Review Cycle Time and Throughput Metrics
Track how long reviews take from PR open to merge. Increasing cycle times often signal reviewer fatigue or overload. If cycle time rises while PR size stays constant, reviewers are likely struggling.
Defect Escape Rate After Review
Measure bugs that reach production despite passing review. A rising escape rate indicates reviewers are missing issues, often due to cognitive fatigue rather than carelessness.
Reviewer Feedback Patterns and Fatigue Signals
Look for declining comment quality, shorter feedback, or rubber-stamp approvals late in the day. If your senior reviewers approve PRs with single-word comments after 3 PM, that's a signal worth investigating.
Building Sustainable Code Reviews Without the Cognitive Tax
Sustainable code reviews require both process changes and intelligent automation. Neither alone solves the problem. Process improvements like smaller PRs, better templates, and dedicated review time reduce the raw cognitive load. Automation handles the repetitive checks that drain mental energy without adding value.
CodeAnt AI brings these together in a unified platform. Automated PR summaries, sequence diagrams, security scanning, and quality gates work alongside your existing workflow. Reviewers preserve mental energy for high-judgment decisions while routine checks happen automatically.
If you are ready to reduce your team's code review burden, book your 1:1 with our sales team for the best deal today!
FAQs
Why do code reviews feel more exhausting than writing code?
How long can a developer review code effectively before fatigue sets in?
What is the most expensive part of software development?
How can engineering managers reduce review-related burnout?
Does pair programming reduce the mental simulation burden?













