

For years, AI code review tools acted like an over-enthusiastic junior developer. They would flood pull requests with suggestions, many of which were theoretical, vague, or simply wrong. Developers wasted hours debating whether an AI-flagged issue was a real bug or a hallucination. In 2026, that dynamic has shifted.
The industry standard has moved from "probabilistic suggestions" to testable engineering statements. Modern AI tools don't just claim code is broken; they provide the proof. This proof comes in the form of reproduction steps and execution traces. By generating a deterministic checklist of how to trigger a failure, these tools transform code review from a subjective argument into an objective verification process. Here is how this technology works and why it matters for your engineering team.
What Are Reproduction Steps in AI Code Reviews?
Reproduction steps are not descriptions of a bug. They are deterministic checklists that prove an issue exists.
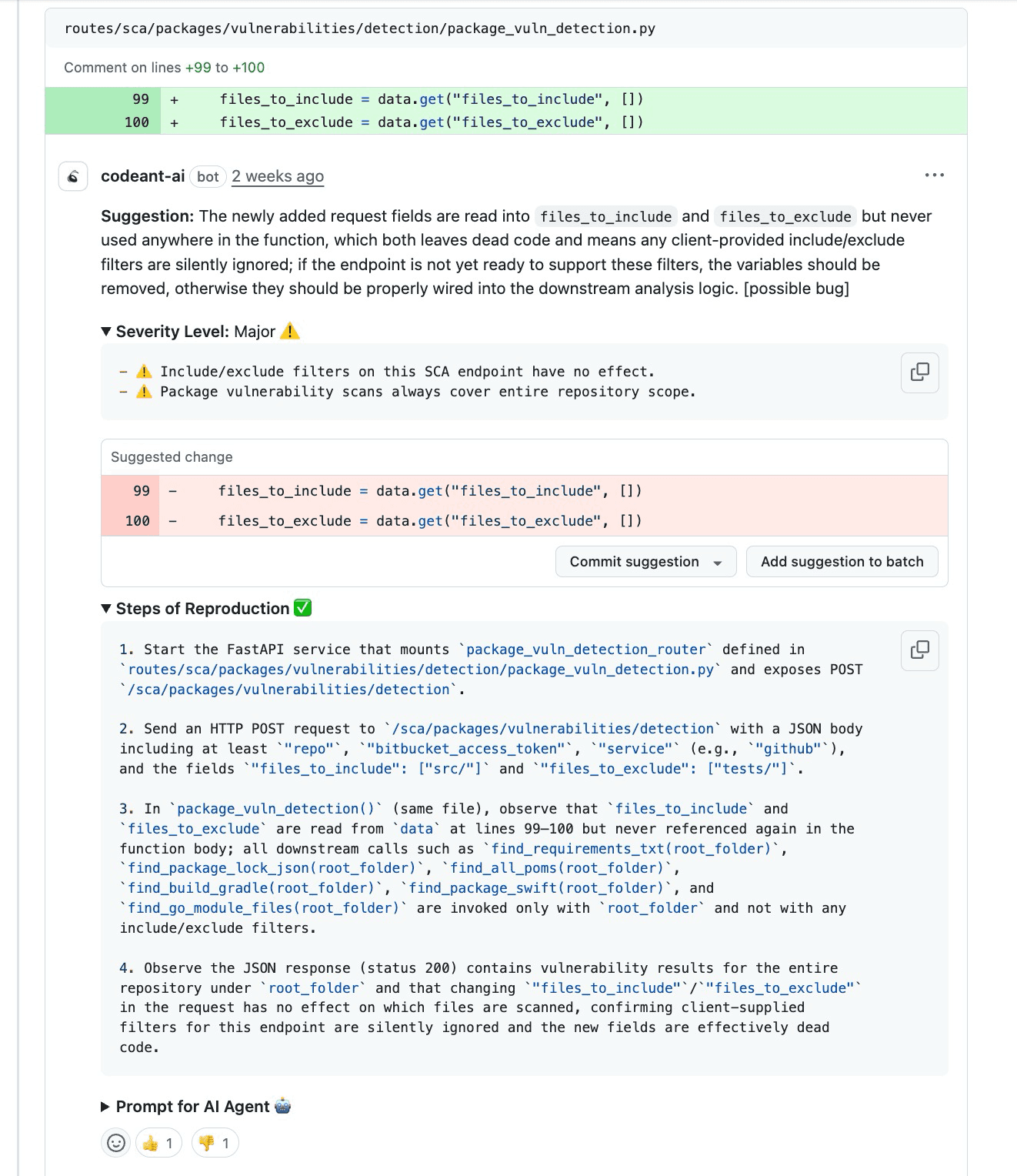
A warning like “this variable might be null” is unverifiable. A reproduction step shows the exact execution path that triggers the failure.
A defensible reproduction block includes:
Entry point: The specific API route, handler, or job where the interaction begins.
Trigger condition: The exact payload, headers, or environment flags needed.
Control-flow evidence: Where the input is ignored or misrouted.
Observable output: The actual response, log, or artifact produced.
Expected vs. Actual: A clear contrast between the intended behavior and the bug.
Confirmation: How to verify the fix worked.
Without these elements, the finding remains a claim.
Why Reproduction Steps Are Non-Optional in AI Code Reviews
Early AI tools failed adoption because engineers had to manually validate every suggestion. Even correct findings created friction if they were unprovable.
Reproduction steps change the role of AI in code review. The system stops behaving like a second developer offering opinions and starts behaving like a quality gate.
Every finding must answer one question:
“Can an engineer prove this failure exists in minutes?”
If the answer is no, severity becomes indefensible and prioritization collapses.
"Every finding is reachable and verifiable, check it out here"
How Do AI Tools Generate Reproduction Steps?
Generating reproduction steps requires understanding execution flow, not just syntax. The system must build a model of how data moves through the application and where contracts break.
This pipeline exists for one reason only: to make findings defensible.
Static Analysis and Real-Time Scanning
The process begins with ingestion and preprocessing. The AI analyzes the Pull Request diff alongside the broader repository context, including the call graph and symbol index.
Parse + Index: It identifies endpoints, handlers, and service functions.
Map Edits: It links the specific code changes to existing symbols and call sites.
Filter: It applies a "gauntlet" of automated checks to filter low-signal targets before deep analysis begins.
Without this stage, reproduction steps become speculative because the system lacks execution context.
Building the Testable Checklist
Once the context is mapped, the AI synthesizes the Repro + Trace. This involves identifying risk patterns, such as ignored inputs, dead fields, or retries with side effects, and constructing a minimal trigger request.
The goal is not exhaustiveness. The goal is proof:
Where should the input influence behavior, and where does it fail?
The output is a synthesized scenario showing the minimal steps required to trigger the bug, contrasting the expected outcome with the actual broken state.
Incorporating Execution Traces
The execution trace is the "missing trust layer." It lays out the complete path of how a bug propagates through the system.
"A transcript (also called a trace or trajectory) is the complete record of a trial, including outputs, tool calls, reasoning, intermediate results."
A defensible trace includes:
Entry point (API / event / CLI)
Request DTO parsing (fields extracted)
Validation (what’s enforced vs not)
Downstream calls (scanners, DB, services)
Where contract breaks (ignored param / missing wiring)
Final observable output (200 OK, wrong payload, scan scope too broad)
Without this trace, reproduction steps lack explainability and engineers are forced back into mental simulation.
1. How Detailed Are Reproduction Steps in Leading AI Tools?
Leading tools now aim for "evidence-first" reviews. The detail level is designed to prevent developers from asking, "Is this reachable?"
Expect to see:
Tests that demonstrate the enforcement of boundaries.
Reproduction steps for edge cases.
Dynamic validation that confirms behavior under misuse.
Logs or metrics that show how the code behaves in practice.
The AI effectively says, "Here is the exact execution path, where the input should have affected behavior, where it didn’t, and what the system outputs as a result."
2. Do Execution Traces and Reproduction Steps Slow Down Reviews?
The short answer is no, they actually speed them up. While generating these traces requires more compute power from the AI, it drastically reduces the human review time.
Without a trace, a reviewer must mentally compile the code, trace the dependencies, and argue about validity. With a trace, the discussion shifts immediately to the fix. The engineer sees the entry point, the downstream failure, and the observable output in seconds. This clarity eliminates the back-and-forth "is this real?" debates that typically drag down review velocity.
3. What If an AI-Flagged Issue Isn’t Easily Reproducible?
If an issue is flagged but hard to reproduce, modern tools use Severity Levels to communicate risk. Severity is a risk score based on the likelihood of failure, blast radius, and detection difficulty.
Critical 🚨: Security exposure, data corruption, or outages.
Major ⚠️: Correctness breaks, consumer-facing bugs, or silent wrong outputs.
Minor 🧹: Maintainability improvements or low-risk cleanup.
Even if a "Major" issue like a silent wrong output is hard to trigger consistently, the AI will still flag it if the code logic (e.g., ignoring a filter configuration) is demonstrably broken.
4. Does It Only Apply to Security Findings?
No. While security is a major use case, reproduction steps are vital for all Impact Areas. "Major" severity often applies to non-security failures that break business logic.
Common impact areas include:
Consumer-facing API behavior: Wrong responses or contract mismatches.
Reliability: Retries causing duplicate side effects or concurrency races.
Performance & Cost: Unbounded loops or full table scans on hot paths.
Observability: Swallowed exceptions or missing logs.
For example, a reliability finding might show a trace where a retry() wrapper around a payment charge causes a double billing event during a timeout.
5. How Well Do They Handle Feature Flags and Config-Driven Behavior?
Modern AI tools consider runtime assumptions as a key input. This includes CI/CD configurations, feature flags, and infrastructure costs.
When generating a reproduction step for code behind a feature flag, the AI identifies the flag as part of the Trigger Condition. The checklist will explicitly state, "Enable feature_x in the environment," then proceed with the payload. If a request accepts a config object but the handler ignores it (a common "Silent Incorrectness" issue), the trace will highlight exactly where the config field was read and subsequently dropped before the downstream call.
6. Can Developers Trust AI-Generated Attack Paths?
Trust is built through transparency. The "Attack Path" feature explains how a bug can be exploited or how it amplifies impact. It moves beyond simple bugs to impact amplification logic.
For instance, if an API ignores an exclude filter, the attack path might show:
Caller submits "narrow scan."
System forces full scan repeatedly.
Result: Compute-cost amplification vector.
"Trust Grows with Gradual Rollout. Instrumenting each stage with precision-recall dashboards, comment-address-rate logs, and user-reported false-positive counts."
7. How Do Reproduction Steps Aid in Validating Fixes?
Reproduction steps provide a clear criteria for success. If the AI provides a deterministic failure path, the developer knows exactly what to test to verify the fix.
This encourages Testable Design:
Testable Design: Is the code structured to allow dependency injection?
Comprehensive Test Suite: Does the PR include tests that mirror the reproduction steps?
Testing Edge Cases: Do tests cover the failure modes identified by the AI?
Instead of guessing if a patch works, the developer simply runs the reproduction steps against the new code. If the "Actual" output matches the "Expected" output, the fix is valid.
Best Practices for Using Reproduction Steps Effectively
To get the most out of these tools, teams need to treat AI findings as engineering inputs rather than just noise.
Verify Findings Systematically
Don't just read the comment; analyze the category. Use a systematic approach to review the AI's logic.
Criterion | What to Look For |
Algorithmic Complexity | Does the code use efficient algorithms? Avoid nested loops (O(n²)). |
Database Queries | Are queries optimized? Look for N+1 problems or missing indexes. |
Resource Management | Is memory/CPU use efficient? Are resources properly closed? |
Scalability | Can the implementation scale horizontally under load? |
Integrate with PR Workflows
Treat the AI review as a Quality Gate. If the AI flags a "Critical" or "Major" issue with a verified reproduction trace, the PR should not be merged until that specific trace is resolved.
This shifts the workflow from "optional advice" to "mandatory checks." The presence of a clear attack path or failure trace makes it difficult to justify ignoring the warning.
Train Teams on Interpretation
Developers need to learn how to read a Trace + Attack Path. It is different from a standard stack trace. It is a logical flow representation.
Teams should understand that a trace showing "Entry point → Downstream calls → Failure point" is a map of the code's logic. Training should focus on verifying these paths: "Does the code actually flow this way?" If the trace matches the code structure, the finding is likely valid.
Common Mistakes to Avoid
The biggest mistake is blind trust in readability. Just because code looks clean doesn't mean it behaves correctly.
Avoid approving PRs solely because the AI didn't complain, or conversely, assuming the AI is right without running the reproduction steps. The tool provides the proof, it is up to the engineer to verify it.
Conclusion
The evolution of AI code reviews in 2026 is defined by the shift from opinion to evidence. By providing Severity Levels, Impact Areas, and most importantly, Steps of Reproduction, modern tools like CodeAnt AI have bridged the trust gap.
These features allow engineering teams to move fast without breaking things. The AI handles the heavy lifting of tracing execution paths and identifying risks, while developers focus on validating fixes and shipping reliable software. When every finding comes with a map to the problem, code review becomes less about argument and more about engineering excellence.

