AI Code Review
Why Retry Logic is One of the Most Dangerous Code Change

Sonali Sood

Founding GTM, CodeAnt AI
Ever slapped retry logic into your code to handle flaky APIs, only to trigger thundering herds that crash your entire system? These "resilient" fixes often mask real bugs, amplify overload, and spark outages no one saw coming. This article exposes why retries rank as one of the most dangerous code changes and arms you with proven strategies to implement them safely. SRE surveys pin retries as a factor in 28% of cascading failures.
Retry Logic Changes System Behavior Under Failure
Retry logic is often the first tool developers reach for when building distributed systems. It feels like a safety net, if a network call fails, just try again, right? But here's the thing: that simple "try again" mechanism is frequently the root cause of massive system outages. What starts as a way to improve reliability often transforms into a weapon that takes down your own infrastructure.
In engineering teams, we often underestimate the complexity of a retry loop. We assume it fixes transient errors, but without strict controls, it amplifies them. That said, "Retries are both essential and dangerous in distributed systems. Indiscriminate retries can lead to latency amplification, resource exhaustion, and cascading failures". This guide explores why this seemingly innocent pattern is one of the most dangerous code changes you can make and how to handle it safely.
What Is Retry Logic?
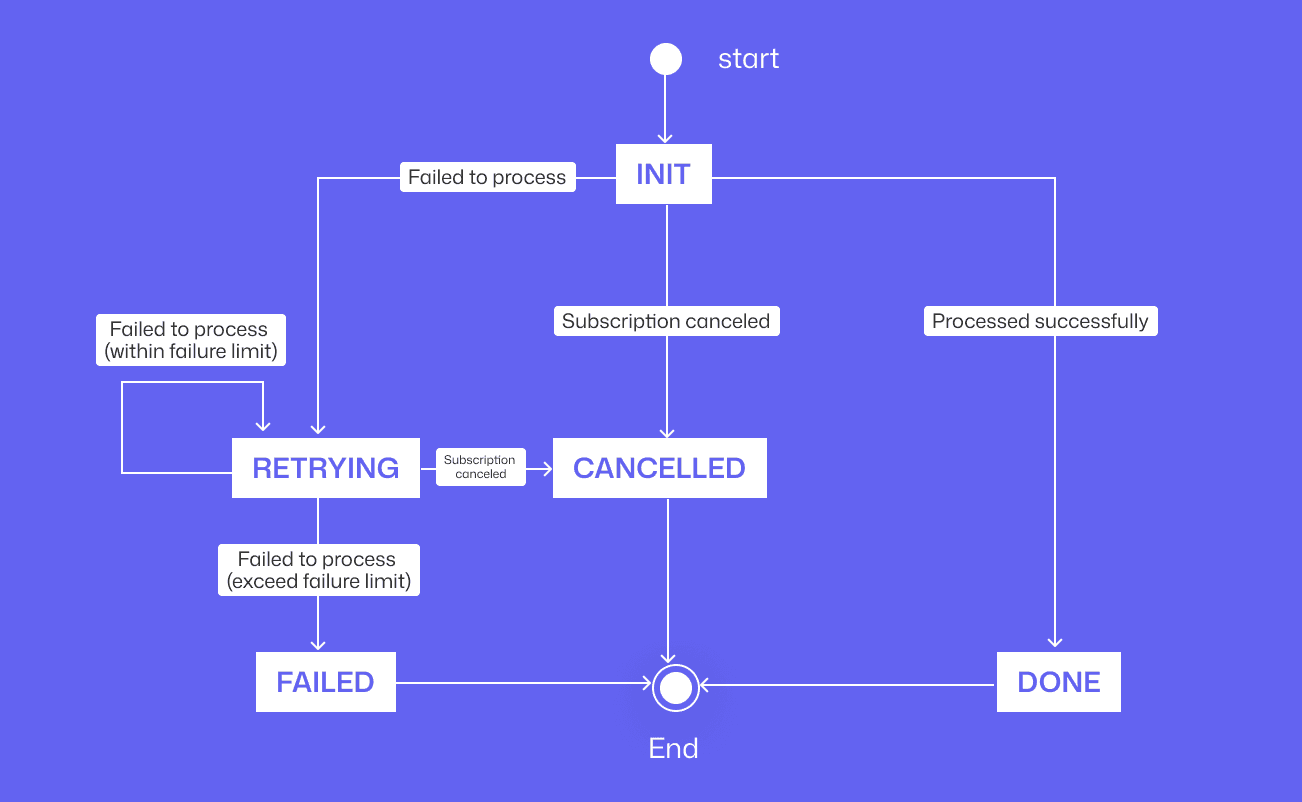
At its core, retry logic is a defensive programming pattern designed to handle transient failures. When an application attempts to communicate with a service or database and fails, it waits a moment and tries the operation again. The goal is to mask temporary blips, like a network timeout or a server restart, from the end user.
However, it's not just about looping until success. It requires distinguishing between errors that might resolve themselves (like a 503 Service Unavailable) and errors that never will (like a 401 Unauthorized).
To see why retries are so dangerous, compare a naïve retry loop with a production-safe implementation.
If you get this wrong, you aren't fixing reliability; you're creating a denial-of-service attack against your own dependencies. That said, "Retry, the mechanism of repeating a request upon failure, is a crucial part of distributed system design".
How Retry Storms Begin in Production
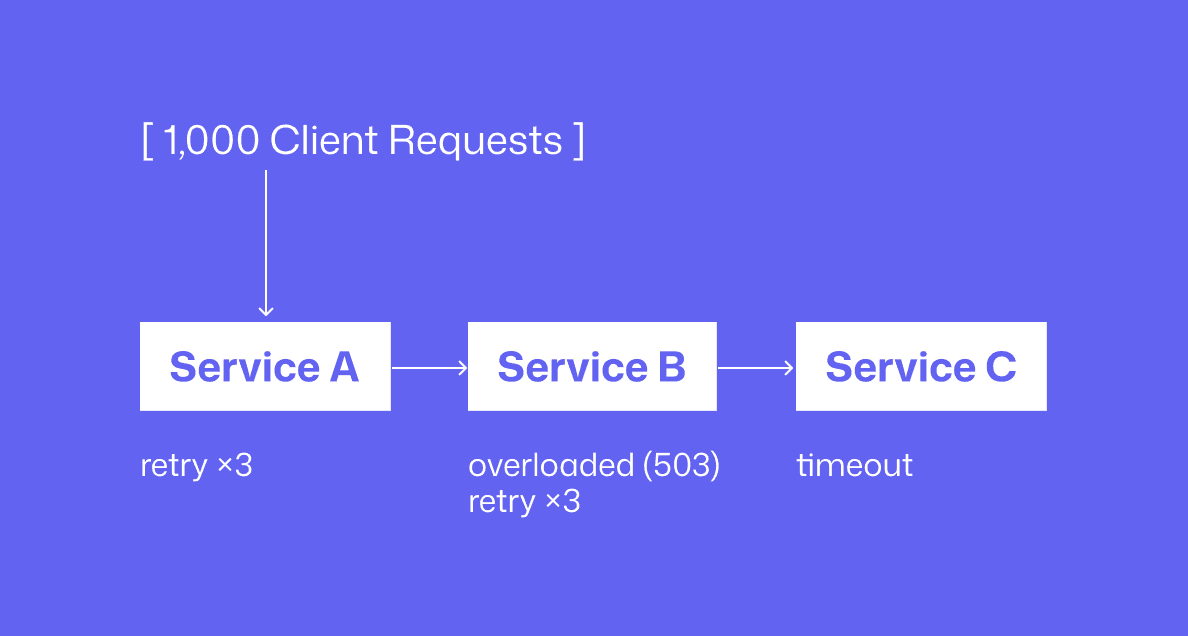
In isolation, retry logic feels harmless: if a request fails, wait briefly and try again. For a single request, this usually works. The danger appears when retries operate under high concurrency across multiple services.
In a distributed system, retries don’t stay local, they multiply.
Here’s a common failure pattern:
Service A calls Service B
Service B is overloaded and returns
503 Service UnavailableService A retries 3 times with a short delay
Now multiply this behavior across 1,000 concurrent requests
Instead of handling 1,000 requests, Service B is suddenly hit with 4,000 attempts. If Service B itself retries downstream calls, the load explodes further. What looked like resilience at the code level becomes amplified traffic at the system level, pushing already-stressed services into collapse.
This is how retry logic quietly turns transient failure into a cascading outage.
Why Basic Retry Loops Fail at Scale
Most retry implementations are simple loops: catch an error, sleep briefly, and retry. These patterns are easy to write, and extremely dangerous in production.
They fail because they ignore system dynamics:
No delay or fixed delay: Retries fire immediately or in lockstep, creating traffic spikes.
Synchronized retries: Hundreds or thousands of instances retry at the same millisecond, triggering thundering herds.
Unbounded attempts: Without strict limits, retries consume CPU, memory, queues, and downstream capacity indefinitely.
Retries don’t just repeat work, they compound load at the worst possible moment.
The Controls That Make Retries Safe
Safe retry logic isn’t about “trying harder.” It’s about knowing when not to retry.
Effective systems add:
Exponential backoff: Retry delays grow over time (1s → 2s → 4s), reducing pressure during failure.
Jitter: Randomized delays prevent synchronized retry waves.
Circuit breakers: When failure persists, retries stop entirely to allow recovery.
Deferred retries: Failed work is queued and retried asynchronously instead of blocking live traffic.
Retries should help systems recover, not punish them while they’re down.
Why Retry Logic Ranks as One of the Most Dangerous Code Changes
Retry logic is dangerous because it changes the traffic characteristics of your system during its most vulnerable moments. When a system is healthy, retries do nothing. When a system is struggling, retries multiply the load, effectively kicking the system while it's down.
This behavior is often invisible during code review. A developer sees a retry(3) and thinks "robustness." They rarely calculate the multiplicative effect across the entire architecture. "Retry isn’t bad. But used incorrectly, you could unknowingly become a 'DDoS hacker'... of your own system".
Sparking Cascading Failures and Thundering Herds
The "Thundering Herd" problem occurs when a large number of processes wake up simultaneously to contend for a resource. If a database blips for a second, thousands of services might enter a retry loop. When the database comes back, it is immediately hammered by the backlog of retries plus new traffic, causing it to crash again instantly.
Masking Real Bugs and Non-Transient Errors
Retries can act as a band-aid that hides deeper wounds. If a service fails 20% of the time due to a race condition, but retries eventually succeed, the bug remains unfixed. This creates a "flaky" system where performance degrades, but monitoring dashboards show "green" because the request eventually passed.
Retries should never apply to:
Client errors: 400, 401, 403, 404
Business logic errors: user not found, insufficient funds, validation failed
422: Unprocessable Entity
Amplifying Load on Overloaded Systems
When a system is slow, adding retries increases latency for everyone. If Service A calls Service B, and Service B times out after 5 seconds, a retry means the user waits 10+ seconds. This is latency amplification. Worse, if Service A retries Service B, and Service B retries Service C, the total request count grows exponentially.
Common Mistakes That Turn Retries into Disasters
The biggest mistake is treating all exceptions as equal. Developers often wrap a block of code in a generic try/catch and retry on any failure. This is catastrophic if the error is a NullPointerException or a ConstraintViolation. Retrying a logic error won't fix it; it just wastes CPU cycles and fills logs with noise.
Another major error is failing to define a "retry budget." If you have a chain of microservices (A -> B -> C -> D), and each layer retries 3 times, a single failure at D results in 81 requests (3^4) hitting the system.
"If I don’t catch all runtime exceptions and set them to application.non-retry exceptions. Any unexpected exception will be forever retried." - Temporal Community Forum.
Best Practices for Implementing Safe Retry Logic
Safe retry logic requires discipline. It’s not just about adding a loop; it’s about understanding the failure mode. The first rule is to fail fast for non-transient errors. If the database says "Duplicate Entry," retrying 10 times won't change the outcome.
You must also decouple the retry from the user request whenever possible. Moving retries to a background queue (asynchronous processing) prevents the user from hanging while your system struggles to recover.
Strategies for safety:
Reduced retries to 2
Added exponential backoff and jitter
Applied circuit breaker on the job
Moved retries to a queue and processed via background jobs
Choose the Right Retry Strategy
Not all failures deserve a retry. You need to categorize errors strictly. A timeout might be worth one retry; a "Bad Request" is not. You also need to coordinate retries across services to avoid the amplification effect mentioned earlier.
When to retry:
Temporary issues: timeouts, connection resets
System errors: HTTP 5xx like 500, 502, 503, 504
Downstream service is restarting
Enforce Idempotency and Error Classification
Idempotency is the safety mechanism that ensures performing an action multiple times produces the same result. If you retry a "Charge Credit Card" API call, you must ensure the user isn't charged twice. Without idempotency keys, retries are financially dangerous.
Monitor, Log, and Limit Retries
You cannot manage what you cannot see. Your observability stack must track retry counts as a specific metric. If a service usually retries 1% of requests and suddenly jumps to 15%, that is an incident, even if the requests eventually succeed.
Set hard limits. A "retry budget" limits the percentage of requests that are allowed to retry (e.g., only 10% of total traffic). Once the budget is exhausted, the system should fail fast to preserve stability for the remaining 90% of traffic.
Real-World Incidents and Lessons Learned
History is full of outages caused by well-intentioned retries. In many cases, the retry logic was added to fix a small instability, only to cause a total blackout later. Automation engineers often use retries in tests to handle flakiness, but this bad habit leaks into production code.
How CodeAnt AI Catches Retry Risks Before They Deploy
Most code review tools function like a "second developer," they offer suggestions, but you still have to verify them. CodeAnt AI operates as a quality gate by providing evidence-first reviews. When it comes to retry logic, CodeAnt doesn't just flag the syntax; it traces the Trace + Attack Path to show you exactly how a retry could break your system.
CodeAnt AI identifies Critical 🚨 and Major ⚠️ severity issues by analyzing side effects. For example, if you wrap a database write in a retry loop without idempotency, CodeAnt flags this as a Retry + side effects risk.
How CodeAnt proves the risk:
Trace (Runtime Flow): It maps the execution path:
Entrypoint→Retry Wrapper→Charge()→Timeout→Retry→Second Charge.Impact Area: It tags this as a Reliability and Correctness issue.
Steps of Reproduction: It generates a deterministic checklist to prove the bug exists, such as mocking a timeout to observe duplicate records.
By moving from vague claims to testable engineering statements, CodeAnt helps teams catch dangerous retry logic that would otherwise cause double-billing or cascading outages.
Key Takeaways for Secure Code Health
Retry logic is a powerful tool, but it requires respect. It is not a magic fix for instability. To use it safely, you must enforce idempotency, implement exponential backoff with jitter, and strictly limit the number of attempts.
Remember, the goal is system resilience, not just successful requests. As you review your code, look for retry loops that lack these safeguards.
FAQs
What is jitter in retry logic?
How do circuit breakers work with retries?
What HTTP status codes should trigger retries?
How do you implement idempotency for retries?
What retry budget should engineering teams set?













