AI Code Review
I Reviewed 1000 Pull Requests and Runtime Bugs Still Slipped Through

Sonali Sood

Founding GTM, CodeAnt AI
You've spent hours reviewing a pull request. You've traced the logic, checked the edge cases, left thoughtful comments. The code looks solid. Then it hits production and breaks in ways you never saw coming.
This isn't a failure of effort, it's a fundamental limitation of how code review works. Reviewers see static text on a screen while runtime bugs live in timing, memory, and environments that diffs can't capture. Here's why even thorough PR reviews miss runtime issues, which bug types slip through most often, and how to build a process that catches more before production.
Why Hours of PR Review Still Miss Runtime Bugs
Developers miss runtime issues in PRs because reviewers see static code on a screen, not memory states, network latency, or concurrent threads. Large PRs obscure details, reviewer fatigue reduces attention, and the asynchronous nature of code review makes it nearly impossible to simulate real-world execution paths. Put simply: you're reading code, not running it.
Reviewers Lack Runtime Context
When you open a pull request, you see function calls, conditionals, and data transformations. What you don't see is what happens when that code executes under load, across network boundaries, or alongside other processes.
A database query that looks fine in isolation might timeout when production traffic spikes. An API call that works locally might fail when the external service rate-limits your requests. Code paths interact differently at runtime than they appear in a diff, and reviewers have no way to observe that behavior.
Cognitive Load Limits What Humans Catch
Cognitive load refers to the mental effort required to trace logic across files, understand dependencies, and hold multiple code paths in your head at once. After about 60 minutes of continuous review, most people start losing focus.
As review sessions extend, attention degrades. You skim instead of read. You approve changes you'd normally question. The longer the review, the more likely something slips through.
Code Looks Correct Until It Runs
Syntactically valid code compiles, passes linting, and often passes tests. Yet it can still fail at runtime. Here's the gap:
What reviewers see: clean syntax, passing tests, logical flow
What happens at runtime: race conditions, null references, timeout failures
What Runtime Issues Slip Through Code Reviews
Certain bug categories are almost invisible during code review. Knowing which ones helps you understand where human review falls short.
Race Conditions and Concurrency Bugs
A race condition occurs when two operations compete for the same resource with unpredictable timing. The outcome depends on which operation finishes first, and you can't determine that by reading code.
Two threads accessing shared state might work perfectly in testing and fail randomly in production. Timing depends on execution, not syntax.
Environment-Specific Failures
Production environments differ from development machines: different operating systems, memory limits, network configurations, and security policies. A feature that works on your laptop might crash on a containerized deployment with restricted memory.
Local dev environments rarely replicate production conditions, so reviewers can't catch what they can't see.
Memory Leaks and Resource Exhaustion
A memory leak happens when code allocates memory but never releases it. Over time, memory usage grows until the application crashes.
Memory leaks don't surface in short test runs or code review. They emerge after hours or days of continuous operation, long after the PR merged.
Security Vulnerabilities Hidden in Logic
Some security flaws are obvious: hardcoded API keys, SQL strings built from user input. Others hide in business logic, like broken access control or authentication bypasses that only appear under specific conditions.
Reviewers often catch the obvious issues while missing the subtle ones.
Integration and Dependency Conflicts
Code reviewed in isolation might break when combined with other services. Version mismatches, API contract changes, and circular dependencies create failures that only appear when components interact.
Common Code Review Mistakes That Let Bugs Escape
Beyond the inherent limitations of human review, certain behaviors make the problem worse.
Focusing on Style Over Substance
It's easy to spend review time on formatting, naming conventions, or whitespace while missing logic errors. Style issues are visible and easy to comment on. Logic bugs require deeper analysis.
Every minute spent on a variable name is a minute not spent tracing error handling.
Skimming Large Pull Requests
Overwhelming diffs lead to superficial scanning. Counterintuitively, reviewers often approve large PRs faster than small ones because the cognitive burden of a thorough review feels too high.
Large PRs hide bugs in plain sight. The more code changes, the easier it is for problems to blend into the noise.
Assuming Test Coverage Is Complete
Tests pass, so the code works, right? Not quite. Tests often cover happy paths, not edge cases or failure modes.
A PR with high line coverage can still contain bugs if the tests don't exercise boundary conditions, error scenarios, or concurrent access patterns.
Missing Edge Cases in Business Logic
Reviewers tend to verify the expected flow without probing boundaries. Common missed edge cases include:
Empty inputs or null values
Boundary conditions (off-by-one errors)
Unusual user behavior sequences
Timeout and retry scenarios
Ignoring Configuration Changes
Config files often get glossed over in review. They're not "real code," so they receive less scrutiny. Yet misconfigurations cause runtime failures that code logic cannot reveal: wrong connection strings, incorrect feature flags, or insecure defaults.
How Large PRs and Review Fatigue Hide Problems
Process and psychology compound the technical challenges. Even skilled reviewers struggle when the system works against them.
Why Big PRs Get Rubber-Stamped
Large diffs create a psychological barrier. Reviewers see hundreds of changed lines and feel overwhelmed. The path of least resistance is a quick approval, especially when urgency compounds the problem and reviewers want to unblock teammates.
The solution is smaller PRs, not harder-working reviewers.
The Context-Switching Tax on Reviewers
Context-switching cost refers to the mental overhead of jumping between unrelated PRs. Each switch requires rebuilding mental context: understanding the feature, the codebase area, and the author's intent.
A reviewer handling five PRs across three projects catches less than one handling a single focused review.
When Speed Pressure Overrides Quality
Deadline-driven cultures push reviewers to prioritize throughput over thoroughness. Ship dates matter. Velocity metrics matter. The pressure to approve and move on is real.
Bugs caught in production are far more expensive to fix than bugs caught in review. Speed now creates slowdowns later.
Where Automation Catches What Reviewers Miss
Automated tools complement human review. Machines excel at consistent, tireless analysis. Humans excel at understanding intent and context.
What Static Analysis Detects That Humans Skip
Static analysis scans source code without executing it, looking for patterns that indicate bugs, vulnerabilities, or quality issues:
Null pointer dereferences
Unused variables and dead code
Type mismatches and unsafe casts
Known vulnerability patterns
Finding these issues is tedious for humans but trivial for machines.
How AI-Driven Code Reviews Enforce Consistent Standards
AI-powered code review tools apply the same rules to every PR without fatigue or bias. They flag quality issues, security risks, and maintainability problems in seconds, before human reviewers even open the diff.
Platforms like CodeAnt AI combine AI code review with static analysis. For every PR, CodeAnt AI automatically generates a sequence diagram capturing the core runtime flow.
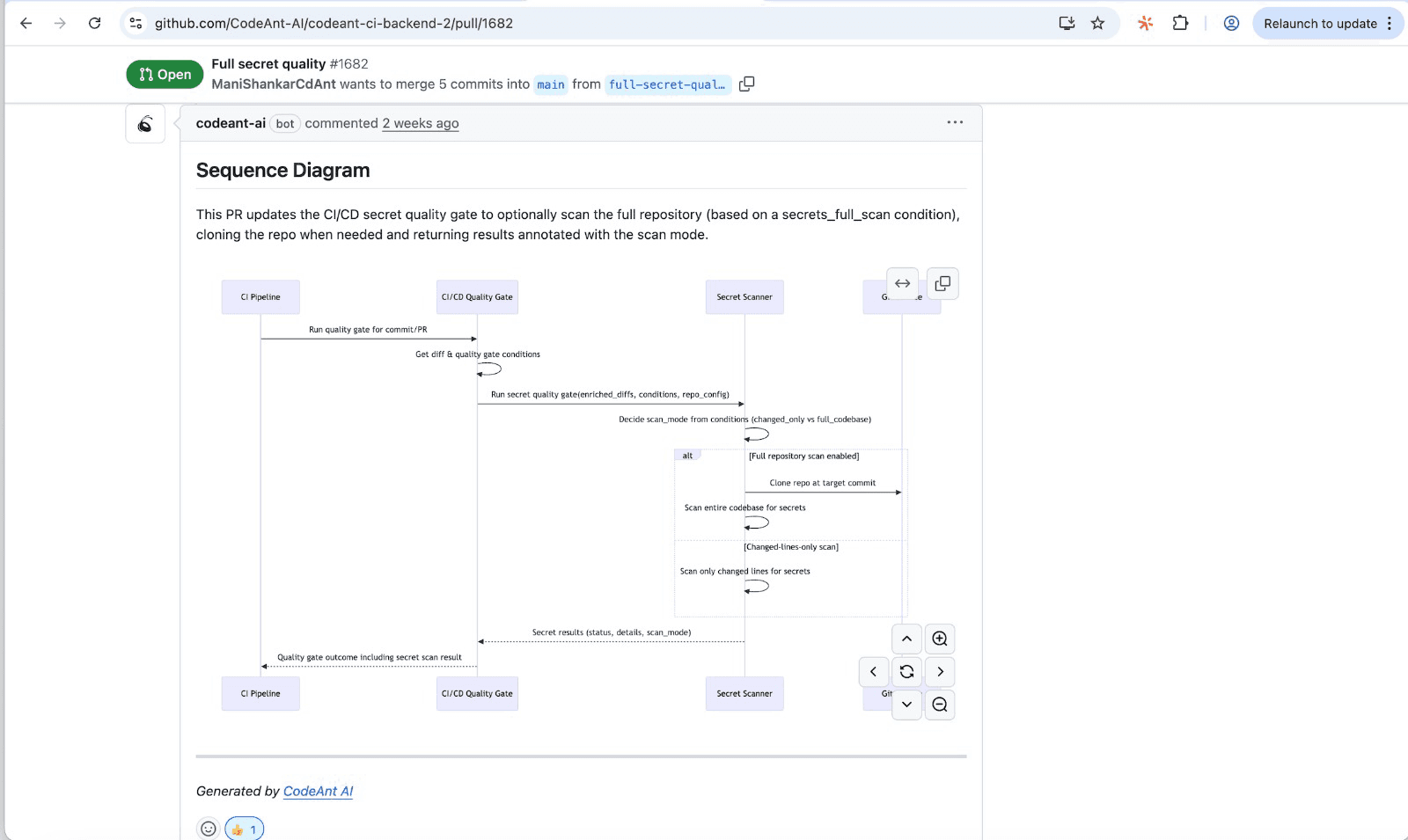
Reviewers get a high-signal view of what the PR actually does: which modules interact, in what order, and where the key decision points happen.
Scanning for Secrets and Misconfigurations Automatically
Automated secret detection finds API keys, passwords, and tokens in code before they reach the repository. Misconfiguration scanning detects insecure defaults, exposed ports, and improper permissions.
Automated checks run on every commit, every PR, every time.
How to Build a Review Process That Catches More Issues
Process improvements reduce the burden on individual reviewers while increasing overall catch rates.
1. Keep Pull Requests Small and Focused
Single-purpose PRs that reviewers can absorb in one session receive more thorough feedback. Smaller PRs also merge faster, reducing the risk of merge conflicts.
2. Pair Automated Checks with Human Review
Position automation as the first line of defense. Run static analysis, linting, and security scans on every PR automatically. CodeAnt AI's automated PR review handles this integration, flagging issues and suggesting fixes before reviewers begin their work.
Ready to automate your first line of defense? Try our self-hosted app today!
3. Use Checklists Tailored to Runtime Risks
Custom checklists prompt reviewers to verify concurrency handling, error paths, and resource cleanup. A checklist transforms implicit knowledge into explicit verification steps.
4. Require Coverage for Critical Code Paths
Test coverage focused on changed lines and high-risk logic provides more signal than overall repository coverage. Untested changes are high-risk areas for runtime bugs.
5. Integrate Security Scanning into Every PR
Embed Static Application Security Testing (SAST) into CI/CD pipelines. Security checks run automatically and don't depend on reviewer memory or expertise.
What Metrics Reveal Code Review Effectiveness
Measuring your review process helps you identify blind spots and track improvement over time.
Metric | What It Measures | Why It Matters |
Escaped defect rate | Bugs found in production that review missed | Reveals blind spots in your process |
Review cycle time | Duration from PR open to merge | Indicates bottlenecks and urgency pressure |
Coverage on changed lines | Test coverage on modified code | Highlights high-risk untested changes |
Change failure rate | Percentage of deployments causing incidents | Directly reflects review effectiveness |
Escaped Defect Rate
Escaped defect rate measures bugs found in production that your review process could have caught. Tracking this reveals patterns, like whether concurrency bugs escape consistently or certain code areas receive less thorough review.
Review Cycle Time and Bug Escape Correlation
Review cycle time measures the duration from PR open to merge. Faster isn't always better. Extremely fast reviews may correlate with more escaped bugs.
Code Coverage on Changed Lines
Overall repository coverage can mask risk. A codebase with 80% coverage might have 0% coverage on the lines you just changed. Measuring coverage specifically on modified code highlights high-risk areas.

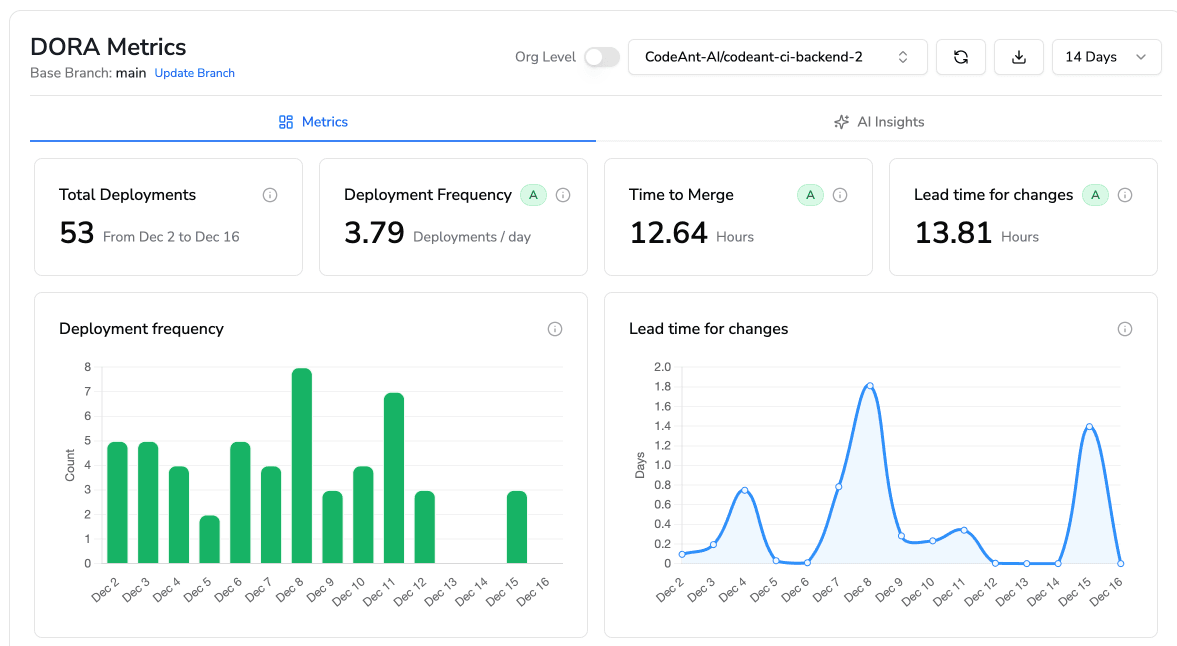
DORA Metrics and Release Stability
DORA metrics include deployment frequency, lead time, change failure rate, and mean time to recovery. Change failure rate directly reflects code review effectiveness. CodeAnt AI tracks DORA metrics to give teams visibility into code health across the development lifecycle.
Ship Faster Without Letting Runtime Bugs Through
Human review alone cannot catch everything. Runtime context, cognitive limits, and process dysfunction create gaps that even experienced reviewers miss.
The solution isn't working harder. It's pairing human reviewers with AI-driven automation that enforces standards, scans for vulnerabilities, and catches what tired eyes miss. Modern platforms unify code review, security, and quality into a single workflow.
Ready to close the gaps in your code review process? Try our self-hosted code review app in your existing workflow today!
FAQs
What is the ideal time limit for a code review session?
Why does peer review take so long?
Can AI code review tools replace human reviewers?
How do you catch race conditions before production?
Are code reviews effective at catching bugs before production?













