AI Code Review
How to Build Self-Evolving LLM Evaluation Pipelines in 2026

Sonali Sood

Founding GTM, CodeAnt AI
Your LLM evaluation pipeline worked perfectly last month. Then the model provider pushed an update, your prompts started behaving differently, and suddenly your carefully tuned system is producing outputs you've never seen before. Static evaluation setups break down fast, and most teams don't realize it until users start complaining.
A self-evolving evaluation pipeline treats testing as continuous infrastructure, not a one-time checkpoint. This guide covers the metrics, frameworks, and feedback loops that keep your evaluations relevant as models change underneath you.
What is an LLM Evaluation Framework?
A self-evolving LLM evaluation pipeline is living infrastructure that treats evaluation as a continuous process, not a one-off step. It combines test datasets, metrics, scoring functions, and automation to measure model outputs against quality criteria. The key difference from static evaluation? It incorporates diverse feedback loops from both humans and AI, then uses that feedback to improve itself over time.
The core components look like this:
Test datasets: curated inputs with expected outputs covering common scenarios and edge cases
Metrics: quantitative measures like accuracy, faithfulness, and relevance
Scoring functions: logic that compares outputs to ground truth or rubrics
Automation: pipelines that run evaluations without manual intervention
Think of it as the nervous system of your LLM product. Without it, you're flying blind every time you update a model or prompt.
Model Evaluation vs System Evaluation
Here's a distinction that trips up many teams. Model evaluation tests the LLM itself, while system evaluation tests your entire application. A great model can still produce poor results when wrapped in bad prompts or broken retrieval logic.
Aspect | Model Evaluation | System Evaluation |
Scope | Raw LLM capabilities | End-to-end application |
Focus | Model accuracy, coherence | User experience, task completion |
When to use | Model selection, fine-tuning | Production readiness, regression testing |
You'll want both. Model evals help you pick the right foundation. System evals tell you whether your product actually works for real users.
Why Static LLM Evaluation Pipelines Fail
Traditional evaluation setups break down fast. You run a test suite once, get good numbers, and ship. Then the model provider releases an update, and suddenly your carefully tuned prompts behave differently.
Model Updates Invalidate Baseline Metrics
New model versions behave differently than their predecessors. Metrics from GPT-4 don't transfer cleanly to GPT-4o. Your baselines become meaningless, and you're left comparing apples to oranges.
Evaluation Datasets Become Stale Over Time
Test cases that once covered edge cases no longer reflect real user queries. Your golden dataset from six months ago might miss entire categories of questions your users ask today.
Prompt Changes Introduce Unmeasured Drift
When teams update prompts without re-running evals, they create blind spots. Each small tweak compounds. Before long, you've drifted far from your last validated state, and you won't know until something breaks in production.
Essential Metrics for Your LLM Eval Framework
Every evaluation framework relies on metrics. The trick is choosing the right ones for your use case.
Accuracy and Correctness
Accuracy measures whether the model's output matches the expected answer. You can use exact match for precise answers or semantic similarity for comparing meaning. It's the foundation of trust in your LLM's output.
Faithfulness and Groundedness
Faithfulness measures whether outputs stay true to source context. This is critical for RAG (Retrieval-Augmented Generation) applications. A faithful response only contains information from the provided documents. Anything else is hallucination.
Also, check out some of our interesting reads:
Why LLM Powered Code Reviews Go Beyond RAG
Why RAG Based Code Review Fails Autonomous Dev Agents in 2026
Why RAG Retrieval Fails for Microservices Code Review
How LLM Based Code Review Achieves System Level Context
Relevance and Coherence
Does the output actually address the user's question? Does it flow logically? Topic relevancy scoring and coherence checks help you catch responses that technically answer a question but miss the point entirely.
Safety and Security
Safety evaluation covers toxicity detection, prompt injection resistance, and sensitive data handling. Test against datasets of harmful prompts, injection attacks, and PII detection. Security evaluation is becoming table stakes for production LLMs.
Latency and Cost Efficiency
A slow or expensive model fails in production regardless of quality. Track time-to-first-token, total generation time, and token usage per call. Operational metrics often determine whether your application is viable at scale.
How to Choose LLM Evaluation Metrics by Use Case
Not all metrics apply to every application. Here's a quick guide:
Use Case | Priority Metrics |
RAG Applications | Faithfulness, Context Relevance, Answer Correctness |
Code Generation | Functional Correctness, Syntax Validity, Security |
Conversational AI | Coherence, Sentiment Appropriateness, Multi-turn Consistency |
Summarization | Compression Quality, Key Information Retention, Readability |
For code generation specifically, functional correctness tests whether the code runs. But you'll also want static analysis for security, quality, and style. Tools like CodeAnt AI automate this analysis across your codebase.
Building a Self-Evolving LLM Testing Framework Step by Step
Now for the practical part. Here's how to build an evaluation pipeline that adapts as your models change.
1. Define Evaluation Objectives and Success Criteria
Start with clear goals tied to business outcomes. "Improve accuracy" is vague. "Reduce hallucination rate below 5% for customer support queries" gives you something measurable. Clear objectives become your North Star as the framework evolves.
2. Create Versioned Evaluation Datasets
Build datasets with version control using Git LFS or DVC. Include golden datasets for core functionality and edge case collections for robustness. Versioning lets you compare model performance across different dataset versions, making evolution measurable.
3. Implement Scoring Functions and LLM-as-Judge Patterns
Write scoring logic for objective metrics. For subjective criteria like tone or helpfulness, use LLM-as-judge patterns where a capable model evaluates another's outputs. The judge can adapt its scoring as new failure modes emerge without requiring new code.
4. Build Synthetic Data Generation Pipelines
Use LLMs to generate new test cases at scale. Synthetic data generation keeps your evaluation datasets fresh and comprehensive without manual effort. As your application's domain evolves, synthetic generation automatically expands test coverage.
5. Optimize Evaluations for Speed and Cost
Implement parallelization and strategic sampling of large datasets. Manage costs for LLM-as-judge calls carefully because they add up fast. An optimized pipeline runs more frequently, enabling faster adaptation to changes.
6. Add Caching and Error Handling
Cache results to avoid re-evaluating identical inputs. Add graceful failure handling so minor issues don't break the entire pipeline. Robustness keeps the feedback loop active, which is critical for continuous evolution.
7. Track Hyperparameters and Evaluation Versions
Log model versions, prompt versions, retrieval configurations, and evaluation settings together. Detailed history provides the context you'll need to understand and guide the pipeline's evolution over time.
8. Create Feedback Loops from Production Data
This is the primary mechanism for adaptation. Build automated workflows to route production failures, user-flagged issues, and implicit negative signals back into your evaluation datasets. The pipeline learns from its mistakes and stays relevant.
LLM Eval Frameworks and Tools Compared
Several frameworks can accelerate your evaluation pipeline. Here's how they compare:
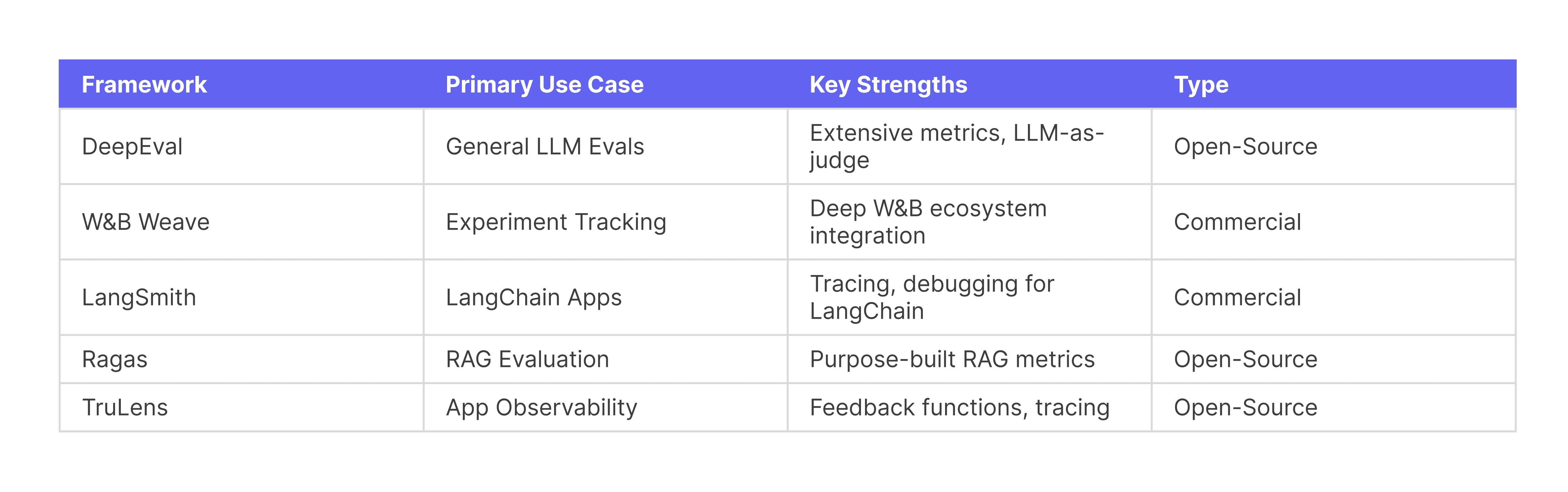
When do you build custom? When you have unique requirements or tight integration with existing infrastructure. Otherwise, start with an existing framework and extend it.
How to Integrate LLM Evals into CI/CD Pipelines
Evals only work if they run automatically. Manual evaluation is evaluation that doesn't happen.
Setting Up Automated Evaluation Gates
Quality gates block merges or deployments when evals fail. Define clear thresholds. A 5% drop in accuracy might be acceptable, while any increase in hallucination rate blocks the release.
Configuring Regression Tests for Model Changes
Trigger full eval suites when models or prompts change. Regression tests catch problems before they reach production. Tools like CodeAnt AI integrate similar quality gates into PR workflows for code, and the same principle applies to LLM outputs.
Handling Evaluation Failures and Rollbacks
Plan for failures. Automated rollback strategies let you revert deployments safely when evals detect problems in production. Define who gets alerted and how quickly you can recover.
How to Monitor LLM Evaluations in Production
Pre-production evals aren't enough. You want continuous validation in the real world.
Logging Prompts Responses and Metadata
Capture full request/response pairs, latency, token counts, and user identifiers. This data feeds your feedback loops and helps you debug issues when they arise.
Detecting Drift with Automated Alerts
Set up drift detection comparing production outputs to baseline distributions. When outputs start diverging from expected patterns, you want to know immediately, not when users complain.
Updating Evaluation Criteria from User Feedback
Close the loop. Use thumbs up/down signals, corrections, and support tickets to refine evaluation criteria. If users consistently flag issues your evals miss, your evals are measuring the wrong things.
Scaling Your LLM Evaluation Strategy for Long-Term Success
True success comes from treating evaluation as continuous, not a one-time checkpoint. This mirrors the philosophy of continuous code health: just as robust software requires unified tooling for quality, LLM-powered systems benefit from integrated evaluation pipelines.
Teams building AI-powered applications benefit from platforms that automate quality gates across the entire development lifecycle. CodeAnt AI brings this approach to code quality, ensuring both your code and model outputs maintain high standards.
Ready to automate your code quality alongside LLM evaluation? Book your 1:1 with our experts today!
FAQs
How often should teams re-evaluate LLM models after deployment?
What factors drive the cost of running LLM evaluation pipelines?
Can teams use one LLM to evaluate another LLM's outputs?
How should teams evaluate LLMs that generate source code?
What is the difference between offline and online LLM evaluation?













