AI Code Review
Severity Without Impact is Just a Label

Sonali Sood

Founding GTM, CodeAnt AI
Struggling to prioritize security fixes when high-severity labels flood your backlog, yet few ever threaten your business? Engineering teams waste up to 50% of remediation time on vulns with zero production impact. This article delivers a step-by-step impact-based framework to focus on what matters, mapping risks to your assets for faster, smarter code health.
Why Severity Alone Fails Modern Engineering Teams
We’ve all been there: you open your security or code quality dashboard, and it screams at you with 500 "Critical" and "High" alerts. The result? You ignore them. When everything is a priority, nothing is a priority. This is the fundamental failure of traditional code analysis tools, they generate noise instead of actionable intelligence.
The problem isn't the detection; it's the context. A "High Severity" SQL injection vulnerability in an internal, offline testing utility is not the same as a "Medium Severity" logic error in your payment gateway’s retry loop. One is a theoretical risk; the other is a guaranteed business loss. To fix code health, we need to stop looking at labels and start looking at consequences.
What Does "Severity Without Impact Is Just a Label" Mean?
Severity and impact are often used interchangeably, but they represent two completely different dimensions of risk.
Severity is a technical risk score compressed into a label. It calculates the likelihood of failure, the blast radius, and the difficulty of detection. It tells you how urgent the issue is from an engineering perspective.
Impact, on the other hand, answers the "so what?" question. It tells you what breaks and who is affected.
"Major" severity means nothing if you don't know if it causes a data breach, a silent calculation error, or just a messy log file. Without impact context, severity is just a scary label that lacks the business justification required to allocate engineering time.
The Pitfalls of Relying Solely on Traditional Severity Ratings
Relying solely on generic severity labels creates a "boy who cried wolf" scenario. Developers eventually tune out alerts because the labels rarely match the actual threat level to the business. A standard static analysis tool might flag a missing input validation as "Low" because it’s a coding weakness, even if that weakness sits on a critical authentication path.
Conversely, it might flag a "Critical" remote code execution vulnerability in a service that has zero external connectivity. This disconnect forces reviewers to manually validate every claim, turning them into human filters for machine noise.
Severity | Definition | Examples |
Critical | Vulnerabilities demanding immediate attention due to high risk of system compromise or data breaches. | Remote code execution, command injection, SQL injection. |
High | Significant risks enabling unauthorized access to resources or sensitive data. | Cross-site scripting (XSS), XML external entity (XXE) injection. |
Low | Less pressing issues with minimal impact, often involving specific coding weaknesses. | Missing input validation, internal information exposure. |
Understanding Impact in Code Security and Quality
To make severity defensible, you must categorize the failure. Impact-based prioritization moves beyond generic "bug" labels and classifies issues based on their actual consequence to the system and the user. This clarity allows teams to prioritize a "Major" correctness issue over a "Critical" but unreachable security flaw.
According to recent engineering research, a robust impact taxonomy includes:
Consumer-facing API behavior: Wrong responses or contract mismatches.
Correctness / Business Logic: Ignored filters, missing validation, or wrong rules.
Security: Auth bypasses, token leakage, or tenant boundary failures.
Reliability: Retries causing duplicates, concurrency races, or cleanup gaps.
Performance & Cost: Hot-path database spikes, full table scans, or unbounded loops.
Observability: Swallowed exceptions or missing metrics.
How Impact-Based Prioritization Works
Impact-based prioritization transforms abstract alerts into testable engineering statements. It works by combining the technical severity of a bug with its environmental context and potential business consequence. Instead of just flagging a syntax error, the system evaluates how that error propagates through the application to affect the end user.
Mapping Vulnerabilities to Critical Assets
Context is everything. An effective analysis pipeline doesn't just look at the line of code; it looks at the call graph and dependency graph. It identifies endpoints, handlers, and service functions to map edits to specific symbols.
By parsing and indexing the codebase, tools can identify if a vulnerability lies within a "hot path" (frequently executed code) or a critical asset like a payment processor. For example, a "retry" wrapper around a database write is technically valid code, but context reveals it causes duplicate billing, a Critical impact that simple syntax checking would miss.
Factoring in Exploitability and Real-World Threat Data
Not all vulnerabilities are created equal. A key part of impact scoring is determining exploitability. Does the attacker need physical access, or can they trigger it remotely? Is the vulnerability in a public-facing API or a buried internal function?
Impact | Access to sensitive information | Requires access to system | Severity Score |
High | Over internet | High | Critical |
Medium | Internet with high level of effort | High | High |
Low | Requires access to system | Low | Medium |
By factoring in real-world threat data, teams can downgrade "Critical" theoretical risks that require impossible access levels and upgrade "Medium" risks that are easily exploitable via public APIs.
Generating Actionable Risk Scores
The final step is generating a composite risk score that engineers can trust. This isn't just a number; it's a synthesis of Severity Level (urgency), Impact Areas (consequence), Steps of Reproduction (proof), and Trace (propagation).
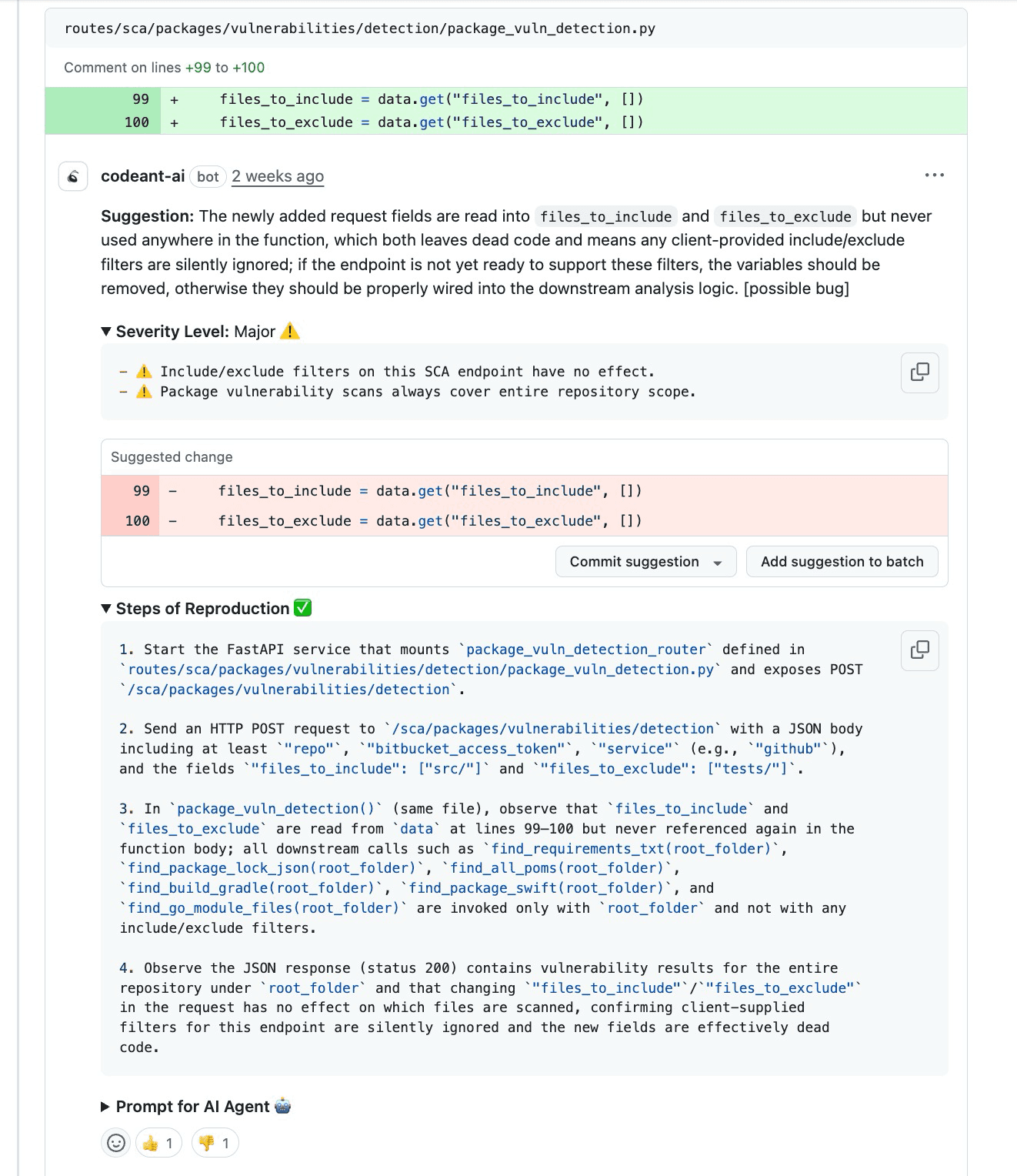
For instance, a risk score calculation might weigh a "silent wrong output" higher than a loud crash because silent failures corrupt data over time without detection. By combining these factors, the output shifts from a claim ("this might be wrong") to a proof ("here is exactly how this breaks").
Best Practices for Impact-Driven Code Health
Implementing impact-driven prioritization requires shifting from passive scanning to active context awareness. It’s about building a system that understands the intent of your code, not just the syntax.
Build a Contextual Asset Inventory
You cannot prioritize what you do not understand. Start by parsing and indexing your repository to identify endpoints, handlers, and service functions. Map your edits to symbols and call sites.
This inventory allows you to tag issues based on the asset they affect. If a bug impacts a consumer-facing API, it automatically carries more weight than a bug in a developer-only script. This "impact area tagging" ensures that resources are focused on maintaining the integrity of business-critical features like billing, authentication, and user data handling.
Automate Impact Assessments in CI/CD
Don't rely on manual triage. Embed impact assessment directly into your CI/CD pipeline using a deterministic processing stage.
Parse + Index: Map the code structure.
Flow-tracing: Follow the call chain from entry point to downstream services.
Risk pattern detection: Identify specific risks like ignored inputs or missing auth checks.
Impact tagging: Categorize into Security, Reliability, or Cost.
Severity scoring: Apply weighted factors based on the findings.
This automation ensures that every Pull Request is evaluated against the same rigorous standard of business impact.
Align Prioritization with Business and DORA Metrics
Code health should directly support business velocity and stability. Align your prioritization with DORA metrics like Change Failure Rate and Mean Time to Recovery.
Focus on impacts that hurt these metrics, such as Reliability issues (retries, concurrency races) that cause production incidents, or Performance issues (unbounded loops) that drive up infrastructure costs. When you frame code health in terms of "reducing cloud bills" or "preventing customer churn," prioritization becomes a business decision rather than just an engineering chore.
Common Mistakes in Severity and Impact Evaluation
The biggest mistake teams make is treating static analysis results as absolute truth without verification. Many tools rely on superficial pattern matching, leading to high false-positive rates that waste developer time.
Another major pitfall is the lack of exploitability proof. That said, manual testing is required to prove exploitability and measure dynamic metrics for a code weakness to graduate to a known vulnerability and higher severity. Without automated trace and reproduction steps, teams are stuck manually verifying every alert, which creates a bottleneck and slows down release cycles.
How CodeAnt AI Delivers Impact-Focused Code Reviews
CodeAnt AI moves beyond simple "suggestions" to behave like a quality gate. We don't just act as a second developer; we provide evidence-first reviews that engineers can verify immediately.
Our platform builds a "Trust Stack" for every finding:
Severity Level: Calculates urgency based on likelihood and blast radius.
Impact Areas: Clearly labels if the issue affects Security, Correctness, or Cost.
Steps of Reproduction: Provides a deterministic checklist (entry point, trigger, expected vs. actual) to prove the bug exists.
Trace + Attack Path: This is our strongest trust feature. We lay out the complete execution path, showing exactly where an input is ignored, where a contract breaks, and how that propagates to a failure.
For example, if we detect a missing tenant filter, we don't just flag it.
We show the Trace: API → auth → query builder → SELECT * (missing constraint).
Then we show the Attack Path: "Token from Tenant A can see Tenant B metadata." This turns a theoretical claim into a proven, actionable engineering task.
Conclusion
Severity labels alone are a relic of the past. In modern software engineering, a "Critical" label without a clear impact description is just noise. By shifting to impact-based prioritization, teams can cut through the clutter, focus on the risks that actually threaten the business, and move from arguing about false positives to fixing real problems. With tools like CodeAnt AI, you get more than just a label, you get the proof, the trace, and the confidence to ship better code faster. Try it out yourself here.
FAQs
How do you implement impact-based prioritization in a CI/CD pipeline?
What DORA metrics should guide impact prioritization for code health?
How does CodeAnt AI prove exploitability in its traces?
What's the difference between severity and exploitability in risk scoring?
Can impact tagging reduce false positives in static analysis?













