AI Code Review
Trace-First AI Reviews: Explaining How Bugs Actually Propagate

Sonali Sood

Founding GTM, CodeAnt AI
Struggling to understand how a small code change turns into a production incident weeks later? Traditional code reviews and early AI tools catch surface-level issues but fail at the one thing engineers actually need: proving how a bug propagates through the system.
Trace-first AI reviews change that by showing the exact execution path from input to impact, turning vague warnings into verifiable engineering facts.
Why Most Code Reviews Fail at the Hard Part
Code reviews rarely fail because engineers miss syntax errors. They fail because reviewers can’t easily answer one question:
“How does this break in production?”
Traditional reviews rely on pattern recognition:
A risky function call
A missing validation
A suspicious retry loop
But without execution context, reviewers are forced to infer impact mentally. That doesn’t scale in modern systems with microservices, async flows, feature flags, and layered abstractions.
Early AI tools made this worse. They behave like an eager second developer:
Lots of suggestions
Minimal prioritization
Little proof of reachability
When engineers must manually verify whether an AI finding is real, trust collapses. Reviews slow down instead of speeding up.
What Trace-First AI Reviews Actually Mean
Trace-first AI reviews reverse the default approach. Instead of starting with a finding, they start with propagation.
A trace-first review answers four non-negotiable questions:
Where does input enter the system?
How does it flow across functions, services, and layers?
Where does behavior diverge from intent?
What observable impact does that divergence create?
Only after these are answered does the AI assign severity.
This turns code review from opinionated suggestions into testable engineering statements.
Severity Without Propagation Is Just a Guess
Most tools lead with severity labels:
Critical
High
Medium
But severity without propagation context is meaningless.
A “Critical” vulnerability in unreachable code is theoretical.
A “Medium” logic bug in a payment retry loop is guaranteed damage.
Trace-first reviews never show severity alone. They pair it with:
Impact Area (security, correctness, reliability, cost)
Execution Trace (how the bug travels)
Reproduction Steps (how to prove it exists)
Severity becomes defensible instead of debatable.
How Trace-First AI Reviews Work (Under the Hood)
Trace-first systems use a deterministic pipeline rather than pure pattern matching.
1. Parse and Index the Codebase
The AI maps:
API endpoints
Handlers and jobs
Service boundaries
Critical domain functions
This establishes entry points and blast radius candidates.
2. Flow-Trace Execution Paths
From each entry point, the AI follows:
Function calls
Async boundaries
Retries and side effects
Data transformations
This produces a call-graph-backed execution path, not a guess.
3. Detect Risk Patterns in Context
The AI flags issues only when they are reachable, such as:
Ignored filters
Missing authorization propagation
Retries wrapping side effects
Unbounded loops on hot paths
If the pattern cannot be traced to impact, it isn’t flagged.
4. Tag Impact Areas
Each finding is mapped to a concrete impact:
Security
Correctness / business logic
Reliability
Performance & cost
Observability
This replaces vague “bug” labels with actionable categories.
From Input to Impact: Making Bugs Explicit
A trace-first review doesn’t say “this looks risky.”
It shows exactly how it fails.
Example trace:
Entry point:
POST /scanreceives requestParsing:
files_to_includeextractedLogic gap: filter never passed to scanner
Downstream: full repository walk executed
Output:
200 OKreturned
The system “works,” but violates the contract silently. This is how production incidents are born.
Why Traces Eliminate False Positives
Early AI tools often hallucinated issues:
Claiming variables were unused when they weren’t
Flagging vulnerabilities in dead code
Reporting risks blocked by feature flags
Trace-first reviews prevent this by requiring proof. If the AI cannot generate a valid execution trace from input to impact, the issue is discarded. No trace, no alert. This single constraint eliminates most alert fatigue.
Reproduction Steps: Turning Reviews Into Proof
Every trace-first finding includes deterministic reproduction steps:
Trigger conditions
Required inputs or headers
Expected vs actual behavior
Observable evidence (logs, outputs, metrics)
This allows any engineer to verify the issue in minutes. Fixes can be validated against the same steps, closing the loop.
Why This Changes Developer Trust
When engineers see traces instead of suggestions:
Review time drops
Debate disappears
Fixes converge faster
The conversation shifts from “Is the tool right?” to “Here’s the fix.” This is the difference between AI as a commenter and AI as a quality gate.
Implementing Trace-First Reviews with CodeAnt AI
CodeAnt AI is built around this trace-first philosophy.
It integrates directly into Git PR workflows and runs automatically on every pull request. Instead of scanning only changed lines, it analyzes the entire execution context to calculate blast radius before merge.
What CodeAnt AI Provides for Every Finding
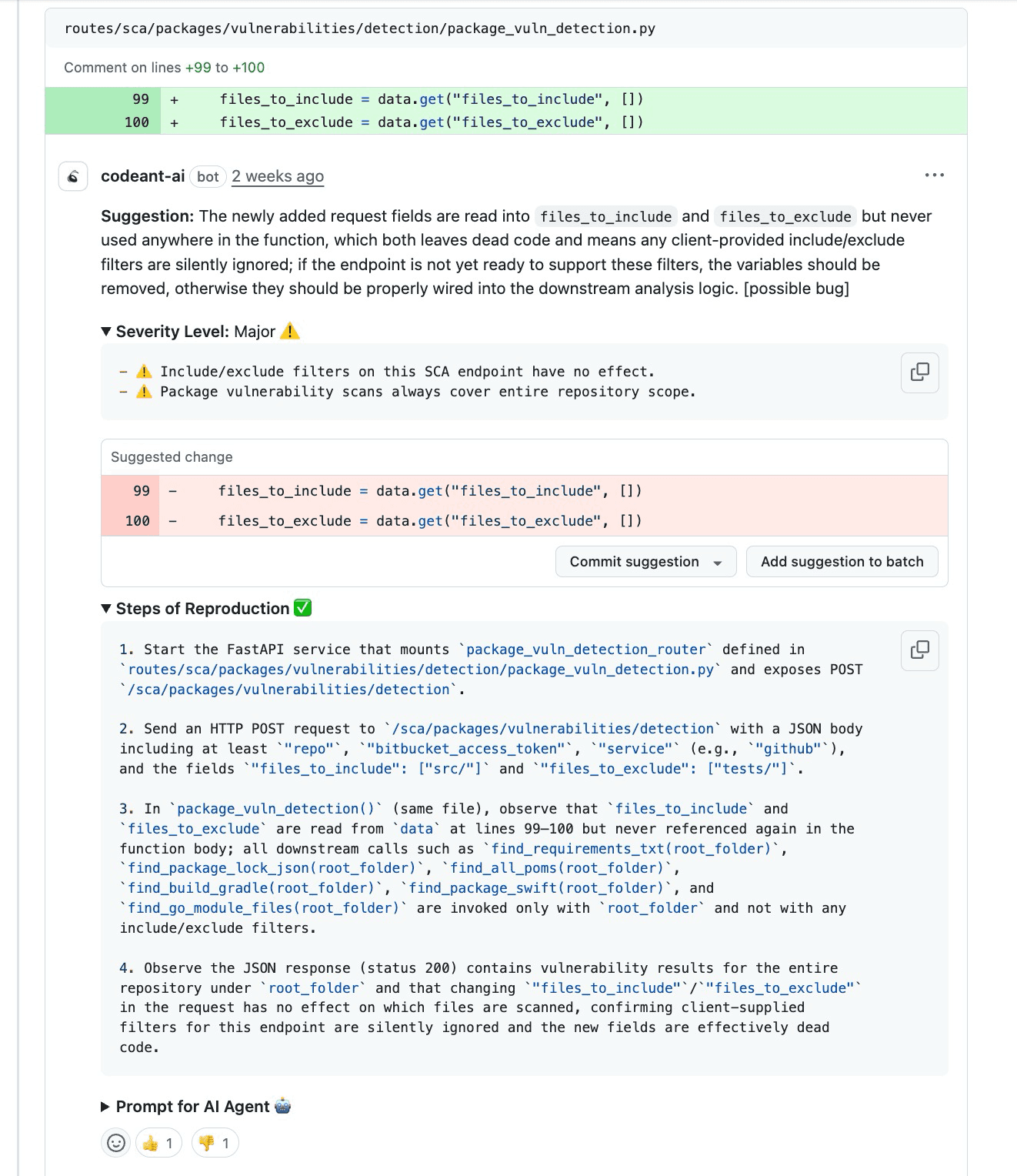
Severity Level based on likelihood and blast radius
Impact Area explaining what breaks and who is affected
Trace + Attack Path showing exact propagation
Steps of Reproduction to prove the issue exists
This turns every review comment into an engineering artifact, not an opinion.
Best Practices for Effective Trace-First Reviews
To get the most out of trace-first reviews, teams should treat the AI's output as a "pre-read" for the human reviewer.
Read the trace before the diff
Prioritize by impact, not label
Verify fixes using reproduction steps
Treat AI output as pre-read, not verdict
When used this way, trace-first reviews reduce review cycles by 30–50% and prevent silent failures from ever reaching production.
Common Mistakes Trace-First Reviews Eliminate
Trusting severity labels without context
Fixing symptoms instead of root causes
Ignoring silent wrong output because tests passed
Shipping retries, loops, or filters without understanding amplification
Trace-first reviews force correctness at the system level.
Conclusion: From Guesswork to Engineering Proof
Moving to trace-first AI reviews is about moving from guesswork to engineering precision. By requiring Severity Levels, Impact Areas, Reproduction Steps, and Execution Traces, we strip away the noise and focus on what actually breaks.
This approach transforms the code review process. It empowers developers with the context they need to understand complex bugs instantly and gives leadership the confidence that the "quality gate" is actually working. In the end, it’s not just about finding bugs; it’s about proving they exist so you can fix them fast.
FAQs
How do you set up trace-first AI reviews in GitHub PRs?
What differentiates trace-first AI from tools like GitHub Copilot or SonarQube?
Can trace-first reviews handle microservices or monorepos?
How accurate are traces for dynamic languages like Python or JavaScript?
What's the ROI of switching to trace-first AI reviews?













