AI Code Review
Understand the SWE-Bench Leaderboard 2026 in Depth

Sonali Sood

Founding GTM, CodeAnt AI
Updated: April 13, 2026
Every week a new AI model "tops the SWE-bench leaderboard." Marketing teams celebrate. CTOs get forwarded the benchmark page. Then the model ships to production and starts missing bugs their senior engineers would catch in 30 seconds.
This page has one job: give you the actual numbers, explain what they mean, and tell you what SWE-bench doesn't measure, so you can make real decisions about AI coding tools for your team.
SWE-Bench Verified Leaderboard: April 2026
SWE-bench Verified tests AI models on 500 real GitHub issues from popular Python repositories. Models must submit code patches that fix the bug without breaking existing tests. As of April 2026, Claude Mythos Preview leads at 93.9%, followed by GPT-5.3 Codex at 85% and Claude Opus 4.5 at 80.9%. The average score across all 83 evaluated models is 63.4%.
Rank | Model | SWE-bench Verified | SWE-bench Pro | Notes |
|---|---|---|---|---|
1 | Claude Mythos Preview | 93.9% | — | Anthropic |
2 | GPT-5.3 Codex | 85.0% | 57.0% | OpenAI |
3 | Claude Opus 4.6 | 80.9% | 45.9% | Anthropic |
4 | Claude Opus 4.5 | 80.9% | 45.9% | Anthropic |
5 | Gemini 3 Flash Preview | 57.6% | — | |
6 | Gemini 3 Pro Preview | 56.5% | — | |
7 | GPT-5 (High) | ~55% | 23.3% | OpenAI |
— | Average (83 models) | 63.4% | ~25% | — |
Sources: BenchLM.ai, llm-stats.com, Scale AI SEAL Leaderboard. Last updated April 13, 2026. Pro scores use Scale AI's standardised scaffolding. Dash (—) means not yet published on that variant.
What is SWE-Bench?
SWE-bench is a benchmark that gives an AI model a real GitHub issue and a codebase, then asks it to write a code patch that fixes the bug without breaking existing tests. Created by Princeton researchers in 2024, it uses actual software engineering tasks from real projects: Django, Flask, scikit-learn, and nine others. Unlike older benchmarks that test isolated coding puzzles, SWE-bench tests the full engineering workflow: understand the issue, navigate the codebase, write the fix, verify it works.
The benchmark exists in three versions. The original SWE-bench has 2,294 tasks and is rarely cited now because it's too easy for frontier models. SWE-bench Verified is a human-validated subset of 500 tasks where annotators confirmed the issues are solvable and the tests are reliable, this is the version almost everyone refers to when they say "SWE-bench score." SWE-bench Pro is the newest and hardest version, built by Scale AI to be contamination-resistant, more on that shortly.
Why did it become the standard? Because it's the most realistic coding benchmark that existed before 2026. HumanEval asks models to complete isolated function stubs. SWE-bench asks them to debug a real bug in a real project with real tests. That's a much harder and more meaningful test of actual software engineering capability, which is why AI labs began racing to top it.
The Real Problem: SWE-Bench Verified is Contaminated
OpenAI's internal audit found that every major frontier model, GPT-5.2, Claude Opus 4.5, Gemini 3 Flash, could reproduce verbatim gold patches for some SWE-bench Verified tasks. The 500 Python tasks appeared in model training data before the benchmark was published. This means models are partly "remembering" answers, not solving them from scratch. OpenAI stopped reporting Verified scores in early 2026 and now recommends SWE-bench Pro instead.
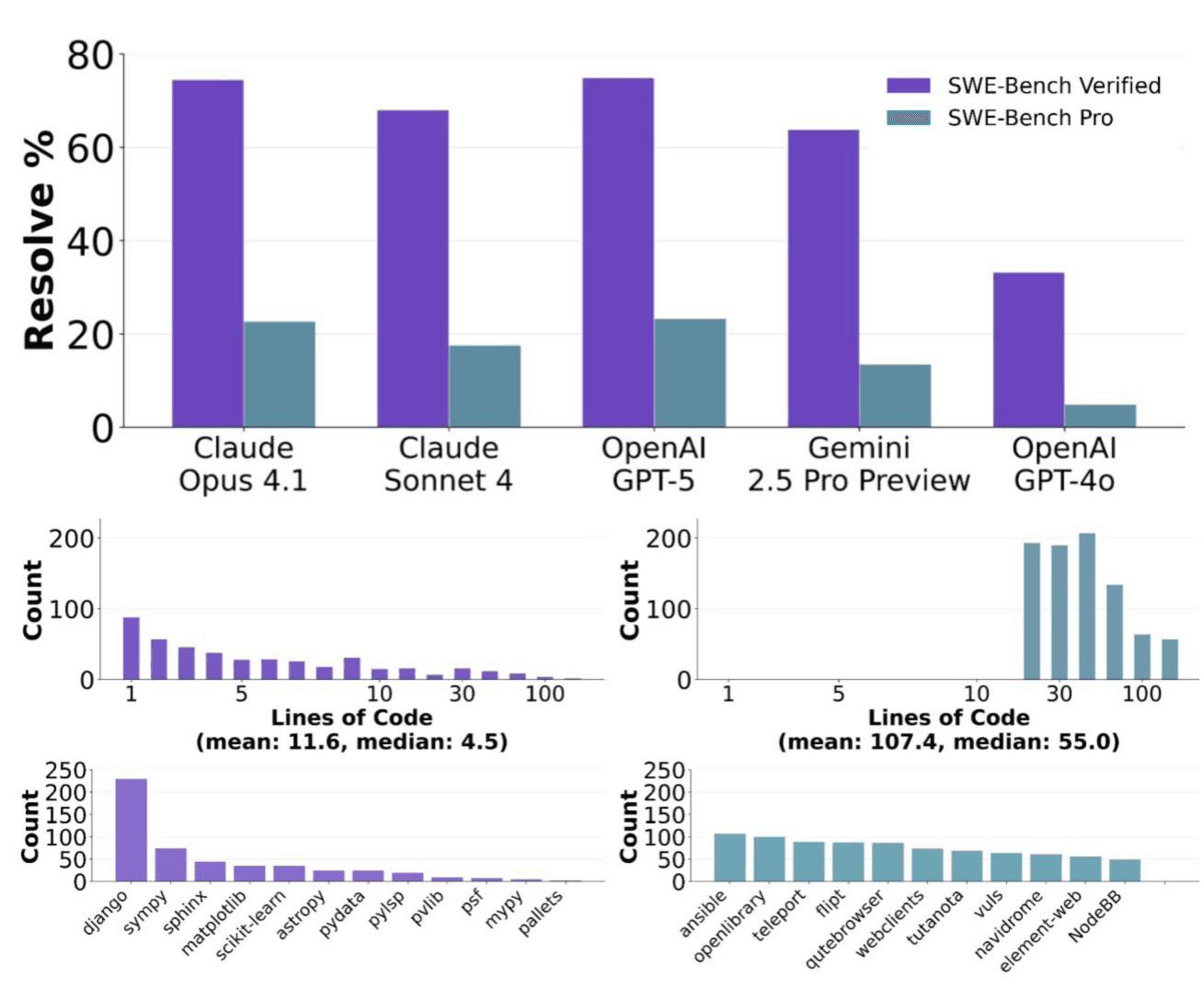
Here's the number that proves it. Claude Opus 4.5 scores 80.9% on SWE-bench Verified. The same model, on SWE-bench Pro, using standardised scaffolding on tasks it could not have seen during training, scores 45.9%. That's not a small margin. That's a 35-point drop on the same model doing the same kind of task. GPT-5 High goes from roughly 55% on Verified to 23.3% on Pro.
OpenAI's audit also found that 59.4% of the hardest unsolved Verified problems had flawed test cases, meaning the benchmark itself had quality issues in the tasks that are supposed to be the hardest. This is why you should treat SWE-bench Verified as a rough directional signal, not a precise measurement. A model at 80% Verified is almost certainly better than a model at 40% Verified, but the exact number carries far less precision than the leaderboard formatting suggests.
SWE-Bench Pro: The Harder, Cleaner Benchmark
SWE-bench Pro contains 1,865 tasks across 41 actively maintained repositories in Python, Go, TypeScript, and JavaScript, including private proprietary startup codebases that have never been publicly available. Tasks come from real commit histories. Because the private codebases are legally inaccessible to model trainers, contamination is structurally prevented. The best model currently scores 57% on Pro. The average is around 25%.
Scale AI built SWE-bench Pro through their SEAL lab (Scale's Evaluation and Assessment Lab). What makes it trustworthy is the standardised scaffolding: every model runs through identical tooling with a 250-turn limit. This removes one of the biggest distortions in Verified scores, the fact that vendors can tune their agent scaffolding (the framework around the model) to game specific benchmark tasks. On SEAL, you're comparing raw model capability, not scaffolding engineering.
The private subset makes Pro scores even more interesting for enterprise teams. Claude Opus 4.1 drops from 22.7% to 17.8% on private codebases. GPT-5 falls from 23.1% to 14.9%. Even the best models perform materially worse on code they've never seen before, which is exactly the situation your engineering team is in. Your codebase is not Django. Your bugs are not in scikit-learn's issue tracker.
What SWE-Bench Doesn't Measure, and Why it Matters for Enterprise
SWE-bench measures bug-fixing ability on familiar open-source Python repos. It does not test security vulnerability detection, code review quality, non-Python languages, maintainability, compliance with organisational coding standards, performance under production load, or behaviour on private codebases. A model scoring 93% on SWE-bench Verified may still introduce SQL injection vulnerabilities, generate unreadable code, or fail completely on your Go microservices.
Here's what's missing from the benchmark, broken down explicitly:
Security scanning: SWE-bench tests whether a patch fixes a bug and passes tests. It does not test whether the patch introduces a new OWASP Top 10 vulnerability. A model can score 90% on SWE-bench while routinely writing code with authentication flaws, injection vulnerabilities, and insecure dependencies.
Language breadth: SWE-bench Verified is Python-only. SWE-bench Pro adds Go, TypeScript, and JavaScript. If your team writes Java, Kotlin, Rust, C++, or anything else, benchmark scores give you no signal at all about performance on your stack.
Code review quality: SWE-bench tests code generation (write a fix). It says nothing about code review (evaluate someone else's code). These are fundamentally different tasks that use different model strengths.
Private codebase reasoning: All Verified tasks are from public open-source projects. Models have seen this code during training. Your codebase is private. Performance will always be lower on your actual code than on benchmark tasks.
Organisational standards: Every engineering team has rules: naming conventions, approved libraries, architectural patterns, security policies. SWE-bench tests none of this. A model that tops the leaderboard may still fail your internal PR review process constantly.
Long-horizon multi-file changes: SWE-bench tasks average fixes across 2–3 files. Enterprise bugs often require changes across 10–30 files with complex dependency chains. Benchmark performance does not extrapolate linearly to this complexity.
How SWE-Bench differs from HumanEval and MBPP
Benchmark | Task Type | Codebase Context | Real-World Relevance |
HumanEval | Single-function generation | None | Low |
MBPP | Basic programming problems | None | Low |
SWE-Bench | Bug fixing from GitHub issues | Full repository | High |
HumanEval and MBPP measure whether a model can write correct code in isolation. SWE-Bench measures whether it can operate within a real project, which is a much harder test.
SWE-Bench Verified vs Lite vs Full
The benchmark comes in several variants:
SWE-Bench Full: The complete dataset of GitHub issues across multiple repositories
SWE-Bench Lite: A curated subset designed for faster evaluation
SWE-Bench Verified: Human-validated subset that reduces noise and confirms each task has a clear, achievable solution
SWE-Bench Verified matters most for serious evaluation because it filters out ambiguous issues.
How SWE-Bench Pro Raises the Bar Beyond Vanilla SWE-Bench
SWE-Bench Pro was introduced to address many of the limitations that surfaced as models began saturating earlier benchmark variants. While the original SWE-Bench measures whether a model can go from issue to patch to passing tests, Pro adds structural safeguards and task design choices that make it a more discriminative and realistic benchmark for modern AI agents.
Three-way dataset split for contamination resistance
One of the biggest challenges with any public benchmark is training data leakage. SWE-Bench Pro explicitly tackles this by splitting tasks across three tiers: public repositories, held-out private GPL repositories reserved to prevent overfitting, and commercial codebases sourced from real startups. The commercial tier is never released publicly; only evaluation results are shared. This makes memorization far less effective as a strategy and improves confidence that scores reflect reasoning, not recall.
Long-horizon, non-trivial tasks by construction
Unlike earlier splits that include small or localized fixes, Pro filters out trivial issues by design. Tasks typically require substantial multi-file changes, with the paper reporting an average of roughly 107 lines of code across just over four files. This shifts the benchmark away from “find the obvious bug” and toward the kind of extended reasoning and coordination real engineering work demands.
Human augmentation to make tasks resolvable
SWE-Bench Pro uses a human-in-the-loop workflow to clarify ambiguous issues and add missing context without simplifying the underlying challenge. This reduces failure modes where agents fail simply because an issue is underspecified, allowing the benchmark to better measure true problem-solving ability rather than prompt interpretation luck.
Stronger verification through improved test recovery
Test quality is a quiet but critical factor in any benchmark. Pro introduces mechanisms to recover or strengthen unit tests so that correct fixes are less likely to fail due to flaky, missing, or overly strict verifiers. This reduces false negatives and makes pass rates more meaningful as signals of actual correctness.
Broader, enterprise-style repository mix
Instead of focusing heavily on a small set of popular open-source libraries, SWE-Bench Pro draws problems from 41 actively maintained repositories spanning business applications, B2B software, and developer tools. This diversity better reflects the kinds of systems engineering teams actually run, rather than just the most commonly forked Python projects on GitHub.
Harder and more discriminative today
Even under a unified evaluation scaffold, strong models and agents remain well below “near-solved” territory on Pro. Baseline results reported in the paper show pass@1 rates below 25%, making it significantly more discriminative than easier splits like Verified. As a result, Pro currently does a better job separating incremental capability gains from benchmark saturation effects.
If you want a deeper breakdown of how SWE-Bench Pro differs methodologically from earlier variants, including task construction and evaluation scaffolds, we’ve covered that in a dedicated comparison below.
Benchmark | Primary Task Type | Codebase Scope | Contamination Resistance | Task Complexity | Enterprise Relevance |
|---|---|---|---|---|---|
HumanEval | Function generation | None | Low | Low | Very Low |
MBPP | Basic programming problems | None | Low | Low | Very Low |
SWE-Bench | Issue-based bug fixing | Popular OSS repos | Medium | Medium | Limited |
SWE-Bench Verified | Bug fixing with validated tasks | Popular OSS repos | Medium | Medium | Limited |
SWE-Bench Pro | Long-horizon issue resolution | OSS + private + commercial | High | High | Higher (still partial) |
SWE-Bench Pro is a meaningful step forward, but it still evaluates models in isolation from the review workflows, security constraints, and organizational standards that define real-world engineering environments.
How SWE-Bench Evaluates LLM Coding Performance
Understanding what a SWE-Bench score actually measures helps you interpret leaderboard results and recognize their limits.
Real GitHub issues as test cases
Each task comes from an actual pull request merged into a popular open-source Python repository. The model receives the issue description and repository context, then attempts to locate and fix the problem. This mirrors how developers approach bug reports in practice.
Bug localization and patch generation tasks
The challenge has two parts. First, the model identifies which files and functions contain the bug. Then it generates a code patch that resolves the issue. Both steps require understanding the codebase structure, not just writing syntactically correct code.
Pass rate scoring and leaderboard rankings
Pass rate equals the percentage of issues where the model's patch passes all associated tests. Leaderboards rank models by this metric. A model scoring 40% on SWE-Bench Verified resolves 40% of the test issues correctly, at least according to the test suite.
Where SWE-Bench Predicts Real-World LLM Performance
High SWE-Bench scores do correlate with practical coding ability in certain scenarios. Here's where the benchmark genuinely predicts performance.
Bug fixing and issue resolution
Models that score well on SWE-Bench typically handle straightforward bug fixes effectively. If your team uses AI assistants for triaging and patching known issues, benchmark performance offers a reasonable signal.
Codebase navigation and context understanding
SWE-Bench tests a model's ability to read and understand large codebases. This skill transfers to real development work. Models that struggle here will likely struggle when you ask them to work with your repositories.
Multi-file code changes
The benchmark requires edits across multiple files, which predicts how well an LLM handles complex, interconnected changes. This matters for feature development and refactoring tasks, not just isolated fixes.
Evidence That LLMs Memorize SWE-Bench Solutions
Microsoft researchers and others have investigated whether high scores reflect genuine reasoning or memorization. The findings are sobering.
File path identification experiments
Researchers tested whether models could identify the correct file paths to modify without seeing the issue description. Some models succeeded at rates suggesting they'd memorized repository structures from training data.
Function reproduction tests
In another experiment, models were asked to reproduce exact function implementations given only partial context. High reproduction accuracy indicated potential training data leakage rather than reasoning ability.
Benchmark contamination research findings
Multiple studies have found evidence of memorization, particularly for older, widely-circulated issues. Data contamination occurs when test data appears in a model's training set, causing inflated scores. SWE-Bench Verified attempts to address this, but the problem persists for models trained on large web corpora.
How SWE-Bench Compares to Other LLM Coding Benchmarks
SWE-Bench isn't the only benchmark worth watching. Here's how it fits into the broader landscape.
HumanEval for function-level code generation
HumanEval tests isolated function writing. It's useful for measuring basic code synthesis but lacks the complexity of real software engineering. Think of it as a baseline, not a ceiling.
MBPP for basic programming problems
MBPP (Mostly Basic Programming Problems) evaluates simple programming tasks. It serves as another baseline but doesn't test codebase navigation or multi-file changes.
Agentic benchmarks for tool use and automation
Newer benchmarks test LLMs using external tools, browsing documentation, and multi-step reasoning. Agentic benchmarks come closer to how AI coding assistants actually operate and may prove more predictive for production use cases.
How to Evaluate AI Coding Tools for Your Enterprise Team
To evaluate AI coding tools properly for enterprise use: run a 30-day pilot on your own private codebase, measure false positive rate in code review (target under 15%), check language coverage matches your stack, test OWASP Top 10 vulnerability detection, and track DORA metrics before and after deployment. Do not make the final decision based on SWE-bench scores alone.
Here is a practical 5-step evaluation framework your team can run:
Step 1: Pilot on your own codebase, not demos
Take your last 50 merged pull requests and run the AI tool on them retrospectively. See what it catches, what it misses, and how many of its comments your engineers would agree with. This is the only test that actually predicts production performance.
Step 2: Measure false positive rate
Count how many AI review comments are wrong or irrelevant. Enterprise teams need this below 15%, above that, engineers start ignoring all AI comments, including the correct ones. Tools that top SWE-bench benchmarks often have high false positive rates in code review because they're optimised for different tasks.
Step 3: Check language coverage for your stack
If you write Java, Python, TypeScript, and Go, you need a tool that covers all four well, not just one. Ask vendors for language-specific benchmark data, not overall scores.
Step 4: Test security detection against OWASP Top 10
Build a test suite of ten code samples, each containing one OWASP Top 10 vulnerability. Run every tool you're evaluating against it. Count how many each tool catches. This is the test that actually matters for enterprise AppSec teams.
Step 5: Track DORA metrics over a 30-day pilot
Measure deployment frequency, lead time for changes, change failure rate, and mean time to recovery before and after deploying the tool. If it's genuinely improving code quality, these numbers move. If they don't, the tool isn't having a real impact regardless of its benchmark score.
See how CodeAnt AI performs on your codebase, not on benchmarks. CodeAnt AI reviews pull requests with full codebase context, detects security vulnerabilities across 30+ languages, and integrates with GitHub, GitLab, Azure DevOps, and Bitbucket.
The Bottom Line on SWE-Bench in 2026
SWE-bench Verified is the most widely cited AI coding benchmark and a useful directional signal. A model at 80% is genuinely more capable than one at 40%. But the absolute numbers are inflated by contamination, the Python-only focus misses most enterprise stacks, and the bug-fixing task format tells you nothing about code review, security detection, or private codebase performance.
Use SWE-bench Pro scores where available. Run your own evaluation on your actual codebase. Measure the things that matter to your engineering team, false positive rate, security coverage, language support, and impact on DORA metrics, not the leaderboard number a vendor put in their sales deck.
Ready to see how AI code review actually performs on your codebase? CodeAnt AI reviews pull requests across GitHub, GitLab, Azure DevOps, and Bitbucket, catching security vulnerabilities, enforcing standards, and cutting review time for enterprise teams.
FAQs
What does a high SWE-bench score actually mean?
Which AI model leads SWE-bench in 2026?
Is SWE-bench Verified contaminated?
What is SWE-bench Pro and how is it different from Verified?
Why did OpenAI stop reporting SWE-bench Verified scores?













