AI Code Review
Why Token Pricing Misleads LLM Buyers: The Real Cost Metrics That Matter

Sonali Sood

Founding GTM, CodeAnt AI
You found the model with the lowest per-token price. You ran the numbers. You projected costs. Then your actual invoice arrived, and it was three times what you expected.
Token pricing feels like a straightforward metric for comparing LLMs, but it obscures more than it reveals. Cheaper models often require longer prompts, more retries, and extra human review to produce usable results. This guide breaks down why per-token costs mislead buyers, what hidden expenses actually drive LLM spend, and which metrics give you an accurate picture of total cost.
Why Token Pricing Creates a False Sense of Cost Control
Token pricing looks simple: pay per token, predict your costs, done. But here's the catch. Cheaper, lower-quality models often require longer prompts, more retries, and extra human review to get usable results. A more capable model might cost more per token yet deliver accurate answers faster, sometimes at lower total cost.
The real expense isn't what you pay per token. It's what you pay to get a successful outcome.
Token counts vary across models and providers
Different LLMs tokenize the same text differently. A tokenizer is the component that breaks your input into chunks the model can process. The same prompt might become 100 tokens on one model and 150 on another.
This variation breaks direct price comparisons:
GPT-4: Uses byte-pair encoding optimized for English
Claude: Tokenizes with different rules, producing different counts
Open-source models: Often use entirely separate tokenization schemes
So when you see "$X per million tokens," you're not comparing apples to apples. You're comparing apples to something that might cost 30% more once you account for how your actual prompts get tokenized.
Context windows inflate actual token usage
A context window is the maximum amount of text a model can process in a single request. Larger windows sound great because they allow more context and better answers. But every token in that window costs money, even the parts that don't directly contribute to your output.
System prompts, conversation history, few-shot examples, and instructions all consume tokens invisibly. A 4,000-token response might require 20,000 tokens of input context. Your invoice reflects the full 24,000 tokens, not just the useful output.
Reasoning models consume more tokens than expected
Advanced reasoning models, including chain-of-thought or agentic workflows, generate many intermediate tokens while "thinking." These tokens appear on your bill but never show up in your final output.
A model that reasons through a problem step-by-step might generate 2,000 tokens internally to produce a 200-token answer. If you're only looking at output token pricing, you'll dramatically underestimate your actual costs.
Hidden Costs Beyond Per-token Pricing
Token pricing captures only a fraction of what you'll actually spend. The expenses that never appear on a token-based invoice often dwarf the API costs themselves.
Compute and infrastructure overhead
Even API-based models require infrastructure on your end:
Orchestration layers: Managing requests, handling rate limits, implementing retry logic
Monitoring and logging: Tracking usage, debugging failures, maintaining audit trails
Security controls: API key management, access controls, data handling compliance
Self-hosted models add GPU procurement, cooling, maintenance, and scaling complexity. None of this appears in per-token calculations.
Latency costs and productivity loss
Faster models cost more per token. Slower models waste developer time. This tradeoff rarely gets quantified, yet it directly impacts productivity.
Inference latency, the time between sending a request and receiving a response, varies dramatically across models and providers. A developer waiting 10 seconds per response instead of 2 seconds loses significant time over hundreds of daily interactions.
Experimentation during development
Teams burn through tokens during development before production even begins. Prompt iteration, A/B testing, model evaluation, and debugging all consume tokens at rates that often surprise buyers who only planned for production usage.
A single engineer refining prompts might use more tokens in a week of development than a production system uses in a month.
Integration and ongoing maintenance
LLM APIs change. Models get deprecated. Behavior shifts between versions. The engineering effort to integrate, maintain, and update your LLM integrations accumulates over time.
When a provider updates their model and your carefully tuned prompts stop working, someone has to fix them. That's engineering time, and it's expensive and unpredictable.
How LLM Vendor Pricing Models Differ
The same workload costs differently across vendors, and not just because of per-token rates.
Provider | Pricing model | Key considerations |
OpenAI | Per-token (input/output split) | Tiered pricing by model capability; cached prompts reduce costs |
Anthropic | Per-token (input/output split) | Different rates for Claude variants; context window affects pricing |
Per-character or per-token | Varies by Gemini model tier; enterprise agreements available | |
Open-source | Infrastructure-only | No API fees but full compute burden; scaling complexity |
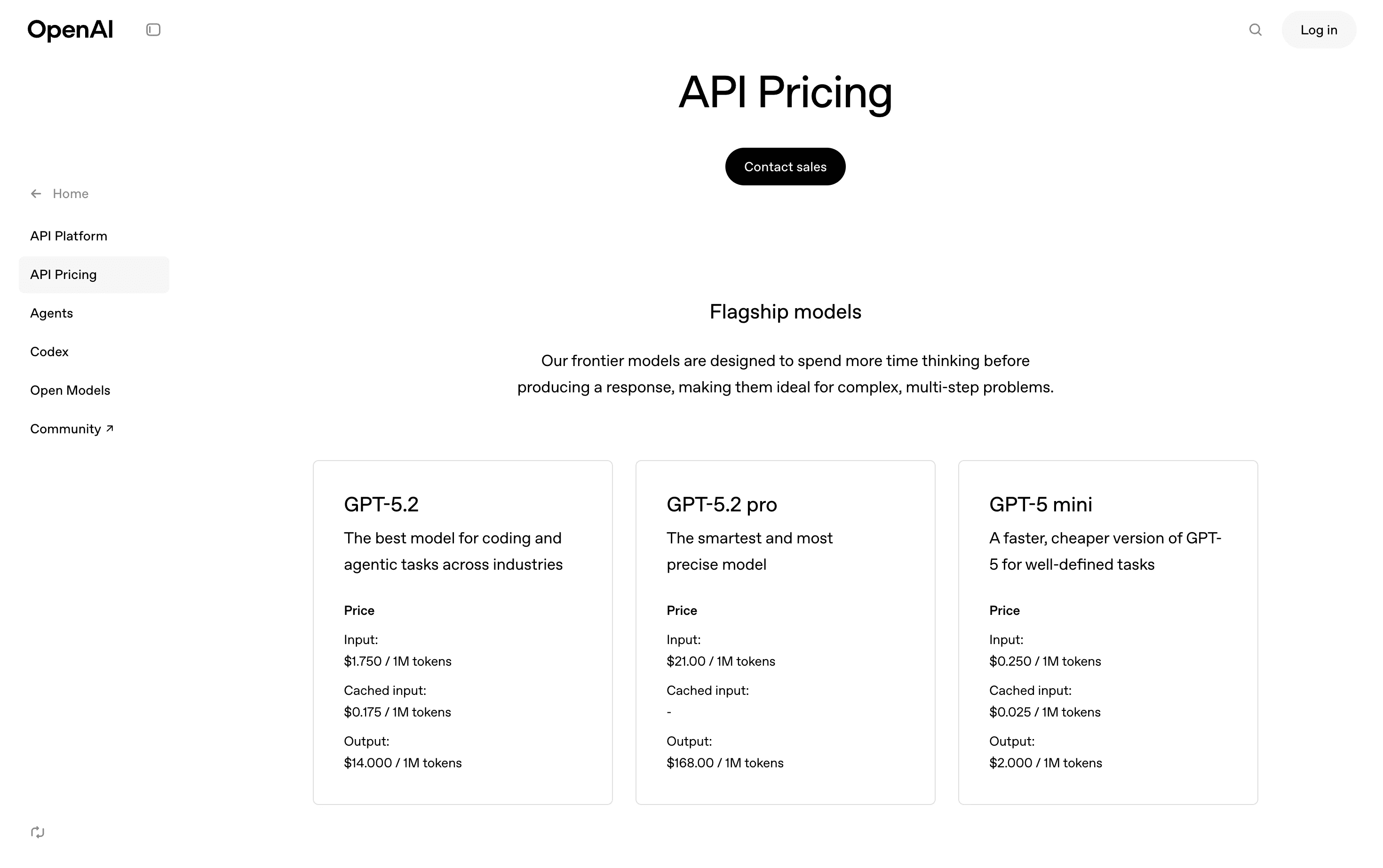
OpenAI
OpenAI charges different rates for input and output tokens, with newer models typically costing more per token. However, newer models often complete tasks with fewer tokens and fewer retries, potentially lowering total cost despite higher rates. Prompt caching can reduce costs for repeated system prompts.
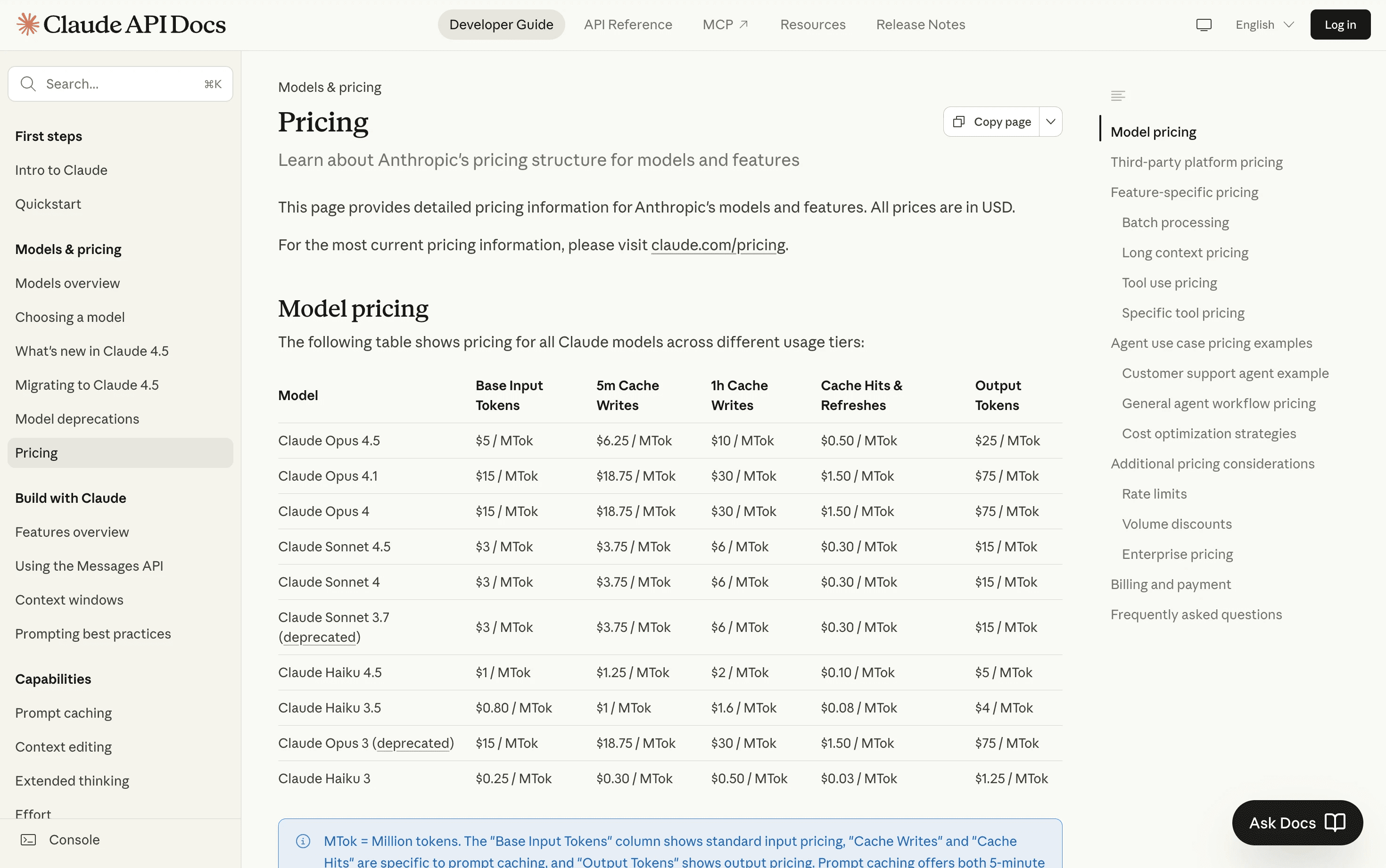
Anthropic
Claude's pricing tiers reflect model capability, with larger context windows generally costing more. Long-context workloads can become expensive quickly if you're not careful about what you include in each request.
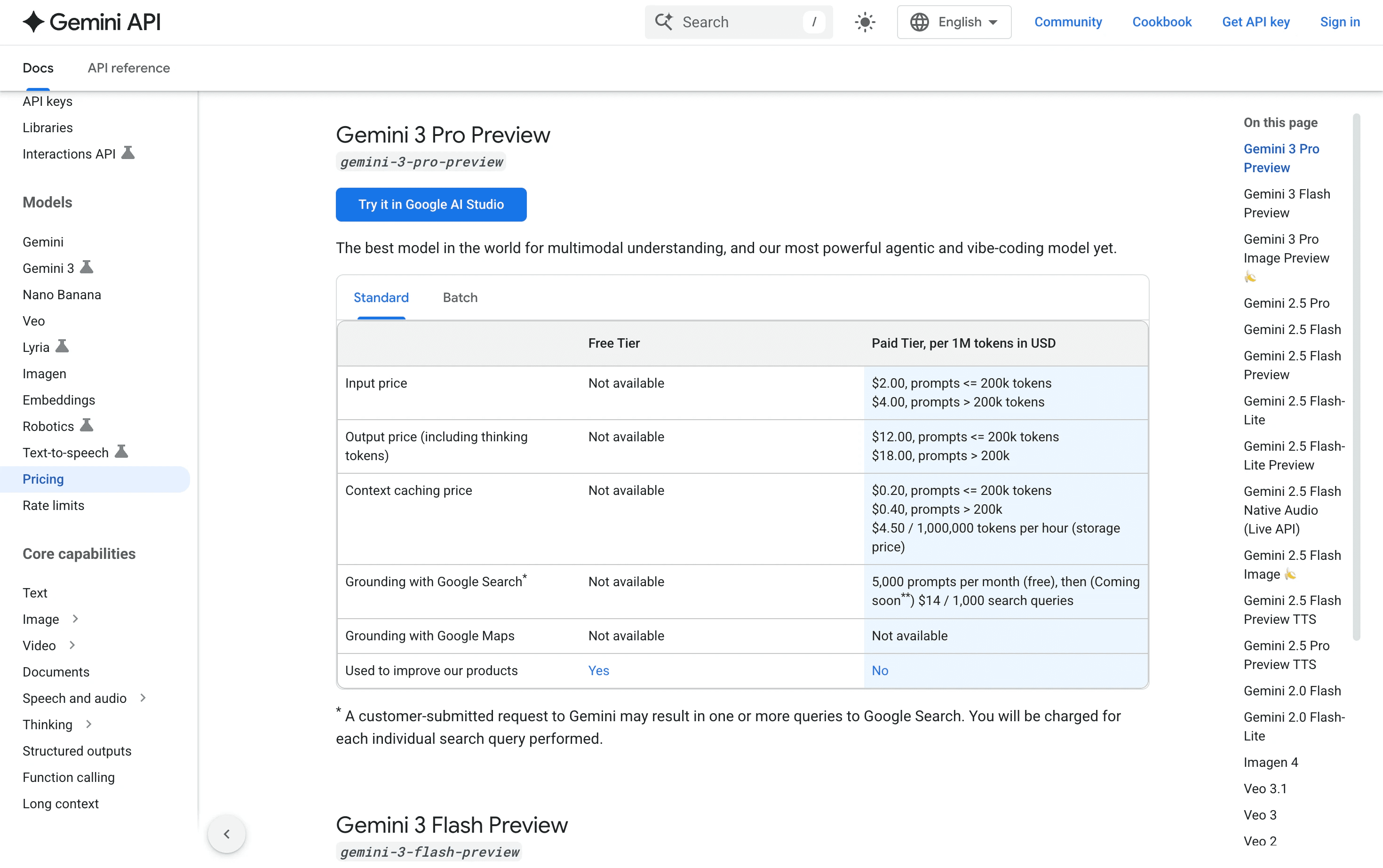
Gemini's pricing varies by model tier and sometimes uses character-based pricing for certain APIs. Google's infrastructure scale allows competitive pricing, but the pricing structure can be less intuitive than competitors.
Open-source and self-hosted models
"Free" models still cost money to run. You trade API fees for full responsibility over compute, scaling, and maintenance. For high-volume, predictable workloads, self-hosting can be dramatically cheaper. For variable or experimental workloads, the operational overhead often exceeds API costs.
The Real Metrics for Evaluating LLM Cost
If token pricing misleads, what metrics actually matter? Four metrics capture the true economics of running LLMs in production.
Cost per successful task completion
This metric divides total spend by successful outputs. A cheap model that fails often costs more than an expensive model that succeeds consistently.

A model with a 60% success rate at $0.01 per attempt costs more per success than a model with a 95% success rate at $0.03 per attempt.
Total cost of ownership
TCO includes everything: tokens, compute, engineering time, monitoring, maintenance, and the cost of errors. This metric reveals the true expense of running LLMs in production.
Most teams underestimate TCO by a significant margin when they focus only on token pricing. Infrastructure, latency, experimentation, and maintenance all belong in this calculation.
Latency-adjusted productivity cost
Response time affects developer productivity. A model that takes twice as long effectively costs more in human time, even if the token price is identical.
Calculate this by combining token cost with the time value of waiting. If your developers spend 10 minutes daily waiting for LLM responses, that productivity cost likely exceeds your API bill.
Accuracy and rework cost
When models produce incorrect outputs, teams spend time reviewing, correcting, and regenerating. This rework cost often exceeds the original token cost. For code-related tasks, catching errors early saves significant rework. A unified code health platform can help identify issues before they compound.
How to Benchmark LLM Costs for Your Workloads
Generic benchmarks won't tell you what a model costs for your specific use cases. Here's how to measure what actually matters.
Define representative use cases
Test with real workloads, not synthetic benchmarks. Identify the specific tasks your team runs: code review, documentation, summarization, analysis. Different tasks have vastly different token profiles and success criteria.
Measure actual token consumption
Track tokens across your real prompts, not just the visible text:
Input tokens: System prompt + user prompt + context + few-shot examples
Output tokens: Full response including any reasoning or formatting
Hidden tokens: Retries, error handling, conversation history
Most teams discover their actual token consumption is 2-3x what they initially estimated.
Track latency under production load
Demo-environment latency differs from production. Measure response times under realistic concurrency and load patterns. Latency often increases as usage scales, and rate limits can introduce unexpected delays.
Calculate end-to-end cost per output
Bring all measurements together into a single cost-per-output metric. Include all the hidden costs identified earlier. This becomes your true comparison baseline across models and providers.
Strategies to Reduce LLM Costs Without Losing Quality
Once you understand true costs, you can optimize effectively.
Optimize prompts for token efficiency
Shorter, clearer prompts use fewer input tokens. Structured output formats reduce output tokens. Efficient prompts also tend to produce better results because clarity helps models as much as it helps humans.
Tier models by task complexity
Use cheaper models for simple tasks. Reserve expensive models for complex ones. This approach, sometimes called model routing, can reduce costs significantly without sacrificing quality where it matters.
Simple tasks: Syntax checks, formatting, classification
Complex tasks: Security analysis, architectural review, nuanced reasoning
Cache responses and reuse results
Semantic caching returns stored results for identical or similar prompts instead of calling the API again. Many code review and analysis tasks fall into this category. If you're analyzing the same patterns repeatedly, caching can dramatically reduce costs.
Monitor costs in real time
Set alerts for spending spikes. Track cost trends over time to catch inefficiencies early. Unified platforms that consolidate AI-driven capabilities, like CodeAnt AI for code health, make this monitoring easier by providing a single view across tools.
How Unified AI Platforms Simplify LLM Cost Management
Managing multiple AI tools creates blind spots in cost visibility. Each tool has its own pricing model, usage patterns, and reporting format. Aggregating this data into a coherent picture takes significant effort.
A unified platform consolidates AI-driven capabilities so teams can track impact and efficiency in one place. For code health specifically, this means code review, security scanning, quality analysis, and developer productivity metrics all visible together.
FAQs
How do enterprise LLM contracts differ from standard API pricing?
What is the difference between input tokens and output tokens in LLM pricing?
Should engineering teams use one LLM provider or multiple providers?
How do fine-tuned models compare to base models on total cost?
What compliance costs should teams consider when selecting an LLM provider?













