

A two-week manual penetration test can produce a detailed report, but that report starts aging the moment your team ships new code. If the assessment finds SQL injection, IDOR, exposed admin panels, and authentication flaws today, those findings only reflect the application state at the time of testing. Three months later, after dozens of new features, APIs, and authorization changes, the attack surface has changed again.
That is the core difference between Burp Suite and CodeAnt AI.
Burp Suite Professional is built for expert-led manual pentesting. It gives security engineers deep control over requests, payloads, authentication flows, session handling, and exploit validation. It remains one of the most trusted tools for human-driven penetration testing, especially when skilled testers need manual depth and flexibility.
CodeAnt AI is built for continuous, code-aware AI penetration testing. It runs black box, white box, and gray box testing across pull requests, CI/CD pipelines, and production-facing applications. Instead of waiting for the next quarterly or annual assessment, CodeAnt AI can test changes as they move through the SDLC and retest fixes after remediation.
The key distinction is not “manual testing vs automation.” It is point-in-time manual depth vs continuous agentic AI pentesting.
Burp Suite is strongest when expert pentesters need maximum control for complex investigation.
CodeAnt AI is strongest when fast-moving SaaS teams need PR-triggered testing, code-informed reconnaissance, exploit validation, automated retesting, and SOC 2-ready evidence between manual assessments.
This guide compares CodeAnt AI vs Burp Suite across testing methodology, CI/CD fit, release velocity, remediation workflow, compliance evidence, and total cost so security teams can choose the right model for their application security program.
Understanding the Pentesting Methodology Shift: Manual vs Agentic Pentesting
Before comparing platforms, understand what makes pentesting “agentic” versus “automated” because the difference fundamentally changes how security testing integrates into modern development.
What “Agentic” Actually Means
Manual pentesting means a human security engineer directs every test, interprets responses, and chains exploits using tools like Burp Suite. When discovering an IDOR in
/api/users/{id}, they manually craft requests, test boundaries, escalate privileges, and document the chain. The tool proxies traffic, but reasoning lives in the tester’s head.Automated scanning runs predefined sequences against known signatures. DAST tools fire SQLi payloads, check for XSS patterns, flag findings based on response matching. No reasoning about application context, no hypothesis testing, no multi-step exploit construction.
Agentic pentesting introduces autonomous decision-making and multi-step reasoning. An agentic system observes application behavior, forms hypotheses about security boundaries, and constructs exploit chains without human direction.
Concrete example: A manual tester discovers /api/admin/users returns 403. They manually test variations, different methods, headers, path traversal, until finding X-Forwarded-For: 127.0.0.1 bypasses IP restrictions. Then manually enumerate endpoints, discover /api/admin/promote, craft escalation chain. Takes 2-4 hours.
An agentic system:
Tests 47 bypass techniques automatically
Discovers the header bypass
Enumerates admin endpoints using bypass context
Identifies role boundary weaknesses
Constructs three-step chain: guest → IP bypass → admin promotion
Reports as single critical finding with combined CVSS scoring
The key difference: autonomous hypothesis testing and exploit construction without human direction.
From Point-in-Time to Continuous Testing
Traditional pentesting operates quarterly: two-week window every 90 days. During that window, skilled testers map your app, identify vulnerabilities, deliver a report. You remediate over 4-6 weeks, schedule retest (new contract, calendar coordination), then go dark for 9-11 months.
The workflow reality:
Week 1-2: Testing engagement
Week 3-6: Remediation
Week 7-8: Retest (if contracted)
Week 9-52: No security validation
This worked for quarterly releases. It breaks when you deploy 2-4 times monthly. Between engagements, you’re shipping features with no adversarial validation.
Continuous testing flips this. Instead of quarterly snapshots, testing triggers on every pull request:
Every feature gets tested before merge. Findings appear as PR comments with curl PoCs. High/critical issues block merge. Unlimited retests included, fix code, push again, validation runs automatically. The 11-month blind spot disappears.
Code-Informed vs Cold-Start Testing
External pentesters start cold, enumerating subdomains, analyzing JS bundles, mapping endpoints, learning your auth architecture from outside. Even with source access (white box), they’re learning during engagement.
Code-informed testing means the platform conducting offensive tests spent months analyzing your codebase defensively. The same system reviewing Spring Security configs, tracing data flows, flagging insecure session handling is conducting adversarial recon.

Example:
Cold-start: Discovers /api/v2/users/{id} through JS analysis. Tests IDOR by incrementing IDs. Finds authorization bypass, reports vulnerability.
Code-informed: Already analyzed auth middleware from defensive review. Knows @PreAuthorize("hasRole('ADMIN')") missing from UserController.getUser(). Knows from data flow analysis userId flows directly to DB query. Knows from Spring config role checks inconsistent across v1/v2. Tests not just ID enumeration but role boundaries, JWT manipulation, cross-version auth bypasses. Constructs chain: guest account → v2 API gap → admin data access → privilege escalation.
The difference: months of defensive context informing offensive strategy. When CodeAnt runs black box (DNS, CT logs, cloud assets), white box (input-to-sink tracing), and gray box (role boundaries, IDOR, JWT) simultaneously, all three share code intelligence.
This is why “agentic” isn’t faster scanning, it’s autonomous reasoning about security boundaries, informed by deep codebase understanding, constructing multi-step chains that map to real business impact.
CodeAnt AI: Unified Defensive and Offensive Architecture
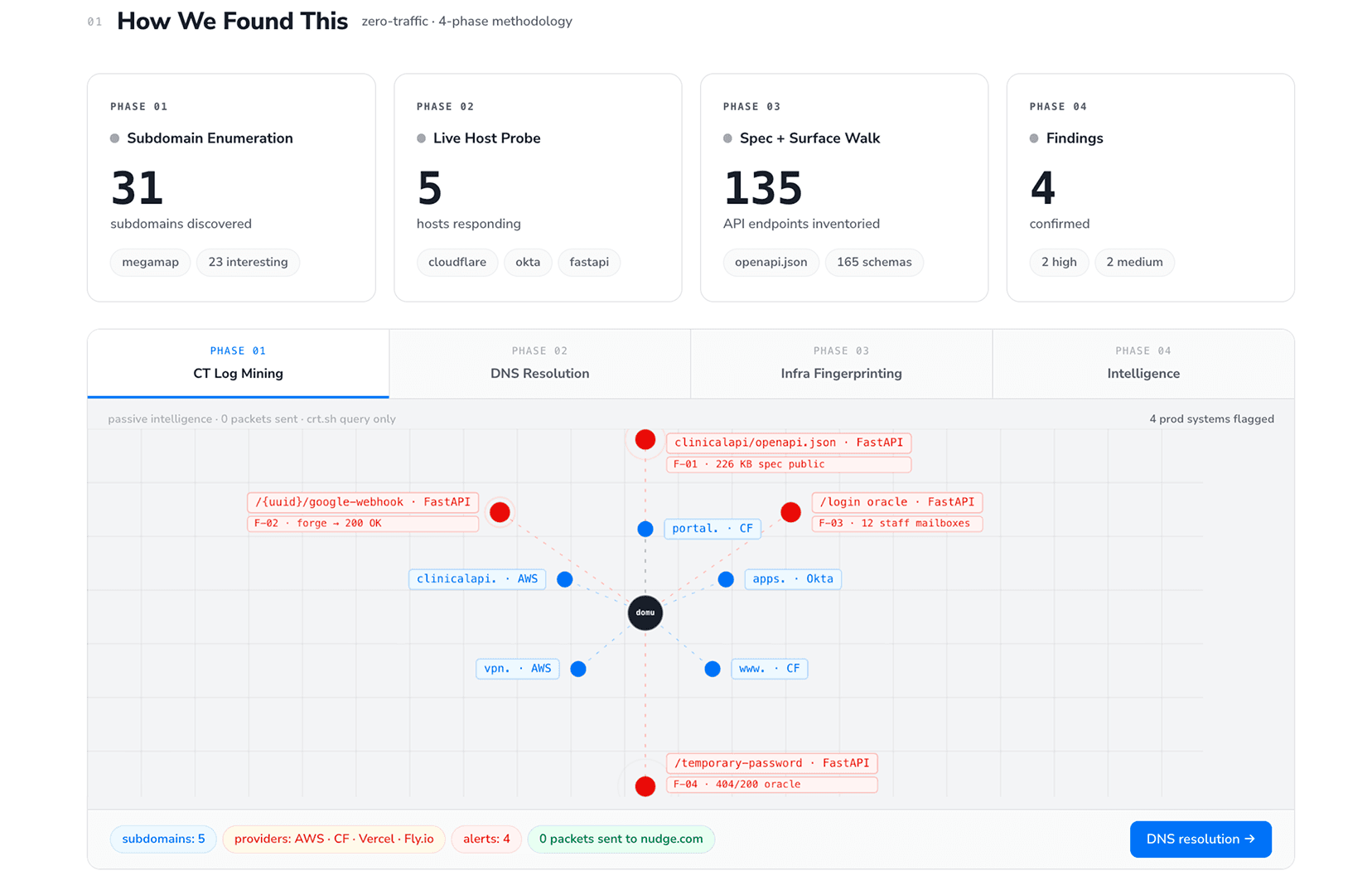
CodeAnt is the only platform operating simultaneously on defensive (code review) and offensive (pentesting) tracks with shared intelligence. This explains the operational model: how three parallel autonomous tracks work together using code context external platforms can’t access.

The Unified Architecture Advantage
Most security platforms operate in silos. SAST reviews code. Pentest vendor attacks from outside. They never talk.
CodeAnt’s architecture is fundamentally different. The same system reviewing auth middleware, tracing data flows through Spring Security, analyzing JWT validation for months is conducting offensive recon and exploit chaining. This creates structural advantage: offensive testing informed by months of defensive code intelligence.
Example:
Black box discovers subdomain at
admin-staging.yourapp.comWhite box already knows from code review this panel shares same Cognito pool as production, with misconfigured IAM allowing cross-environment access
Gray box chains findings: production credentials → Cognito escalation → 476K healthcare records in staging
External pentester starting cold needs days to map this. CodeAnt’s offensive engine has codebase context from defensive review before first HTTP request.
Three Parallel Autonomous Tracks
Black Box: External Reconnaissance + Live Verification
Operates like external attacker with zero inside knowledge:
Enumerates subdomains via DNS brute-force, CT logs, cloud provider APIs
Discovers cloud assets across S3, Azure Blob, GCS, checking public misconfiguration
Analyzes JavaScript bundles for hardcoded secrets, API keys, internal endpoints, GraphQL schemas
Verifies secrets live by testing discovered keys against actual services
Real example: Discovered GraphQL endpoint in minified JS, extracted introspection query, identified listAllUsers resolver with no auth, verified access to 742M records, all autonomously.
White Box: Source-to-Sink Data Flow Tracing
Full source access, operates like expert auditor with unlimited time:
Traces every user-controlled input (HTTP params, headers, cookies, GraphQL variables) to dangerous sinks (SQL, OS commands, file ops, LDAP)
Maps authentication boundaries by analyzing middleware ordering, decorator patterns, framework-specific auth
Identifies business logic flaws by understanding state machines, workflows, authorization checks
Real example: Traced userId parameter from REST endpoint through three service layers, identified missing auth check before DB query, flagged IDOR, confirmed by gray box with working exploit.
Gray Box: Authenticated Workflow Testing
Combines external testing with authenticated access:
Tests every role boundary by creating accounts at each privilege level, attempting cross-role operations
Validates JWT signatures by tampering claims, testing
nonealgorithm, checking signature verification bypassAttacks IDOR endpoints by enumerating object IDs, testing horizontal/vertical escalation
Tests workflow bypasses by skipping required steps in multi-stage processes
Real example: Created two accounts, discovered changing role=user to role=admin in JWT payload accepted without signature verification, escalated to admin panel, accessed 27K CRM contacts, complete chain documented with curl commands.
Exploit Chain Construction
CodeAnt doesn’t just report individual vulnerabilities, it autonomously constructs multi-step chains demonstrating real business impact:
Reports as single critical finding with:
Step-by-step reproduction (curl commands, screenshots, video PoC)
Business impact assessment
Mapped control violations (SOC 2 CC6.1, ISO 27001 A.9.4.1, HIPAA §164.312)
Remediation guidance

Evidence & Compliance Deliverables
Every finding includes audit-grade evidence:
Working PoC exploit (curl/Python)
Before/after screenshots
Video walkthrough (critical findings)
CVSS 3.1 scoring with vector breakdown
Compliance mapping (SOC 2, ISO 27001, PCI-DSS, HIPAA)
For SOC 2, delivers 8-document evidence package as standard: initial report, retest verification, remediation timeline, control effectiveness mapping, risk register updates, data deletion cert, tester independence attestation, methodology alignment (OWASP WSTG, PTES). No manual assembly required.
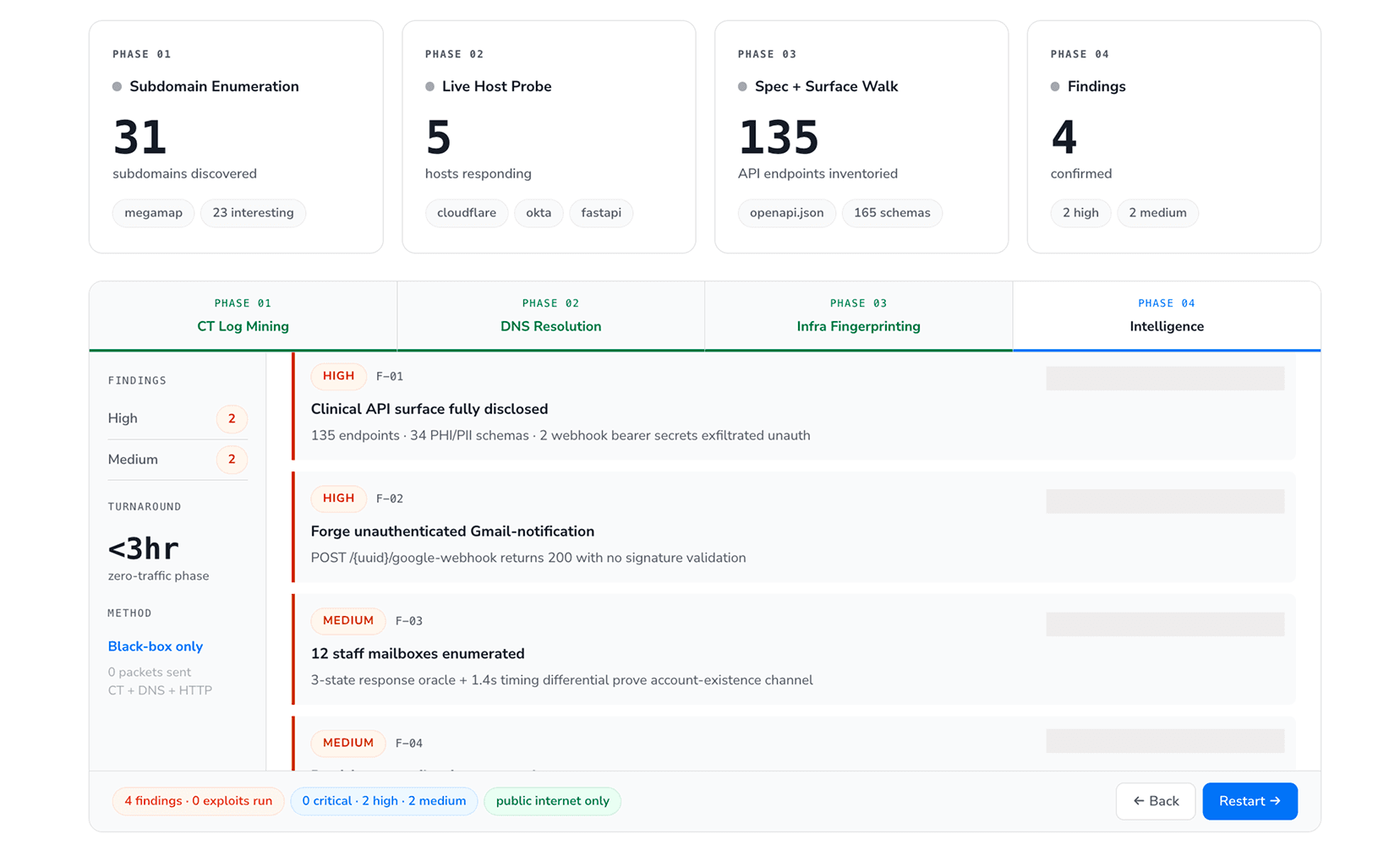
Operational Reality
Unlike point-in-time pentests covering single snapshot, CodeAnt runs continuously:
PR-triggered: Every feature tested before merge
Blocking policy: High/critical prevents merge until remediated
Unlimited retests: Fix pushed → retest automatic, no new engagement
24-48h turnaround: Full black/white/gray box results within two days
For teams shipping 2-4 releases monthly, this eliminates 11-month blind spot between annual pentests.
Burp Suite Professional: Strengths and Structural Limits
Burp Suite has been the manual pentesting standard for 20+ years, and for good reason. Understanding where its proxy-based, expert-driven workflow excels versus where it creates friction for continuous deployment is critical.
Where Burp Suite Genuinely Excels
Unmatched Manual Control
Burp’s HTTP proxy architecture gives skilled operators complete visibility and control:
Intercept and manipulate requests in real-time via Burp Proxy
Chain exploits manually through Repeater, iterating on auth bypass or SQLi evasion with full context
Build custom workflows via 1,000+ BApp Store extensions
Go deeper on edge cases requiring human intuition: complex multi-step auth, race conditions, business logic flaws
Every major consultancy, NCC Group, Bishop Fox, Trail of Bits, standardizes on Burp because when you need maximum depth on a specific target, nothing beats skilled operator with full manual control.
The New Burp AI Capabilities (September 2025)
PortSwigger introduced agentic AI assistance directly into Repeater:
Payload generation based on context and observed behavior
Filter bypass recommendations when initial attempts blocked
Pattern recognition across requests to identify attack vectors
This positions Burp AI as force multiplier for experts, not replacement. Human directs strategy, interprets results, decides paths, AI accelerates iteration.
When Burp Suite Is Right Choice
Deep one-time assessments: Pre-acquisition audits, compliance-driven annual pentests, initial security baselines
Expert security teams: Full-time engineers who can invest 40-80 hours per engagement
Highly custom protocols: Non-standard auth schemes, proprietary frameworks
Low release velocity: Quarterly or less frequent shipping where point-in-time aligns with deployment
Structural Limitations for Modern Velocity
The Expert Operator Requirement
Effective Burp use requires:
Specialized security expertise: HTTP internals, auth mechanisms, vulnerability patterns, exploit construction
Tool mastery: Proxy architecture, Intruder positions, Repeater workflow, Scanner config, extensions
Continuous skill development: New attack techniques, bypass methods, emerging vulnerability classes
This isn’t self-service for developers. Typical engineering teams need dedicated security engineer or external consultancy.
Manual Workflow Doesn’t Scale to Continuous Deployment
Traditional engagement follows point-in-time model:
For teams shipping 2-4 releases monthly, this creates fundamental gap: pentest covers one snapshot, leaving 11 months blind between engagements.
No Source Code Analysis
Burp operates black box, tests running application from outside, no visibility into source, data flows, or business logic. This means:
No static analysis context: Can’t trace user input through middleware to database systematically
Limited business logic coverage: Relies on crawling and manual exploration vs analyzing route definitions
No code-informed recon: Starts cold every engagement

Retest Friction
Validating fixes requires:
New engagement or amendment: Retesting not included by default
Scheduling coordination: Aligning pentester availability with remediation timeline
Partial coverage: Retests focus only on previously identified issues
Time lag: Often 4-8 weeks between fix deployment and verification
Realistic Costs
Total Cost of Ownership:
Component | Annual Impact |
|---|---|
Burp Suite Professional license | $449/year per seat |
Skilled operator time (40-80h @ $150-$250/h) | $6,000-$20,000 per engagement |
Retest engagement (20-40h @ $150-$250/h) | $3,000-$10,000 per retest |
Opportunity cost | Variable, often significant |
Typical quarterly cadence: $24K-$80K annually in direct costs, plus structural limitation of testing only 4 snapshots yearly while shipping 12-48 releases.
Head-to-Head: Capability Comparison
Dimension | Burp Suite Professional | CodeAnt AI |
|---|---|---|
Autonomous Exploit Chaining | ⚠️ Burp AI assists in Repeater, human directs | ✅ Three tracks autonomously build multi-step chains |
Source Code Analysis | ❌ Black box only, no internal visibility | ✅ Full white box, traces input to sinks across codebase |
Code-Informed Recon | ❌ Cold start, learns codebase during test | ✅ Months of defensive context informs offensive probes |
Continuous PR/CI Integration | ❌ Point-in-time, quarterly snapshots, 11-month gaps | ✅ PR-triggered, every feature tested before merge |
Authenticated Business Logic | ✅ Expert-dependent—skilled operator tests manually | ✅ Systematic gray box, tests every boundary automatically |
JavaScript Bundle Analysis | ⚠️ Manual via extensions, requires operator work | ✅ Autonomous, discovers secrets, live-verifies APIs |
Compliance Evidence | ❌ Manual assembly, pentester writes, team maps | ✅ 8-document SOC 2 package included |
Unlimited Retests | ❌ New engagement required—additional contract | ✅ Included, unlimited re-scans after fixes |
Pricing | $449/year + pentester time ($6K-$20K/engagement) | Pay only for confirmed high/critical exploits |
CodeAnt AI Vs Burp Suite: What Manual Control Vs Continuous AI Pentesting Reveals
Comparison Area | Where Burp Suite Wins | Where CodeAnt AI Wins | Honest Trade-Off |
|---|---|---|---|
Core Strength | Burp Suite wins when expert pentesters need maximum manual control for custom payloads, request manipulation, non-standard protocols, and complex authentication flows that require human intuition. | CodeAnt AI wins when teams need continuous AI pentesting at deployment speed, with black box, white box, and gray box testing running across the SDLC. | Burp gives deeper human control. CodeAnt gives broader continuous validation without waiting for a manual testing window. |
Testing Methodology | Burp Suite’s proxy architecture and 20+ years of ecosystem maturity remain unmatched for deep one-time manual penetration testing assessments. | CodeAnt AI uses code-informed testing. The same system reviewing Spring Security configs, API logic, and auth patterns can guide external reconnaissance against production-facing assets. | Burp is stronger for hands-on exploration. CodeAnt is stronger when release velocity makes point-in-time testing insufficient. |
Code Context | Burp Suite is primarily external and manual unless the tester separately reviews code, architecture docs, or internal context. | When CodeAnt discovers a subdomain or endpoint, it can already know which routes accept user input and where those inputs flow in source code. | This code-aware penetration testing advantage is not possible with purely external-only tools. |
Exploit Chaining | Burp Suite allows skilled humans to pause, inspect, modify, and chain attacks manually with fine-grained control. | CodeAnt AI can autonomously build exploit chains such as Cognito misconfiguration → admin panel access → 476K exposed records without human direction. | CodeAnt’s agentic AI pentesting is less granular than a skilled human with Burp, but it scales exploit chaining across more surfaces continuously. |
Payload Control | Burp Suite is better when testers need to pause mid-request, tweak payloads, test edge cases, and inspect unusual application behavior. | CodeAnt AI is better when teams need repeatable AI penetration testing across many releases, APIs, roles, and environments. | Manual control favors Burp. Continuous automated penetration testing favors CodeAnt. |
Best Use Case | Best for deep manual pentesting, consultant-led assessments, complex auth flows, custom protocol testing, and high-skill exploit research. | Best for continuous code-aware AI pentesting, CI/CD security testing, automated retesting, exploit validation, and SOC 2-ready evidence. | For many SaaS teams, the right stack is CodeAnt for continuous validation and Burp Suite for periodic expert-led deep dives. |
Bottom Line | Choose Burp Suite when manual depth, precision, and expert control matter most. | Choose CodeAnt AI when release velocity outpaces manual testing capacity and you need continuous penetration testing between assessments. | The trade-off makes sense when the risk of untested releases is greater than the need for manual control on every finding. |
Decision Framework: When to Use What
Fast-Moving SaaS (2-4 Releases/Month)
Profile: 50-200 engineers, SOC 2/ISO 27001 compliance, rapidly expanding product surface, 1-3 person security team
Problem with manual: Annual or quarterly Burp engagement tests one snapshot. Between engagements, shipping 8-12 releases with zero offensive validation. Math doesn’t work: $12K-$20K per engagement covers 2 weeks of 52-week cycle. Blind 96% of time.
CodeAnt fit:
Continuous validation, every PR triggers testing before merge
Compliance evidence at velocity, 8-doc package standard deliverable
Cost scales with findings, not time, pay only confirmed high/critical exploits, unlimited retests
Real outcome: 120-person SaaS caught 23 critical findings in CI/CD over 6 months that would have shipped under quarterly cadence. Total cost: $8,400. Equivalent Burp coverage: 2 engagements at $24K-$40K.
Expert Security Team with Deep Custom Requirements
Profile: 3+ full-time pentesters, complex custom protocols, highly regulated (fintech/healthcare/defense), quarterly or less release velocity
Burp fit:
Unmatched manual depth for proprietary auth flows
Expert-driven investigation, Burp’s proxy gives skilled operators complete visibility
New Burp AI capabilities augment expert workflows without removing manual control
Trade-off accepted: This works when release velocity low and security headcount can dedicate 40-80 hours per engagement. Optimizing for depth over coverage—accepting testing is point-in-time, not continuous.
Real outcome: Fintech with 5 security engineers uses Burp for quarterly deep assessments of custom payment protocol. Quarterly release cadence means operational model matches tool strengths.
The Complementary Strategy for Your Next Pentesting Session
Profile: Enterprise (200+ developers) with both high velocity and deep security maturity
Hybrid approach:
CodeAnt AI (Continuous) | Burp Suite (Quarterly Deep Dive) |
|---|---|
PR-triggered every release | Expert-led assessment every 90 days |
Black/white/gray for common patterns | Deep custom protocol investigation |
Catches 80% exploitable issues early | Validates edge cases, complex chains |
Complete SOC 2 evidence | Human-verified audit narrative |
Why this works: CodeAnt provides continuous validation between manual engagements, catching BOLA, injection, auth bypass, IDOR systematically. Quarterly Burp engagement focuses on what requires human expertise: complex business logic chains, custom protocol edge cases, deep investigative work.
Real outcome: 300-person enterprise runs CodeAnt continuously (47 critical findings over 12 months in CI/CD) + quarterly Burp engagements (3-5 additional complex issues per quarter). Total security posture: continuous baseline + expert validation.
Quick Decision Criteria
Choose CodeAnt when:
Release cadence 2+ monthly, need continuous validation
SOC 2/ISO 27001 requires ongoing testing evidence
Small security team (0-3 people), can’t dedicate 40-80 hours per engagement
Need code-informed testing (white box data flow, gray box business logic)
Cost model must scale with findings, not pentester time
Choose Burp when:
Dedicated security engineers need maximum manual control
Release velocity low (quarterly or less), point-in-time sufficient
Custom protocols require deep investigative work
Expert-driven testing depth more valuable than continuous coverage
Choose both when:
Enterprise scale (200+ developers) with budget for complementary approaches
High velocity requires continuous testing, but quarterly deep validation adds value
Compliance and maturity demand both ongoing evidence and expert-verified findings
Implementation: 2-4 Week Pilot Framework for Your AI Pentesting
Gap between “interesting” and “running in production” kills most security tool adoption. Here’s concrete pilot framework validating agentic pentesting in parallel with existing process, no disruption, clear metrics, audit evidence from day one.
Week 1: Scope Single High-Value Service
Pick one service meeting these criteria:
User-facing API/web app with authentication (gray box shows value immediately)
Active development (2+ PRs weekly gives comparison data)
Known security surface (existing findings = baseline for comparison)
SOC 2/compliance scope (validates audit evidence quality early)
Document current testing cadence and baseline time-to-detect for last 3 critical findings.
Week 1: Configure PR-Triggered Testing
Key decisions:
Start with
criticalblocking only,highas warnings, adjust after 10 PRs based on false positivesMap findings to security Slack + PR author
Enable unlimited retests on fix commits
Weeks 1-4: Run Parallel Testing
For every PR triggering agentic testing:
Let existing process run unchanged (manual review, DAST, whatever you do today)
Compare findings side-by-side:
What did agentic catch that manual missed?
False positive rate per 10 PRs?
Time-to-detect: How long until finding surfaced vs quarterly pentest?
Measure retest friction:
Manual: Schedule retest after fix (typical: 2-4 weeks)
Agentic: Push fix, retest automatic (typical: 15 minutes)
Track findings:
Finding | Severity | Detected By | Time-to-Detect | Time-to-Retest |
|---|---|---|---|---|
IDOR in | High | Agentic (gray) | PR #847, 12min | 8min (auto) |
SQLi in search | Critical | Both | Agentic: PR #851, Manual: Week 3 | Agentic: 15min, Manual: 18d |
Week 2-3: Establish Audit Evidence
SOC 2 auditors care about coverage, remediation timeline, control mapping. Configure evidence export early:
Automated reports: Every critical/high produces 8-doc package (summary, PoC with curl, retest timeline, control mapping, data cert)
Compliance dashboard: Track coverage across services, time-to-remediation by severity, retest completion
Auditor-ready artifacts: Export findings as CSV with CVSS, CWE mappings, remediation evidence
Run one full test cycle, export evidence package, walk through with compliance lead—validate it meets audit requirements before expanding scope.
Week 4: Define Success and Expand
After 2-4 weeks, compare data:
Time-to-detect:
Baseline (quarterly manual): 90 days average between merge and discovery
Agentic (PR-triggered): 10-15 minutes average
Time-to-retest:
Baseline (manual): 14-21 days to schedule retest
Agentic (unlimited): 5-20 minutes automated retest
Cost per critical verified:
Manual: $6K-$20K engagement ÷ findings = $1.5K-$4K per critical
Agentic: Pay-per-finding, no retest fees
Decision: If agentic caught ≥2 critical your process missed, or cut time-to-retest by >80%, expand to 3-5 services. If false positives >20%, tune severity thresholds and run another 2-week cycle.
Key insight: agentic pentesting runs in parallel, not series. Existing process continues unchanged while pilot validates whether continuous, code-informed testing delivers measurable improvements. No workflow disruption, clear success criteria, expansion only after data proves value.
Cost-Per-Finding Economics
For engineering leaders, real question isn’t “which tool is better”—it’s “what does each critical finding actually cost to discover, verify, and close?” Here’s transparent cost model accounting for full economic reality.
True Cost of Manual Engagements
Burp Suite seat: $449/year. But that’s fraction of total economics for 100+ developer org:
Direct Costs:
Burp license: $449/year per security engineer
Pentester time: $150-$250/hour (consultant) or $120K-$180K/year (in-house senior AppSec, fully loaded)
Typical engagement: 40-80 hours for single application (1-2 weeks focused testing)
Per-engagement cost: $6,000-$20,000 external consultants, or 2-4 weeks internal capacity
Organizational Overhead:
Pre-engagement coordination: 4-8 hours (kickoffs, scoping, test accounts, VPN access)
Remediation lag: 3-6 weeks between report and fixes (context-switching, prioritization, deployment)
Retest contracts: Each requires new SOW, 8-16 hour engagement ($1,200-$4,000), 4-8 weeks after remediation
Compliance evidence: 6-12 hours manually compiling reports, retest confirmations, control mappings
Total per application per quarter: $8,000-$28,000 accounting for coordination, remediation cycles, retest friction.
For organization with 8 customer-facing apps tested quarterly: $256K-$896K annually—and still only getting point-in-time snapshots with 11 months blind between tests.
Continuous Testing Economics
CodeAnt inverts traditional model: pay only for confirmed high/critical findings with working exploits, unlimited retests included, low/medium free.
Cost Structure:
Per-finding pricing: Pay when critical/high vulnerability discovered with working PoC
Unlimited retests: No new engagement—push fix, trigger retest in CI/CD, verify closure in hours
Included: Complete SOC 2 evidence package per finding
Efficiency Gains:
Zero scheduling overhead: PR-triggered automatic, no kickoffs or test account provisioning
Remediation velocity: Developers see findings in PR comments within 24-48h, fix in context, retest immediately
Compliance evidence: Automated assembly of audit-ready documentation
Economic Comparison
Cost Factor | Manual Pentesting | Continuous Agentic |
|---|---|---|
Per-engagement setup | $2K-$4K coordination | $0 (automated) |
Retest economics | New SOW + 8-16 hours | Unlimited, included |
Remediation lag | 3-6 weeks (scheduling + deployment) | Hours (fix in PR, retest immediate) |
Compliance evidence | 6-12 hours manual assembly | Automated 8-doc package |
Coverage gaps | 11 months blind between quarterly tests | Continuous (every PR) |
Cost per verified critical | $4K-$8K (engagement + retest + overhead) | Pay per confirmed exploit only |
The Math for 100+ Developer Org
For organization shipping 2-4 releases/month across 8+ applications:
Currently spending $500K-$900K annually on quarterly manual pentests (engagement + retests + coordination)
Discovering 120-200 high/critical yearly across all applications
Cost per verified critical: $3K-$7.5K including retest cycles and organizational overhead
Continuous model eliminates retest contracts, scheduling friction, remediation lag—while testing every feature before ship rather than quarterly snapshots. ROI question becomes: What’s value of catching critical findings in CI/CD before production, with zero retest cost and hours-to-verification instead of months?
Conclusion: Choose Based on Your Release Velocity
CodeAnt AI vs Burp Suite is not a question of which tool is universally better. It is a question of which pentesting model matches how your team ships software.
Burp Suite is still the right choice when expert security engineers need maximum manual control, custom payload crafting, deep protocol testing, and one-time investigative depth. It remains the standard for skilled manual pentesting and consultant-led assessments.
CodeAnt AI is stronger when security needs to move at CI/CD speed. Its advantage is continuous, code-aware AI penetration testing that runs across black box, white box, and gray box tracks, validates exploitability, comments in PRs, and retests fixes without waiting for a new engagement.
If shipping 2+ releases monthly and need continuous validation:
Run CodeAnt pilot on most active repository
See how PR-triggered black/white/gray box catches issues before merge
Evaluate cost-per-finding economics vs quarterly engagement fees
If need deep manual control for complex protocols:
Continue with Burp Suite for expert-driven testing where human judgment and custom payload crafting remain essential
Consider new Burp AI capabilities for agentic assistance in Repeater workflows
If want both methodologies:
Adopt complementary model: CodeAnt for continuous PR-triggered testing between releases, Burp for deep quarterly manual reviews
Best of both worlds: continuous validation + periodic expert-led depth
Decision Framework Summary
Your Scenario | Right Choice | Key Outcome |
|---|---|---|
2+ releases/month, SOC 2 compliance | CodeAnt AI | Continuous testing, complete audit evidence, unlimited retests |
Dedicated security team, quarterly releases | Burp Suite | Maximum manual control, deep custom protocol testing |
Enterprise with both needs | Both (complementary) | Continuous validation + periodic expert depth |
Ready to see how continuous, code-informed pentesting fits your workflow? Book a 1:1 with our security experts for a live demo tailored to your release cadence and compliance requirements.
The gap between manual and agentic pentesting isn’t about which tool is “better”—it’s about which methodology matches how fast your team ships code and how you verify security between releases.

