AI Code Review
10 Good Coding Principles to Improve Code Quality

Sonali Sood

Founding GTM, CodeAnt AI
Your team knows DRY, SOLID, and separation of concerns. Yet duplicated logic still ships to production, God classes balloon to 2,000 lines, and architectural violations slip through code review. The gap between knowing principles and consistently applying them across 100+ developers isn't about education, it's about enforcement at velocity.
Manual reviews can't scale when you're shipping 50 PRs daily. Static analyzers like SonarQube flag hundreds of issues, but 60% are noise. Meanwhile, senior developers become bottlenecks, junior developers repeat mistakes, and technical debt compounds sprint after sprint.

This guide breaks down 10 coding principles with a critical lens: what breaks when teams rely on manual enforcement, and how AI-driven platforms systematically enforce them without sacrificing velocity. If your team ships through CI/CD and PR-based development, this is the framework for turning principles into practice.
Why Coding Principles Fail at Scale
The fundamentals haven't changed, Martin Fowler's guidance on readable code, Robert Martin's SOLID principles, and Hunt and Thomas's DRY philosophy remain relevant. What has changed is the enforcement challenge. When you're managing distributed teams, reviewing 50+ PRs per day, and maintaining microservices across dozens of repositories, manual adherence becomes statistically impossible.
The enforcement gap: Your senior engineers understand SOLID. They can explain separation of concerns. But when reviewing their 12th PR at 4:45 PM, they're not catching that a service violates single responsibility by handling both authentication and payment processing. They're not noticing duplicated validation logic across three microservices.
Traditional solutions don't scale. More rigorous code reviews create bottlenecks and burn out seniors. Static analyzers generate noise, 300 flagged issues where only 50 matter, and can't understand your organization's specific patterns. The teams that successfully enforce principles at scale have moved beyond manual checklists and generic analysis. They've adopted AI-powered continuous enforcement that learns from their codebase, understands architectural intent, and provides context-aware feedback at the PR level.
The 10 Essential Coding Principles
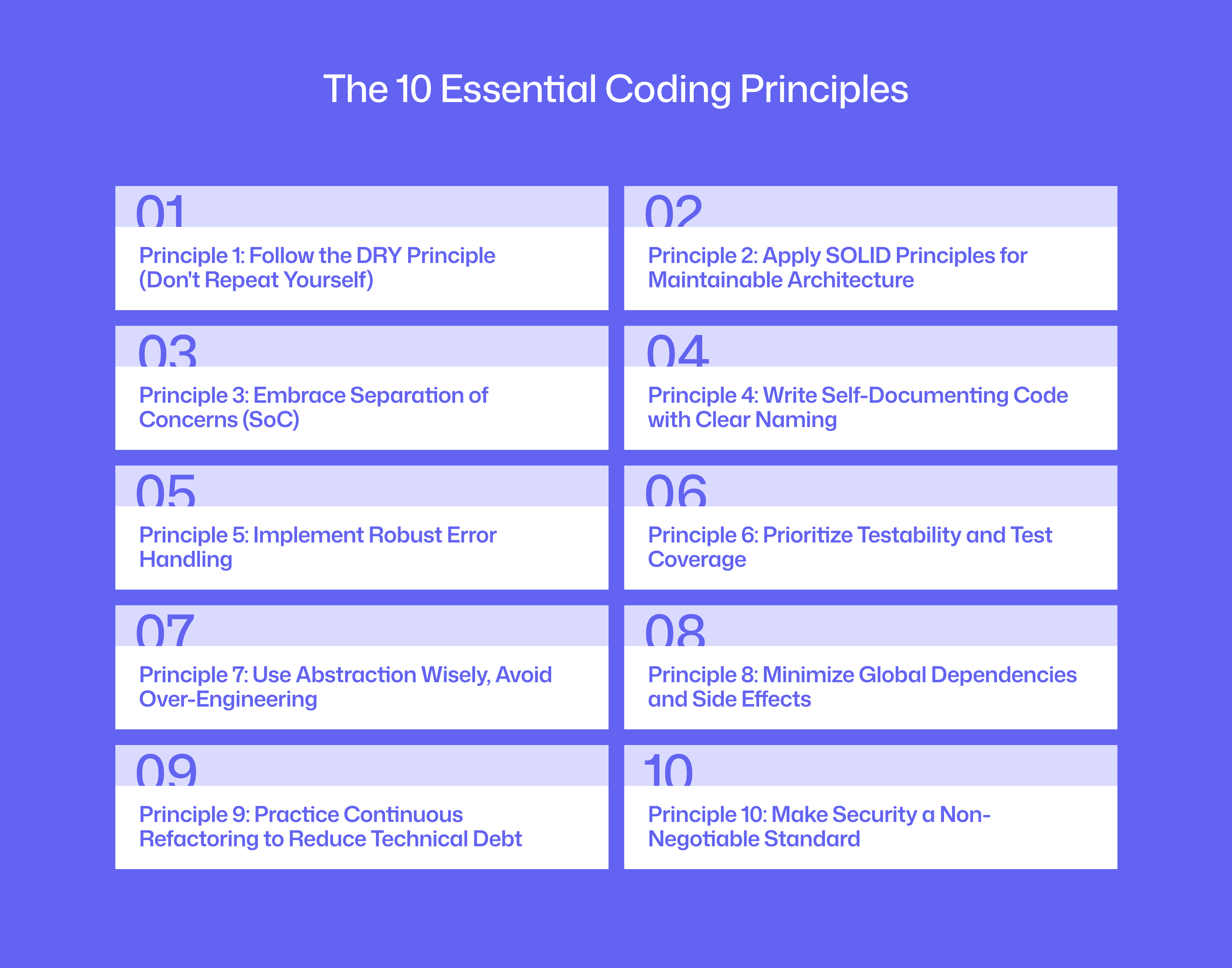
Principle 1: Follow the DRY Principle (Don't Repeat Yourself)
What it means: Every piece of knowledge should have a single, authoritative representation in your system. As Hunt and Thomas wrote in The Pragmatic Programmer, "DRY is about the duplication of knowledge, of intent."
Why manual enforcement fails: Code reviewers catch obvious copy-paste within a single file. They rarely catch semantic duplication across services, the same business logic implemented three different ways in three repositories. They definitely don't catch when a new PR reintroduces logic already abstracted into a shared library.
The scale problem: In microservices architectures, duplicated validation logic across six services means a security patch requires coordinating six teams, six PRs, and six deployment cycles. The blast radius multiplies by the number of duplications.
How AI-powered enforcement works: Modern platforms detect both syntactic and semantic duplication across your entire codebase, not just within a single PR. CodeAnt AI scans for duplicated patterns across repositories, identifies when new code reimplements existing functionality, and suggests the appropriate shared abstraction. Teams using automated DRY enforcement reduce violations by 65% in their first sprint.
Principle 2: Apply SOLID Principles for Maintainable Architecture
What it means: SOLID is five principles guiding object-oriented design: Single Responsibility, Open/Closed, Liskov Substitution, Interface Segregation, and Dependency Inversion. Each addresses a specific aspect of maintainability and extensibility.
Why manual enforcement fails: Static analyzers flag "God classes" but can't propose context-aware refactors. Human reviewers might notice a single responsibility violation in a new class but miss that the PR adds a fourth responsibility to an existing service. The feedback loop is too slow, by the time architectural issues surface, code is already merged.
The scale problem: SOLID violations create ripple effects. A class with multiple responsibilities means changes to one feature break another. Services violating dependency inversion become impossible to test in isolation. When managing hundreds of classes and dozens of services, SOLID violations compound into architectural debt that slows every future change.
How AI-powered enforcement works: AI-driven platforms understand architectural intent, not just code structure. CodeAnt AI analyzes service boundaries, identifies when classes violate single responsibility, and suggests SOLID-compliant refactors that preserve functionality. Instead of generic "this class is too complex" warnings, you get actionable guidance: "This service handles both user authentication and payment processing, consider splitting into AuthService and PaymentService with a shared UserContext interface."
Principle 3: Embrace Separation of Concerns (SoC)
What it means: Dijkstra's 1974 concept describes separating a program into distinct sections, each addressing a separate concern. In modern architectures, this means clear boundaries between presentation, business logic, data access, and infrastructure.
Why manual enforcement fails: Reviewers see individual files, not system-wide patterns. They might approve a PR adding database queries to a controller because the code works and the change is small. They don't see this is the 15th violation of the same pattern, and now your presentation layer is tightly coupled to your data model.
The scale problem: When concerns are tangled, changes cascade unpredictably. A database schema change shouldn't require touching API controllers. In microservices, poor separation leads to services that can't be deployed independently, defeating the entire architecture purpose.
How AI-powered enforcement works: Automated architectural analysis tracks concerns across your codebase and flags violations at the PR level. CodeAnt AI identifies when services violate separation of concerns, like a notification service directly querying the user database instead of calling the user service API, and suggests appropriate service decomposition.
Principle 4: Write Self-Documenting Code with Clear Naming
What it means: Code should be readable without extensive comments. Variable names reveal intent, function names describe behavior, class names indicate responsibility. As Martin Fowler says, "Good programmers write code that humans can understand."
Why manual enforcement fails: Naming is subjective. What's clear to one reviewer is cryptic to another. Teams create style guides, but enforcement is inconsistent. Worse, documentation drifts, comments become outdated, README files don't reflect recent refactors.
The scale problem: When your team has 100+ developers with varying tenure, self-documenting code is the difference between productive onboarding and weeks of confusion. Clear naming reduces cognitive load, makes debugging faster, and prevents "what does this function do?" questions that waste hours.
How AI-powered enforcement works: AI platforms analyze naming patterns and flag inconsistencies or unclear names at the PR level. More importantly, they auto-generate PR summaries documenting why changes were made. CodeAnt AI's automated documentation captures intent, links to related issues, and maintains searchable history, eliminating documentation drift without requiring extensive comments.
Principle 5: Implement Robust Error Handling
What it means: Every failure mode should be anticipated and handled gracefully. Errors caught at appropriate levels, logged with sufficient context for debugging, never exposing sensitive information.
Why manual enforcement fails: Reviewers focus on happy-path logic. They might not ask "what happens if this API call times out?" or "is this user input validated before hitting the database?" Security-focused code reviews catch some issues, but they're time-consuming and often happen too late.
The scale problem: In distributed systems, failures are inevitable. Robust error handling is the difference between a degraded experience and a cascading failure. It's also security—unhandled exceptions expose stack traces with sensitive data, missing input validation creates injection vulnerabilities.
How AI-powered enforcement works: Unified SAST and quality scanning catches unhandled exceptions, missing validation, and exposed secrets in a single pass. CodeAnt AI scans for error handling gaps at the PR level, flags potential security vulnerabilities before merge, and provides one-click fixes for common patterns.
Principle 6: Prioritize Testability and Test Coverage
What it means: Code should be designed for easy testing, loose coupling, dependency injection, avoiding global state. Test coverage is tracked as a quality gate measuring confidence in changes, not as a vanity metric.
Why manual enforcement fails: Teams set coverage targets (e.g., "maintain 80% coverage"), but enforcement is reactive. Developers discover their PR dropped coverage only after pushing, creating friction and delays. Worse, coverage metrics don't distinguish between meaningful tests and brittle tests providing false confidence.
The scale problem: In CI/CD environments, tests are your safety net. High-quality coverage enables confident refactoring, faster debugging, and reliable deployments. Low coverage means every change is a gamble.
How AI-powered enforcement works: Automated quality gates block merges when coverage drops below thresholds, with feedback at the PR level before context-switching. CodeAnt AI tracks coverage per PR, identifies untested code paths, and highlights high-risk changes (complex logic with low coverage). The platform also detects test quality issues, tests that don't assert anything or tests so brittle they fail on unrelated changes.
Principle 7: Use Abstraction Wisely, Avoid Over-Engineering
What it means: Abstraction reduces complexity when applied to stable, well-understood concepts. The goal is abstracting when it eliminates duplication, not applying design patterns for their own sake.
Why manual enforcement fails: Reviewers either under-abstract (missing opportunities to eliminate duplication) or over-abstract (accepting unnecessary indirection because "it follows the pattern"). There's no objective measure of appropriate abstraction, it's a judgment call varying by reviewer and context.
The scale problem: Over-engineered code is as problematic as under-abstracted code. When every operation goes through five layers of interfaces and factories, onboarding becomes painful, debugging becomes archaeology, and simple changes require touching dozens of files.
How AI-powered enforcement works: Context-aware AI detects both under-abstraction (duplication that should be extracted) and over-abstraction (unnecessary indirection that should be simplified). CodeAnt AI learns from your codebase maturity, suggesting more abstraction in mature services and less in experimental features. It provides recommendations based on actual usage: "This abstraction is only used once, consider inlining" or "This pattern appears in 8 places, extract to shared utility."
Principle 8: Minimize Global Dependencies and Side Effects
What it means: Functions should depend on inputs and return outputs, not modify global state or rely on hidden dependencies. This makes code predictable, testable, and safe for concurrent execution.
Why manual enforcement fails: Reviewers see individual functions, not the dependency graph. They might approve a function modifying a global cache because it works in isolation. They don't see this creates a hidden dependency causing intermittent test failures and production race conditions.
The scale problem: Global state breaks testability, you can't run tests in parallel. It breaks reasoning, you can't understand a function without knowing entire global context. In distributed systems, global state creates race conditions and makes horizontal scaling impossible.
How AI-powered enforcement works: Automated dependency analysis tracks global state usage and side effects across your codebase. CodeAnt AI flags functions modifying global state, identifies hidden dependencies between modules, and suggests refactors toward dependency injection.
Principle 9: Practice Continuous Refactoring to Reduce Technical Debt
What it means: Technical debt is the compounding cost of deferred improvements. Continuous refactoring means addressing small issues before they become large problems, treating code health as ongoing concern rather than periodic cleanup.
Why manual enforcement fails: Refactoring is always deprioritized against feature work. Teams create "tech debt" tickets that languish in backlogs. When they finally schedule a cleanup sprint, they don't know where to start, which debt matters most? Which refactors will have the biggest impact on velocity?
The scale problem: Technical debt has interest rates. A small DRY violation today becomes a maintenance nightmare in six months when that duplicated code exists in 20 places. Teams deferring refactoring find themselves in a death spiral, so much debt they can't afford to pay it down.
How AI-powered enforcement works: Continuous scanning of existing code surfaces debt proactively, not just reactively during PR reviews. CodeAnt AI scans your entire codebase, identifies violations of all 10 principles, and prioritizes by impact: "These 50 DRY violations affect 12 services and have caused 8 bugs in the last quarter, fix first." The platform tracks debt trends over time, showing whether you're accumulating or paying down.
Principle 10: Make Security a Non-Negotiable Standard
What it means: Security isn't a feature you add later, it's a quality attribute built in from the start. This means following OWASP Top 10, adhering to CWE standards, validating all inputs, encrypting sensitive data, and never trusting user input.
Why manual enforcement fails: Security reviews are specialized and time-consuming. Most code reviewers aren't security experts. They might catch obvious SQL injection but miss subtle authentication bypasses or timing attacks. Security-focused tools like Snyk help, but they're separate from quality tools, creating fragmented workflows.
The scale problem: A single security vulnerability can compromise your entire platform. For fintech and healthcare teams, it's also compliance, SOC2, ISO 27001, HIPAA, and PCI-DSS all mandate secure coding practices. Security breaches destroy trust and can end companies.
How AI-powered enforcement works: Unified security and quality scanning treats code health holistically. CodeAnt AI scans for vulnerabilities, secrets, misconfigurations, and dependency risks in the same workflow that enforces SOLID and DRY. Instead of context-switching between Snyk for security and SonarQube for quality, you get comprehensive coverage with a single platform understanding how security and quality intersect.
From Principles to Systematic Enforcement
Traditional tools create three critical failures: context loss (each tool operates in isolation), alert fatigue (500+ findings per sprint with 60% false positives), and compliance theater (generating separate reports without proving remediation).
CodeAnt AI's unified approach:
Context-aware vulnerability assessment: When CodeAnt detects a dependency with a known CVE, it traces whether your code paths actually invoke the vulnerable function. If the risk is theoretical, it's deprioritized. If exploitable in your context, it blocks merge with one-click upgrade suggestion.
Intelligent prioritization: Not all violations are equal. CodeAnt prioritizes by impact, flagging the DRY violations that affect multiple critical services before minor naming inconsistencies. This reduces noise by 70% compared to traditional static analyzers while catching critical issues competitors miss.
Continuous scanning beyond new code: Unlike tools that only analyze PRs, CodeAnt continuously scans your entire codebase to surface debt as it accumulates. It detects semantic duplication across microservices, architectural drift, and dependency risk scoring.
Measurable outcomes: Teams using CodeAnt AI report:
80% faster code reviews by automating mechanical checks
65% reduction in SOLID violations with continuous scanning and one-click fixes
50% lower defect escape rate by catching principle violations before merge
Improved DORA metrics: higher deployment frequency, lower lead time, reduced change failure rate
Implementation Roadmap
Phase 1: Establish baseline (Week 1)
Run full repository scan to identify top 5 violation patterns
Quantify impact by blast radius (how many services/modules affected)
Map violations to business outcomes (defect rates, review cycles)
Phase 2: Enable PR-level enforcement (Week 2-3)
Start with non-negotiables: secrets detection, critical security vulnerabilities, egregious duplication (>15%)
Configure quality gates that block only critical violations while warning on others
Phase 3: Expand enforcement (Week 4+)
Layer in maintainability rules (function length, complexity, SOLID violations) as team adapts
Use graduated enforcement: observation mode → warning mode → full enforcement
Track override rates to identify training gaps
Phase 4: Measure impact
PR review time (target: 50% reduction)
Defect escape rate (target: 40-60% decrease)
Code duplication percentage (target: <5% in new code)
DORA metrics (maintain or improve deployment frequency while reducing change failure rate)
Lightweight governance:
Code Health Owner (Staff+ engineer, 4-6 hours/month) defines quality gates and approves exceptions
Team Quality Champions (1 per 15-20 developers, 2-3 hours/month) triage false positives
Engineering Leadership (1 hour/quarter) reviews standards alignment with business priorities
Conclusion: Make Principles Enforceable, Not Aspirational
These ten principles aren't new, but the ability to enforce them systematically at scale is. Teams that operationalize coding principles through AI-powered automation ship faster, with higher quality, and with less technical debt than teams relying on manual enforcement.
The question isn't whether these principles matter, it's whether you have the tooling to make them real in your day-to-day workflow. When enforcement is automated, intelligent, and integrated into your existing PR workflow, principles transform from aspirational guidelines into lived practice.
See these principles enforced in your codebase today. Start your free 14-day trial and scan your repositories to identify exactly which principles your code violates most. Connect in 60 seconds, no credit card required. Orbook a 1:1 technical demo to see CodeAnt analyze your actual codebase with context-aware explanations and one-click fixes.
FAQs
Won't automated enforcement slow down our deployment velocity?
How do I prevent false positives from eroding developer trust?
How do we handle legacy code without grinding feature work to a halt?
Can rules differ by repository or team maturity?
How does this fit with GitHub Copilot and AI code assistants?













