

DevSecOps is one of those ideas that sounds great in theory, until you try to implement it. It promises a world where developers, security engineers, and operations teams work in perfect harmony. Security is built in from the start. Vulnerabilities are caught before they ever hit production. And delivery speed doesn't slow down.
But in practice? Most teams end up with bloated pipelines, noisy scanners, false positives, and burned-out developers who quietly start skipping security checks just to get their work merged. The core problem isn't tooling. It's that DevSecOps assumes everyone in the pipeline, dev, sec, ops, shares the same goals and incentives. They don't.

That's why this article doesn't just give you another "what is DevSecOps" definition. But if you are really for that, here you go:
What is DevSecOps?
DevSecOps means building security into the entire software delivery process, right from code to production, without slowing anyone down.
It's not "DevOps + security tools." It's about:
Giving developers real-time, in-flow security feedback
Automating checks in CI/CD without killing build speed
Making security a shared responsibility, not someone else's job
When done right, DevSecOps feels invisible.
We'll break down why DevSecOps often fails despite best intentions, where it works (hint: micro-feedback, not mega dashboards), how modern teams are reframing it—from static scanning to secure-by-default systems, and the frameworks that help, the ones that don't, and how tools like CodeAnt.ai can make the difference if used right.
Let’s start by questioning the very foundation DevSecOps is built on.
Why DevSecOps Often Fails (Even with the Best Intentions)
DevSecOps starts with good intentions.
You want to ship fast, stay secure, and avoid turning audits into fire drills. You add a few scanners. Set up policies. Maybe even hire a security engineer or two to join your platform team.
But three months in?
Your CI pipeline is slower. Devs are muting alerts. Security is filing Jira tickets that nobody closes. And that fancy dashboard you rolled out? Still stuck on "medium risk."
What happened?
Here’s the uncomfortable truth: most DevSecOps setups fail not because people don’t care, but because the system wasn’t built for how people work.
Let’s break it down.
1. The Incentive Mirage
DevSecOps sounds collaborative, in theory. In practice, it assumes something that's rarely true: that Dev, Sec, and Ops all want the same thing.
But developers want to ship quickly. Security wants airtight control. And ops wants to sleep through the night without getting paged.
These aren't just different KPIs. They're often in direct conflict.
When you plug a new secrets scanner into your CI pipeline and it starts flagging every third-party dependency, each team reacts differently:
Devs shouting: "I didn't even touch that code."
Sec says: "It's the right call."
Ops thinks: "If this blocks prod again, I'm going to lose it."
2. Security Gets Tacked On
Even in orgs that say security is “shifted left,” it often still shows up at the end.
A feature is built. The PR is open. The deadline is tomorrow.
Then… bam, a new check fails. “Dependency vulnerable: CVE-2021-something.”
It doesn’t matter that the scanner is technically right. Security is barging in late with a “no,” not sitting beside you earlier with a “what if.”
That’s what makes security feel like someone else’s problem. It shows up too late to help, only early enough to block.
3. More Tools, Same Problems
Let’s say you roll out a bunch of scanners. SAST. SCA. IaC policies. They light up your dashboards with red, yellow, and orange alerts.
Great coverage, right?
Not really.
Developers are staring at 20 warnings on a PR they opened for a single-line change. Half the issues are in transitive dependencies. The rest? Not fixable.
Nobody tells them which ones matter. Or how to fix them. Or who owns them?
So they start to ignore the noise.
And that’s the danger: when everything is a high priority, nothing is. The signal is buried. The team tunes out.
4. Friction Without Ownership
Maybe the security alert is legit.
A Terraform config accidentally exposes an S3 bucket to the internet.
The problem? It lives in a shared module that no one on the current team maintains.
The developer hits a wall: “I didn’t write this, I can’t fix this, but now I can’t merge my PR.”
They tag a lead. The lead shrugs. The ticket moves to the backlog.
No one's being negligent. But no one owns the issue either.
So the problem sits. Security logs it. Engineering avoids it. The risk lingers.
5. Shift Left... Then What?
The mantra is “shift left.” Catch issues early. Scan earlier in the pipeline.
But what happens when you shift left without shifting how feedback works?
Now devs are hitting blockers faster, not resolving risks better.
They still don’t have context.
They still don’t know what’s critical.
They still get overloaded with things they didn’t break.
You’ve moved the traffic jam from staging to development. That’s early-stage noise.
6. One-Way Communication
Security tools often throw alerts into a void.
They don’t explain.
They don’t discuss.
They don’t listen.
A tool flags an issue in a regex pattern. The dev disagrees, but there’s no way to say why. No inline suppression. No “I’ve reviewed this, here’s the context.”
Eventually, developers stop arguing. They start skipping. They feel like security is a parent, not a partner.
And nobody wants to be micro-managed by a tool.
7. DevSecOps as Theater
In response to these issues, orgs reach for frameworks. NIST. OWASP SAMM. SLSA. Great acronyms. They document maturity levels, draft threat modeling checklists. Define on-boarding flows. But none of it answers:
Who reviews the Terraform files?
Who maintains the base image?
What happens when a scanner fails at 4:59 p.m. on a Friday?
You end up with process documents no one reads, and pipelines no one trusts. The theater is running, but no one's watching.
8. Same Fires, Different Sprint
The patterns start to repeat:
A secret leaks again.
A misconfigured rule makes a bucket public.
A stale dependency shows up with a fresh CVE.
You patch it. Push a fix. Move on.
But no one automates prevention.
No one updates the base module.
No one rewrites the pre-commit hook.
So the fire comes back next month. And the month after that. It’s security as churn, not as learning.
9. CI/CD Slowdowns Break Trust
Even small changes can trigger long pipeline delays when security tooling isn’t tuned.
Three minutes here. Five minutes there.
It doesn’t sound like much until it starts breaking flow for every feature push.
Developers notice. They find shortcuts. They disable hooks. Skip stages. Revert configs.
If security makes your CI feel like molasses, your team will route around it. Every time.
10. No One's Incentivized to Fix It
Security wins when something goes wrong (which is invisible). Engineering wins when something ships (which is very visible). So when the system breaks, who's incentivized to dig deep and fix the underlying problems? Too often, no one.
Dev teams don't have the engineering bandwidth. Security doesn't own the scanner configs. Platform teams are chasing infra debt. So DevSecOps tools get dusty. The dashboards stay red. And everyone hopes they don't get breached before the next audit. That's how good intentions die.
DevSecOps isn't broken because it's a bad idea. It's broken because most teams never redesign their workflows, feedback loops, or incentives to make it real. It's not about adding security. It's about rethinking how you build — so security happens by default, not by exception.
Where DevSecOps Actually Works
If you’ve been burned by DevSecOps rollouts that added friction but didn’t reduce risk, you might be skeptical that it ever works at all.
Yup, we’ve been there too.
But some teams are quietly getting it right, not with 30-step frameworks or perfect compliance scores, but by designing security to be so embedded that no one even calls it DevSecOps anymore.
Let’s look at what these setups do differently.
1. It Shows Up Before You Ask for It
In most teams, “security” means scanning a pull request and filing a ticket if something breaks.
In great teams, security happens earlier, way earlier.
They use hardened base containers with unsafe packages already stripped out.
They rely on IaC modules that come pre-validated, so engineers don’t misconfigure them.
They enforce secret scanning before code even leaves the local machine, using lightweight Git hooks that barely interrupt flow.
The result? Engineers don’t need to “remember” security. It’s part of the path of least resistance.
There’s no policy doc. No extra training. Just better defaults.
Yeah, it’s not sexy. But that’s what makes it powerful.
2. Feedback is Local, Not Global
Here’s a dead giveaway your security setup is broken: every PR gets flagged with issues in code the dev didn’t touch.
No wonder people start ignoring it.
High-trust setups fix this by focusing feedback only on the diff. If you changed three lines, you should see security alerts for… those three lines.
And that feedback is tight:
“This regex is vulnerable to ReDoS; here’s a safer pattern.”
“This S3 bucket config defaults to public, double-check that.”
No PDFs. No dashboards. No 400-line scan reports dumped into Slack.
Just helpful, targeted nudges that make it easy to fix what you just wrote, without dragging in historical debt that isn’t yours.
3. It Lives Where the Work Happens
If your security tool lives inside its login, dashboard, or learning curve, it's already lost. Security that works needs its tool inside your flow:
Inline PR comments
IDE suggestions (not popups)
CI feedback that looks just like another code check
Yup, that includes using tools like CodeAnt AI that hook into VS Code or GitHub and surface alerts in the same place you're already reviewing code. Because when security shows up where decisions are being made, it stops being something "extra." It becomes part of shipping.
4. It Blocks Only When It Matters
One of the fastest ways to lose trust in DevSecOps? Block the build for every minor issue. High-functioning teams get this right by tuning their systems:
Warnings are flagged but non-blocking.
Only high-confidence, high-risk issues (like hardcoded secrets or RCE-level vulns) stop the merge.
Everything else comes with a fix, a rationale, or a snooze button — not just a red X.
Devs start trusting the system not because it's perfect, but because it respects their time. So when it says "don't merge this," people listen.
5. The Checks Keep Running After the Merge
A lot of DevSecOps setups die at merge. But reality doesn't. Your code is live. Dependencies age. Secrets rotate. Configs drift. Great teams keep scanning:
Main branch and production artifacts
CVEs in deployed code, not just committed code
Runtime environments for policy violations and infrastructure drift
Because security isn't just something you do before release, it's something that quietly runs after, so your team doesn't have to scramble every time a zero-day hits.
6. Developers Aren't Treated Like Attackers-in-Waiting
In fragile orgs, security locks things down. Every tool is a gate. Every check assumes malice. In mature teams, the assumption flips: developers want to do the right thing if the system makes it easy. That means:
Quick, explainable feedback
Suppression options for known edge cases (with justification)
Slack threads or comment threads where devs and sec talk like teammates, not adversaries
It's a subtle shift. But it turns security from a cop into a coach. Yup, that one shift changes everything.
7. Teams Can Explain How It All Works
You know a DevSecOps setup is working when you ask someone on the team, "Hey, how does security work here?" and they can answer without pausing. Not with jargon. But with confidence.
"We scan diffs, not the whole repo."
"If something breaks, we get fix suggestions right in the PR."
"Secrets don't leave local, we block them before push."
"If a scanner fails, there's a Slack alert, and we usually fix it the same day."
It's not about having the perfect toolchain. It's about having a system that people understand and trust. Because when security isn't mysterious, it becomes manageable. This is where DevSecOps works. Not in a dashboard. Not in a framework.
But in tiny design choices that lower friction, earn trust, and make safety feel seamless. Yeah, it takes effort to get there. But once you do? Your team won't call it "DevSecOps." They'll just call it the way we build.
How Modern Teams Reframe DevSecOps for Secure-By-Default Systems
Once you're no longer obsessing over "how teams ship software," something shifts. You're asking better questions:
Why was this mistake possible in the first place?
How do we make the secure default, not the exception?
What's the system behavior behind the risk?
This isn't about adding more checks. It's about changing the environment that lets insecure code exist at all.
1. Security Starts Before the First Commit
In high-functioning teams, the foundation itself prevents bad patterns from creeping in.
IaC modules enforce sane defaults, no open buckets, no 0.0.0.0 ingress.
Base containers are pre-locked to secure versions.
Git hooks catch hardcoded secrets before they’re ever staged.
There’s no post-hoc enforcement, because the initial scaffold makes it difficult to mess up.
This isn’t “left shift.” It’s a design shift. Security moves from the pipeline to the blueprint.
2. Scanners are the Strategy, Constraints Are
Modern systems work proactively:
Block unapproved packages at the package manager level
Enforce RBAC boundaries via IaC guardrails
Auto-generate service configs with rate limits, CORS, and TLS enabled
You're not "catching" bad code. You're removing the conditions that make it possible.
3. Security Moves into the Sprint
In traditional setups, security lands as Jira tickets: “rotate keys,” “lock down endpoint,” “patch lib.”
In modern systems:
Pipelines auto-inject logging and SBOM generation
Deployment scripts wire up monitoring, access control, and alerting
Enforcement lives inside CI/CD, not someone’s checklist
The result? Devs don’t “do” security. They just follow paths where it’s already embedded.
4. Don't Block… Redirect
When blockers are vague or feel wrong, teams bypass them. Instead of failing builds on every alert, mature systems:
Fail only on high-confidence, high-impact or async alerts
Route lower-priority issues to triage queues or risks
Provide actionable context, not just red flags
The goal isn't to stop developers. It's to help them make the next secure move.
5. Trust Metrics Beat Coverage Metrics
Modern teams love saying, "We scan everything." But scanning without trust is just noise at scale.
How often do devs fix what's flagged?
What's the false positive rate?
Do teams trust the signals enough to act?
If the answer is no, more tooling won't help. Better feedback loops will. Secure-by-default isn't about perfection, it's about removing decision fatigue and reducing blast radius. Because when the system guides engineers toward safety, you don't need to police every action. You've already shaped the environment to do most of the work.
DevSecOps Frameworks That Work (and Those That Don’t)
Most DevSecOps frameworks are written for ideal environments.
Unfortunately, your team doesn’t live in one.
You’re juggling legacy code, half-owned infra, tight deadlines, and that one service still running in prod with zero tests because no one wants to touch it.
So, when a framework says “perform threat modeling at design time,” what does that mean when your sprint didn’t have a design phase?
Yea. That’s the disconnect.
Why Most Frameworks Don't Hold Up
To be fair, frameworks like OWASP SAMM or NIST 800-218 aren't useless. They offer structure. They give you a common language. But they fail in three critical ways:
1. They assume control you don’t have
You don’t own all the code. You don’t manage all the infrastructure. You’re integrating SaaS, third-party tools, and legacy stacks. Telling devs to “own their threat model” when they don’t even control the module config is wishful thinking.
2. They prioritize documentation over behavior
Teams write down security processes once a quarter. But day-to-day? Devs are copying infra from internal wikis, pushing hotfixes under pressure, and skipping optional checks because the pipeline already takes 12 minutes. If the behavior doesn’t change, the framework didn’t land.
3. They’re too rigid for reality
Most frameworks describe maturity models. But they don’t account for reality:Misconfigurations inside reusable modulesSecret leaks from rogue tools or CI logsShadow dependencies introduced via a one-liner, Stack Overflow codeFrameworks miss the messy middle, where most security fails.
What Works: Failure-Driven Frameworks
The best teams don't roll out someone else's framework. They reverse-engineer their failures and build from there.
Step 1: Pull your last 3–5 real-world incidents
Not what could go wrong. What did? For each one, ask:
Where did the signal fail?
Was the risk visible in time?
Could a dev have caught it in flow?
Step 2: Turn those into constraints
Now write down the things that must never happen again.
Not in abstract language. In real, testable rules:
Incidents | Behaviour Constraint |
|---|---|
Secret leak in Git history | No secrets leave local → enforce pre-commit scanning |
Public S3 bucket created | The IaC module cannot expose buckets by default |
Auth logic accidentally changed | All auth-related PRs require out-of-team review |
You now have a living, useful security framework.
It’s yours. It reflects your codebase, your team, and your risks.
No generic checklist required.
How CodeAnt.ai Fits Into This, if You Use it Right
CodeAnt AI isn’t a magic fix. No tool is.
But if you’ve built or are building systems like the ones we just described, CodeAnt AI can make the right behavior feel natural. Before the feature dive, check the dashboard out.
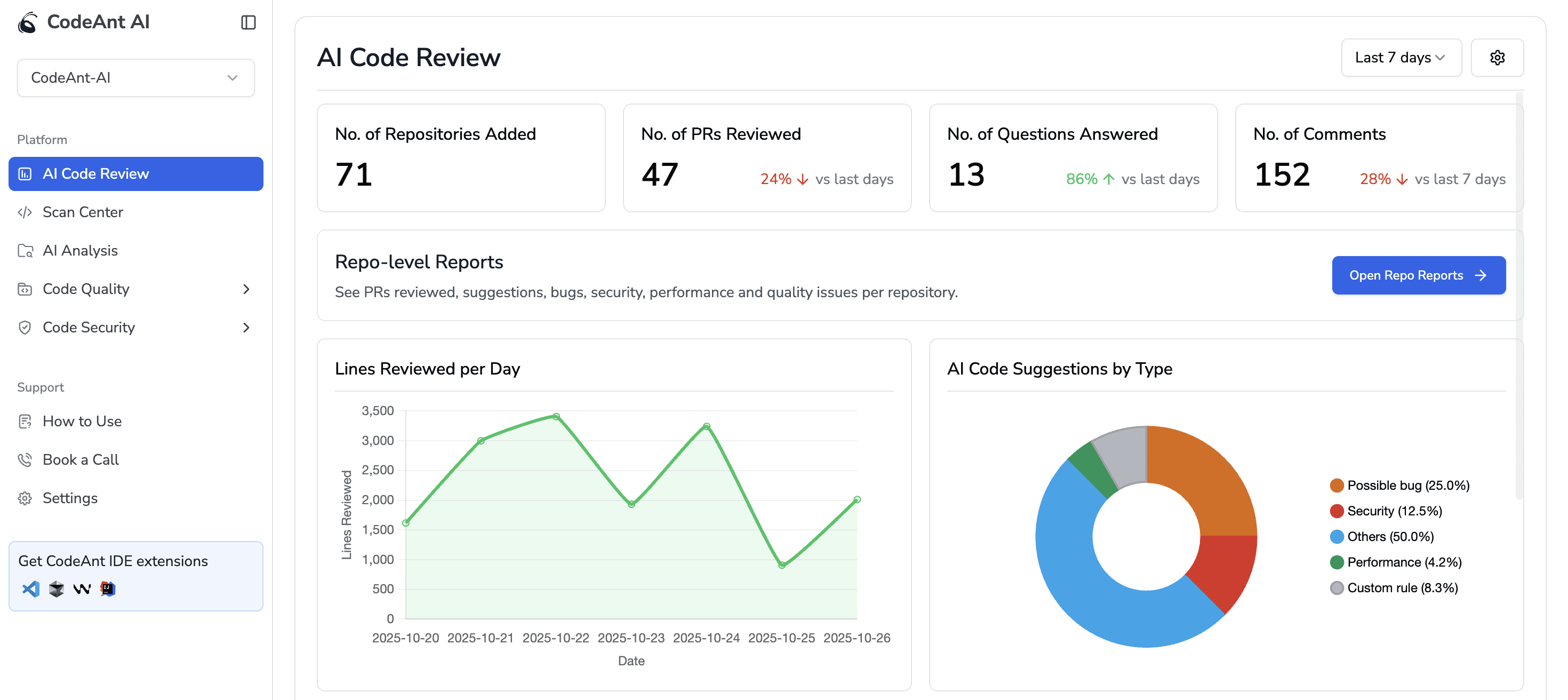
Just covers everything 😉 and we have recently brought DORA metrics too.
This is how CodeAnt AI fits:
1. Feedback in the flow

CodeAnt surfaces security issues right where devs are working, inside the PR, or even their IDE, scoped to just the lines they touched. No dashboards. No switching context.
2. Fixes, not just flags

Hardcoded secrets? Unsafe patterns? Known CVEs?
CodeAnt doesn’t just tell you it’s broken; it offers one-click AI-powered suggestions to fix it, in place.
3. Blocks only what matters

You can configure CodeAnt to stop risky merges only when something’s critical. Everything else can pass with a warning or be triaged later, without blocking delivery.
4. Continuous visibility
Post-merge, CodeAnt continues scanning artifacts, tracking regressions, and you can push unresolved issues into Jira, so cleanup doesn’t rely on memory.
5. Works with your system, not against it
Pre-commit hooks
Diff-aware scanning
CI/CD integrations
English-written policies (no YAML wrangling)
It doesn’t ask your team to change how they work, it supports how good teams already build.
If you’re building a secure system, not just checking a box, this is what you want:
Behaviour-driven policies
Guardrails built into the flow
Feedback is scoped, fast, and fixable
Tools like CodeAnt that amplify your intent, not fight it
That’s DevSecOps that works.
Conclusion
Thanks for reading. If you’ve made it this far, you already know: DevSecOps isn’t about buzzwords or compliance checklists. It’s about building secure, high-quality systems that don’t get in the way of speed or your team.
And yeah, now you probably get the hype around CodeAnt.ai, too.
We built it because teams like yours were tired of spending hours sifting through noisy security scans and slow code reviews that barely caught anything important.
With CodeAnt AI, you get a platform that’s already helping teams:
Cut review times by over 50%
Block critical issues before they land in the main
Ship faster, safer, and cleaner, without changing how they work
It’s trusted by engineering teams across industries, from fast-moving startups to high-compliance enterprises. And it works. Right out of the box.
Want to see how it can work for your team?
👉 Schedule a 15-minute call and we’ll walk you through it live, no slides, just the product in action.
Thanks again for reading. Happy Securing.

