Code Security
Why Rule-Based SAST is Not Enough

Sonali Sood

Founding GTM, CodeAnt AI
GitHub’s CEO has predicted that Copilot will write 80% of code in the near future. Developers are already there in practice, over 80% regularly use AI coding assistants, and the volume of AI-generated code entering pull requests has grown exponentially since 2024. But the security implications of this shift are severe, well-documented, and largely unaddressed by existing tooling.
This guide explains what vulnerabilities AI coding assistants introduce, why traditional SAST tools struggle with AI-generated code, and how AI-native SAST catches what rule-based scanners miss..
The AI-Generated Code Problem in 2026
The research on AI-generated code security is consistent and concerning. A landmark study by NYU researchers evaluating GitHub Copilot across 89 security-relevant scenarios found that approximately 40% of generated programs contained vulnerabilities, with the most common categories being CWE-79 (XSS), CWE-89 (SQL injection), CWE-798 (hardcoded credentials), and CWE-22 (path traversal). A Stanford study led by Dan Boneh’s group found that developers using AI assistants were more likely to produce insecure code and simultaneously more confident that their code was secure, creating a dangerous gap between perceived and actual security.
A 2025 large-scale analysis of 7,703 AI-generated files on public GitHub repositories using CodeQL static analysis identified over 4,200 CWE instances across 77 distinct vulnerability types. Python code showed the highest vulnerability rates at 16–18%, followed by JavaScript at 8–9%. The consistent finding across all studies is that AI-generated code introduces the same categories of vulnerabilities as human-written code, injection flaws, insecure defaults, hardcoded credentials, deprecated APIs, but developers review it less carefully because they assume the AI produced correct code.
This creates a compounding problem. As AI coding assistants produce more code faster, the volume of potential vulnerabilities entering pull requests increases. At the same time, developers are spending less time reviewing each suggestion because they trust the AI’s output. The result: more vulnerabilities entering the codebase, with less human scrutiny at the point of entry.
What Vulnerabilities Do AI Coding Assistants Introduce?
AI coding assistants are trained on billions of lines of public code from GitHub repositories, including insecure tutorials, hasty Stack Overflow answers, and buggy implementations. They reproduce the patterns they learned from training data, including the security flaws. Four vulnerability categories appear consistently across every research study.
Injection Flaws and Insecure Defaults
AI assistants frequently generate code that concatenates user input directly into SQL queries, shell commands, or template strings. When a developer asks Copilot to “query users by ID,” the suggestion often uses string formatting rather than parameterized queries, because the training data contains far more examples of the insecure pattern than the secure one.
Here is a realistic example of what GitHub Copilot or Cursor might suggest when asked to build a user search endpoint:
This is a single file with four distinct vulnerabilities, SQL injection, reflected XSS, insecure cryptography, and a hardcoded database credential. Every one of these patterns exists abundantly in the training data that AI coding assistants learn from. A developer who hits “Tab” to accept this suggestion and moves on has introduced four exploitable vulnerabilities in seconds.
Hardcoded Credentials and API Keys
AI assistants frequently generate code with placeholder API keys, database passwords, and authentication tokens that look realistic enough to be mistaken for actual credentials, or that get replaced with real credentials during development and then committed. Research has found that repositories using Copilot leak secrets at a rate approximately 40% higher than repositories without AI assistance.
Outdated Patterns and Deprecated APIs
AI models are trained on historical code, which means they suggest patterns that were common when the training data was collected but have since been deprecated or replaced by more secure alternatives. MD5 and SHA-1 for hashing, eval() for parsing, HTTP instead of HTTPS for API calls, and outdated TLS configurations all appear regularly in AI-generated suggestions because they were prevalent in the training corpus.
Copy-Paste Vulnerabilities from Training Data
AI coding assistants can reproduce code verbatim from their training data, including code with known vulnerabilities. When the model has seen a particular vulnerable pattern thousands of times across public repositories, it learns to reproduce that pattern as the “correct” way to implement the functionality. The insecure tutorial code that developers have been copying from Stack Overflow for years is now being automatically suggested by AI, at scale, with higher confidence.
Why Traditional SAST Struggles with AI-Generated Code
SAST tools scan code regardless of who or what wrote it. A SQL injection vulnerability has the same CWE classification whether it was written by a human developer or suggested by Copilot. But AI-generated code creates two specific challenges that traditional rule-based SAST tools handle poorly.

Rule-Based Scanners Miss Novel Patterns
AI coding assistants do not always generate code that matches the exact patterns rule-based SAST tools are built to detect. When Copilot suggests a novel way to construct a query, concatenate strings, or handle authentication, the code may be functionally vulnerable but syntactically different from any rule in the scanner’s library.
Rule-based tools detect what their rule authors anticipated. AI-generated code regularly produces patterns that no rule author anticipated, because the AI is synthesizing from millions of code examples into new combinations.
AI-native SAST tools like CodeAnt AI handle this differently. Because the detection engine reasons about what code does rather than matching patterns, it can identify vulnerabilities in novel code constructions that no rule exists for.
When Copilot generates an unusual string concatenation that produces a command injection, CodeAnt AI’s LLM-powered analysis understands the semantic behavior, untrusted input reaching a dangerous operation, even if the syntax has never been seen before. To see which tools use rule-based vs. AI-native detection, check which SAST tools handle AI-generated code in our tools comparison.
AI-Generated Code Creates Higher Volume, More Noise
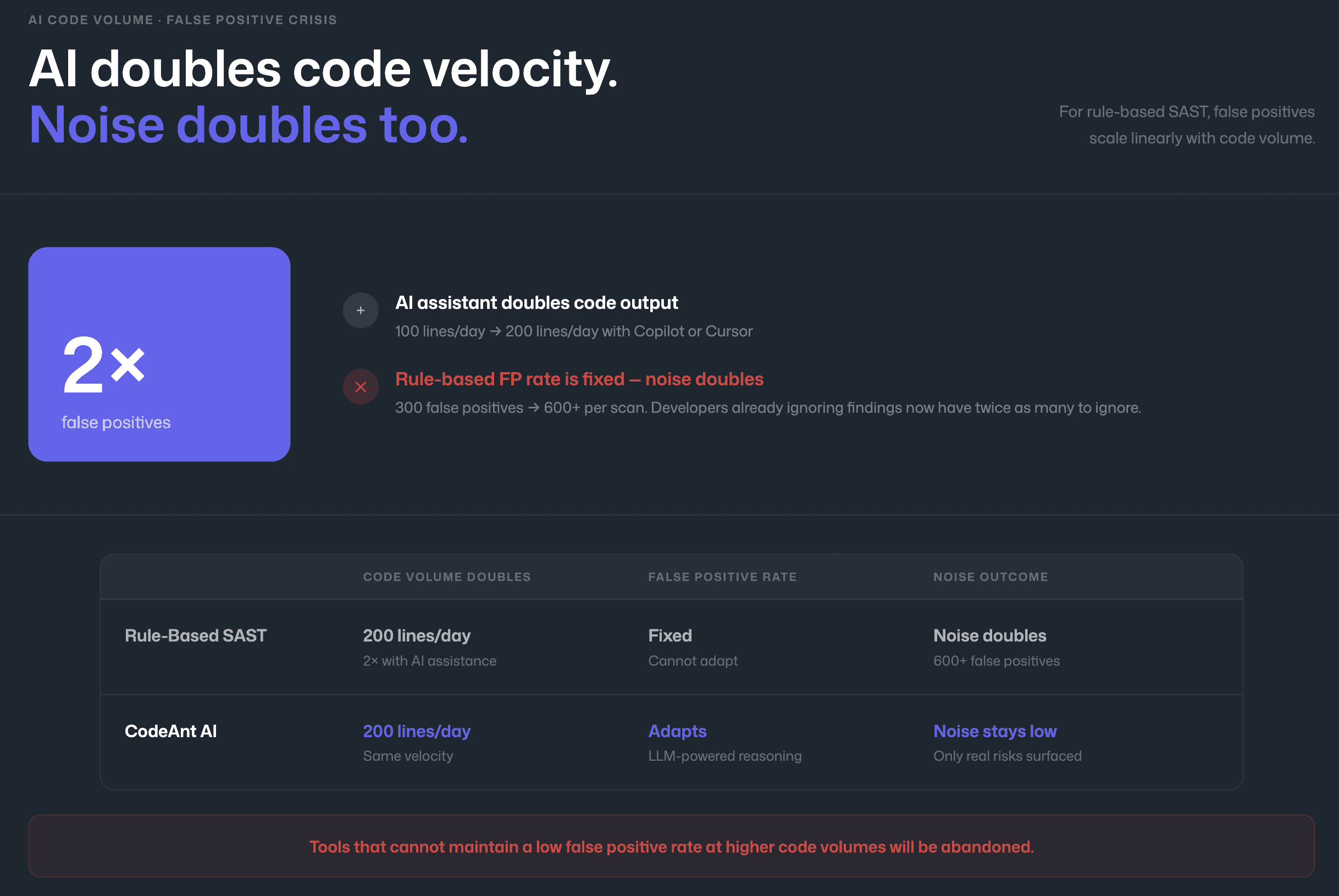
AI assistants dramatically increase code velocity. A developer using Copilot or Cursor produces more code per hour, which means more code entering pull requests per day, which means more findings per scan. For rule-based SAST tools with high false positive rates, this increased volume is catastrophic, the number of false positives scales linearly with code volume, and alert fatigue escalates proportionally.
A tool that produced 300 false positives per scan when developers wrote 100 lines per day now produces 600+ when AI helps them write 200 lines per day. The developers who were already ignoring findings now have twice as many to ignore.
This is why false positive reduction is not just a quality-of-life improvement, it is an existential requirement for SAST tools in the AI coding era. Tools that cannot maintain a low false positive rate at higher code volumes will be abandoned. For a detailed breakdown of how to evaluate and reduce false positives, see How to Reduce SAST False Positives.
How AI-Native SAST Solves the Problem
The most effective approach to AI-generated code security is scanning at the pull request level, where the SAST tool evaluates all code changes regardless of origin. This means AI-generated code from Copilot, Cursor, or any other assistant receives the same scrutiny as hand-written code, without requiring developers to manually flag which code is AI-generated.
Scanning at the PR Level: Before Merge
PR-level SAST scanning is the single most important control for AI-generated code security. Every code change, human-written or AI-generated, must pass through a pull request, and every pull request triggers an automated security scan. The scanner does not need to know or care whether the code was AI-generated. It evaluates what the code does.
CodeAnt AI scans every PR across GitHub, GitLab, Azure DevOps, or Bitbucket, delivering findings as inline comments on the specific lines of code affected. For the vulnerable code example above, CodeAnt AI would flag all four vulnerabilities, the SQL injection, the XSS, the insecure crypto, and the hardcoded credential, with full attack paths, EPSS exploit probability scores, and one-click AI-generated fixes. The developer who hit “Tab” on Copilot’s suggestion would see four inline comments before the code can be merged, each with the evidence needed to understand and fix the issue in minutes.
Steps of Reproduction for AI-Generated Findings
When a SAST tool flags AI-generated code, the developer’s first instinct is often to trust the AI over the scanner: “Copilot suggested this, it’s probably fine.” Steps of Reproduction counter this instinct by providing irrefutable evidence.
Steps of Reproduction in SAST provide developers with the exact sequence of conditions needed to trigger a flagged vulnerability, the entry point, the taint flow through each intermediate step, the vulnerable sink, and a concrete exploitation scenario.
For the SQL injection in the code above, the developer would see that request.args.get('q') flows unsanitized through string concatenation into cursor.execute(), with a concrete exploit payload (' OR '1'='1) that demonstrates the vulnerability is real.
This evidence-based approach is critical for AI-generated code specifically because developers are predisposed to trust AI suggestions.
A vague alert saying “possible SQL injection” gets dismissed.
A full attack path showing exactly how the vulnerability can be exploited does not.
This is why CodeAnt AI’s fix rates are dramatically higher than tools that present generic alerts, and why that gap widens further for AI-generated code where developer trust in the source is already high.
Tool Consolidation: Review + Quality + Security in One Pass
AI coding assistants create a volume problem that extends beyond security. More AI-generated code also means more code quality issues (complexity, duplication, dead code) and more code review burden. Running separate tools for code review, code quality, and security scanning triples the feedback channels, the context-switching, and the alert fatigue.
CodeAnt AI consolidates all three functions:
code quality analysis
security scanning (SAST + SCA + secrets + IaC)
… into a single PR-native workflow. One tool, one set of inline comments, one dashboard. This consolidation is particularly valuable in the AI coding era because it gives developers a single source of truth for all feedback on AI-generated code rather than juggling three separate tool outputs. For a deeper exploration of the consolidation argument, see how tool consolidation simplifies AI code review.
Best Practices for Securing AI-Assisted Development
The following practices apply to any team using AI coding assistants, regardless of which SAST tool you choose. For a broader framework, the OWASP AI Security and Privacy Guide provides additional guidance on securing AI-assisted development workflows.
Make PR-level SAST mandatory, not optional. Every pull request, regardless of whether it contains AI-generated code, must trigger an automated SAST scan. AI-generated code should not receive less scrutiny than human-written code. In practice, it often does because reviewers assume the AI produced correct code. Mandatory scanning removes this discretion.
Update code review guidelines. Explicitly state that AI-generated code requires the same security-focused review as any other code. Share the research data, the NYU 40% vulnerability rate, the Stanford false-confidence finding, and walk through examples of AI-generated vulnerabilities in your team’s technology stack. Developers who understand the specific failure modes of AI code generators are better at catching them in review.
Use AI-native SAST, not rule-based. Rule-based scanners miss novel patterns that AI assistants generate. AI-native tools like CodeAnt AI reason about what code does rather than matching patterns, catching vulnerabilities in code constructions that no rule author anticipated. This gap between rule-based and AI-native detection widens as AI assistants produce increasingly creative (and insecure) code patterns.
Consolidate your toolchain. Running separate tools for code review, quality, and security creates three feedback channels. With AI-generated code increasing the volume across all three, consolidation into a single platform like CodeAnt AI reduces noise and keeps developers in a single workflow.
Monitor AI-specific metrics. Track the vulnerability rate in PRs containing AI-generated code vs. human-only PRs. Track the false positive rate separately for AI-generated findings. These metrics tell you whether your SAST tool is handling the AI code volume effectively. GitHub Copilot’s audit logs and Cursor’s usage analytics can provide data on which files and functions were AI-generated.
Conclusion: AI Code Changes the Volume. Your Security Model Must Change Too.
AI coding assistants increase output velocity. They also increase vulnerability volume. The solution is not banning AI. It is upgrading your security controls.
PR-native SAST, AI-native detection, enforceable CI/CD gates, and evidence-backed findings ensure that AI-generated code is reviewed with the same rigor as human code, without slowing development.
Security must operate at the speed of AI. If it does not, vulnerabilities scale faster than review capacity. Modern application security is not about adding more tools. It is about integrating security directly into the workflow where AI code is written, reviewed, and merged.
If your team is already using AI coding assistants, the question is not whether vulnerabilities exist, it is whether you are catching them early enough.
Compare tools on AI capabilities
Reduce false positives
Consolidate your toolchain
And start scanning AI-generated code via CodeAnt AI on your next Copilot-assisted PR
FAQs
Is AI-generated code less secure than human-written code?
Why do traditional rule-based SAST tools struggle with AI-generated code?
What types of vulnerabilities do AI coding assistants commonly introduce?
How can teams securely adopt GitHub Copilot or other AI coding tools?
Can AI-native SAST replace DAST for AI-generated code security?













