

CODEANT AI · MARCH 2026 · BENCHMARK
AI code review tools have exploded in the past two years. Every major AI vendor now offers some version of automated pull request review. Tools promise to detect bugs, security issues, performance problems, and code quality regressions before code merges.
But until recently there was a fundamental problem:
There was no independent benchmark measuring how well these tools actually perform.
Most published comparisons were produced by the vendors themselves. Predictably, every benchmark declared its own tool the winner. That changed in March 2026 with the release of Martian’s Code Review Bench, the first independent evaluation framework designed specifically for AI code review systems.
The benchmark evaluates 17 AI code review tools across more than 200,000 real pull requests from open-source repositories. Instead of relying only on curated datasets, the benchmark measures something much closer to reality:
Which review comments developers actually act on.
In this first release, CodeAnt AI ranked #3 globally, achieving a 51.7% F1 score across real-world pull requests.
This article explains:
How the benchmark works
What precision, recall, and F1 mean for code review
Where CodeAnt AI ranked
Why different tools score differently
What the results reveal about the future of AI code review
The First Independent AI Code Review Benchmark
For years, evaluating AI code review tools was surprisingly difficult. Every AI code review vendor publishes benchmarks where they win. Greptile publishes benchmarks where Greptile wins. CodeRabbit publishes benchmarks where CodeRabbit wins. This is the state of the category.
In February 2026, a research lab called Martian, built by researchers from DeepMind, Anthropic, and Meta, and notably not in the business of selling code review tools, published what is arguably the first genuinely independent benchmark for AI code review agents. They open-sourced the dataset, the judge prompts, the evaluation pipeline, and the methodology. Anyone can reproduce the results.
We submitted CodeAnt AI. Here is what we found. Martian does not build a competing code review product.
This independence is what makes the benchmark credible.
The benchmark analyzes:
200,000+ real pull requests
thousands of GitHub repositories
17 AI code review tools
Instead of manually labeling bugs, the benchmark observes developer behavior directly. If developers fix code after a review comment, that comment is treated as a meaningful signal.
If developers ignore or dismiss the comment, that signal is recorded as well. This creates one of the largest behavioral datasets ever used to evaluate automated code review.
What Martian's Benchmark Actually Measures
Most vendor benchmarks measure what they want to measure. Martian's benchmark measures two things that actually matter to engineering teams: precision and recall.
Precision is the percentage of a tool's review comments that lead to an actual code change. If a tool leaves 100 comments and developers act on 52 of them, the precision is 52%. The rest are noise.
Recall is the percentage of real issues in a PR that the tool actually catches. A tool can achieve high precision by commenting very rarely, but it will miss most of the bugs. The benchmark measures both.
The offline benchmark runs every tool against 50 curated PRs from five major open-source repositories, Sentry, Grafana, Cal.com, Discourse, and Keycloak, each with human-verified lists of real issues a reviewer should catch.
The online benchmark continuously samples fresh real-world PRs from GitHub, tracking which AI review comments developers actually act on versus ignore. Because the PRs are recent, tools cannot have memorised them during training.
How Martian’s Benchmark Works
Martian designed the benchmark using two complementary evaluation systems. This architecture solves many problems that have historically made AI evaluation unreliable.
1. Online Benchmark: Real Developer Behavior
The online benchmark tracks how developers respond to automated review comments.
Martian monitored open-source pull requests across GitHub repositories during January–February 2026. For each review comment generated by a tool, the benchmark asks:
Did the developer modify the code after the comment? If yes, the comment counts as a true positive. If the comment was ignored, dismissed, or resulted in no change, it contributes to the evaluation differently depending on the scenario.
This method removes a common source of bias in AI benchmarks.
There is:
no curated answer key
no manual annotation
no static list of bugs
Only real developer decisions. Because the dataset includes over 200,000 pull requests, it provides an unusually strong signal about how useful review comments actually are in practice.
2. Offline Benchmark: Controlled Comparison
While the online benchmark measures real-world behavior, Martian also runs a traditional offline evaluation.
In this setup:
All tools review the same 50 pull requests
Results are compared against a curated gold dataset
This allows researchers to compare tools under identical conditions.
The offline benchmark answers questions like:
Which tool identifies known bugs?
Which tool misses issues?
Which tool generates excessive false positives?
While smaller than the online dataset, this controlled environment helps validate the tools’ technical detection capabilities.
Where CodeAnt AI Landed
The results below are sorted by F1 score, the benchmark’s primary metric.
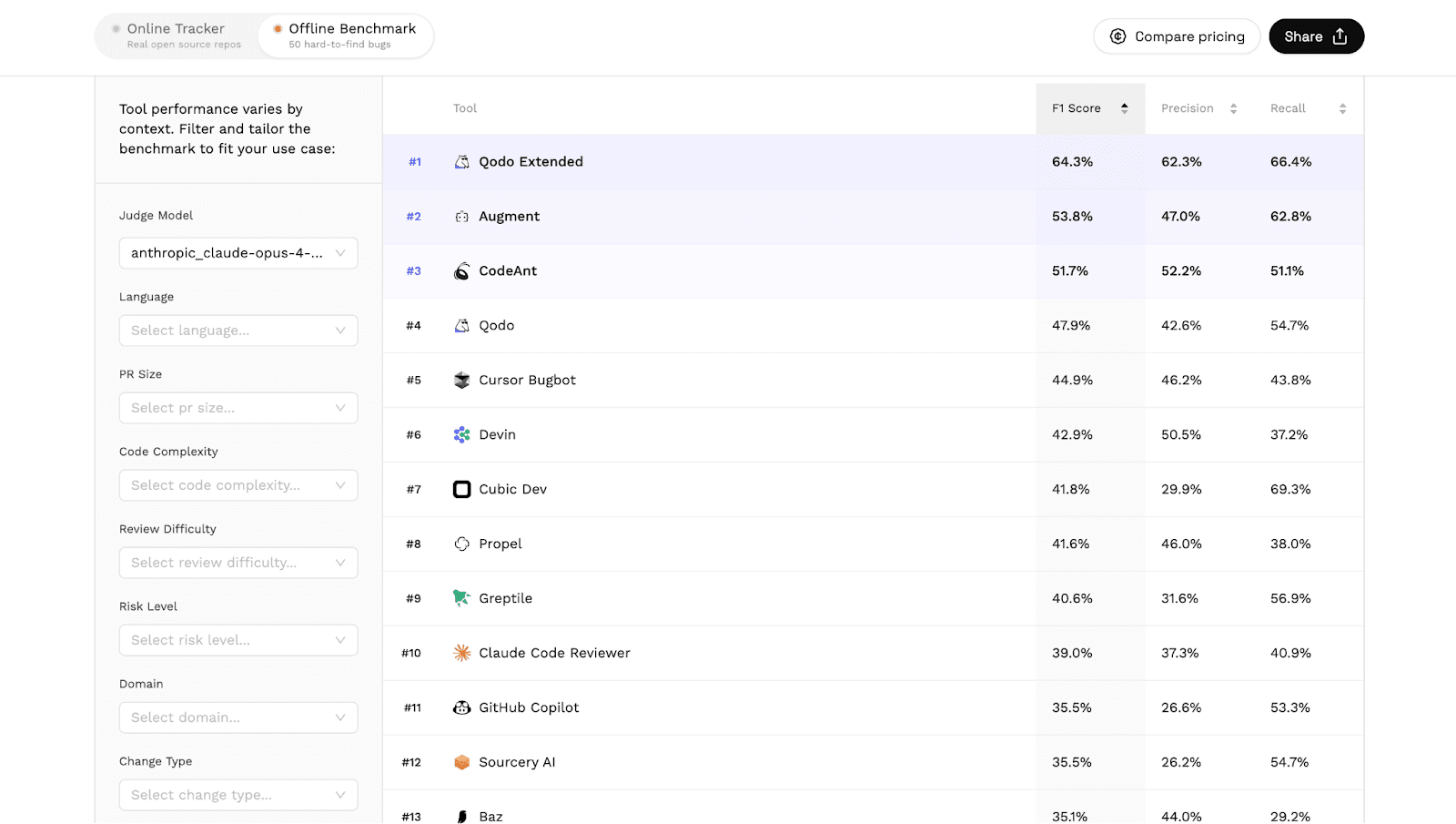
Rank | Tool | F1 | Precision | Recall |
#1 | Qodo Extended | 64.3% | 62.3% | 66.4% |
#2 | Augment | 53.8% | 47.0% | 62.8% |
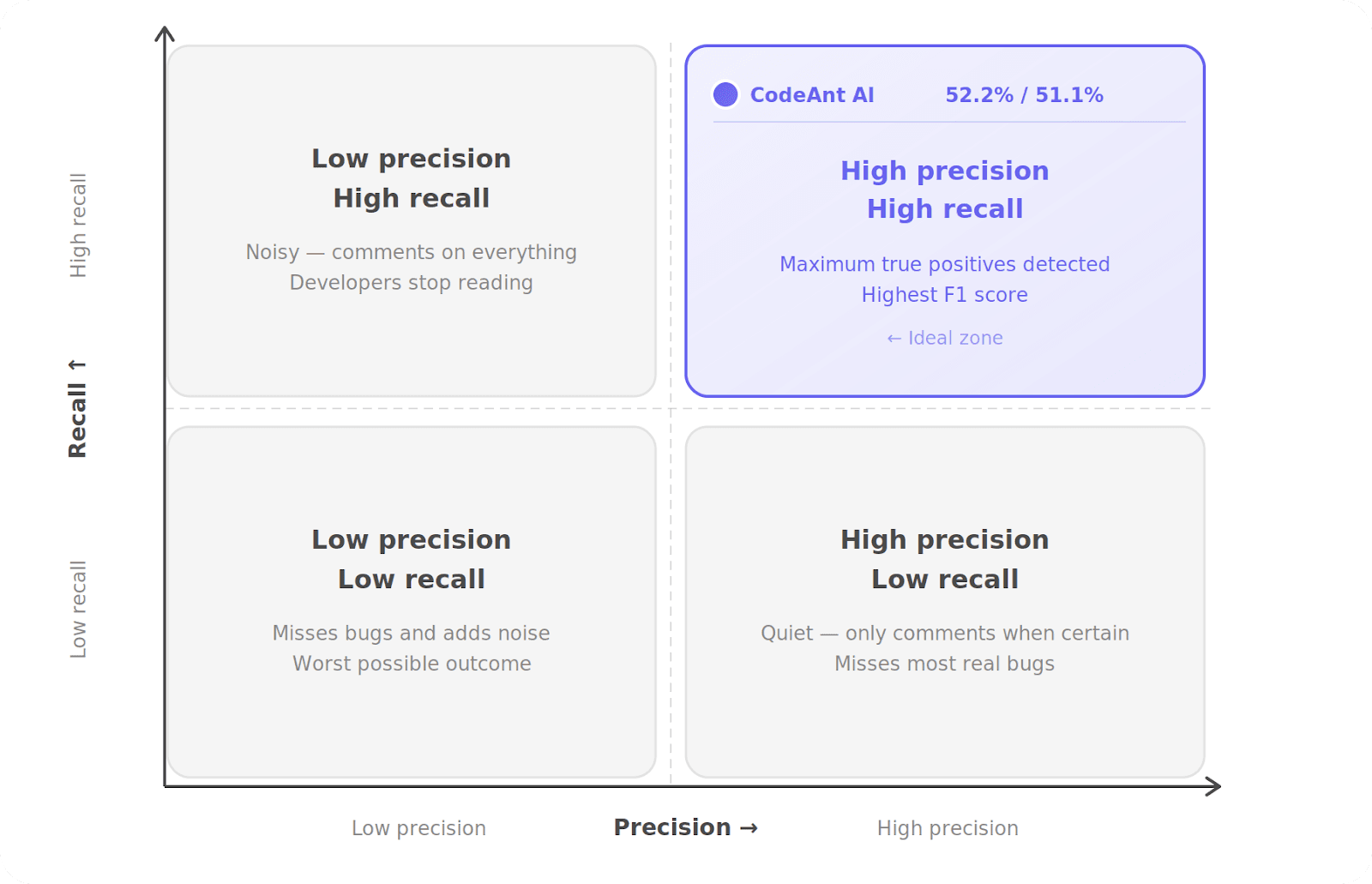
#3 | CodeAnt AI | 51.7% | 52.2% | 51.1% |
#4 | Qodo | 47.9% | 42.6% | 54.7% |
#5 | Cursor Bugbot | 44.9% | 46.2% | 43.8% |
#6 | Devin | 42.9% | 50.5% | 37.2% |
#7 | Cubic Dev | 41.8% | 29.9% | 69.3% |
#8 | Propel | 41.6% | 46.0% | 38.0% |
#9 | Greptile | 40.6% | 31.6% | 56.9% |
#10 | Claude Code Reviewer | 39.0% | 37.3% | 40.9% |
#11 | GitHub Copilot | 35.5% | 26.6% | 53.3% |
CodeAnt AI ranked #3 globally, achieving:
51.7% F1 score
52.2% precision
51.1% recall
Across thousands of repositories and hundreds of thousands of pull requests.
See the full benchmark results at codereview.withmartian.com
The practical meaning of a 52.2% precision score: when CodeAnt AI leaves a review comment on your team's PRs, more than half the time a developer will act on it. The rest of the category is closer to one in four.
Alert fatigue is real in code review. A tool that comments constantly but is wrong most of the time trains developers to ignore it. Over time, teams stop reading the bot's comments entirely. Precision is not a vanity metric, it is the difference between a code review tool that engineers trust and one they mute.
What Precision, Recall, and F1 Mean in Code Review
Understanding these metrics is essential for interpreting the benchmark.
Precision
Precision measures how often a tool’s comments identify real problems. A precision of 52.2% means: More than 1 in 2 comments generated by CodeAnt resulted in a real code change.

In practice this reflects signal-to-noise ratio. Low precision tools produce many false alarms. Developers eventually ignore them. High precision tools generate fewer, more trusted comments.
Why precision alone is not the whole story
A tool can game precision by commenting almost never. Leave one comment per PR, make it a genuinely critical bug, and your precision approaches 100%. But you will miss everything else.
This is why the benchmark measures both precision and recall together. CodeAnt AI's 51.1% recall means it is also catching a substantial proportion of the real issues in each PR — not just cherry-picking one obvious problem to protect its score.
The combination is what matters. Catching real issues (recall) without creating noise (precision) is the actual problem code review tools are trying to solve.
Recall
Recall measures how many of the real issues in a pull request the tool actually detects. CodeAnt AI’s recall of 51.1% means the system surfaces more than half of the issues present in the pull requests it analyzes.

Recall reflects coverage. A tool with low recall may stay quiet most of the time but miss critical bugs.
F1 Score
F1 combines precision and recall into a single balanced metric. It penalizes tools that optimize only one side of the tradeoff. A tool cannot achieve a high F1 score by:
detecting everything but generating noise
commenting rarely but missing bugs
The metric rewards systems that maintain both accuracy and coverage.
But benchmarks can be gamed
Martian's own blog post makes this explicit. They designed the benchmark with this in mind, which is why they run both an offline benchmark (fixed dataset, reproducible) and an online benchmark (fresh real-world PRs, no training data leakage) as a check on each other.
We are sharing these results because we think they are accurate. But we also think the strongest proof that a code review tool works is not a benchmark score at all.
It is finding real bugs in real production code before attackers do.
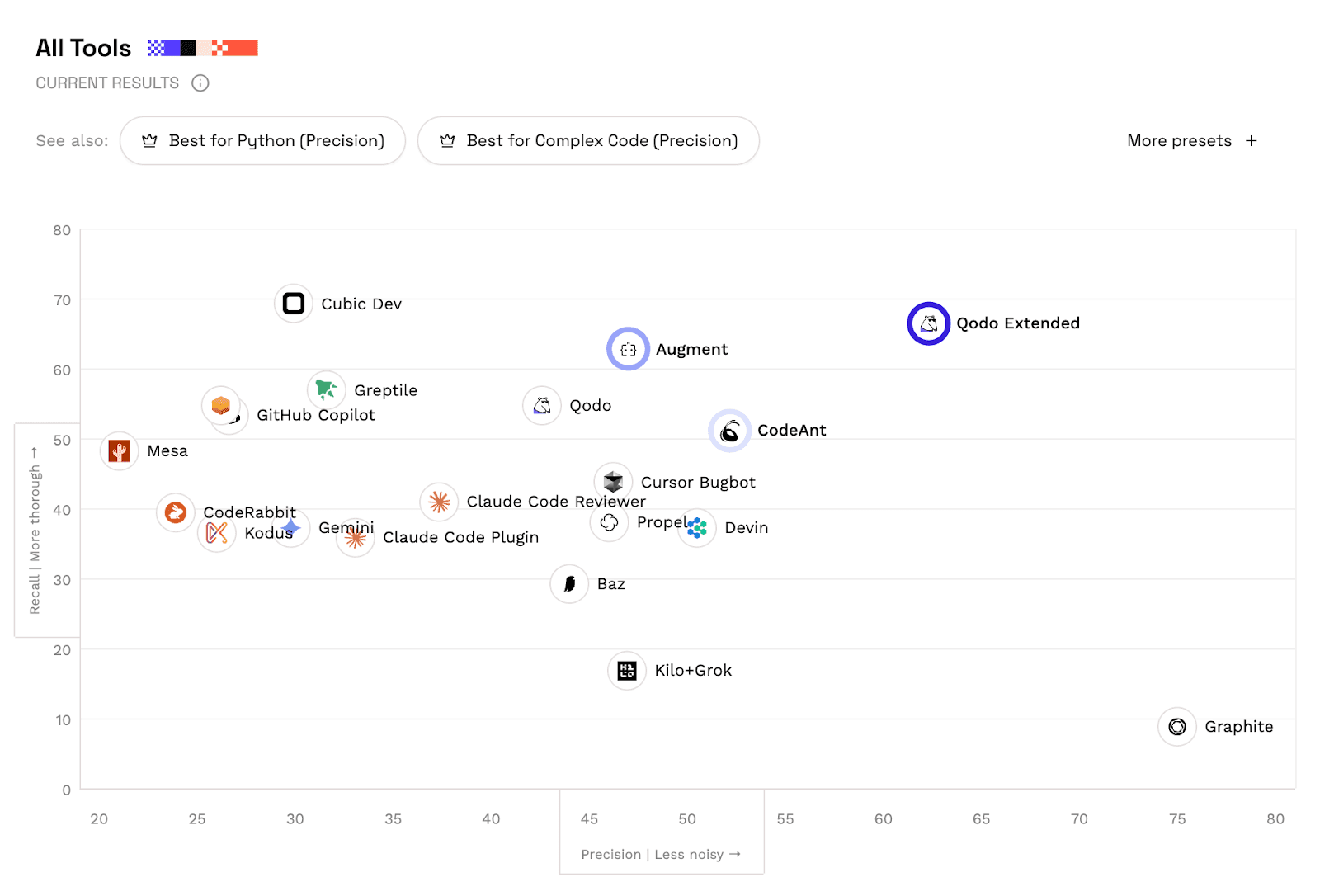
Why AI Code Review Tools Struggle With This Balance
Automated code review has always faced a structural challenge. Developers dislike tools that generate too many false positives. But they also dislike tools that miss real problems. This creates a difficult optimization problem.
High Recall Strategy
Some tools aim to detect as many issues as possible. They comment frequently. The result is high recall but low precision. Developers begin ignoring the comments.
High Precision Strategy
Other tools comment only when extremely confident. This produces high precision. But recall drops sharply. Important issues remain undetected.
Balanced Systems
The most useful tools operate in the middle. They detect a large portion of issues while maintaining a high signal-to-noise ratio. This balance is what the F1 score attempts to measure.
Why the Offline Benchmark May Underestimate Some Tools
Martian also highlights an important limitation in the current offline evaluation. The curated gold dataset used for the offline benchmark was initially built using datasets from two existing tools:
Augment
Greptile
While this allowed the benchmark to launch quickly, it introduces a structural bias. The dataset naturally reflects the categories of bugs those tools were originally designed to detect.
If another tool identifies a real issue not present in the gold set, the benchmark may classify that comment as a false positive.
In other words:
The tool may be correct.
But the dataset does not yet contain the issue.
Martian has already observed cases where comments initially marked as false positives were later confirmed to be legitimate bugs.
This is one reason the benchmark will continue evolving.
Why the Rankings May Change Over Time
The benchmark is designed to update regularly. Each monthly iteration introduces:
additional pull requests
expanded gold datasets
improved evaluation coverage
As the dataset becomes more representative of real-world code, offline and online results are expected to converge.
This means the leaderboard will likely shift over time.
Tools that detect broader categories of issues may benefit as the dataset expands.
Where CodeAnt AI Performs Particularly Well
Beyond the overall leaderboard, the benchmark also evaluates specific code review domains. In several categories, CodeAnt ranks at the top of the benchmark.
These include:
Security patch analysis
Testing issues in pull requests
Logging and PII leak detection
Large pull request review
Each of these areas is analyzed in detail in the following benchmark breakdowns:
Security Patch Detection Benchmark
Testing Issue Detection Benchmark
Logging and PII Detection Benchmark
Large Pull Request Review Benchmark
Each analysis explores how different AI systems perform on specific categories of engineering problems.
What the Benchmark Reveals About AI Code Review
The Martian benchmark provides an early look at how modern AI systems perform in real engineering environments.
Several patterns emerge from the results.
First, AI code review is still a rapidly evolving field. No tool currently achieves perfect precision or recall.
Second, tools differ significantly in how they balance signal and coverage.
Some systems prioritize detection breadth, while others prioritize comment accuracy.
Third, real developer behavior is a powerful evaluation signal.
Traditional benchmarks often struggle to capture how tools behave in real workflows. By observing developer responses to comments, Martian’s benchmark measures the real impact of automated review systems. This approach may become the standard for evaluating developer tools going forward.
Conclusion: A New Standard for Evaluating AI Code Review
The Martian Code Review Bench is the first large-scale independent attempt to measure AI code review tools using real developer behavior. Across more than 200,000 pull requests, the benchmark reveals both the progress and the limitations of modern AI-assisted code review.
In this first release:
CodeAnt AI ranked #3 globally with a 51.7% F1 score, balancing both precision and recall across thousands of repositories and engineering teams. More importantly, the benchmark introduces a transparent methodology that can evolve over time.
As datasets expand and evaluation methods improve, the leaderboard will continue to change. What will remain constant is the core objective:
High-signal code review that developers trust and act on. If you want to see what CodeAnt AI surfaces in your own repositories, you can install it in minutes and start reviewing pull requests today.

