

TL;DR
Anthropic launched Code Review on March 9, 2026, a multi-agent PR review system built into Claude Code
Available only for Team and Enterprise customers (not Pro or Max individual plans)
GitHub-only at launch; GitLab, Azure DevOps, Bitbucket not supported
Cost is token-based, and Anthropic’s own docs now put the average at $15–$25 per review
Dedicated tools like CodeAnt AI offer unlimited reviews at a flat $24/user/month
The self-review problem, AI reviewing AI-generated code, is architecturally real but partially mitigated by the multi-agent design
The Problem That Made This Launch Inevitable
AI coding assistants have created a paradox. The same tools that make developers 2–3x more productive have created a review bottleneck that is quietly becoming one of the biggest risks in software engineering.
Anthropic itself acknowledges that developers using AI assistants are producing code far faster than review capacity can keep up with. More code, more PRs, less time to review each one carefully. Human reviewers are stretched. The bugs that slip through are not always the obvious ones — they are the subtle ones, the latent ones, the ones hiding in code adjacent to what actually changed.
That is the problem Anthropic set out to solve when it launched Code Review for Claude Code on March 9, 2026.
What is Claude Code Review?
Claude Code Review is a multi-agent automated PR review system built directly into Claude Code, Anthropic’s agentic coding tool. When a pull request opens on GitHub, the system automatically dispatches multiple specialized AI agents to analyze the code simultaneously. Each agent targets a different class of issue: logic errors, boundary conditions, API misuse, authentication flaws, and compliance with project-specific conventions.
A verification step then attempts to disprove each finding before results are posted, a deliberate false positive filter. Surviving findings are deduplicated, ranked by severity, and posted as inline comments on the PR.
According to Anthropic’s official blog post, the system is designed to catch two specific categories of bugs that human reviewers most commonly miss:
Latent bugs in adjacent code, pre-existing issues in files the PR touches but doesn’t change
Subtle behavioral changes in small diffs, logic errors that look innocuous at a glance but break edge cases at runtime
In one documented case at TrueNAS, Code Review surfaced a pre-existing type mismatch in adjacent code that was silently wiping an encryption key cache on every sync, a bug that had nothing to do with the PR change itself, but was exposed because the system analyzed full codebase context, not just the diff.
How it Works Technically
The architecture is the story here, so it is worth walking through the moving parts.
Multi-Agent Architecture
Unlike most AI code review tools that make a single pass through the diff, Claude Code Review is a multi-agent pipeline. Here is what happens when a PR opens:
Multiple review agents analyze the diff and the surrounding code in parallel on Anthropic’s infrastructure.
A verification step re-checks every candidate finding against actual code behavior and drops anything it cannot substantiate.
Surviving findings are deduplicated and ranked by severity.
The PR gets inline comments plus a summary. If nothing is found, the check run simply completes.
The verification step is architecturally significant. Most AI reviewers post every finding they generate. Claude Code Review forces agents to challenge their own output before surfacing it — the primary mechanism for reducing false positives.
Full Codebase Context, Not Just the Diff
This is the most important technical distinction between Claude Code Review and most competitors. The system does not only look at what changed. It indexes the full repository and analyzes changes in the context of the entire codebase. This is how it catches the TrueNAS-style latent bug, it can reason about how a change interacts with code in files not included in the diff.
Diff-based tools like CodeRabbit analyze only the changed lines. Full codebase tools like Greptile and CodeAnt AI analyze the broader system. Claude Code Review falls into the latter category for this specific capability.
Review Scale by PR Size
Reviews are not one-size-fits-all. According to Anthropic’s documentation, the system scales dynamically:
PR Size | % Receiving Findings | Avg. Issues Found | Avg. Completion Time |
|---|---|---|---|
Small (< 50 lines) | 31% | 0.5 | ~5–8 minutes |
Large (> 1,000 lines) | 84% | 7.5 | ~20 minutes |
Average completion time runs approximately 20 minutes for a full review, slower than instant static analysis tools, but significantly deeper. Anthropic’s internal data shows that after deploying Code Review, the percentage of PRs receiving substantive review comments jumped from 16% to 54%, with engineers marking fewer than 1% of findings as incorrect.
Configuration
Teams can customize the behavior through two files in the repository:
CLAUDE.md: general project context, coding conventions, architecture decisions
REVIEW.md: specific review scope, what to ignore, what to prioritize (injected into every review agent’s system prompt at highest priority)
Code Review defaults to detecting correctness bugs only; logic errors, security vulnerabilities, broken edge cases, and regressions. It deliberately ignores style, formatting, and missing test coverage by default. Teams can expand scope through these configuration files.
Who Can Access it and Who Cannot
This is where most of the early confusion has come from. Claude Code Review is not available to individual developers on Pro or Max plans.
As of the March 9 launch, it is available in research preview only for:
Team plan customers, with Code Review billed separately through usage credits rather than a specific seat type
Enterprise plan customers (custom pricing)
Individual plans have no access to Code Review:
Plan | Price | Claude Code Access | Code Review Access |
|---|---|---|---|
Free | $0/month | No | No |
Pro | $20/month | Yes | No |
Max 5x | $100/month | Yes | No |
Max 20x | $200/month | Yes | No |
Team (standard seat) | $25/month ($20 annual) | Yes | Yes ✓ (usage credits) |
Team (premium seat) | $125/month ($100 annual) | Yes | Yes ✓ |
Enterprise | Custom | Yes | Yes ✓ |
Source: Claude pricing and Claude Code documentation
What Pro and Max Users Actually Get
The managed reviewer is Team-and-up, but it is not the only surface. Anthropic ships four ways to get a Claude review, and three of them work on individual plans.
Surface | Who gets it | Cost |
|---|---|---|
Managed Code Review (GitHub App) | Team and Enterprise | $15–25/review via usage credits |
/code-review in Claude Code | Any plan | Counts toward normal plan usage |
/code-review ultra (ultrareview) | Pro and Max | 3 free runs, then ~$5–20/run |
Open-source code-review plugin | Anyone | Your own API usage |
Ultrareview runs a multi-agent fleet in the cloud for 5 to 10 minutes per run. It is not available through Bedrock, Vertex, or Foundry, or under zero-data-retention agreements.
The Pricing Reality: What Does it Actually Cost?
This is the most important question for any team evaluating Code Review, and the answer is not straightforward.
Anthropic now publishes an official average of $15–$25 per review. Cost is token-based and scales with PR size, codebase complexity, and how many findings need verification. For general Claude Code usage the docs cite about $13 per developer per active day, with $150–250/month typical, and that refers to coding assistance, not Code Review.
VentureBeat’s launch day analysis estimated the same $15–$25 per review on average on launch day. Anthropic has since documented the range in the official docs Pricing section, so the number is no longer just a journalist’s calculation.
The practical cost impact at scale:
Team Size | PRs/Day | Monthly Reviews | Est. Monthly Cost (at $20 avg) |
|---|---|---|---|
10 developers | 10 | 200 | ~$4,000 |
50 developers | 50 | 1,000 | ~$20,000 |
100 developers | 100 | 2,000 | ~$40,000 |
Estimates based on Anthropic’s documented $15–$25/review average. Actual costs vary by PR size and configuration.
Anthropic provides guardrails: monthly spending caps, repository-level enable/disable controls, and an analytics dashboard tracking per-repo average costs. If you enable the “review on every push” trigger mode (rather than only on PR open), costs multiply with every commit to a PR branch. Code Review bills through usage credits and does not count against plan usage, and admins set the spend cap in claude.ai admin settings.
Reviews run in one of three per-repo modes, once after PR creation, after every push, or manual. Commenting @claude review subscribes a PR to push reviews, and @claude review once runs a single pass.
How Competitors Charge - a Direct Cost Comparison
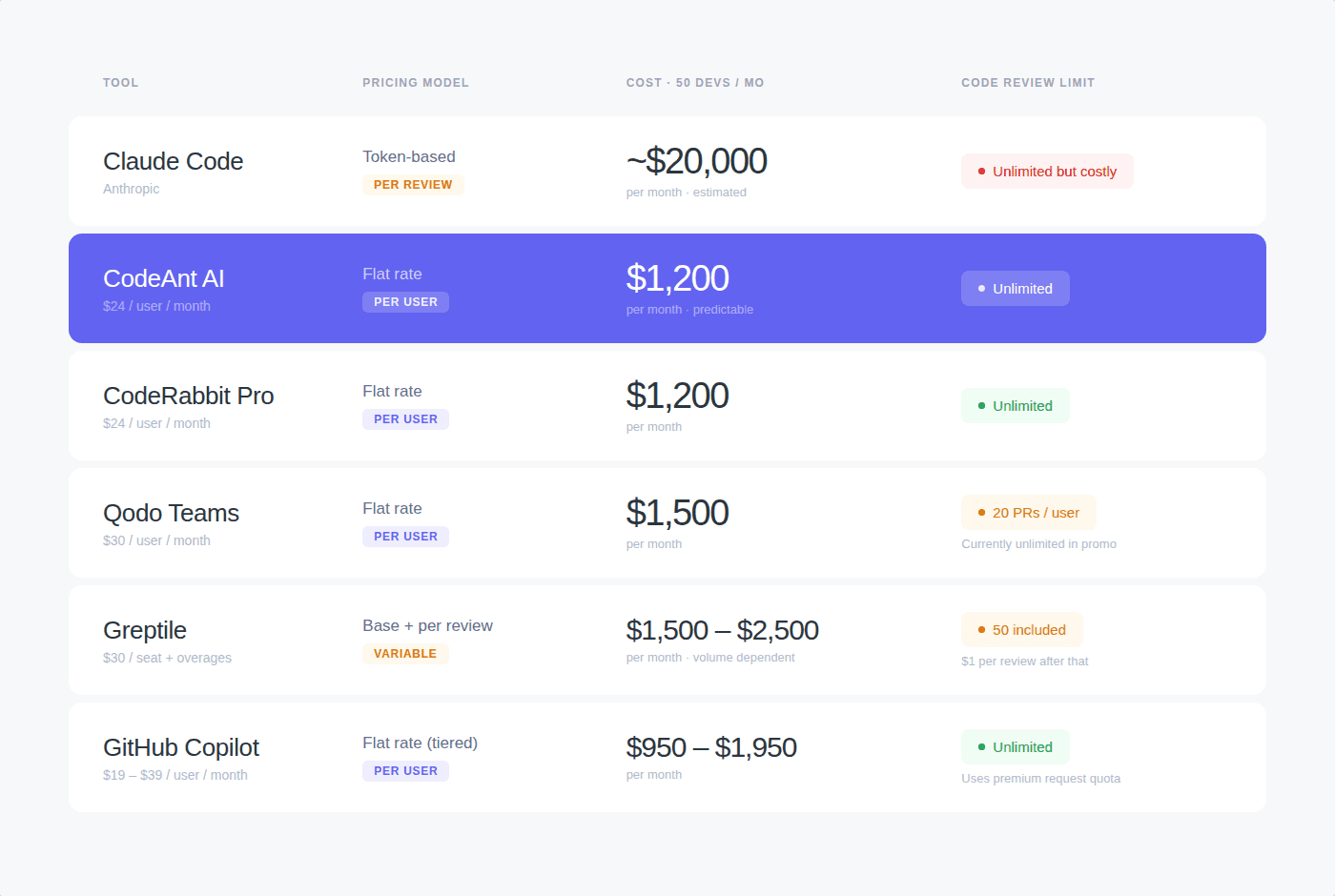
The pricing gap between Claude Code Review and dedicated AI code review tools is stark. Most dedicated tools use flat per-seat pricing with unlimited reviews.
Tool | Pricing Model | Cost for 50 Developers | Code Review Limit |
|---|---|---|---|
Claude Code Review | $15–25/review (usage credits) | ~$20,000/month (est.) | Unlimited but expensive |
CodeAnt AI | $24/user/month flat | $1,200/month | Unlimited |
CodeRabbit Pro | $24/user/month flat | $1,200/month | Unlimited |
Qodo Teams | $30/user/month flat | $1,500/month | No limits on repos or reviews (pooled credits) |
Greptile | $30/seat + $1/review over 50 | ~$1,500–2,500/month | 50 included, then $1 each |
GitHub Copilot | $19–39/user/month | $950–1,950/month | Unlimited (uses premium requests) |
Pricing verified from official pricing pages: CodeAnt AI, CodeRabbit, Qodo, Greptile. Claude Code Review pricing from Anthropic’s documented average, verified July 2026.
Anthropic’s counterargument: a single production incident, a rollback, a hotfix, an on-call page, can cost more in engineer hours than a month of Code Review. The implicit claim is that depth justifies the premium. Whether that holds is an empirical question each team has to answer with their own incident data.
Platform Support: GitHub Only at Launch
At launch, Claude Code Review is a GitHub-exclusive managed service (github.com and GitHub Enterprise Server). Setup requires installing a Claude GitHub App to your organization with:
Read and write access to repository contents
Read and write access to issues and pull requests
There is no native support for GitLab, Azure DevOps, or Bitbucket in the managed Code Review product. Teams on GitLab can access lighter-weight review capabilities through the Claude Code GitLab CI/CD integration, which runs on their own infrastructure. A GitLab CI/CD integration is documented in beta, and a native integration is tracked as an open feature request in the claude-code repository.
For teams with multi-platform version control, GitHub for some teams, Bitbucket for others, Azure DevOps for enterprise workflows, this is a hard constraint at launch.
Comparison on platform support:
Tool | GitHub | GitLab | Bitbucket | Azure DevOps |
|---|---|---|---|---|
Claude Code Review | ✓ | Partial (CI/CD only) | ✗ | ✗ |
CodeAnt AI | ✓ | ✓ | ✓ | ✓ |
CodeRabbit | ✓ | ✓ | ✓ | ✓ |
Qodo | ✓ | ✓ | ✓ | ✗ |
Greptile | ✓ | ✗ | ✗ | ✗ |
What it Can and Cannot Detect
The scope is deliberately opinionated in both directions.
What Code Review targets by default
Logic errors and incorrect control flow
Broken edge cases and boundary conditions
Security vulnerabilities (authentication, injection, exposure)
API misuse
Regressions in behavior
Latent bugs in code adjacent to the PR changes
What it deliberately ignores by default
Code style and formatting preferences
Missing test coverage
Performance optimizations
Documentation gaps
Teams can expand scope through REVIEW.md configuration, but the default is intentionally narrow, correctness bugs only.
Findings arrive with severity labels: 🔴 important, 🟡 nit, and 🟣 pre-existing.
The check run always completes as neutral, so a review never blocks a merge on its own. Teams that want gating parse the machine-readable severity JSON in the check-run details from their own CI.
Known technical constraints
Reviews take ~20 minutes, not instant. If your team merges PRs in under 30 minutes regularly, this creates a workflow friction point.
Cannot execute code, analysis is reasoning-based, not runtime verification. It cannot catch bugs that only appear at runtime with real data.
Unavailable for Zero Data Retention organizations, if your enterprise has ZDR enabled in your Anthropic contract, Code Review cannot be used.
No SAST, secrets detection, or IaC scanning, security analysis is described as “light.” Deeper vulnerability scanning is delegated to the separate Claude Code Security product. Dedicated tools like CodeAnt AI bundle SAST, secrets detection, and IaC scanning into the same review workflow.

The Self-Review Problem: Can AI Grade Its Own Homework?
The most important open question about Claude Code Review is also the most uncomfortable one: if AI tools wrote the code, can AI tools effectively review it?
This is not a hypothetical concern. As developers use Cursor, GitHub Copilot, and Claude Code to write increasing proportions of production code, the reviewer and the author start sharing the same underlying models, training data, and systematic blind spots.
Builder.io documented the concern directly: “Asking an AI to grade its own work is a bit like hiring spell-check to edit a novel. Machine-generated code often looks more polished than human work, and its symmetry can hide deep nonsense.”
Ankit Jain, CEO of Aviator, argued in Latent.Space that post-PR review itself is becoming obsolete: “When agents write code, ‘fresh eyes’ is just another agent with the same blind spots. LLMs are unreliable at self-verification — they’ll confidently tell you the code works while it’s on fire.”
IBM Research’s 2026 AAAI paper quantified the problem: LLM-as-Judge alone detects only about 45% of code errors. Combining LLMs with deterministic analysis tools raised detection to 94%.
What Anthropic built to address it
The multi-agent design is specifically an architectural response to the self-review problem:
Multiple independent specialized agents, rather than one model making one pass, different agents with different scopes analyze the same code independently, reducing the chance that a shared blind spot affects all findings simultaneously
Verification step, each agent must attempt to disprove its own findings before surfacing them
No auto-approve, Code Review never approves PRs. The human always makes the merge decision.
Whether these mitigations are sufficient is genuinely uncertain. Agents from the same provider family may still share architectural biases regardless of specialization. The honest answer is: we do not have enough real-world data yet to know how well multi-agent Anthropic models catch bugs written by single-agent Anthropic models.
The IBM data suggests the prudent approach is to combine Claude Code Review with deterministic static analysis tools rather than treating it as a standalone solution, a point Anthropic itself implicitly acknowledges by keeping SAST in a separate product.
What CodeAnt AI Does Differently
CodeAnt AI is an AI-native code review platform, part of a defensive and offensive security stack, designed to work regardless of who, or what, wrote the code. A few meaningful differences worth understanding:
On cost: CodeAnt AI charges $24/user/month flat with unlimited reviews.
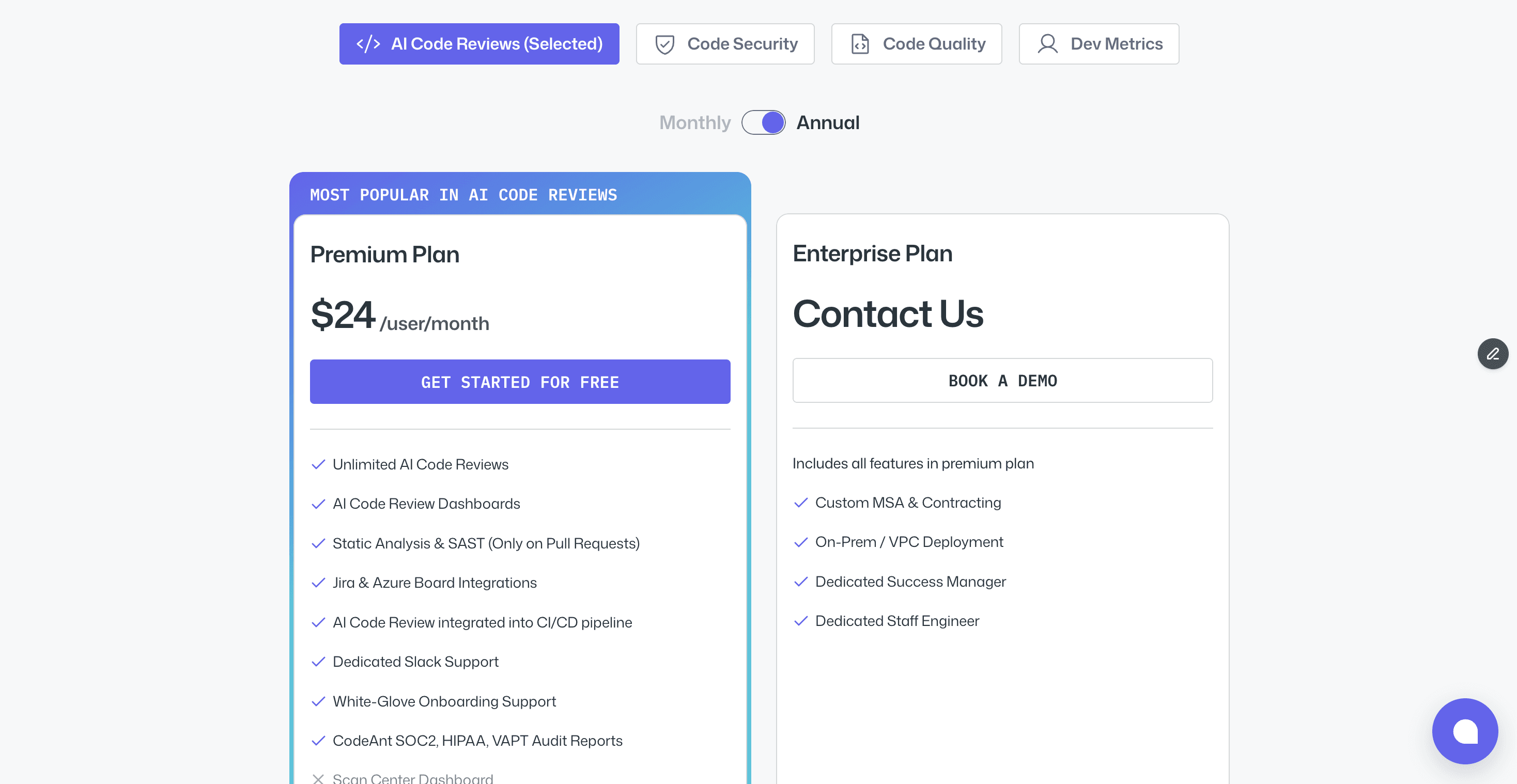
There is no per-PR cost, no token consumption billing, and no surprise bill at the end of the month. For a 50-person team, that is $1,200/month regardless of PR volume, versus an estimated $15,000–$25,000/month for Claude Code Review at similar volumes.
On platform coverage: CodeAnt AI supports GitHub, GitLab, Azure DevOps, and Bitbucket in a single workflow. Teams with mixed version control environments do not need separate tools or workarounds.
On security: CodeAnt AI bundles SAST, secrets detection, and IaC scanning, and AI code review in a single platform. There is no separate “security product” to license. Every PR review includes security analysis by default.
On the self-review problem: CodeAnt AI is a purpose-built reviewer, not a code generator. It does not write code and review it with the same underlying model. The reviewer and the author are architecturally separate.
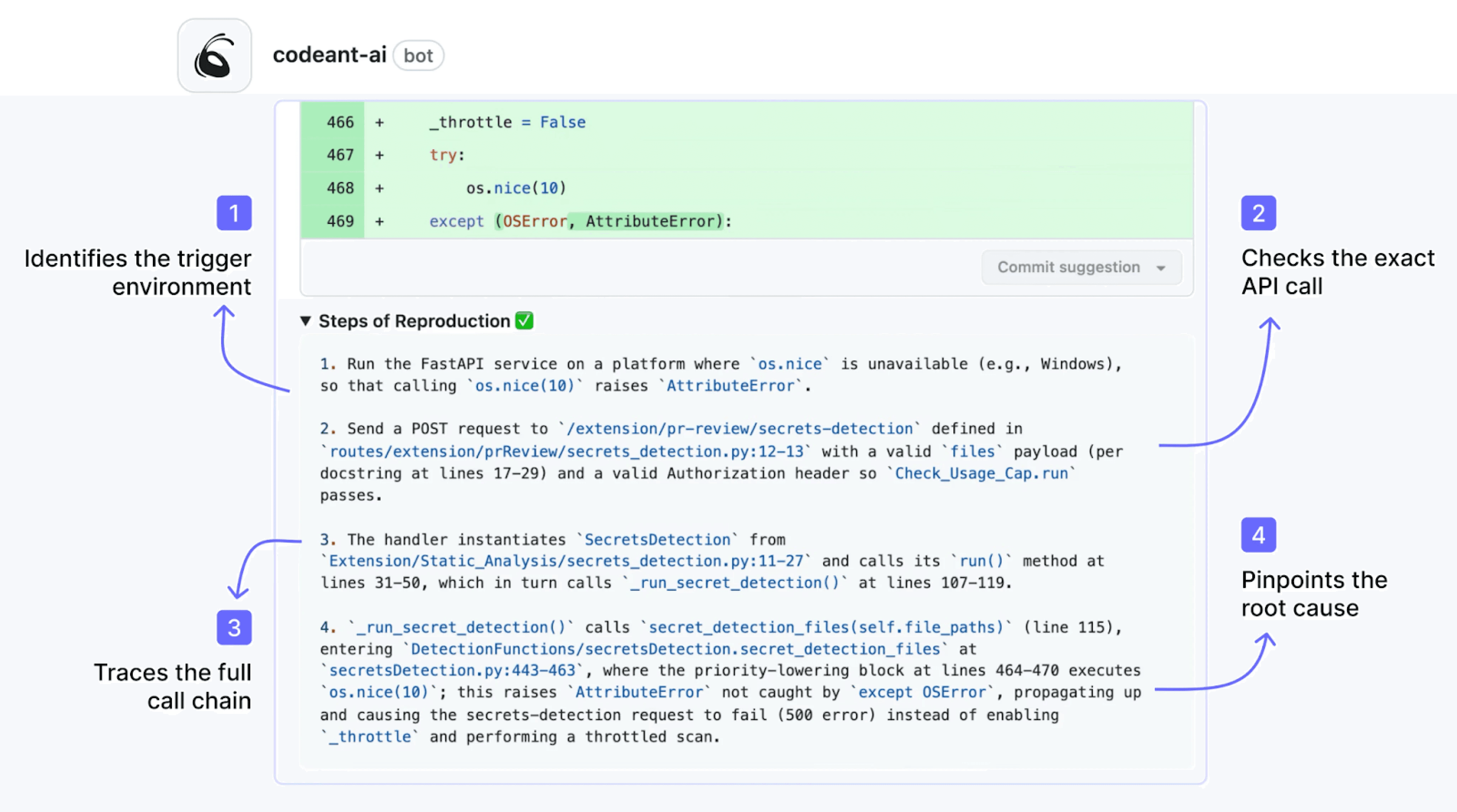
On Steps of Reproduction: CodeAnt AI’s Steps of Reproduction feature automatically identifies the conditions needed to trigger a bug flagged in a PR, a capability that eliminates the “I can’t reproduce it” back-and-forth between reviewer and developer.
The Bottom Line
Claude Code Review brings multi-agent verification, full-codebase context, and a falsification step that filters noise before it reaches developers. Anthropic’s own numbers (findings on 16% of PRs rising to 54%, under 1% incorrect) hold up if they carry across diverse codebases.
Two constraints shape the decision. It is GitHub-only, which rules it out for multi-platform teams, and at roughly $15-25 per review the math only works if it catches bugs cheaper tools miss.
For most teams as of July 2026, the practical move is to run the preview alongside your current reviewer and compare what each catches on the same PRs. If you want unlimited reviews plus SAST, secret, and IaC scanning in one tool across GitHub, GitLab, Bitbucket, and Azure DevOps, CodeAnt AI covers that at a flat $24 per user per month.
See how CodeAnt AI compares to dedicated AI code review tools. Start a free trial or talk to our team.

