AI Code Review
Best Pull Request Automation Tools for Large Engineering Teams

Sonali Sood

Founding GTM, CodeAnt AI
Your engineering team ships 2-3x more code since adopting AI code generation, but PRs still sit for days awaiting review. Senior engineers burn 15+ hours weekly on routine checks, style violations, test coverage, dependency conflicts, while architectural risks slip through because file-level tools can't see the full picture. When you're managing 100+ developers across microservices or monorepos, GitHub Copilot's file-level analysis and SonarQube's 40% false positive rate don't cut it anymore.
This guide evaluates six PR automation platforms through the lens of what large teams actually need: architectural context across repositories, sub-5% false positive rates, governance controls, and DORA metrics integration. You'll see exactly where file-level bots break down and which platform delivers the continuous code health that keeps elite teams shipping confidently at scale.
The PR Review Gap: When AI Code Generation Outpaces Human Oversight
AI-powered code generation has altered software development economics, but not as expected. GitHub Copilot and similar tools help developers produce 2–3x more code per sprint, yet human review capacity remains flat. For organizations with 100+ developers, this creates PR queue inflation: pull requests that once took 6–8 hours to merge now sit for 3–5 days awaiting review.
Senior engineers spend 15+ hours weekly on routine checks instead of evaluating architectural decisions. Traditional static analysis tools like SonarQube flag 200+ issues per PR with 40–50% false positive rates, training teams to ignore warnings until production breaks.
At scale, the stakes escalate rapidly. A 250-engineer team managing microservices across 20+ repositories faces cross-service regressions that file-level tools can't detect. LinearB's 2026 benchmarks show AI-authored PRs have a 32.7% acceptance rate versus 68% for human-written code, yet most review automation treats all code identically.
This guide delivers a ranked comparison of six leading PR automation platforms, evaluated for challenges large teams face: latency under high PR volume, context-aware analysis across repositories, governance controls for compliance, and measurable impact on DORA metrics.
What Changes at 100+ Engineers: Scale-Specific Failure Modes

Three Operational Thresholds
100–250 Engineers: The Monorepo Breaking Point
File-level analysis starts failing catastrophically. The core failure mode: semantic drift between services. A developer changes a shared utility function, and three downstream consumers break in production because your PR tool only analyzed changed files, not the dependency graph.
CODEOWNERS files become bottlenecks. Principal engineers get tagged on 40% of PRs for critical shared libraries, spending 15+ hours weekly reviewing routine changes. Merge queues show 6–12 hour delays during sprint completion.
250–500 Engineers: Multi-Repo Orchestration Hell
You're coordinating 30–100 repositories with complex cross-service dependencies. The dominant failure mode: architectural context blindness. Your PR tool flags 200+ issues per PR but misses that a payment service API change will break checkout, inventory, and fraud detection services simultaneously.
CI costs explode, $50K+ monthly, because every tool (linter, security scanner, test runner) operates independently, duplicating work. Standards fragment across squads with no way to enforce consistency.
500+ Engineers: Governance Becomes Non-Negotiable
Managing 100+ repositories with regulatory requirements (SOC 2, PCI-DSS, HIPAA). The critical failure mode: post-merge drift. Code that passed all PR checks accumulates technical debt over months because no tool continuously validates the entire codebase.
DORA metrics tracking becomes essential but stitching together data from GitHub, Jira, PagerDuty, and CI/CD platforms requires custom dashboards that break every quarter. Compliance audits consume 200+ engineering hours because you can't automatically prove every merged PR met security standards.
Non-Negotiable Requirements for Enterprise PR Automation
1. Context Depth: Beyond File-Level Analysis
File-level context: Catches syntax, style, basic security within changed files. Breaks down when changes affect multiple services.
Repository-level context: Understands dependencies within a single repo. Struggles with monorepos over 100K LOC or cross-repo changes.
Multi-repo architectural context: Builds semantic dependency graphs across repositories, tracking how changes propagate through your system.
Benchmark: At 250+ PRs/month, you need sub-90-second analysis processing 50K–500K LOC across 10–50 repositories without degradation.
2. Precision and Noise Control
A 40% false positive rate means senior engineers spend 6+ hours weekly triaging noise. At 400 PRs monthly, that's $15K+ in lost productivity per month.
Tool Category | False Positive Rate | Configuration Overhead | Adapts to Team Patterns |
File-level bots | 30–50% | Low | No |
Static analyzers | 40–50% | High | No |
Context-aware AI | 5–15% | Medium | Yes |
3. Latency and Concurrency Under Load
Sprint completion days see 20+ simultaneous PR submissions. If your automation takes 10+ minutes per review or queues requests sequentially, you've created a new bottleneck.
Critical metrics:
P80 review latency: Under 90 seconds for 200–400 LOC changes
Concurrent capacity: Handle 15–20 simultaneous PRs without degradation
Monorepo performance: Sub-2-minute reviews for 200K+ LOC repos
4. Governance and Compliance
Essential capabilities:
Policy-as-code: Organization-specific rules that auto-enforce across teams
Audit trails: Immutable logs showing who approved what, when, and which checks passed/failed
Compliance reporting: Pre-built dashboards for SOC 2, ISO 27001
Role-based controls: Granular permissions for overrides and policy changes
5. Automated Remediation
Identifying 200 issues per week is useless if engineers spend 15 hours manually fixing them.
Must-haves:
One-click fixes: Auto-generate patches for common issues
Safe auto-apply: Auto-commit low-risk fixes with rollback capability
Suggested refactors: AI-generated improvements with diff preview
Batch operations: Fix same issue across 10 files with single action
6. Post-Merge Continuous Scanning
PRs are point-in-time snapshots. New vulnerabilities emerge daily, dependencies update, compliance requirements evolve.
Critical for:
Continuous monitoring of main branches
Drift detection when merged code violates new policies
Dependency tracking when merged libraries develop CVEs
Automated remediation workflows
7. DORA Metrics Integration
Leaders managing 100+ developers need visibility into review efficiency, code quality trends, and team performance.
Requirements:
Automated DORA metrics collection (deployment frequency, lead time, MTTR, change failure rate)
Review efficiency metrics (PR cycle time, review load per engineer)
Quality trends (technical debt, test coverage, security posture)
Team-level dashboards for performance comparison
Context Depth Spectrum: Why File-Level Bots Break Down
Context Level | What It Sees | Typical Tools | Breaks Down When... |
File/Diff-Level | Changed lines, AST of modified files | GitHub Copilot, CodeRabbit | Cross-file dependencies, API contracts |
Repository-Level | Full repo structure, static call graphs | SonarQube, DeepSource | Multi-repo architectures, shared libraries |
Multi-Repo Architectural | Semantic dependency graphs across repos | CodeAnt AI | (Designed for this complexity) |
Real Scenario: API Contract Change Across Services
You modify a REST endpoint in payment-service to add a required field. File-level tools see valid TypeScript. Repository-level tools confirm internal consistency. But three downstream services still send the old payload shape.
CodeAnt AI's dependency graph traces the API contract across service boundaries, flagging all three call sites that will break in production. A fintech customer avoided a P0 incident when CodeAnt AI caught this exact scenario, their previous tool approved the change because it looked fine in isolation.
Best Pull Request Automation Tools: Ranked Comparison
1. CodeAnt AI: Best Overall for Multi-Repo Enterprise Teams
Best for: 100-500+ developer organizations managing microservices, monorepos, or complex multi-repo architectures requiring governance and continuous code health.
Strengths:
Architectural context across repositories: Semantic dependency graph processes 400,000+ files, catching cross-service breaking changes file-level tools miss
Sub-5% false positive rate: Reduces noise by 80% compared to SonarQube's 40-50% rate
One-click fixes with context: Generates production-ready fixes that understand your codebase patterns
Continuous post-merge scanning: Validates code health after merge, catching drift
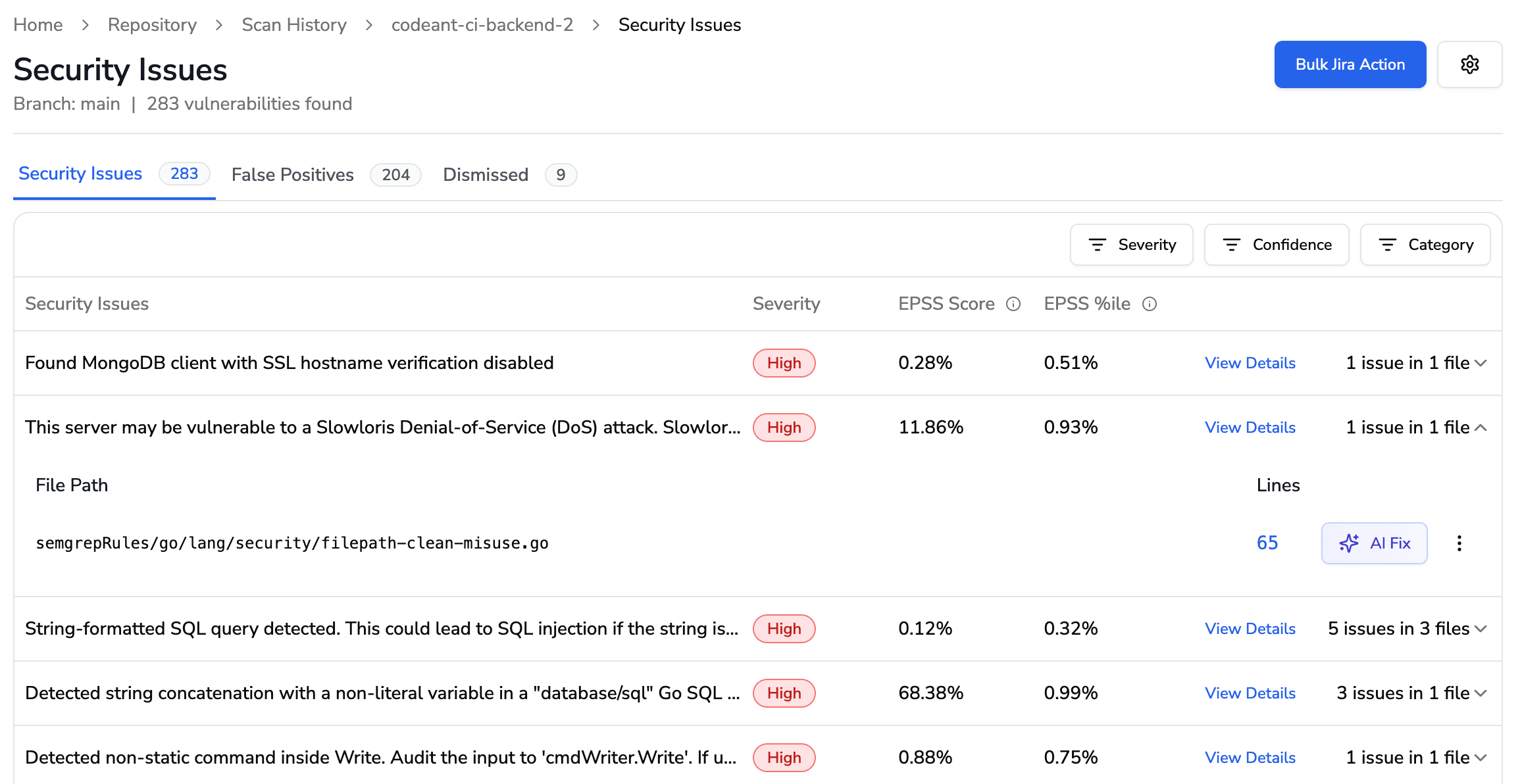
DORA metrics integration: Tracks deployment frequency, lead time, change failure rate alongside code quality
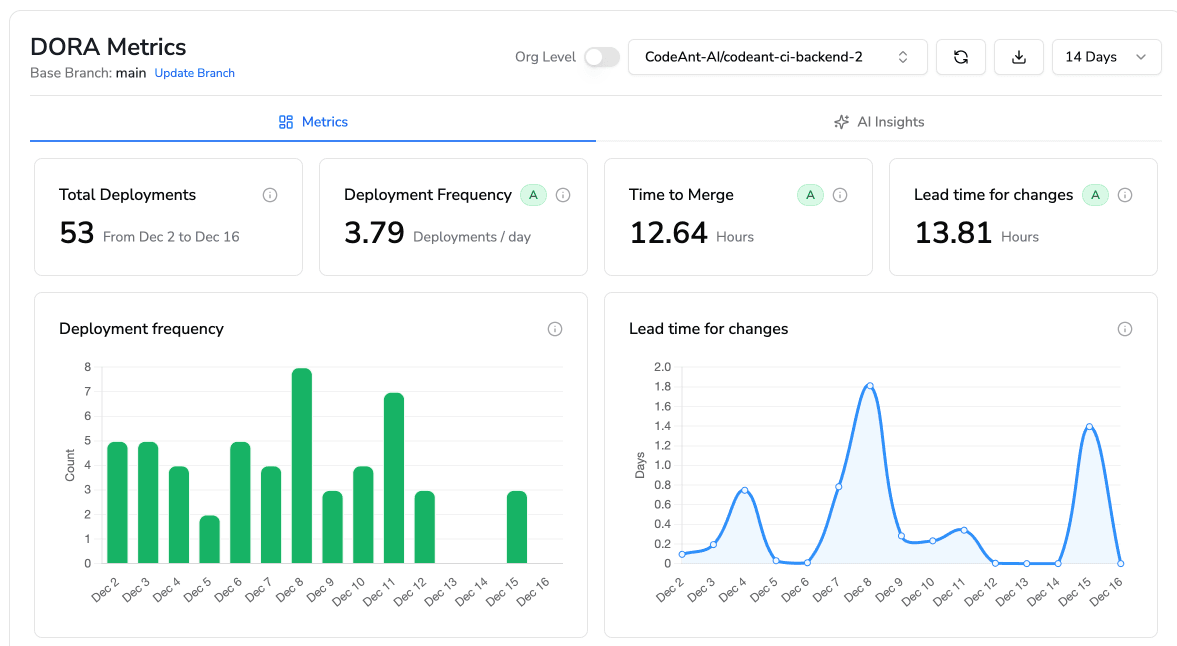
Real-world impact: A 200-engineer e-commerce platform reduced senior engineer review load from 15 hours/week to 4 hours/week (65% reduction) while catching a critical cross-service integration failure that passed GitHub's merge queue and SonarQube checks.
Read detailed real use cases here.
Avoid if: Sub-50 developer team with single repository and simple workflow.
Pricing: Enterprise-focused. A typical 200-engineer team saves $500K+ annually in reduced review time and prevented incidents.
2. GitHub Copilot: Best for Native GitHub Integration
Best for: GitHub-centric teams under 100 developers with simple, single-repo workflows.
Strengths:
Seamless Microsoft ecosystem integration
Familiar developer experience
Fast setup
Where it breaks at scale:
File-level analysis only: Misses cross-file dependencies and architectural impacts
30-40% false positive rate: Generates significant noise on large PRs
No post-merge validation: Compliance drift accumulates undetected
Limited governance controls: No custom rule enforcement or audit trails
Real limitation: A fintech team merged a PR that modified authentication middleware. Copilot flagged syntax issues but missed that the change broke API compatibility for three internal services. The issue surfaced in production.
Pricing: $21/user/month (Business) or $39/user/month (Enterprise).
Checkout the best Github Copilot alternative.
3. SonarQube: Best for Compliance-Heavy Static Analysis
Best for: Organizations prioritizing compliance reporting over developer velocity.
Strengths:
Mature 30+ language support
Comprehensive compliance dashboards
Industry standard with extensive documentation
Where it breaks at scale:
40-50% false positive rate: Hundreds of low-priority warnings per PR
Repository-level context only: Misses cross-service dependencies
No AI-driven fixes: Engineers spend 15-20 minutes per issue researching fixes
Complex CI/CD configuration: Significant DevOps effort for monorepos
Complementary use: Many CodeAnt customers run both—SonarQube for compliance dashboards, CodeAnt for day-to-day reviews with 80% fewer false positives.
Pricing: Free (Community), $150/year per 100K LOC (Developer), custom enterprise pricing.
Checkout the best SonarQube alternative.
4. CodeRabbit: Best Standalone Bot for Mid-Sized Teams
Best for: 25-75 developer teams willing to invest configuration time for detailed AI feedback.
Strengths:
Detailed line-by-line explanations
Conversational interface for questions
Configurable rules per repository
Where it breaks at scale:
Clutters PR timelines: 10-20 comments per PR
File-level analysis: Misses architectural impacts
25-35% false positive rate
No DORA metrics or leadership visibility
Pricing: $15/user/month (Pro) or custom enterprise pricing.
Checkout the best CodeRabbit alternative.
5. GitHub Advanced Security: Best for Security-Focused PR Gating
Best for: GitHub-native teams prioritizing security scanning over comprehensive code health.
Strengths:
Native GitHub integration
CodeQL for vulnerability detection
Secret scanning and dependency review
Where it breaks:
Security-only focus: Doesn't address code quality or architectural issues
No AI-driven fixes
Limited governance controls
No post-merge validation
Pricing: Included with GitHub Enterprise Cloud, $49/user/month standalone.
6. Snyk Code: Best for Dependency Security
Best for: Teams prioritizing open-source dependency security, especially in JavaScript ecosystems.
Strengths:
Real-time dependency vulnerability scanning
License compliance checks
Developer-friendly UI
Where it breaks:
Dependency-focused only: Doesn't address code quality or architecture
Limited language support for code analysis
No architectural context
No DORA metrics or post-merge scanning
Pricing: Free (limited), $98/month (Team), custom enterprise pricing.
Checkout the best Synk alternative.
Comparison Table: Enterprise Readiness
Tool | Context Depth | False Positive Rate | One-Click Fixes | Post-Merge Scanning | DORA Metrics | Best For |
CodeAnt AI | Multi-repo architectural | <5% | ✅ Yes | ✅ Yes | ✅ Yes | 100+ dev teams, microservices |
GitHub Copilot | File-level | 30-40% | ❌ No | ❌ No | ❌ No | <100 dev teams, simple repos |
SonarQube | Repository-level | 40-50% | ❌ No | ⚠️ Limited | ❌ No | Compliance-heavy orgs |
CodeRabbit | File-level | 25-35% | ❌ No | ❌ No | ❌ No | 25-75 dev teams |
GitHub Advanced Security | File-level (security) | 15-25% | ❌ No | ❌ No | ❌ No | Security-focused GitHub teams |
Snyk Code | Dependency-level | 20-30% | ⚠️ Limited | ❌ No | ❌ No | Dependency security priority |
Decision Framework: When CodeAnt AI Becomes Non-Negotiable
Choose CodeAnt AI when:
Your team crosses 100 developers and file-level tools miss cross-service impacts
You manage microservices, monorepos, or 10+ repositories requiring architectural awareness
Senior engineers spend 10+ hours weekly on routine PR reviews
Compliance requirements demand continuous post-merge validation and audit trails
Leadership needs DORA metrics to track team performance alongside code quality
False positive rates above 20% are training your team to ignore bot feedback
Stick with alternatives when:
Sub-50 developer team with single repository (GitHub Copilot or CodeRabbit may suffice)
Compliance reporting is your only concern (SonarQube viable)
You only need dependency security (Snyk Code works)
Implementation Blueprint: Rolling Out Without Breaking Developer Trust
Phase 1: Observe-Only Mode (Weeks 1-2)
Deploy in shadow mode where it analyzes every PR but posts findings to a private Slack channel. Build your baseline:
Track:
False positive rate by rule category (aim for <5% before enforcement)
Time-to-feedback latency (target <2 minutes for 80% of PRs)
Issue distribution across teams
Override frequency patterns
Phase 2: Rule Calibration (Weeks 3-4)
Define your noise budget, maximum automated comments per PR before developers tune out. For most teams: 3-5 actionable items per PR.
Calibration steps:
Start with high-signal rules: security vulnerabilities, exposed secrets, breaking API changes
Tune severity thresholds: P0/P1 to PR comments, P2/P3 to weekly digests
Suppress known patterns: generated code, vendored dependencies, test fixtures
Enable team-specific overrides while enforcing security/compliance universally
Phase 3: Phased Enforcement (Weeks 5-8)
Roll out incrementally, starting with volunteer teams:
Week 5-6: Pilot team (10-15 developers)
Enable blocking checks for security and compliance only
Senior engineers retain override authority
Daily standups review false positives
Week 7-8: Expand to 3-5 additional teams
Add code quality checks
Publish team-level dashboards showing savings
Document override patterns to refine rules
Phase 4: Auto-Fixes with Guardrails (Week 9+)
Auto-fix tiers:
Tier 1 (auto-apply): Formatting, import sorting, deprecated API migrations
Tier 2 (one-click): Security patches, dependency updates—require approval
Tier 3 (suggest only): Architectural refactors—provide diff preview, never auto-apply
Phase 5: Merge Queue Integration (Week 10+)
Performance SLAs:
<2 minutes: Time-to-feedback for 90% of PRs under 500 LOC
<5 minutes: Full analysis including cross-repo dependency checks
<30 seconds: Re-analysis after developer pushes fixes
Phase 6: Ongoing Governance
Weekly metrics dashboard:
Review time reduction by team (target: 65% decrease)
False positive rate trending (maintain <5%)
Override frequency and justification patterns
DORA metrics impact
Success indicator: Developers request automation for their repos rather than resisting it.
ROI Model: Justifying the Investment
Build your business case around four measurable improvements:
1. Review Time Savings
Annual Savings = (20 engineers × 12 hours/week × 52)
× 0.65 × $125/hour
= $1,014,000
2. Incident Cost Reduction
Annual Avoidance = (8 incidents/month × 12)
× 0.40 × $45,000
= $1,728,000
3. CI/CD Cost Savings
Annual Savings = (2.4M minutes/month × 12)
× 0.25 × $0.008
= $57,600
4. Audit Preparation
Annual Savings = (120 hours/quarter × 4)
× 0.60 × $110/hour
= $31,680
Total ROI Example:
Total Value = $1,014,000 + $1,728,000 + $57,600 + $31,680 - $150,000
= $2,681,280
ROI = 1,687%
For 100+ developer teams, CodeAnt typically delivers 10-15x ROI in year one.
The Verdict: Scale Demands Architectural Intelligence
At 100+ developers, the winning pull request automation platform reduces review latency and noise while catching architectural risks that file-level tools miss. GitHub Copilot and similar assistants excel at line-level suggestions but can't trace cross-service dependencies or enforce governance policies.
Run This 1–2 Week Benchmark:
Track false positive rate on 20-30 real PRs
Test cross-repository intelligence on PRs touching shared libraries
Verify custom rules and security policies actually block violations
Measure time-to-first-review and time-to-merge
Confirm post-merge monitoring of drift and DORA metrics
What to Bring:
3-5 representative repositories
Current code quality policies and security requirements
Target DORA metrics
List of recurring PR review pain points
If you're managing multi-repo architectures, need auditability for compliance, and want continuous code health monitoring that scales with your team, CodeAnt AI delivers the architectural context and sub-5% false positive rate that elite engineering orgs require.Start your 14-day free trial with your actual codebase, no sandbox demos, just real PRs and measurable impact on review speed and code quality.
FAQs
How do you measure and minimize false positives?
How does it handle monorepos and multi-repo architectures?
Can we restrict data egress and maintain compliance?
Will it spam developers with noise?
Can it auto-apply fixes safely?













