AI Code Review
Limitations of AI Code Review and How to Achieve Real Code Health

Sonali Sood

Founding GTM, CodeAnt AI
You know that feeling when you open a pull request and see 37 AI-generated comments about variable names and tiny refactors… yet the one architectural landmine still slips through? Your team fixes lint, merges confidently, ships, and two days later you're untangling the same regression pattern you've seen three times this quarter.
The AI code review bot “approved.” The CI pipeline passed. Reviewers dropped a few nit comments.
And still, your codebase feels like it's slowly fraying at the edges. This isn’t a tooling problem. It’s a model problem.
Most AI code review tools are built to review diffs. They do what static code analysis tools always did, just louder and faster, (you can check out “What Is Static Code Analysis”)
They help you review code, not improve code health.
But code reviews don’t fix codebases. Code health solution does.
In this article you’ll learn:
What AI code review actually solves, and where it fails
Why comment-heavy PRs still produce bugs and tech debt
The difference between code review and code health
Guardrails and developer productivity metrics that prevent rework
How to implement good code review practices, policy-as-code, PR-size limits, and org-specific quality gates
How to shift your team from noise → outcomes with a code health system
You can check out these interesting reads: code review best practices and the modern code review process
Let’s dig in.
What AI Code Review Actually Does (And Why It Stops Short)
Today’s AI-assisted code review typically lives at the pull-request layer. A model scans the diff, applies static-analysis rules, pattern recognition, and best-practice heuristics, and leaves comments.
That absolutely has value, it automates routine checks, reduces reviewer fatigue, and catches surface-level issues earlier.
But the field is still maturing, and teams are feeling the gap between promise and practice.
A study by Metr ("Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity”) round that experienced open-source contributors using early-2025 AI tools became 19% slower, not because AI made them worse, but because the cost of verifying suggestions outweighed the time saved when context was missing. Another industry perspective puts it simply: AI review is “a contributor to code quality, not a replacement for human review.”
This isn’t failure, but a sign of where the technology sits today.
AI does a great job answering what changed.
Where it struggles, and where teams feel friction, is answering:
Why this change matters in our system
Whether it aligns with our architectural or security intent
How to prevent this class of issue next time
Which risks connect to developer, product, or business outcomes
Put simply, most AI reviews generate comments, they spot issues; they don’t yet build systems.
And that’s the opportunity space we’re about to explore.
Why Code Review Comments Alone Won’t Improve Code Health
Even with advanced AI code review tools, most engineering teams still hit the same wall:
Plenty of comments
Minimal actual improvement
Longer PR threads, slow merges, and frustrated developers
Bots nitpick formatting, humans tune them out, and the codebase quietly accumulates inconsistency, tech debt, and rework.
Why?
Because comments, human or AI, react to code. They don’t shape developer behavior, improve decision-making, or enforce standards over time. Real quality doesn’t come from more annotations. It comes from guardrails, expectations, and feedback loops that shape how code is written, reviewed, and merged, consistently.
And this is exactly where AI code review falls short without a true code health model:
No Org-specific Quality Standards
At many companies, “good code” means different things depending on architecture, domain, team skill, and business risk. Telling all devs “fix this pattern” doesn’t capture your standard of readability, modularity, scalability, test coverage or refactor thresholds. An AI bot may flag “complex method” but not know how much complexity is acceptable in your domain. Without org-specific definition of quality, you get noise, lots of suggestions, limited effect.
For example, one review by Amena Amro, Manar H. Alalfi mentioned that AI assistants generate “low-severity issues” while missing deep architectural flaws.
Source: https://arxiv.org/abs/2509.13650?
No Policy or Gates
You can review code after it’s submitted, but if there’s no enforcement in your code review process (e.g., rules that block merge if coverage < 80%, PR size > 400 lines, complexity > “X”), then suggestions from AI remain at the mercy of human discretion. That means regressions slip through, review fatigue grows, and your review becomes reactive, not preventive.
Research on metrics by AWS emphasises that measuring “review time to merge” and “reviewer load” helps you spot inefficiencies.
No System-Level Visibility
Comments on individual PRs solve single-change issues. But a codebase is a living system. Technical debt accrues, modules diverge, review bottlenecks grow, review quality declines as load increases.
A 2025 article on DevTools Academy notes that reviewers lose effectiveness after ~80-100 lines of change, and manual reviews at scale become unsustainable.
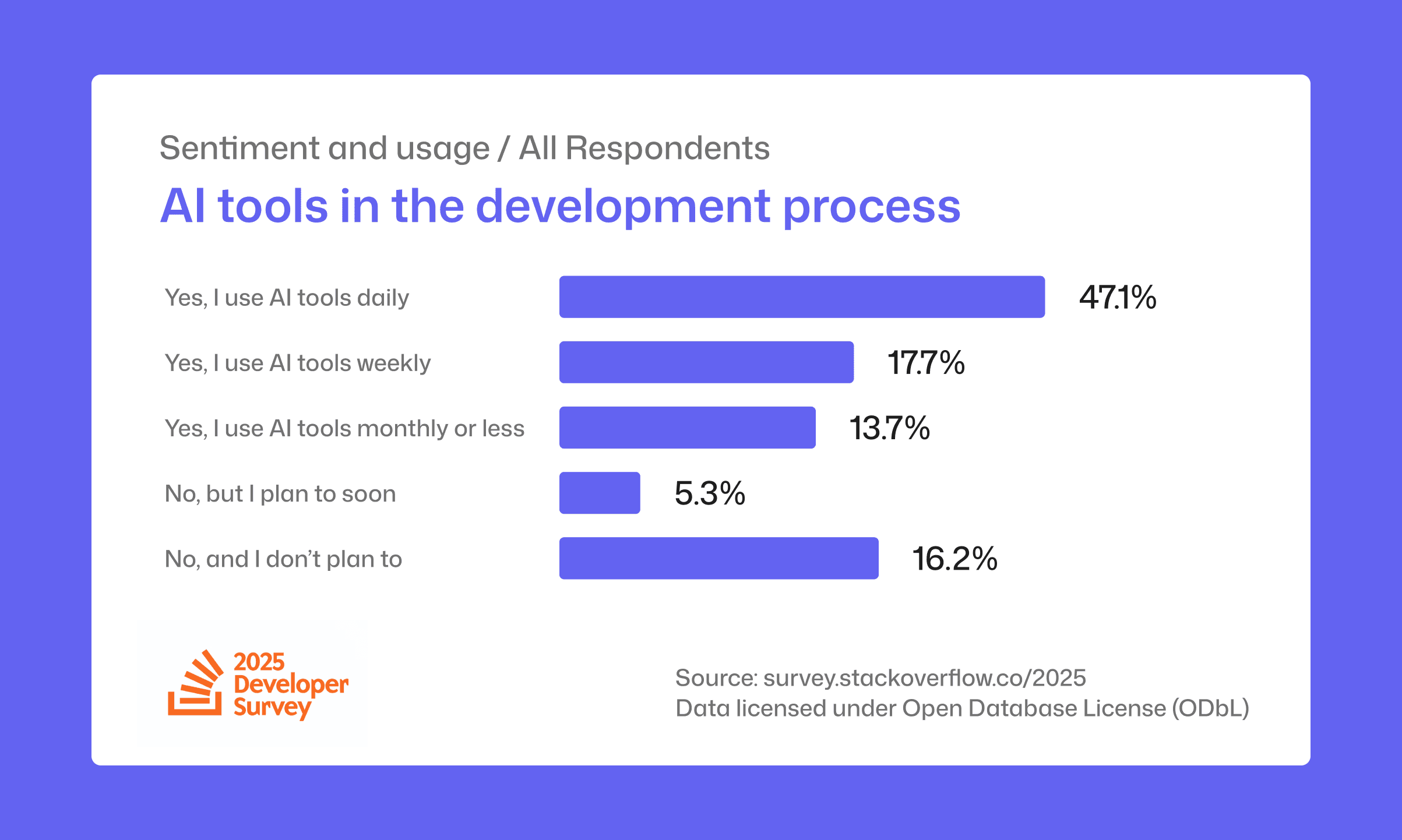
If you don’t monitor metrics across PRs, modules, teams, you’ll never see the drift until it’s too late.
In short: AI code review helps you react to issues, it rarely helps you prevent the underlying problems. That’s why many teams are stuck with “lots of comments, same defects.”
Code Health = What Actually Fixes Your Codebase
TL;DR:
Most code review tools as mentioned earlier comment on a diff, useful, but that’s where the help often stops. Code health is different… it defines your organization’s quality standards, enforces them at PR-time, and measures results so developer productivity, merge speed, and code quality trend the right way. That’s how teams move beyond code review limitations and actually fix the codebase.
Org-Defined Quality Rules, Not Generic Comments
What devs need: clear, org-specific rules for “good code,” encoded directly into the code review process, not endless, generic suggestions. Think policy-as-code thresholds like:
PR size guardrails (e.g., <300 LOC)
Cyclomatic complexity ceilings per module
Duplication budgets (e.g., <2%)
Unit test coverage floors (e.g., ≥85%)
Refactor budgets and documentation checks
These rules prevent code drift and PR bloat. When maintainability lives in policy instead of opinion, quality stops relying on vibes, and defect rates fall. That’s how elite teams scale standards reliably across squads.
And this is exactly where CodeAnt.ai fits in, operationalizing those standards. It lets teams define and enforce org-specific quality thresholds while running static analysis and security scanning on every PR. CodeAnt flags complexity, duplication, and code-level bugs across 30+ languages directly inside pull requests, and offers one-click fixes so reviewers stay focused on design and risk, not syntax cleanup.
PR-Time Guardrails Beat After-Merge Cleanup
If your “quality control” happens after merge, you’re paying for rework. Real code health pushes enforcement left so risky changes never land:
Block merges when thresholds fail (PR size too large, coverage too low, complexity out of bounds).
Require justification (e.g., architectural exceptions) when rules are exceeded.
Automate trivial fixes (formatting, minor smells) so code reviewers can review code that matters.
We at CodeAnt.ai highly recommend measuring and improving “Review Time to Merge (RTTM)” and using automation to cut review latency, i.e., speed comes from guardrails and fast feedback, not more comments. Our AI code review tool runs in-PR and integrates with CI/CD, surfacing actionable issues and pass/fail checks aligned to your rules.
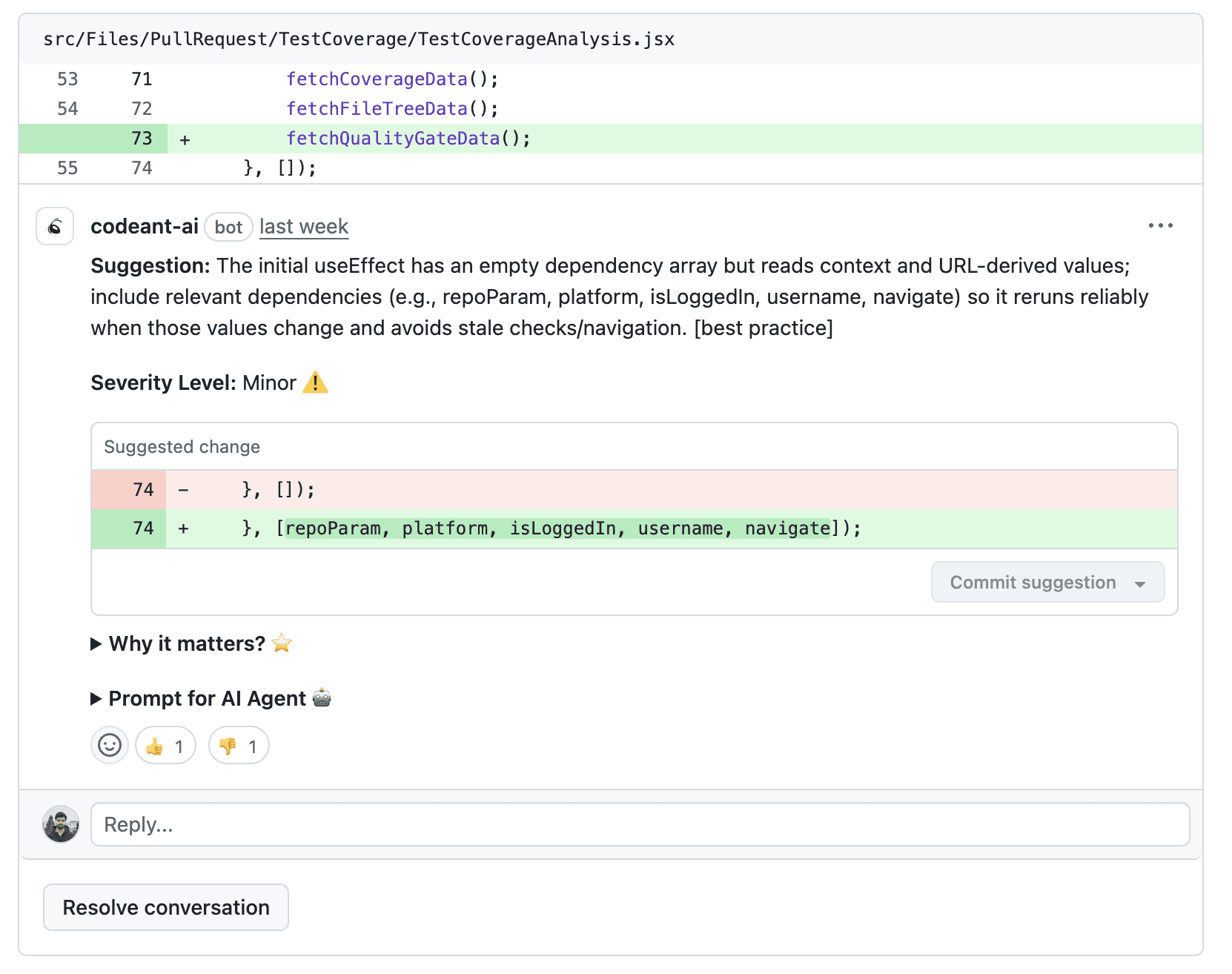
Elite teams like Bajaj Finserv report dramatic cuts in manual review time when bots handle the repeated findings and reviewers handle the judgment calls.
Check out the case study here: Bajaj Finserv Health’s 300+ Developers Now Review Code in Seconds
Metrics That Drive Behavior (and Developer Productivity)
Code health isn’t a feeling, it’s measured. Teams move from “we added another tool” to “we changed how we ship” by tracking metrics like:
Time to First Review (TFR) and Review Time to Merge (RTTM)
PR size
Review depth (meaningful findings vs. nit density)
Defect escape rate (post-merge bugs)
Developer productivity metrics (merge throughput, reviewer load)

That said, always look into the RTTM and related indicators for a healthy code review process. This is how correlating review metrics with delivery outcomes improves both speed and stability, what your leadership actually cares about.
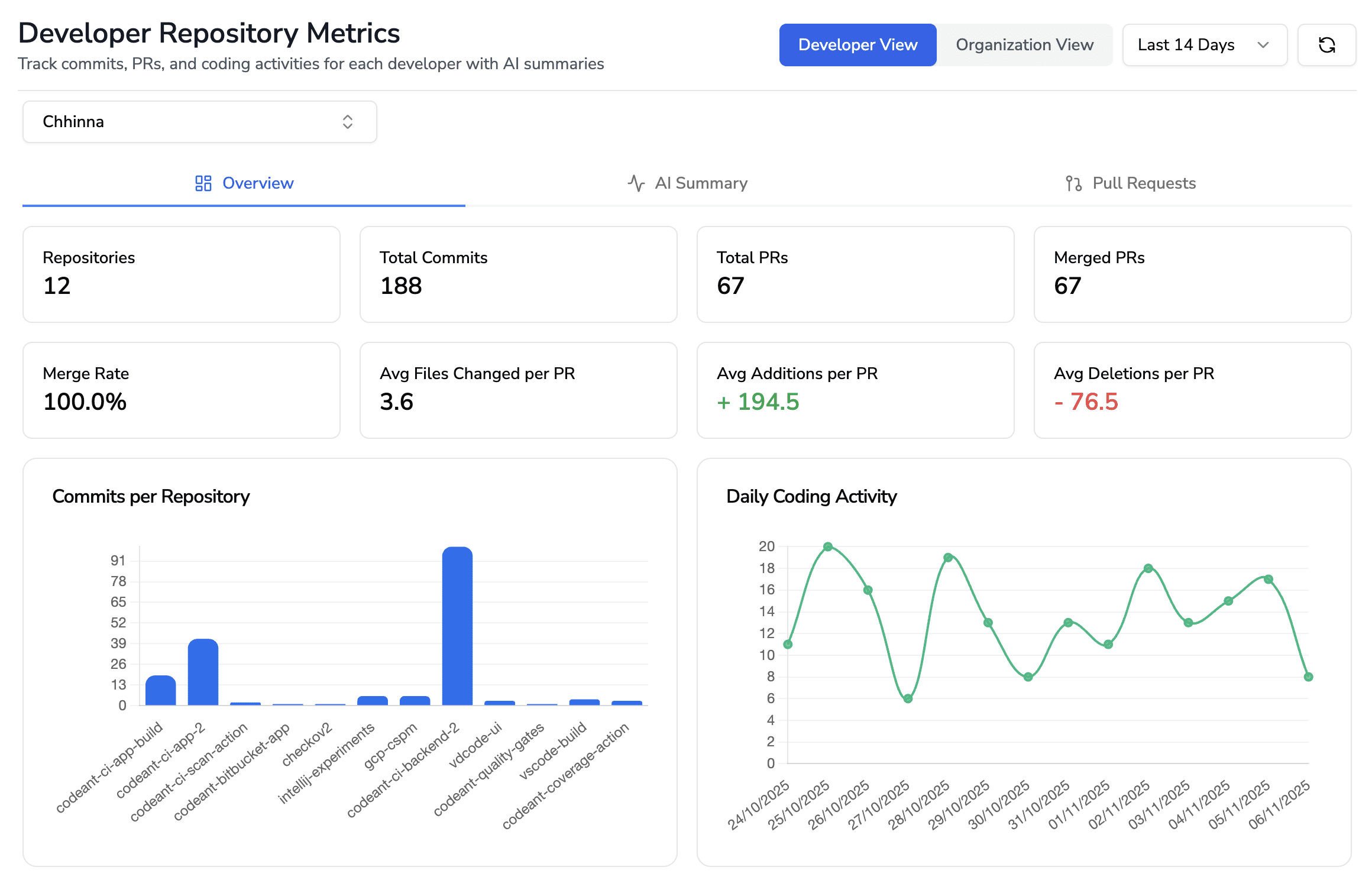
If you check out our developer productivity dashboard, it expose developer-level and team-level insights across PRs (e.g., review velocity, PR sizes, change types), not just a pile of alerts. This elevates the conversation from “how many issues did we flag” to “how did our code reviews improve software developer productivity and release predictability this sprint/quarter?”
Optional but BONUS: Provenance & Integrity (Keep It Simple, Developer-First)
Security standards (secrets detection, SAST, dependency checks) are broadly universal…keep them baseline and low-friction. If your org tracks build provenance (SBOM, SLSA), treat it as a gate, not a separate ritual: it’s part of “healthy PRs merge; risky PRs don’t.” SLSA levels clarify how provenance attestation helps ensure you’re reviewing trusted artifacts (useful shorthand for devs who just want to know why it blocks).
So, when you work on Codent.ai, instead of juggling multiple bots, scanning tools, and dashboards, CodeAnt.ai brings quality gates, AI-powered reviews, security checks, and productivity insights into the same PR surface, one unified “ship or fix” decision flow.
Fewer alerts. Fewer tabs. Less latency.
Faster merges. Higher confidence.
Real code health scales culture into automation, and frees reviewers to focus on architecture and risk, not re-explaining style guidelines for the 100th time.
What Engineering Teams Actually Need (Not Just More Comments)
If you’re tired of chasing PR comments and still seeing the same defects, your team needs:
A shared definition of good code (tailored to your domain)
Guardrails built into the review process (PR size threshold, complexity ceilings, coverage rules)
Automation for trivial tasks so reviewers spend time on architecture and logic
Metrics dashboards that track review throughput, review latency, defect escape rate, team load
Cultural shift: developers and reviewers aligned around outcomes (healthy codebase, high delivery velocity), not activity (25 comments per PR)
This is not just about tooling, it’s about aligning your process, metrics, and culture. The article by BrowserStack “Top 30+ Software Development Metrics to Track in 2025” backs this notion: meaningful metrics + measurement improves both delivery speed and developer satisfaction.
How to Move From AI Comments → Code Health
Here’s a practical roadmap for you:
Define your quality standards
Collect data on your current codebase: modules with most bugs, areas with high tech debt. Set specific, measurable rules (e.g., complexity, duplication, test coverage).
Add PR guardrails
In your review workflow, enforce thresholds (PR size < 300 lines; coverage rule; duplication cap). Use automation where possible to enforce or block.
Automate trivial fixes
Use your AI code review tool to auto-fix lint/style issues, suggest improvements. But keep human reviewers for logic, architecture, and domain context.
Instrument metrics
Set dashboards for metrics like Time to First Review (TFR), Time to Merge (TTM), PR size trends, review backlog, review comments per PR, defect escape rate. Use sources like AWS DevOps metrics guidance.
Continuous feedback loop
Periodically review your rules and metrics. If modules drift or new tech stacks emerge, update your quality standard. Encourage cross-team review insights.
This is a continuous process, not a one-time setup. The best code health frameworks evolve with your codebase and team. And CodeAnt.ai is the one you can trust blind folded, becauseee…
How Impact Analytics Reviewed 1.2M+ Lines of Code with CodeAnt AI
How Nivoda Reviews 500,000+ Lines of Code Every Day With Our Code Health Platform
… is all that you need to read to justify the claim.
CodeAnt AI = Code Health, Not Just AI Code Review Tool
In this landscape of noisy tools and infrequent outcomes, it’s important to pick a platform designed for code health, not just comment spam. That’s where CodeAnt AI stands out:
Context-aware reviews: understands your repo, history, team conventions, and suggests actionable improvements beyond style.
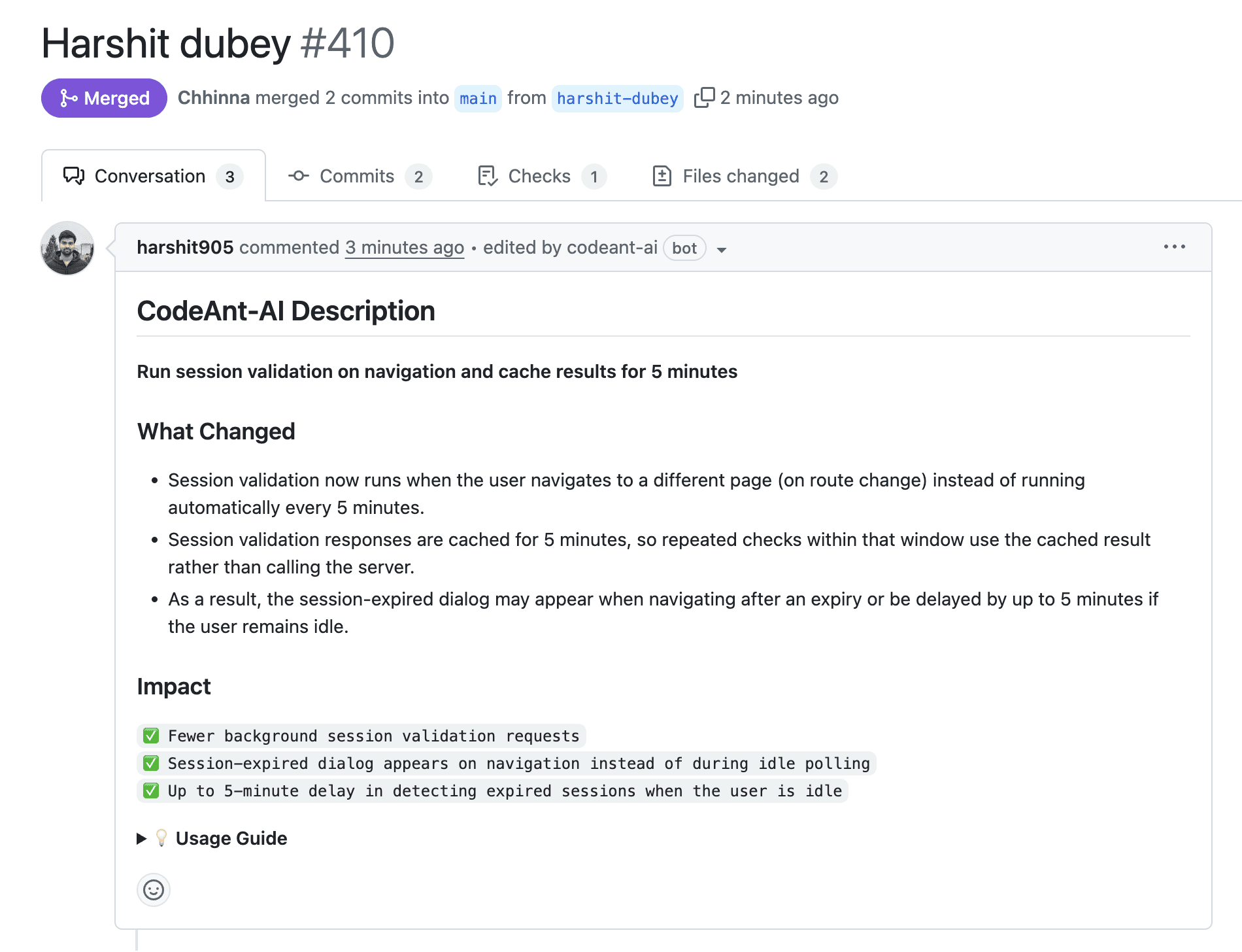
Integrated guardrails: supports org-specific quality rules encoded into PR workflows, enabling enforcement at merge time.
Developer metrics & analytics: surfaces reviewer load, review throughput, PR size trends, defect escape patterns, helping leadership link review performance to productivity.
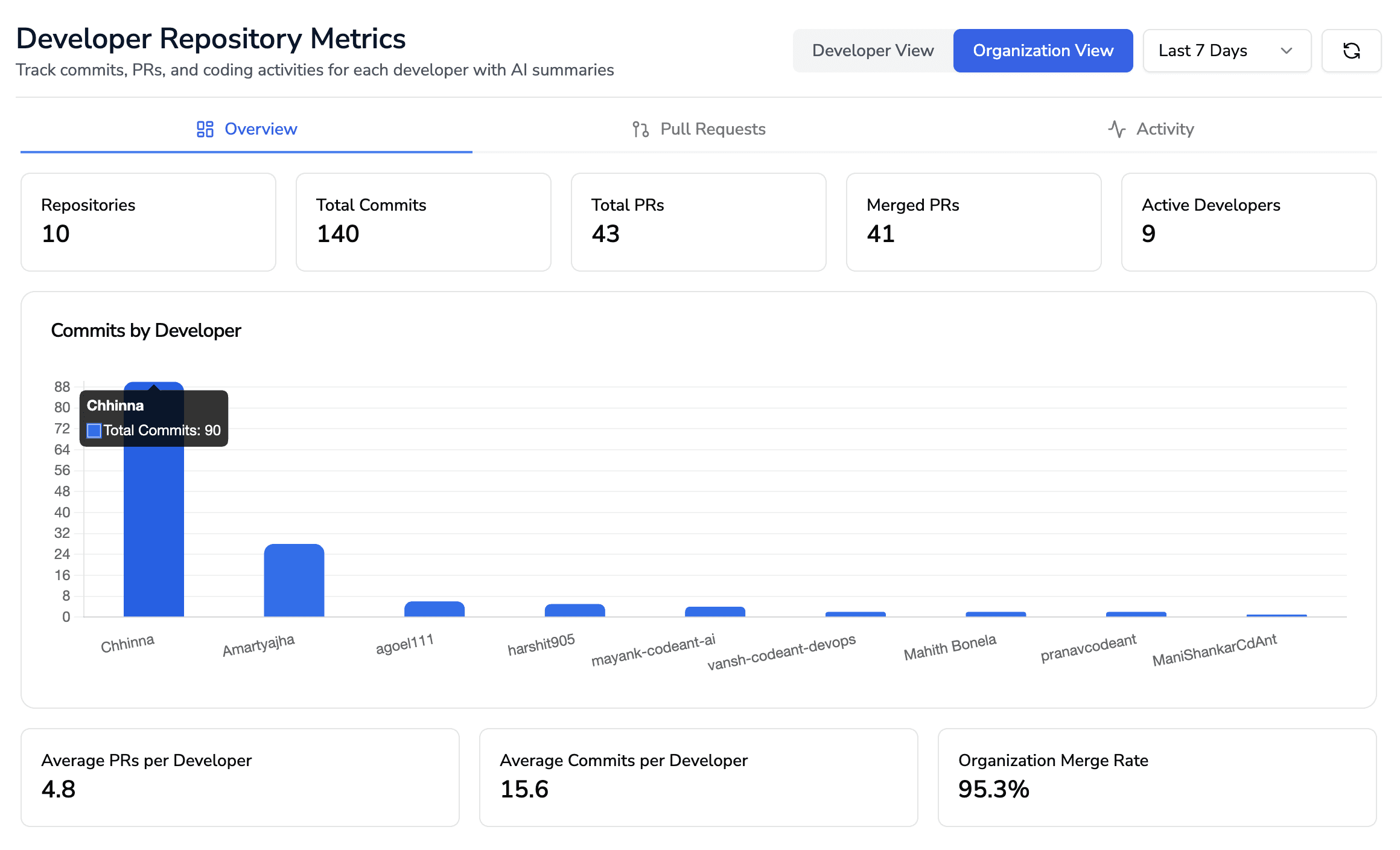
Single platform for quality and productivity: not just “run static analysis”, but “drive developer productivity, enforce good code review practices, and scale review velocity”.
Engineered for teams with 100+ developers: built to handle multi-repo, multi-stack environments, and support engineering leadership visibility, not just local teams.
When you choose CodeAnt AI, you’re choosing a path from AI code review comments to meaningful code health outcomes:
fewer defects
faster merges
higher developer productivity
sustainable healthy codebase
Conclusion: Let’s Improve Your Code Health Today!
Engineering teams don’t struggle because they lack feedback. They struggle when feedback isn’t tied to rules, repeatability, and accountability. AI code review tools are great at telling you what changed. But high-performing engineering orgs win because they define how change is allowed to happen. That’s the difference between commenting on code
and governing the health of a codebase over time.
The future isn’t “more AI PR comments.” The future is codified standards, predictable velocity, and real-time guardrails that help engineers ship with confidence, not corrections after the fact.
Code health isn’t a feature. It’s an engineering operating system.
It’s time to upgrade from AI code review to AI code health platform todayy!!
FAQs
What is the difference between AI code review and code health?
Why won’t AI code review alone fix code quality issues in a large codebase?
How do you perform a good code review that improves developer productivity?
What metrics matter most for code reviews and engineering productivity?
How do I enforce good code review practices across engineering teams?













