Code Security
What Are Steps of Reproduction in SAST? (And Why They Matter)

Sonali Sood

Founding GTM, CodeAnt AI
Most SAST tools tell you something might be wrong. They flag a line of code, attach a CWE identifier, assign a severity score, and leave the developer to figure out whether the finding is real and how to fix it. The result is predictable: developers spend more time investigating findings than fixing them, and many findings get ignored entirely.
Steps of Reproduction take a fundamentally different approach. Instead of a vague alert, the developer receives the complete chain of evidence, the exact entry point, each step of the taint flow, the vulnerable sink, and a concrete exploitation scenario that proves the vulnerability is triggerable. This is the difference between “possible SQL injection on line 47” and “here is the specific request parameter, the exact code path it follows through three functions, and the payload that exploits it.”
This page explains what Steps of Reproduction are, how they work at a technical level, and why they represent a shift in how SAST findings are consumed by development teams. For a broader understanding of how SAST detection works, see “What is SAST?”
What Are Steps of Reproduction in SAST?
Steps of Reproduction in SAST are the exact sequence of conditions, inputs, and code paths needed to trigger a flagged vulnerability, provided alongside every finding so developers can validate the issue in seconds rather than hours.
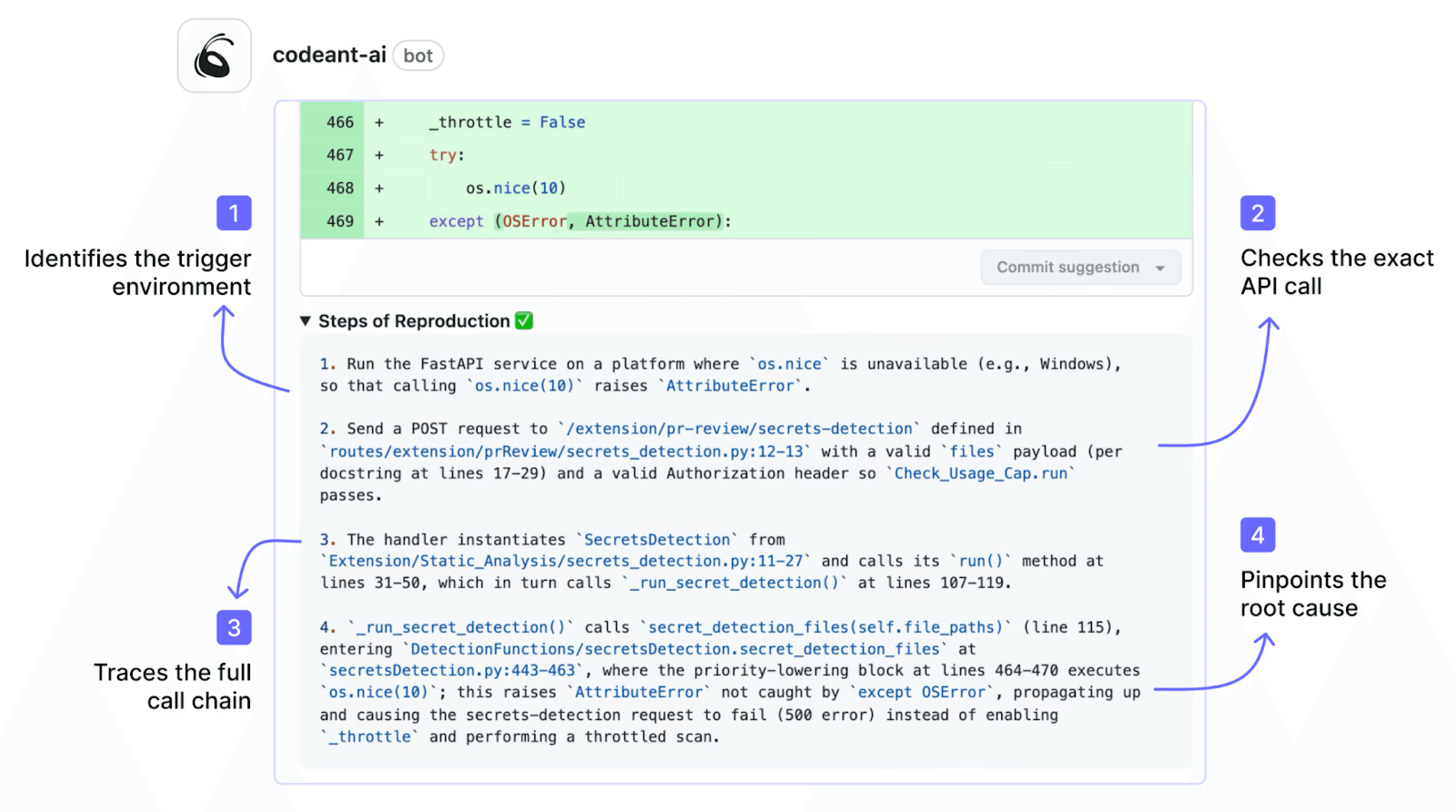
A Steps of Reproduction output includes four components:
the entry point where untrusted data enters the application (such as a request parameter or file upload)
the taint flow showing how that data propagates through functions and variables without sanitization
the vulnerable sink where the unsanitized data reaches a security-sensitive operation (such as a database query or command execution)
a concrete exploitation scenario demonstrating how an attacker would trigger the vulnerability in practice
Unlike a traditional SAST alert, which typically provides a line number, a CWE classification, and a severity rating, Steps of Reproduction present a falsifiable claim. The developer can follow the reproduction sequence, verify whether the conditions hold in their codebase, and make a confident decision to fix, accept, or suppress the finding. This transforms SAST from a probabilistic warning system into an evidence-based validation workflow.
Why Steps of Reproduction Change How Developers Trust SAST
The Alert Fatigue Problem
Alert fatigue is the single largest adoption barrier for SAST tools. When a scanner generates hundreds of findings and a significant percentage are false positives, developers learn to distrust the tool. They stop reading alerts, delay triage, or push back on security mandates entirely. The problem is not that SAST tools detect too much, it is that they do not provide enough evidence for developers to act on what they detect.
A 2023 Snyk developer security survey found that most developers consider vulnerability alerts unhelpful when they lack context about exploitability. The OWASP Vulnerability Disclosure guidelines emphasize that useful vulnerability reports must include sufficient detail for the recipient to reproduce and validate the issue, the same principle applies to automated SAST findings delivered to developers.
Traditional SAST alerts fail this standard. A finding that says “CWE-89: SQL Injection, line 47 - Severity: High” tells the developer what might be wrong but not whether it actually is. The developer must then manually trace the data flow, determine if the input is truly user-controlled, check for upstream sanitization, and assess whether the code path is reachable. This investigation process takes 15–60 minutes per finding, and the conclusion is often “not exploitable” time wasted that erodes trust in the tool.
For a deeper analysis of why SAST tools produce false positives and techniques to reduce them, see How to Reduce SAST False Positives.
From “Maybe Vulnerable” to “Here’s Exactly How to Trigger It”
Steps of Reproduction invert the developer’s task. Instead of starting from a vague alert and working backward to determine if a vulnerability is real, the developer starts from a complete exploitation scenario and works forward to determine if the conditions still hold.
This changes the cognitive load entirely. Reviewing evidence is faster than conducting an investigation. A developer who receives a finding with Steps of Reproduction does not need to trace data flows, the tool has already done that. They do not need to assess reachability, the tool has already mapped the execution path. They do not need to construct a test case, the tool has already provided one.
The result is measurable: findings with Steps of Reproduction are resolved faster, suppressed less often, and generate fewer “is this real?” back-and-forth conversations between developers and security teams. When developers trust the evidence, they fix the vulnerability. When they do not, they rationally ignore it, and the tool loses adoption.
This evidence quality is especially critical for findings in AI-generated code, where developers are predisposed to trust their AI coding assistant over the scanner. A vague alert gets dismissed; a complete exploit path does not. See securing AI-generated code with SAST for a deeper look at this dynamic.
How Steps of Reproduction Work
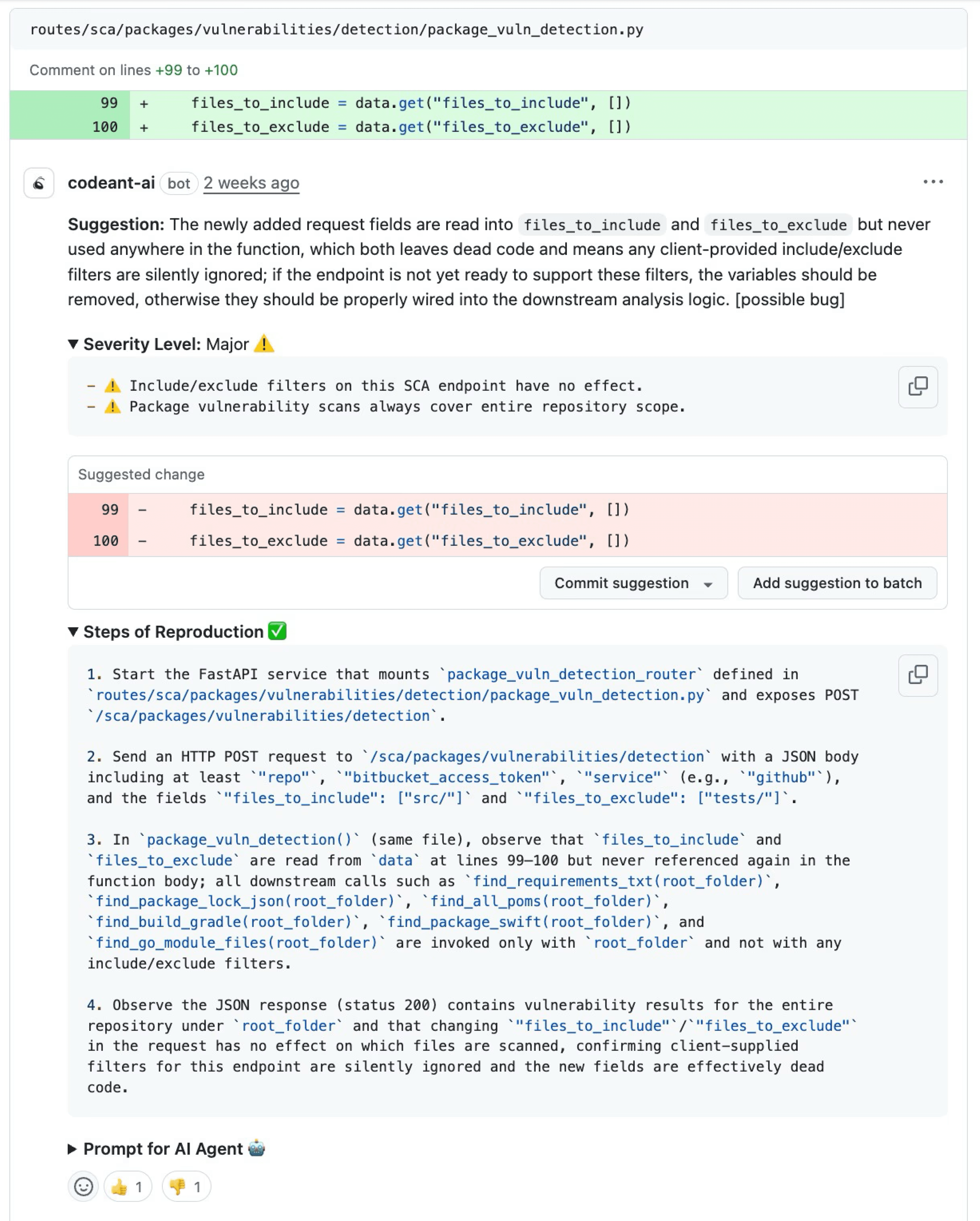
Steps of Reproduction are generated through a four-stage analysis pipeline that goes beyond traditional SAST pattern matching. Each stage adds a layer of evidence to the final output.
Step 1: Vulnerability Detection
The SAST engine scans the codebase and identifies a potential vulnerability using a combination of pattern matching, taint analysis, and (in AI-native tools) semantic reasoning about code behavior. At this stage, the finding is a candidate, the scanner has detected a code pattern that could be vulnerable.
In traditional SAST, this is where the process ends: the candidate finding is reported directly to the developer. With Steps of Reproduction, detection is just the beginning.
Step 2: Exploit Path Analysis
The engine traces the complete data flow from source to sink. For a SQL injection candidate, this means identifying the specific entry point (which request parameter, which API endpoint, which file input), following the data through every function call, variable assignment, and conditional branch, and verifying that the data reaches a security-sensitive operation (database query, command execution, file system access) without adequate sanitization at any point in the chain.
This stage filters candidates that are technically flaggable but not actually exploitable, cases where the data is sanitized at an intermediate step, where the code path is unreachable, or where the input is not actually user-controlled. These candidates are suppressed rather than reported, directly reducing false positive noise.
Step 3: Reproduction Sequence Generation
For candidates that survive exploit path analysis, the engine generates a concrete reproduction sequence: the specific input that triggers the vulnerability, the exact code path it follows, and the outcome an attacker would achieve. This is not a generic description of the vulnerability class, it is a specific, testable scenario tied to the developer’s actual code.
For example, rather than “user input reaches database query without sanitization,” the reproduction sequence would specify that a GET request to /api/search with the query parameter q set to ' OR '1'='1 flows through get_search_results() at line 23, into build_query() at line 45 (where it is concatenated into a raw SQL string), and reaches cursor.execute() at line 52, resulting in a query that returns all database rows instead of filtered results.
Step 4: Developer Review with Evidence
The complete finding, detection result, exploit path, and reproduction sequence, is delivered to the developer as an inline PR comment (not a dashboard notification). The developer sees the vulnerability classification, the full taint flow, the reproduction steps, and an AI-generated fix suggestion, all within their pull request workflow.
The developer’s task is now review, not investigation: does this exploit path hold? Is this entry point exposed? Is the fix suggestion correct? This review typically takes 1–3 minutes rather than the 15–60 minutes required to investigate a traditional SAST alert.
Steps of Reproduction vs. Traditional SAST Alerts: A Side-by-Side
The difference between a traditional SAST alert and a finding with Steps of Reproduction is best illustrated with a concrete example. Consider a server-side request forgery (SSRF) vulnerability where user input controls a URL that the application fetches internally.

Traditional SAST Alert:
⚠️ CWE-918: Server-Side Request Forgery (SSRF) · Severity: High · File: services/proxy.py · Line: 34
User-supplied input may be used in a server-side HTTP request without validation. Review the data flow and ensure the URL is validated against an allowlist.
This alert correctly identifies the vulnerability class and location. But the developer must now answer several questions independently: which user input? Through what code path? Is the input actually user-controlled or derived from a trusted source? Are there validation checks upstream? How would an attacker actually exploit this? Each question requires code investigation, and the answers are not always obvious.
Finding with Steps of Reproduction:
🔴 CWE-918: Server-Side Request Forgery (SSRF) · Severity: High · EPSS: 0.04%
Entry point: POST /api/webhooks/preview — the callback_url field in the JSON request body is user-controlled.
Taint flow:
callback_urlis extracted from the request body inwebhook_handler()atroutes/webhooks.py:18Passed as the
urlparameter tofetch_preview()atservices/proxy.py:27No URL validation or allowlist check is performed between extraction and use
urlis passed directly torequests.get(url)atservices/proxy.py:34
Reproduction: Send a POST request to /api/webhooks/preview with {"callback_url": "<http://169.254.169.254/latest/meta-data/>"} to access AWS instance metadata from the server’s network context.
Suggested fix: Validate callback_url against an allowlist of permitted domains before passing to fetch_preview(). [Apply fix →]
The second finding is falsifiable. The developer can verify each step of the taint flow. They can confirm whether callback_url is truly user-controlled, whether validation exists elsewhere, and whether the reproduction scenario is realistic. If it is, they apply the fix. If it is not (perhaps there is a middleware allowlist not captured by the scanner), they suppress the finding with confidence, and that suppression does not erode trust in the tool because the tool showed its reasoning.
Which SAST Tools Support Steps of Reproduction?
Steps of Reproduction are not a standard feature across the SAST market. The table below shows the finding evidence quality for each major tool. For the full feature comparison, see which SAST tools offer Steps of Reproduction in the complete comparison.
Tool | Finding Evidence | Steps of Reproduction | Inline PR Fix Suggestions |
CodeAnt AI | Full exploit attack path + reproduction sequence + EPSS score | Yes | Yes (AI-generated one-click fix) |
Snyk Code | Data flow visualization + CWE reference | No | Yes (AI-assisted) |
Checkmarx One | Attack vector + data flow graph | No | Partial (remediation guidance) |
SonarQube | CWE reference + code location | No | No (description only) |
Semgrep | Rule match + code pattern | No | Partial (Semgrep Assistant) |
Veracode | CWE reference + flaw details | No | Partial (remediation guidance) |
GitHub CodeQL | Data flow paths + CWE | No | Yes (Copilot Autofix) |
GitLab SAST | CWE reference + code location | No | No |
Fortify | Data flow graph + rule reference | No | No |
Some tools provide partial evidence — Checkmarx and Fortify show data flow graphs, Snyk Code visualizes taint paths, and GitHub CodeQL can trace data flow through its query language. But none generate the complete reproduction sequence: the specific input, the exact exploitation scenario, and the concrete outcome that Steps of Reproduction provide. The distinction is between showing the developer where a vulnerability might exist (data flow graph) and proving to the developer that a vulnerability is exploitable (reproduction steps).
This is why the CWE documentation — the industry standard for classifying software weaknesses — distinguishes between weakness identification and weakness validation. Steps of Reproduction bridge that gap by providing the validation evidence inline with the identification, so developers do not have to perform validation manually.
How CodeAnt AI Delivers Steps of Reproduction
CodeAnt AI generates Steps of Reproduction for every finding, across every supported language and framework. This is not an optional add-on or a premium feature, it is the default output for every vulnerability detected by the platform.
The architecture that enables this is AI-native detection, integrated across the complete developer workflow, from IDE (VS Code, JetBrains, Cursor, Windsurf) to PR to CI/CD pipeline. Because CodeAnt AI’s scanning engine reasons about code semantically (rather than matching patterns against a rule database), it can trace exploit paths through complex multi-function, multi-file code flows, determine whether inputs are genuinely user-controlled, and generate reproduction scenarios that are specific to the developer’s actual code, not generic descriptions of the vulnerability class.
Steps of Reproduction appear at every stage of the workflow where CodeAnt AI operates: in IDE scanning (so developers see evidence before opening a PR), in PR-native inline comments (where findings are most actionable), and in the SecOps dashboard (where security teams review findings with the full audit trail for compliance reporting via Jira and Azure Boards).
In practice, this means developers reviewing CodeAnt AI findings in their pull requests spend their time deciding how to fix a vulnerability, not whether the vulnerability is real. Commvault’s 800-developer team experienced this directly: across 17,000+ merge requests, developers resolved findings faster because each finding came with the evidence needed to act immediately, contributing to a reduction in time-to-first-review-comment from 3.5 days to under one minute (full case study).
The Future of Evidence-Based SAST
Traditional SAST tools identify weaknesses. Steps of Reproduction prove exploitability.
That difference changes everything. Developers stop investigating vague alerts and start fixing validated vulnerabilities. Security teams stop fighting alert fatigue and start building trust. Fix rates increase. False positives decrease. Adoption improves.
If your current SAST tool cannot show the full exploit path, entry point, vulnerable sink, and concrete attack scenario, you are still running an investigation workflow instead of a validation workflow.
See the difference yourself. Run an AI-native SAST scan with Steps of Reproduction on your next pull request and compare it to your current tool.
Start a free 14-day trial or book a short demo to see evidence-based SAST in action.
FAQs
What are Steps of Reproduction in SAST?
How do Steps of Reproduction reduce false positives?
Do most SAST tools support Steps of Reproduction?
Are Steps of Reproduction the same as a data flow graph?
Why do Steps of Reproduction improve developer adoption of SAST?













