Code Security
Reduce SAST False Positives: 5 Root Causes and 4 Proven Fixes

Sonali Sood

Founding GTM, CodeAnt AI
Every SAST vendor claims low false positive rates. Very few show evidence. Even fewer explain why false positives happen in the first place, which means teams keep buying tools that produce the same noise, then stop trusting the results, and eventually stop looking at findings entirely.
This guide is different. It explains the five technical root causes behind SAST false positives, walks through four techniques that actually reduce them (with proof, not just marketing), and gives you a checklist of questions to ask during a tool evaluation so you can separate real signal-to-noise improvements from vague vendor promises.
If you are new to SAST, read What is SAST? Static Application Security Testing Explained first for the technical foundation. If you are comparing tools, our 15-tool SAST comparison includes an AI Capabilities Matrix that shows which tools implement the techniques described below.
Why SAST False Positives Are a Bigger Problem Than Most Teams Admit
False positives in SAST occur when the scanner flags code as vulnerable that is actually safe, leading to alert fatigue and wasted developer time. The research confirms what practitioners already feel: a Ponemon Institute study found that application security teams spend over 25% of their time dealing with false positives, while NIST’s SATE (Static Analysis Tool Exposition) studies have consistently shown that rule-based SAST tools produce false positive rates ranging from 30% to over 70% depending on the tool and codebase.
Consider a mid-sized codebase producing 500 findings per scan.
At a 60% false positive rate, 300 findings are noise.
If each takes 10–30 minutes to investigate, that equals dozens, sometimes hundreds, of developer hours per quarter.
None of that effort improves security.
False positives are not just a productivity problem. They create a behavioral problem.
The Trust Collapse
When developers encounter repeated false alarms:
They stop investigating findings carefully.
They begin dismissing alerts by default.
The tool remains installed for compliance, but ignored in practice.
At that point, SAST becomes reporting software, not a security control.
This is why false positive reduction is the single most important factor in SAST effectiveness. A tool that surfaces fewer, validated findings improves security more than one that generates hundreds of theoretical risks no one trusts.
The 5 Root Causes of SAST False Positives
Understanding why false positives happen is the first step to choosing a tool that minimizes them. The five root causes below explain the technical gaps that allow a scanner to flag safe code as vulnerable.
1. Missing Runtime Context
SAST analyzes code without executing the application, so it cannot observe runtime behavior. A code path that looks vulnerable in the source may be unreachable in practice because of runtime guards, environment variables, or configuration.
For example, a SAST tool might flag a SQL query that concatenates a variable, but that variable is populated from a configuration file with a fixed set of allowed values, never from user input. Without runtime context, the scanner flags both genuinely tainted variables and safely constrained ones identically.
This is the most fundamental source of false positives and where the gap between rule-based and AI-native tools is widest. AI-native tools like CodeAnt AI reason about how variables are initialized and constrained, significantly reducing noise from this category.
2. Dead Code and Unreachable Paths
Codebases accumulate dead code over time, functions that are no longer called, feature flags that are permanently disabled, legacy modules that exist in the repository but are excluded from builds. Rule-based SAST tools scan every file in the repository regardless of whether the code is reachable from any execution path. Vulnerabilities in dead code are technically real (the pattern exists) but practically irrelevant (no attacker can reach it).
Reachability analysis addresses this by tracing execution paths from the application’s entry points to determine which code is actually accessible. A tool with reachability analysis might take 500 raw findings and filter them to 30 that exist in reachable code, an immediate 94% noise reduction on dead-code findings alone.
3. Framework-Specific Patterns the Scanner Doesn’t Understand
Modern web frameworks include built-in security protections that SAST tools often do not recognize. Django’s ORM automatically parameterizes queries. React’s JSX escapes output by default, preventing XSS. Spring Security’s CSRF protection handles token validation transparently.
A rule-based scanner does not understand these framework behaviors. It sees a user input flowing to a template render and flags XSS, even though React has already escaped the output. It sees a variable in a query and flags SQL injection, even though Django’s ORM is handling parameterization. These false positives repeat on every scan, generating the same incorrect findings over and over.
4. Custom Sanitizers the Tool Doesn’t Recognize
Many engineering teams build custom sanitization functions, input validation libraries, output encoding utilities, security wrappers. When a developer writes a sanitize_input() function that strips dangerous characters before the data reaches a sink, the code is secure. But unless the SAST tool recognizes sanitize_input() as a trusted sanitizer, it flags the data flow as vulnerable.
Rule-based tools address this with custom sanitizer mappings, whitelisting function signatures. This works but requires ongoing maintenance.
AI-native SAST takes a different approach: because the engine reasons about what code does rather than matching patterns, it can recognize sanitization behavior even without explicit registration. CodeAnt AI’s LLM-powered analysis understands the behavior of custom sanitizers without requiring teams to maintain a configuration file.
5. Over-Broad Rules Without Severity Calibration
Rule-based SAST tools ship with rule libraries optimized for recall (catching everything) at the expense of precision (only flagging what is real). A rule that flags every use of eval() makes sense in untrusted-input contexts but generates false positives in build scripts where eval() is used safely. A rule that flags every hardcoded string as a potential secret produces noise for configuration constants that are not sensitive.
Without severity calibration, adjusting rule thresholds based on the context in which a pattern appears, these over-broad rules generate a constant stream of low-value findings that dilute real issues.
4 Techniques That Actually Reduce False Positives
The five root causes above are not unsolvable. The SAST market has developed four techniques to address them, but they vary enormously in how effectively each tool implements them. This section explains what to look for.
Reachability Analysis
Reachability analysis determines whether a vulnerability in the codebase is actually accessible through the application’s execution paths, filtering out theoretical risks that cannot be exploited in practice. It directly addresses root causes #1 and #2 by tracing the application’s call graph from entry points to determine which code paths are reachable.
Not all implementations are equal. Some tools perform shallow reachability (direct function calls) while others perform deep reachability (multi-step call chains across files and modules). CodeAnt AI implements deep reachability analysis, mapping findings across the entire codebase to ensure only genuinely accessible vulnerabilities reach the developer.
Contextual Taint Tracking
Taint analysis in SAST traces the flow of untrusted user input from its source (where it enters the application) through the code to a sensitive sink operation (where it does something dangerous). Standard taint analysis tracks data flow but lacks the context to understand whether the data has been sanitized along the way.
Contextual taint tracking improves on this by understanding framework-specific sanitizers, recognizing custom validation functions, and evaluating whether data transformations between source and sink render the flow safe. This directly addresses root causes #3 and #4, recognizing, for example, that data flowing through Django’s QuerySet.filter() is automatically parameterized and suppressing the false SQL injection alert.
AI-Powered Triage and Learning
AI-powered triage uses machine learning to evaluate findings, filtering out likely false positives based on patterns learned from previous scans, developer feedback, and codebase context. This addresses root cause #5 by providing the severity calibration that static rules lack.
The critical distinction is where AI operates. Some tools implement AI as a post-scan filter, generating findings first, then suppressing likely false positives. CodeAnt AI integrates AI at the detection layer itself, using LLM-powered reasoning as the primary analysis engine. When AI is the detection engine, false positives are prevented from being generated in the first place rather than generated and then hidden. The engine reasons about what code does, understanding framework behaviors, recognizing custom sanitizers, evaluating reachability, before producing a finding.
Steps of Reproduction: Validating Before Alerting
The three techniques above reduce false positives by improving detection accuracy. Steps of Reproduction take a fundamentally different approach: they give developers the evidence to validate any finding in seconds rather than hours.
Steps of Reproduction in SAST provide developers with the exact sequence of conditions needed to trigger a flagged vulnerability, the entry point, the taint flow through each intermediate step, the vulnerable sink, and a concrete exploitation scenario. Instead of “possible SQL injection on line 47,” the developer sees the specific input, the exact code path, and the conditions under which the vulnerability is actually exploitable.
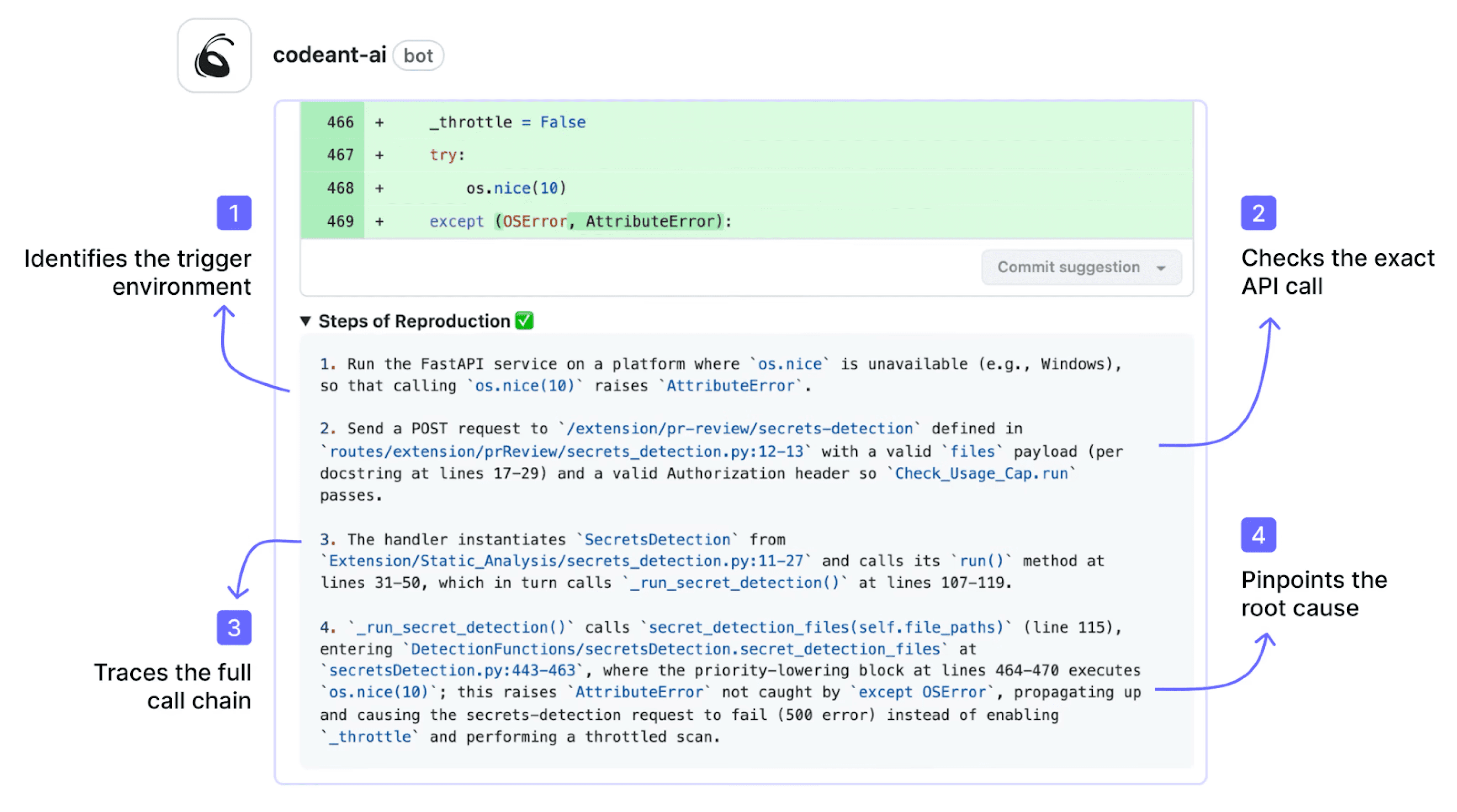
This transforms the false positive problem from “how do we prevent every false positive” (impossible, no scanner is perfect) to “how do we make it trivially easy for developers to validate any finding” (solvable, with the right evidence).
Before: A traditional SAST alert
⚠️ SQL Injection - CWE-89 · Severity: High
String-formatted SQL query detected on line 47. This could lead to SQL injection if the string includes user input.
File: app/models/user.py · Line 47
This alert tells the developer what was flagged and where, but not whether it is real. The developer must open the file, trace the data flow manually, check for upstream sanitization, and decide whether the finding is a true positive or noise. This takes 10–30 minutes per finding.
After: A CodeAnt AI finding with Steps of Reproduction
🔴 SQL Injection — CWE-89 · Severity: Critical · EPSS: 0.09%
Attack Path (5 steps):
Entry Point · api/routes/users.py:12 — request.args.get('user_id') accepts untrusted input from the query string. No validation or type checking is applied.
Step 1 · api/routes/users.py:15 — The raw user_id value is passed to UserService.get_user(user_id) without sanitization.
Step 2 · app/services/user_service.py:28 — get_user() forwards the value to UserRepository.find_by_id(user_id).
Step 3 · app/repositories/user_repo.py:41 — find_by_id() constructs a SQL query using string concatenation: "SELECT * FROM users WHERE id = '" + user_id + "'".
Vulnerable Sink · app/repositories/user_repo.py:42 — cursor.execute(query) executes the unsanitized query.
Exploitation Scenario: An attacker sends GET /api/users?user_id=' OR '1'='1 — the crafted input bypasses the intended query logic and returns all rows from the users table. A payload of '; DROP TABLE users; -- would delete the table entirely.
Fix: Replace string concatenation with a parameterized query → [Apply fix in one click]
The developer reading this finding does not need to investigate whether it is real. The attack path traces the untrusted input from the entry point through every intermediate function to the vulnerable sink. The exploitation scenario proves it is exploitable. The fix is one click away. Total time to validate and remediate: under 2 minutes.
This is the core difference. Traditional SAST tools shift the burden of false positive investigation to the developer. CodeAnt AI shifts the burden of proof to the tool, providing the evidence so the developer can make a confident decision immediately.
How to Evaluate a SAST Tool’s False Positive Rate
Every vendor will tell you their false positive rate is low. Here is how to verify that claim during a proof of concept.
Questions to Ask During a POC
Run the tool against your actual codebase, not a demo repository, and evaluate:
Detection quality: How many total findings are true positives vs. false positives? (This is your real-world FP rate.) Does the tool flag vulnerabilities in dead code or unreachable paths, and does it distinguish them from reachable ones? Does it understand your framework’s built-in protections? Run it against Django ORM, React JSX, or Spring Security code and check.
Evidence and explainability: For each finding, does the tool show the full attack path from entry point to vulnerable sink, or just a line number with a CWE reference? Does it provide Steps of Reproduction, a concrete exploitation scenario proving the vulnerability is real? Does it provide EPSS scoring for real-world exploit probability?
Developer experience: How long does it take a developer to validate a single finding? Time this, if it exceeds 5 minutes, the evidence quality is insufficient. Are findings inline in the PR or dashboard-only? Does the tool provide one-click AI-generated fixes?
Noise management: Does the tool learn from dismissed findings over time, or produce the same false positives on every scan? Can you configure custom sanitizers without editing XML files?
Red Flags in Vendor Claims
Be skeptical of any vendor that makes these claims without evidence:
“Our false positive rate is under 5%.” Ask: measured against what benchmark? On which codebase? If the vendor cites a synthetic benchmark rather than real-world customer codebases, the number is meaningless. Run the tool against your codebase during a POC and measure it yourself.
“AI eliminates false positives.” Ask: is AI used in the detection engine or only as a post-processing filter? A tool that generates 500 findings and then uses AI to suppress 400 is fundamentally different from a tool whose AI engine generates only 100 findings in the first place.
“We have the lowest false positive rate in the market.” Ask: what evidence? CodeAnt AI makes this claim and backs it with a specific architecture: AI-native detection as the primary engine, deep reachability analysis, EPSS-based prioritization, and Steps of Reproduction for every finding. If a vendor claims low false positives without explaining how, the claim is not verifiable.
The OWASP Benchmark Project provides a standardized test suite for evaluating SAST tool accuracy, including true positive and false positive rates. While no single benchmark captures real-world performance perfectly, it is a useful baseline for comparing tools on a consistent dataset.
Conclusion: SAST False Positives Are a Tool Problem, Not a Security Problem
False positives are not “just how SAST works.” They are a consequence of outdated rule-based detection.
When scanners flag hundreds of theoretical issues, developers stop trusting the tool. Security becomes noise. Remediation slows. Real vulnerabilities hide in the backlog.
Modern AI-native SAST changes that equation.
With semantic analysis, reachability filtering, EPSS exploit probability scoring, and full attack path tracing, findings are validated before they reach developers. Instead of investigating alerts, teams fix real issues.
The difference between a legacy scanner and an AI-native SAST platform is not incremental. It is operational.
If your team is spending more time dismissing alerts than fixing vulnerabilities, it is time to measure the false positive rate directly.
Run an AI-native SAST scan against your own codebase and compare signal versus noise. Book a quick walkthrough or start a 14-day trial and see what changes when findings are evidence-backed.
FAQs
Why do traditional SAST tools generate so many false positives?
How can AI-native SAST reduce false positives?
What is reachability analysis in SAST?
How does EPSS improve vulnerability prioritization?
What should teams evaluate during a SAST proof of concept?













