AI Code Review
What is AI Code Review and Why Every Engineering Team Needs It

Sonali Sood

Founding GTM, CodeAnt AI
Your team merged 200 pull requests last month. A human reviewed maybe 40% of them in any meaningful depth. The rest got a skim, a rubber stamp, or a "looks good to me" from someone who was already context-switching between four other things. This isn't a people problem. It's a volume problem, and it's about to get significantly worse.
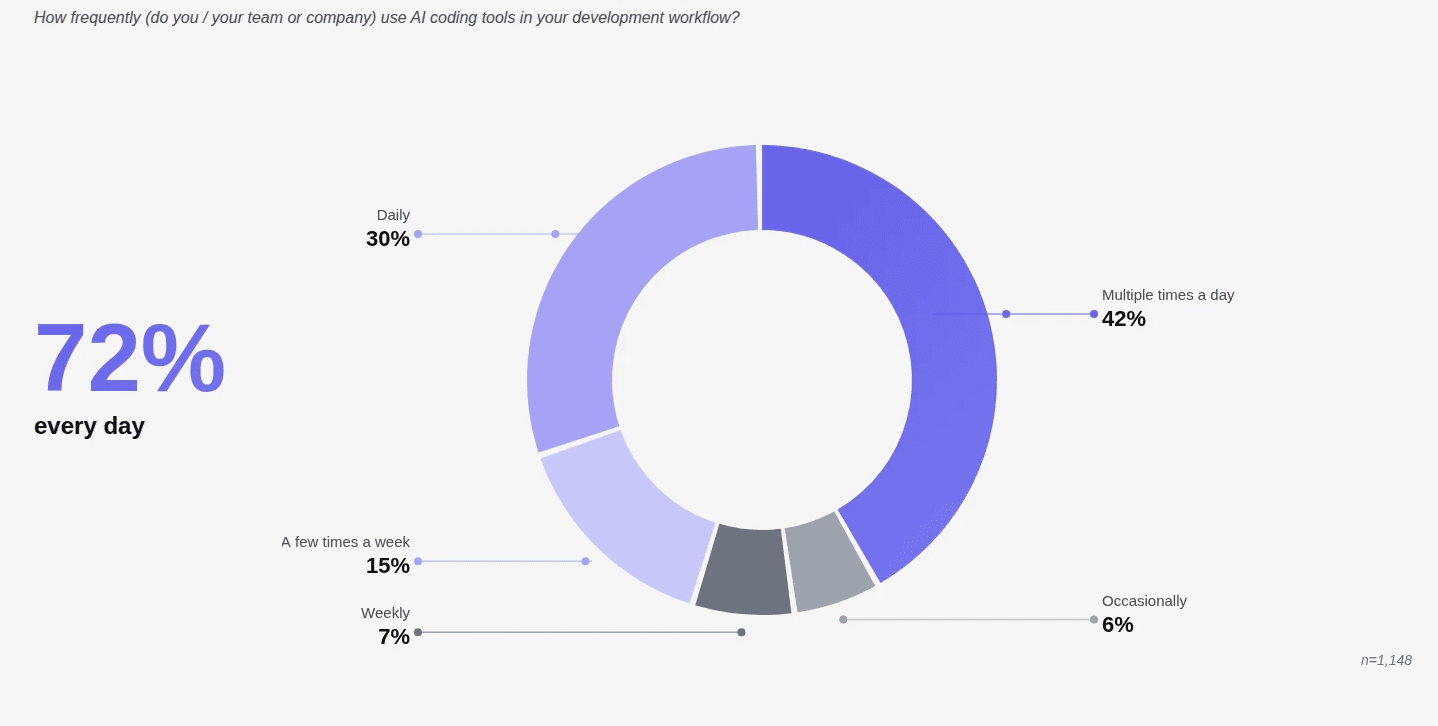
If 40%+ of new code is now AI-assisted, and AI-generated PRs produce 1.7× more issues per PR than human code, the math doesn't work in your favor.
What is AI Code Review?
AI code review is the use of machine learning and static analysis to automatically inspect pull requests for bugs, security vulnerabilities, code quality issues, and style violations, without requiring a human to manually examine every line. It runs on every PR, posts findings as inline comments, and can block merges that fail defined quality or security thresholds.
This article covers how it works, what separates the three tiers of tools, what it catches (and misses), and how to evaluate whether you need it.
For a full comparison of tools, see our best AI code review tools guide.
TL;DR
AI code review automates the first-pass inspection of pull requests, catching bugs, security issues, and quality problems before a human reviewer looks at the code
Three distinct tiers exist: rule-based SAST, AI-augmented review, and AI-native PR review platforms, each with different strengths and blind spots
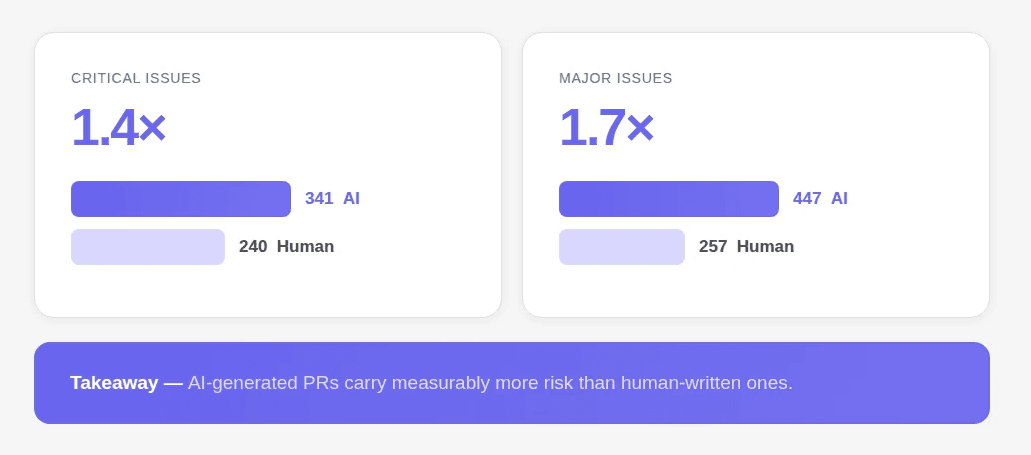
AI-generated code produces 1.7× more issues per PR than human code, making automated review more critical than ever
Effective AI code review requires full codebase context, not just diff analysis, and combining SAST with AI-native review achieves 93–94% accuracy vs. either alone
CodeAnt AI is an AI-native platform that bundles code review, SAST, secrets detection, IaC scanning, and DORA metrics in one tool
The Problem Automated Code Review Solves
Manual code review doesn't scale. Faros AI's research across 10,000+ developers found that high-AI-adoption teams merge 98% more PRs while review time increases 91%.
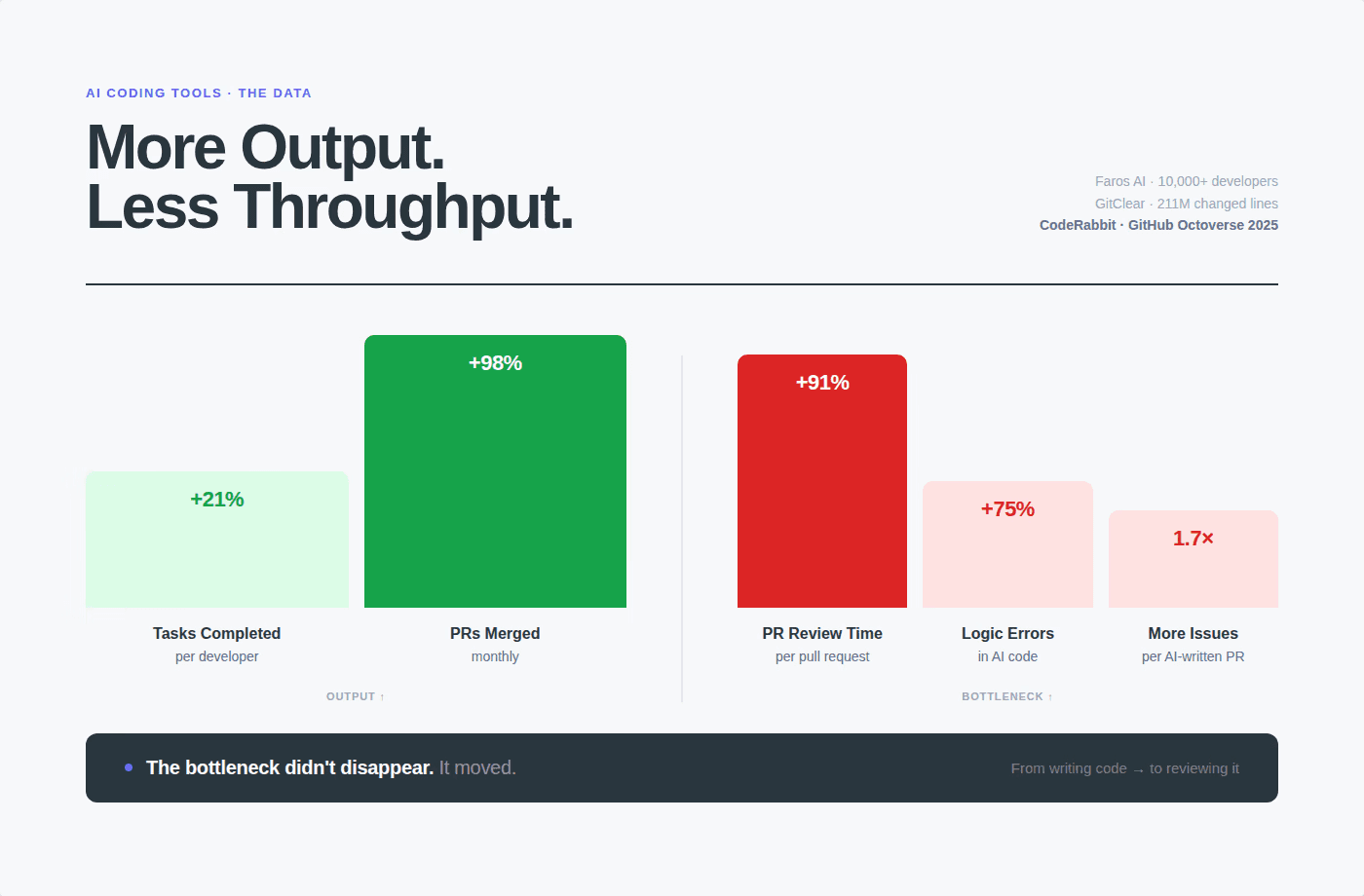
The result: overloaded reviewers who can't give every PR the attention it deserves, bugs that sneak through, security vulnerabilities that go unnoticed for weeks, and technical debt accumulating faster than it can be paid down.
AI code review tools address this by running an automated first pass on every PR, catching the mechanical issues (security vulnerabilities, known bug patterns, style violations, secret exposure) so human reviewers can focus on the things that actually require judgment: architecture, business logic, and design decisions.
The 3-Tier Taxonomy of AI Code Review Tools
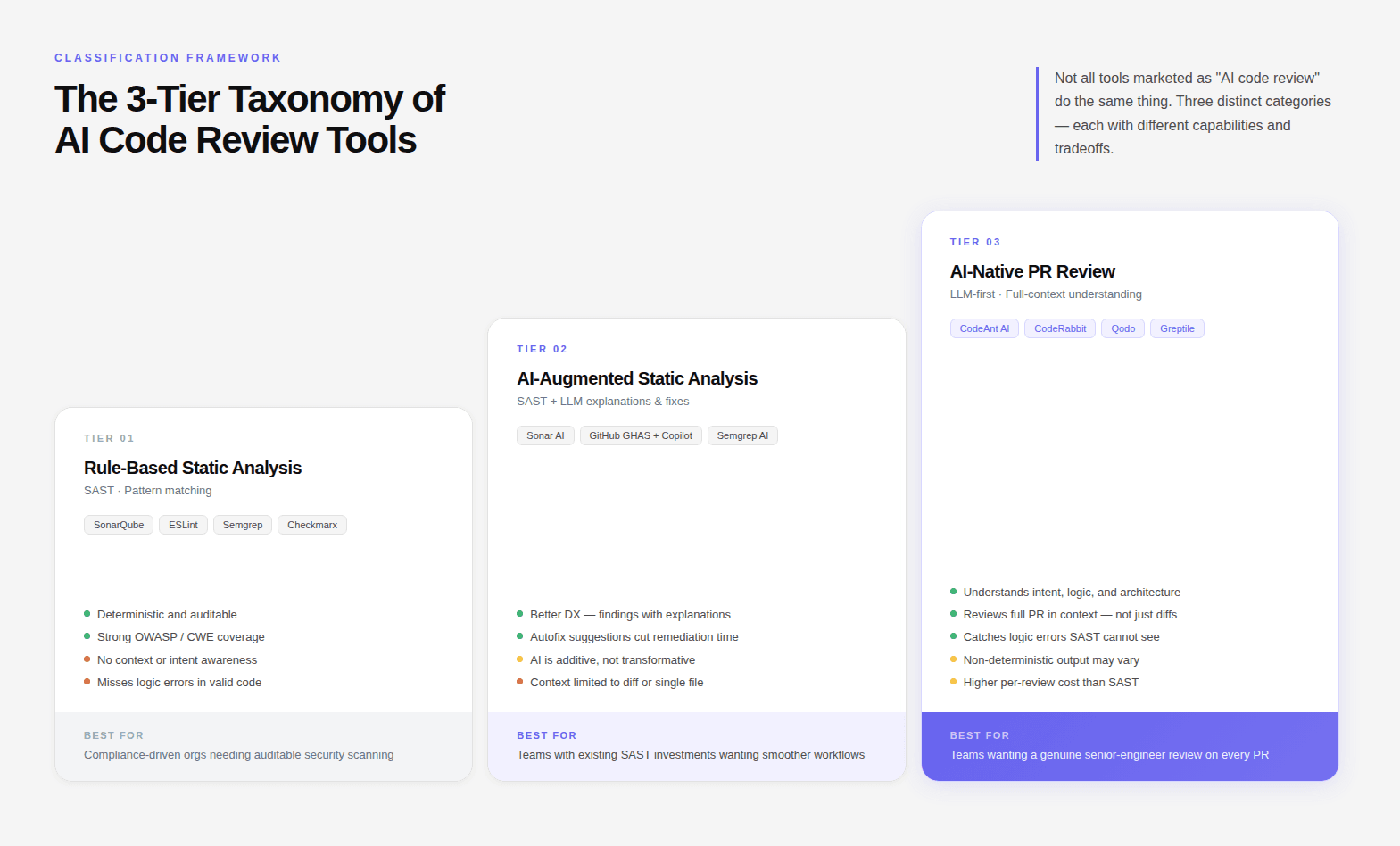
Not all tools marketed as "AI code review" do the same thing. There are three distinct categories, each with different capabilities and limitations.
Tier 1: Rule-Based Static Analysis (SAST)
How it works: Scans source code against a predefined library of rules and patterns. Flags code that matches known vulnerability signatures, complexity thresholds, or style violations.
Examples: SonarQube Community Build, ESLint, Semgrep, Checkmarx
Strengths:
Deterministic; same input always produces same output
Fast and cheap to run at scale
Strong at catching known vulnerability classes (OWASP Top 10, CWE Top 25)
Audit-friendly; findings are traceable to specific rules
Limitations:
Can only catch patterns it has rules for
High false positive rates without tuning
No understanding of intent or context
Misses logic errors where code is syntactically valid but semantically wrong
Cannot evaluate whether a PR fits your team's architectural conventions
When it's the right choice: Compliance-driven organizations that need deterministic, auditable security scanning. Works best as a layer within a broader pipeline, not as a standalone review solution.
Tier 2: AI-Augmented Static Analysis
How it works: Combines traditional SAST with LLM-based summarization and explanation. The static analysis engine still drives detection; the AI layer adds natural language explanations, prioritization assistance, and sometimes fix suggestions.
Examples: SonarQube with AI Code Fix (Sonar AI), GitHub Advanced Security with Copilot Autofix, Semgrep with AI-assisted triage
Strengths:
Better developer experience, findings come with explanations and context
AI helps reduce false positive noise through natural language triage
Autofix suggestions accelerate remediation
Retains auditability of underlying SAST rules
Limitations:
Still fundamentally rule-bound in what it detects
AI layer is additive, not transformative, doesn't change the underlying detection surface
Context awareness is limited to the diff or the immediate file, not the full codebase
Autofix quality varies significantly by tool and language
When it's the right choice: Teams that already have a SAST investment and want to reduce the friction of acting on findings, without rearchitecting their pipeline.
SonarQube's AI Code Assurance feature (introduced October 2024 in v10.7) is worth calling out here. It applies stricter quality gates to projects containing AI-generated code, requiring zero new bugs, mandatory security hotspot review, and higher test coverage thresholds. It's a sensible response to the AI code quality problem, but it's still fundamentally a rule-based detection engine with AI-augmented UX.
Tier 3: AI-Native PR Review Platforms
How it works: Uses large language models with full codebase context to review PRs the way a senior engineer would, understanding intent, checking for logic errors, evaluating architectural fit, and surfacing issues that no static rule would catch.
Examples: CodeAnt AI, CodeRabbit, Qodo, Cursor BugBot, Greptile
Strengths:
Understands code in context, not just what the diff says, but whether it fits the codebase
Catches logic errors, hallucinated APIs, context blindness, and architectural drift
Generates natural language review comments developers actually read
Can learn team conventions and enforce them without explicit rule writing
Supports auto-fix suggestions that go beyond mechanical pattern matching
Limitations:
Non-deterministic; the same PR might get slightly different comments on different runs
Higher compute cost than SAST
Can produce false positives without tuning
Doesn't replace deterministic SAST for compliance requirements that need rule traceability
When it's the right choice: Teams shipping AI-generated code at scale, organizations that need review to go beyond rule matching, and engineering orgs with multiple git platforms that need a single consistent review layer.
What AI Code Review Actually Catches
Here's a concrete breakdown of what falls within the detection surface of modern AI-native review tools:
Issue type | Rule-based SAST | AI-Augmented | AI-Native |
|---|---|---|---|
Known vulnerability patterns (SQLi, XSS, SSRF) | ✅ | ✅ | ✅ |
Hardcoded secrets and API keys | ✅ | ✅ | ✅ |
Outdated / vulnerable dependencies | ✅ | ✅ | ✅ |
IaC misconfigurations (K8s, Terraform, Docker) | ✅ | ✅ | ✅ |
Logic errors in valid code | ❌ | ⚠️ Partial | ✅ |
Hallucinated API calls | ❌ | ❌ | ✅ |
Architectural convention violations | ❌ | ❌ | ✅ |
Context blindness (cross-file, cross-module) | ❌ | ❌ | ✅ |
Tautological tests (tests that don't test) | ❌ | ⚠️ Partial | ✅ |
Copy-paste amplification | ❌ | ⚠️ Partial | ✅ |
PR summary and intent explanation | ❌ | ✅ | ✅ |
One-click auto-fix | ❌ | ⚠️ Limited | ✅ |
The cells marked ⚠️ reflect capability gaps: some AI-augmented tools detect these partially, depending on context window size and tool configuration.
What AI Code Review Does NOT Replace
It's worth being direct about the limits.
AI code review doesn't replace human judgment on architecture. Whether a new service should be its own microservice or a module within an existing one, whether a data model is the right abstraction for a business concept, whether a proposed API design will age well, these are not pattern-matching questions. They require understanding business context, historical decisions, and future direction that no tool has access to. So, learn why it is important for your team to make AI code review mandatory now.
It doesn't replace security audits for high-stakes systems. For financial systems, healthcare data, or national infrastructure, a dedicated security audit by a human expert is still necessary. AI review dramatically reduces the attack surface that auditors need to examine, but it doesn't eliminate the need for their judgment.
It doesn't catch everything. A hybrid SAST + AI-native approach achieves 93–94% accuracy in research benchmarks. That means 6–7% of issues still slip through. The goal is to dramatically reduce the defect rate that reaches production, not eliminate it entirely.
You can read our complete 101 guide on AI code review vs Human code review.
How the Hybrid Approach Works in Practice
The strongest review pipelines combine all three tiers. Here's how a PR flows through CodeAnt AI:
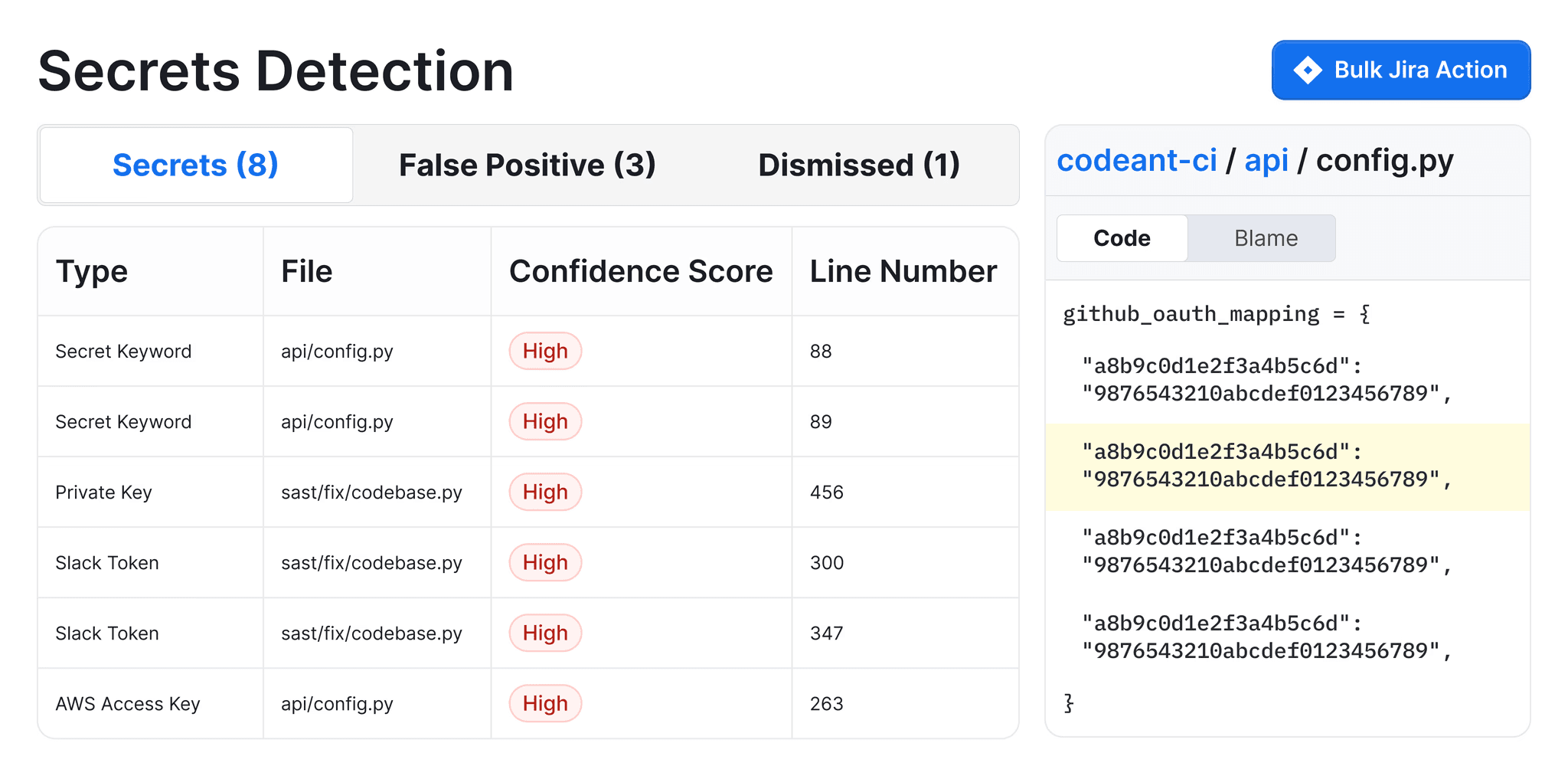
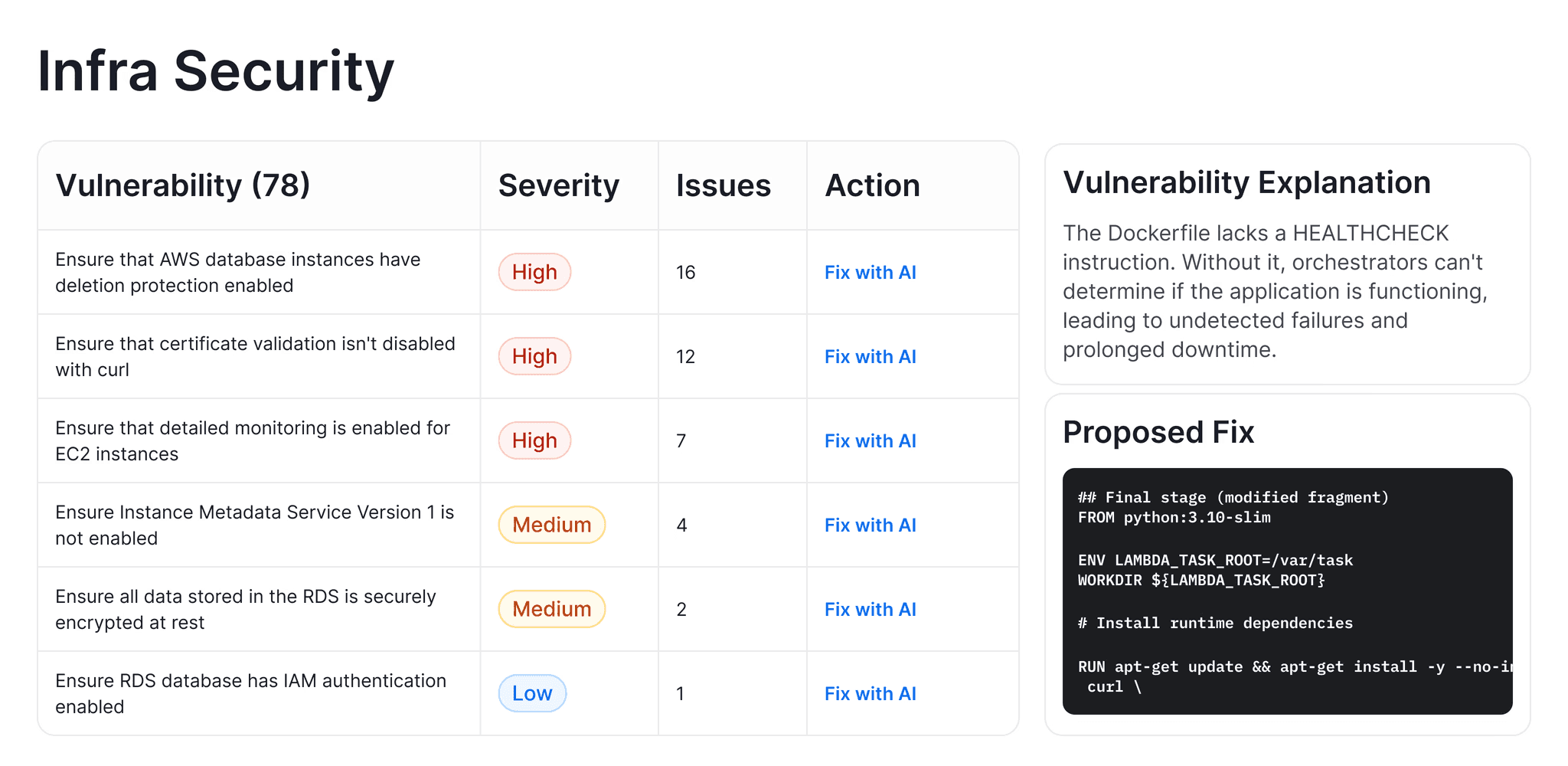
PR opened → webhook fires, CodeAnt AI begins analysis
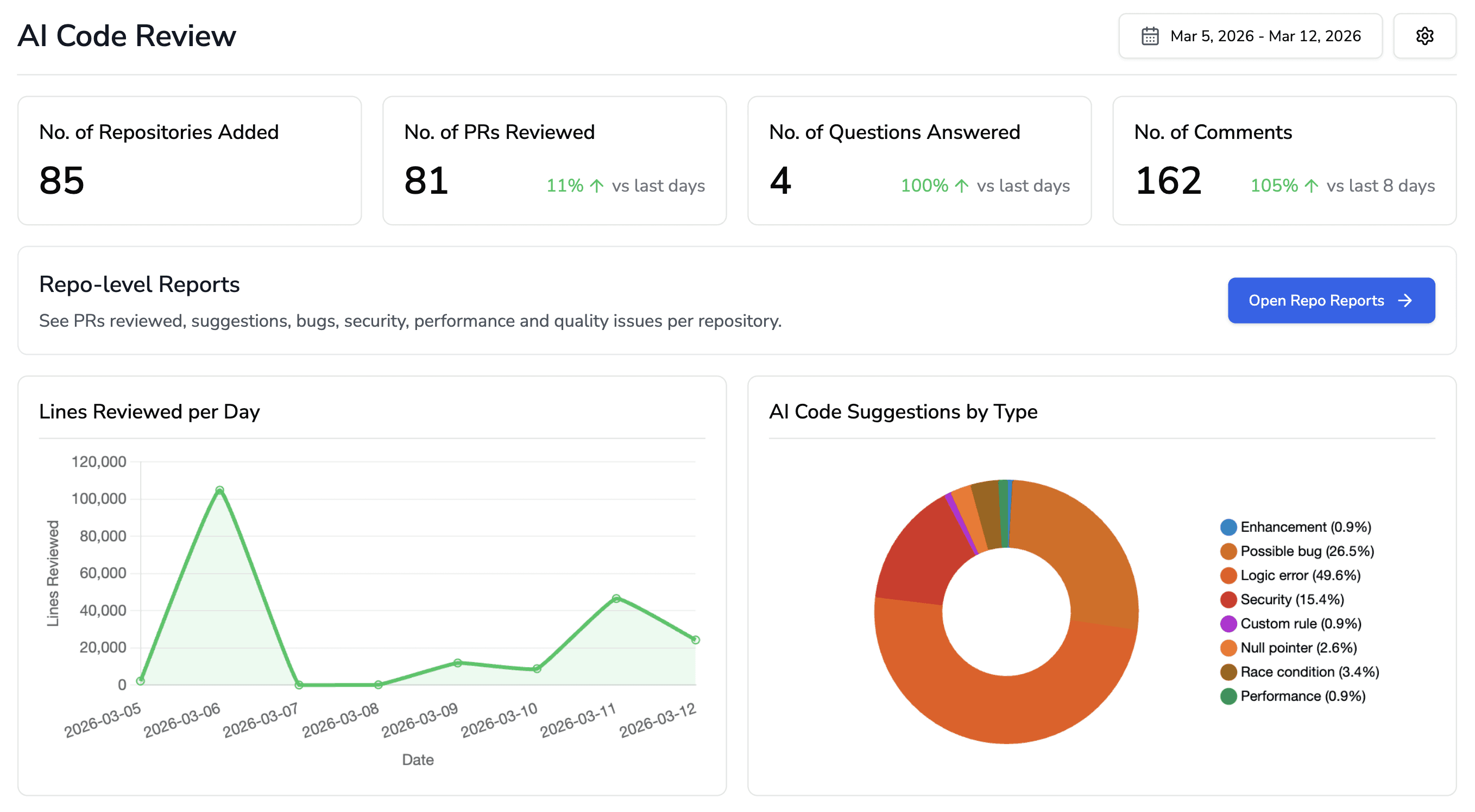
SAST scan → 30+ languages scanned against known vulnerability patterns (OWASP Top 10, CWE Top 25, language-specific rules)
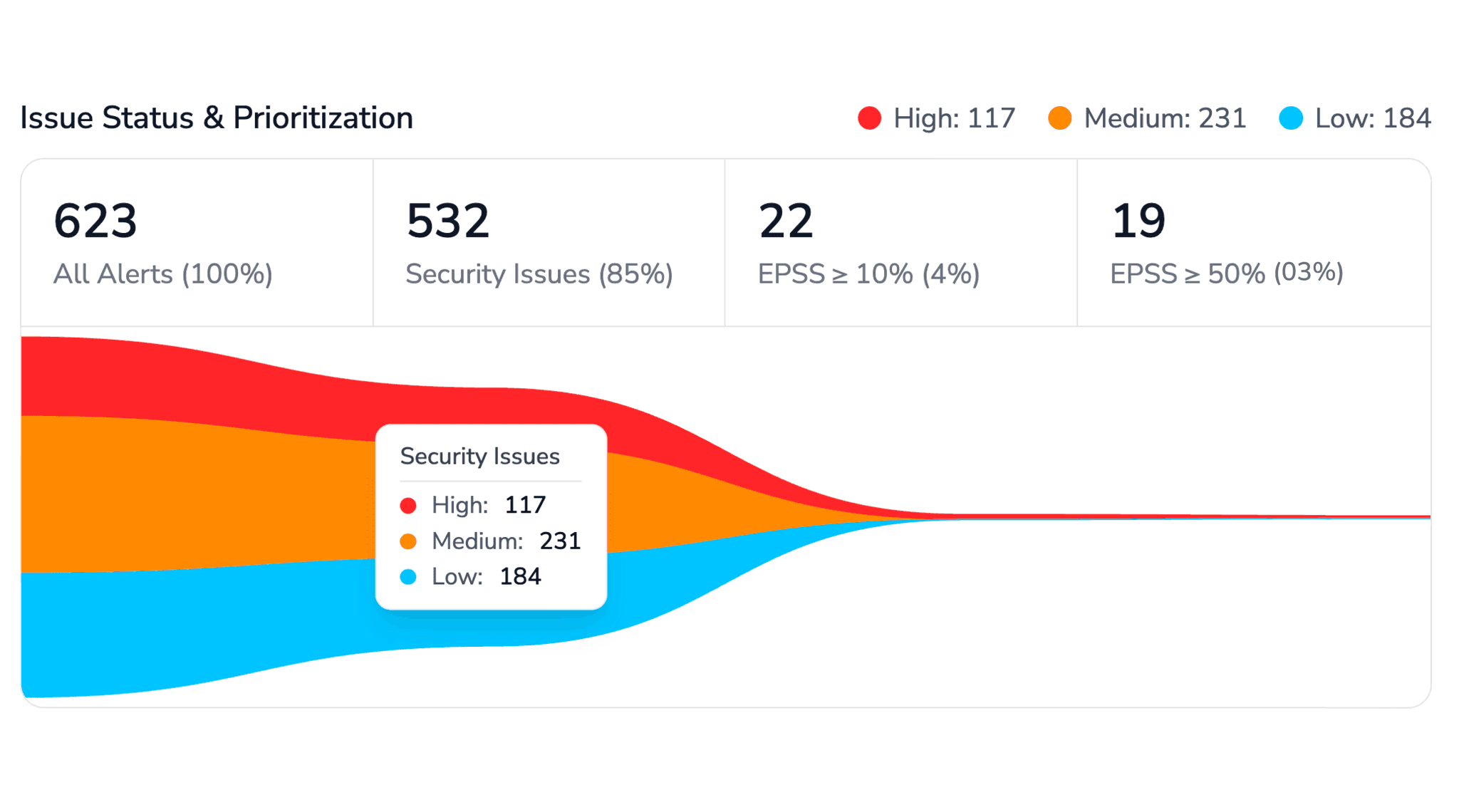
Secrets detection → entropy-based and pattern-based scanning for exposed credentials, tokens, and API keys
IaC scanning → Kubernetes, Terraform, Docker, and YAML configurations checked for misconfigurations
SCA → dependencies cross-referenced against CVE databases; vulnerable versions flagged with fix recommendations

AI-native review → full codebase context loaded; LLM analyzes the PR for logic errors, context violations, hallucinated calls, style drift, and architectural issues
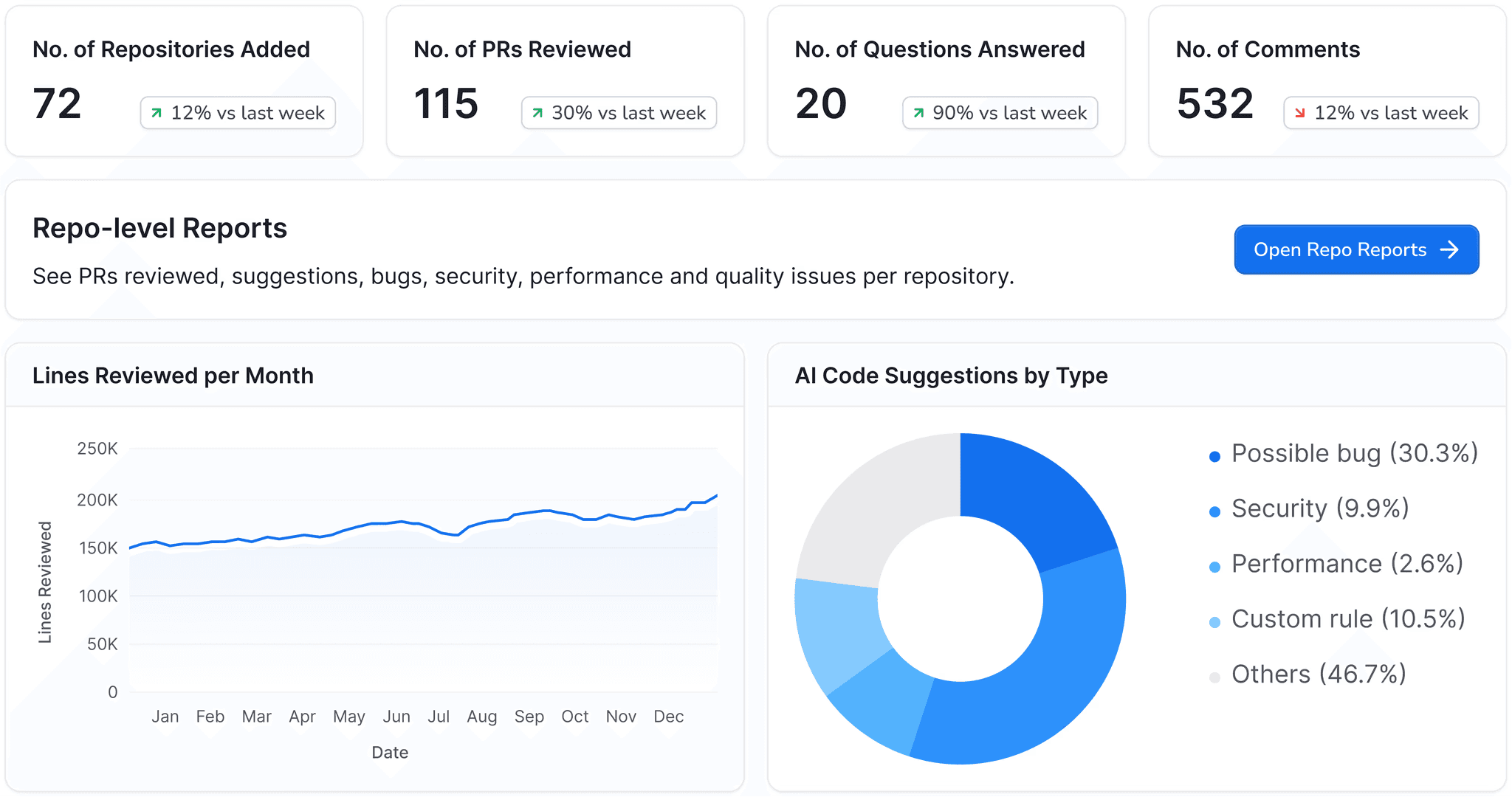
Steps of Reproduction → for flagged bugs, CodeAnt AI generates exact reproduction steps so developers can verify the issue in seconds
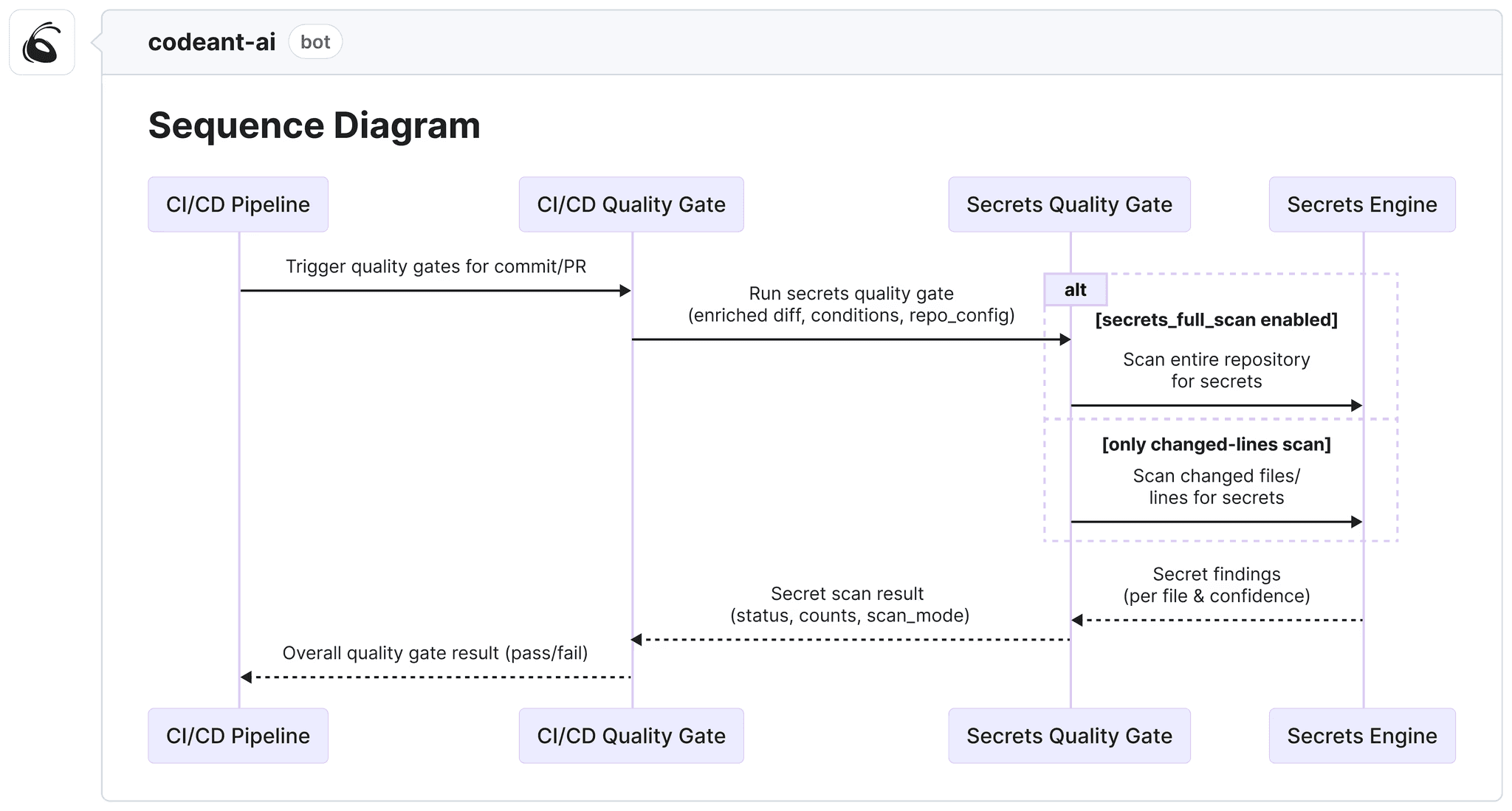
Quality gate check → critical findings block the PR; others post as inline review comments with one-click auto-fix options
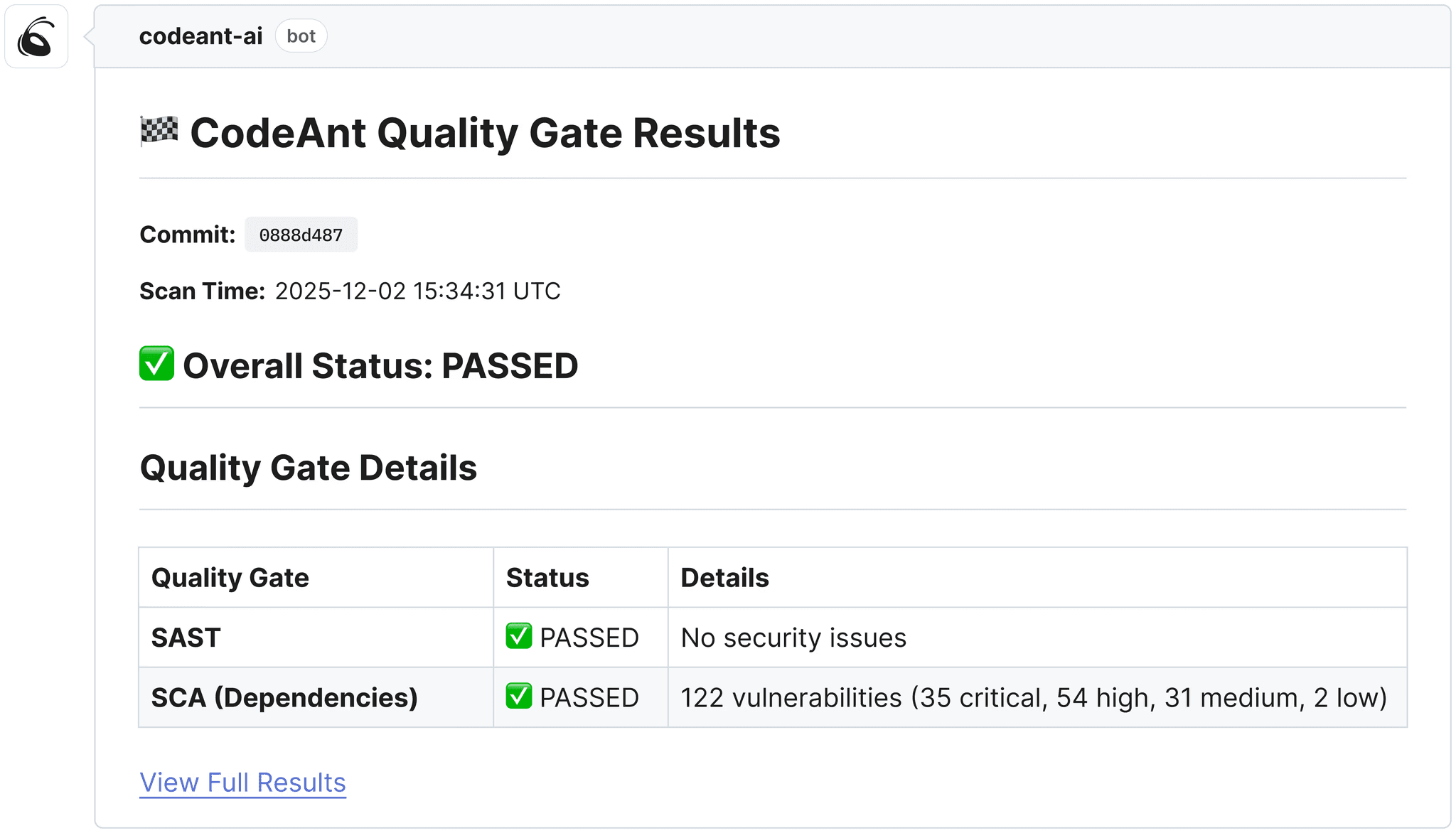
Developer response → ~80% of findings include an auto-fix; developers can apply, dismiss, or escalate
The entire pipeline runs in under 2 minutes for most PRs. You can checkout our real use cases where, Commvault reduced review turnaround from 3.5 days to under 1 minute. Bajaj Finserv replaced SonarQube with CodeAnt AI for 300+ developers, eliminating per-lines-of-code pricing while adding AI-native review on top.
How AI Code Review is Changing With AI-Generated Code
The most important trend in the space is that the source of the code being reviewed is changing. When developers wrote every line manually, review tools could assume the code had intent behind it, a human made a deliberate choice.
AI-generated code violates this assumption. That said, PRs now produce 1.7× more issues per PR, with logic errors 75% more common, security vulnerabilities 1.5–2× higher, and excessive I/O operations ~8× more prevalent.
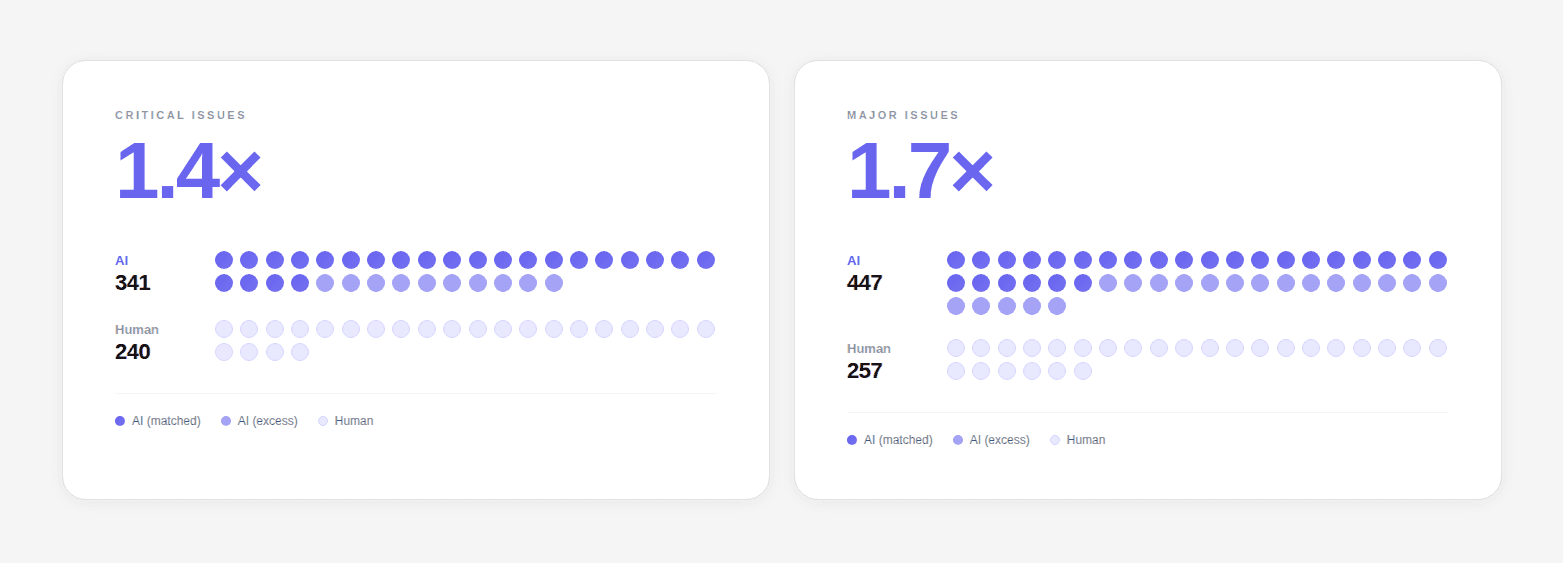
Simultaneously, copy-paste code blocks increased 8-fold during 2024 as AI tools scaled adoption.
This changes the requirements for review tools significantly:
Full codebase context is now non-negotiable. AI writes code without knowing your conventions; the reviewer needs to know them.
SAST alone is insufficient. Logic errors in syntactically valid code require understanding, not pattern matching.
Quality gates need to be stricter. The higher defect rate from AI code means more issues would slip through if gates stay calibrated for human-written code.
Where to Go Next?
If you're evaluating tools: best AI code review tools in 2026, a ranked comparison of 10 platforms with verified pricing and platform support.
The Future of Code Review Is AI Assisted
Software development is entering a new phase where the volume of code is growing faster than humans can review it. AI generated code is accelerating development, but it is also introducing new categories of bugs, security risks, and architectural inconsistencies.
Manual review alone cannot keep up. AI code review does not replace human engineers. Instead it acts as the first line of defense, scanning every pull request for vulnerabilities, logic errors, and quality issues before a human reviewer ever looks at the code.
This shift allows engineers to spend less time catching mechanical mistakes and more time focusing on architecture, design, and business logic.
As AI generated code continues to scale across the industry, automated code review will become a standard part of modern development pipelines. The teams that adopt it early will ship faster, reduce production defects, and maintain higher code quality at scale.
Tools like CodeAnt AI demonstrate what this future looks like by combining static analysis, security scanning, and AI-native review into a single automated quality gate.
Because in the era of AI generated software, the most valuable code reviewer may no longer be human.
It will be the system that reads every line of code before it reaches production. Check out our 14-day free trail yourself and know the perks.
FAQs
What is AI code review in simple terms?
How does AI code review integrate with GitHub, GitLab, or Bitbucket?
Does AI code review work on AI-generated code?
What is the difference between AI code review and AI code generation?
Is AI code review secure? Does it send my code to third parties?













