

Your team ships faster than ever. Copilot, Cursor, and Claude write half the code. PRs flood in. And your review process, designed for a world where humans wrote every line, is drowning.
Here's the paradox: AI writes code that looks flawless on the surface but hides subtle logic errors, hallucinated APIs, and security anti-patterns that traditional review was never built to catch. The fix isn't more human reviewers. It's a fundamentally different automated review pipeline, one designed specifically for AI-generated code.
AI-generated code review is the practice of using automated tools to analyze, validate, and enforce quality and security standards on code produced by AI coding assistants like GitHub Copilot, Cursor, or Claude Code, before it merges into your codebase. Unlike traditional code review, it requires full codebase context, multi-layered analysis (SAST + AI-native review), and stricter quality gates to catch the failure modes unique to AI output.
If you're evaluating tools for this workflow, our comparison of the best AI code review tools covers the full landscape. This guide focuses on the how, building the pipeline from scratch.
TL;DR
AI-generated code produces 1.7× more issues per PR than human code, with logic errors up 75% and security vulnerabilities 1.5–2× higher (CodeRabbit, Dec 2025)
Traditional diff-only review and rule-based SAST miss AI-specific failure modes like hallucinated APIs, context blindness, and copy-paste amplification
Effective automated review combines deterministic SAST with AI-native analysis, hybrid approaches achieve 93–94% accuracy vs. either tool alone
A practical pipeline integrates SAST + secrets detection + IaC scanning + AI review into your existing PR workflow with security quality gates that block critical issues
CodeAnt AI bundles all of this, including Steps of Reproduction and one-click auto-fixes, across GitHub, GitLab, Bitbucket, and Azure DevOps
Why AI-Generated Code Breaks Your Existing Review Process
The numbers are stark. Faros AI's research across 10,000+ developers found that teams with high AI adoption merge 98% more pull requests, but PR review time increases 91%. Greptile's data shows median PR size grew 33% between March and November 2025. More code, bigger PRs, and fewer humans available to review it all.
The acceptance rate gap tells the real story. LinearB's 2026 benchmarks across 8.1 million PRs from 4,800 engineering teams found that AI-generated PRs have a 32.7% acceptance rate vs. 84.4% for human-written PRs. That's not a rounding error. That's a signal that most AI code isn't production-ready without serious intervention.
Why? Because AI code fails differently than human code. A junior developer writes code that obviously needs work — missing error handling, unclear naming, rough edges a reviewer spots immediately. AI code is the opposite. It's syntactically polished, consistently formatted, and confidently wrong.
Traditional review assumes the reviewer can trust what they see. AI-generated code violates that assumption. For a deeper dive into what AI code review is and how it differs from traditional approaches, we've covered the fundamentals separately.
The 7 failure modes of AI-generated code
Understanding how AI code fails is prerequisite to building a review pipeline that catches these failures. Each mode requires a different detection strategy.
1. Hallucinated API calls
AI generates calls to functions that don't exist, use wrong signatures, or reference deprecated interfaces. A Stanford and Hugging Face study found over 42% of AI code snippets contain hallucinations, including non-existent APIs.
This is more dangerous than it sounds. In dynamically typed languages, hallucinated calls often compile and run without errors:
Standard linters won't catch this. TypeScript strict mode catches some cases at compile time, but Python, JavaScript, and Ruby are wide open. Endor Labs reported that ~34% of AI-suggested dependencies don't exist at all in public registries — creating supply-chain attack vectors where attackers register packages under hallucinated names.
2. Context blindness
AI writes code without understanding your architecture. It doesn't know that Service A shouldn't query Service B's database directly, or that your team wraps all HTTP calls through a custom retry client.
MIT CSAIL researchers found that "every company's code base is kind of different and unique," making proprietary conventions "fundamentally out of distribution" for AI models. CodeRabbit's data confirmed it: naming inconsistencies were ~2× more common in AI PRs, and formatting problems appeared 2.66× more frequently.
3. Copy-paste amplification
When AI duplicates a pattern, it duplicates it everywhere — including the bugs. GitClear's analysis of 211 million changed lines found an 8-fold increase in duplicated code blocks (5+ lines) during 2024. Copy-pasted lines now exceed refactored lines for the first time in the history of their dataset. Refactoring signals crashed from 24% in 2021 to below 10% in 2024.
Unlike human copy-paste (which is targeted and usually modified), AI copies mechanically at scale. When a bug exists in one copy, AI won't fix it in the others — it may even regenerate the same buggy pattern.
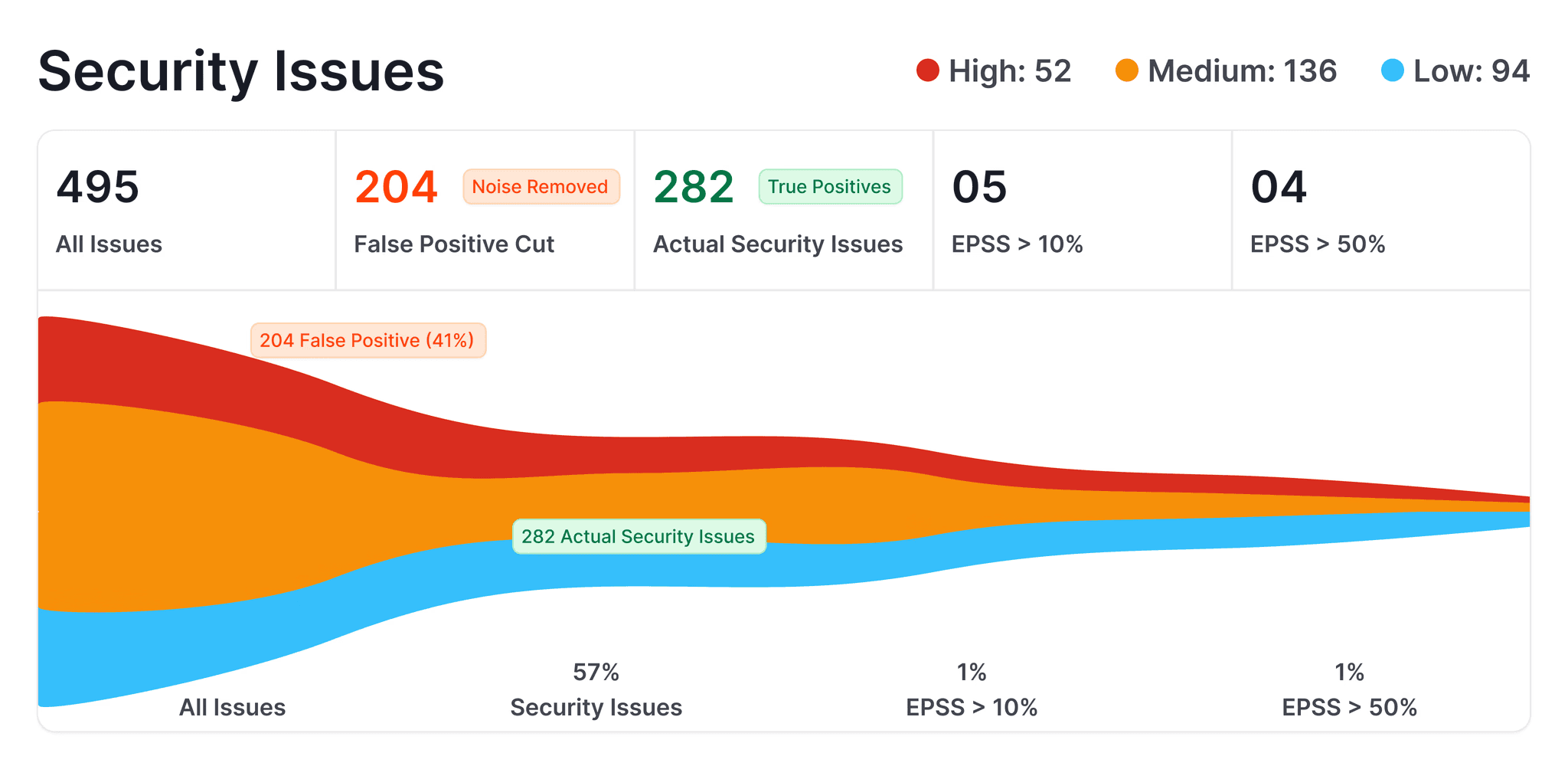
4. Security anti-patterns
Veracode tested 80 coding tasks across 100+ LLMs and found 45% of all test cases introduced OWASP Top 10 vulnerabilities. Java had the worst results at a 72% security failure rate. AI failed to defend against XSS in 86% of cases and log injection in 88% of cases.
A study of GitHub repos found that 6.4% of repos using Copilot leak at least one secret — 40% higher than repos without AI assistance. For more on how to handle AI code from a security review perspective, we cover the detection strategies in depth.
5. Test coverage gaps
AI generates tests that pass but don't test real behavior. Mark Seemann calls this "cargo-cult testing" tests that mirror implementation assumptions rather than challenging them.
A real postmortem on DEV Community described AI-generated tests that "essentially duplicated the implementation's assumptions rather than challenging them." Tests passed, CI showed green, but production revealed silently incorrect data. AI-generated tests also skew heavily toward happy-path scenarios, ignoring edge cases, boundary conditions, and error states.
6. Dependency drift
AI models train on static snapshots of public code, often scraped before 2023. They have no live access to package registries, no awareness of CVE records, no concept of deprecation. Endor Labs found that only 20% of AI-suggested dependencies meet safety standards, and 44–49% of AI-imported dependency versions have known vulnerabilities.
An academic study confirmed that AI agents select known-vulnerable versions more often than humans (2.46% vs. 1.64%), and remediation is harder: 36.8% of agent-introduced vulnerable selections require a major-version upgrade.
7. Style inconsistency with team conventions
This seems minor compared to security holes, but it compounds fast. AI-generated code drifts toward generic defaults, standard library idioms instead of your team's patterns, default error handling instead of your custom error types, camelCase where your codebase uses snake_case. A CMU study found static analysis warnings rose ~30% post-AI-adoption across 800+ GitHub projects, with code complexity increasing more than 40%.
What Good Automated Review Looks Like for AI Code
Traditional review tools weren't built for these failure modes. Here's what's different about a review architecture designed for AI-generated code.
Diff-only review is insufficient
Most code review tools analyze only the changed lines in a PR. That's fine when a human developer makes a targeted change. It fails for AI-generated code because the bugs are contextual, a function that's syntactically correct but architecturally wrong, a pattern that violates a convention established three directories away, a dependency that conflicts with an existing import.
Effective AI code review requires full codebase context. The review tool needs to understand your entire repository, its architecture, conventions, existing patterns, to evaluate whether new AI-generated code fits.
Rule-based SAST alone misses the point
Static analysis catches known vulnerability patterns:
SQL injection via string concatenation
hardcoded credentials
insecure deserialization
It doesn't catch hallucinated APIs, context blindness, or logic errors where the code is syntactically valid but semantically wrong.
SonarQube recognized this gap with their AI Code Assurance feature (introduced in v10.7, October 2024). It enforces stricter quality gates on projects containing AI-generated code, zero tolerance for new bugs, mandatory security hotspot review, high test coverage requirements. It's a step in the right direction, but it's still fundamentally SAST-based. It doesn't understand intent.
The hybrid approach: SAST + AI-native review
Recent research confirms what practitioners already suspected: neither SAST nor LLM-based review alone is sufficient, but combining them achieves dramatically better results. A hybrid methods study found that combining LLMs with static analysis achieves 93–94% accuracy, significantly outperforming either approach alone. Another study focused on vulnerability detection found that injecting SAST findings as verification hints achieves a 96.9% detection rate and recovers 47% of baseline misses.
The architecture looks like this:
Layer | What it catches | Tool type |
|---|---|---|
Deterministic SAST | Known vulnerability patterns, code smells, complexity | Rule-based scanner |
Secrets detection | API keys, credentials, tokens | Pattern + entropy scanner |
SCA / dependency check | Vulnerable or outdated dependencies | Registry-aware scanner |
IaC scanning | Misconfigurations in Terraform, K8s, Docker | Policy engine |
AI-native review | Logic errors, hallucinated APIs, context violations, architectural drift | LLM with full codebase context |
Quality gates | Enforcement — blocks merge on critical findings | Policy layer |
Multi-pass review reduces false positives
Cursor's BugBot demonstrated an effective pattern: run 8 parallel review passes with randomized diff ordering, then use majority voting to filter results. When multiple passes independently flag the same issue, it's treated as a stronger signal. This approach pushed their resolution rate (percentage of flagged issues actually fixed by developers) from 52% to over 70%, meaning developers agreed with and acted on the findings.
The key insight: a single LLM pass produces too many false positives. Multiple independent passes with consensus filtering dramatically improves signal quality. This is consistent with the broader finding that combining multiple LLMs for false positive detection improves accuracy from 62.5% to 78.9% on standard benchmarks.
Steps of Reproduction close the verification gap
When an AI reviewer flags a potential bug, the developer's first question is: "Is this real?" Without reproduction steps, flagged issues become noise. With them, developers can verify the problem and confirm the fix in seconds. This is especially critical for AI-generated bugs, which are often subtle logic errors requiring specific input sequences to trigger.
For more on why Steps of Reproduction matter in code review, we've written about the concept in detail.
Setting Up Your Automated Review Pipeline With CodeAnt AI
Here's the practical setup. CodeAnt AI bundles SAST, secrets detection, IaC scanning, SCA, and AI-native review into a single platform, which means you don't need to stitch together five different tools.
Step 1: Connect your Git platform
CodeAnt AI integrates natively with GitHub, GitLab, Azure DevOps, or Bitbucket. Installation is a one-click OAuth flow:
Go to codeant.ai and start a free trial
Select your Git provider and authorize access
Choose which repositories to enable
No YAML pipelines to configure. No CI runners to provision. The integration installs as a webhook on your repos and starts reviewing PRs immediately.
Step 2: Configure quality gates
Quality gates define what blocks a merge. For AI-generated code, configure these stricter than your human-code defaults:
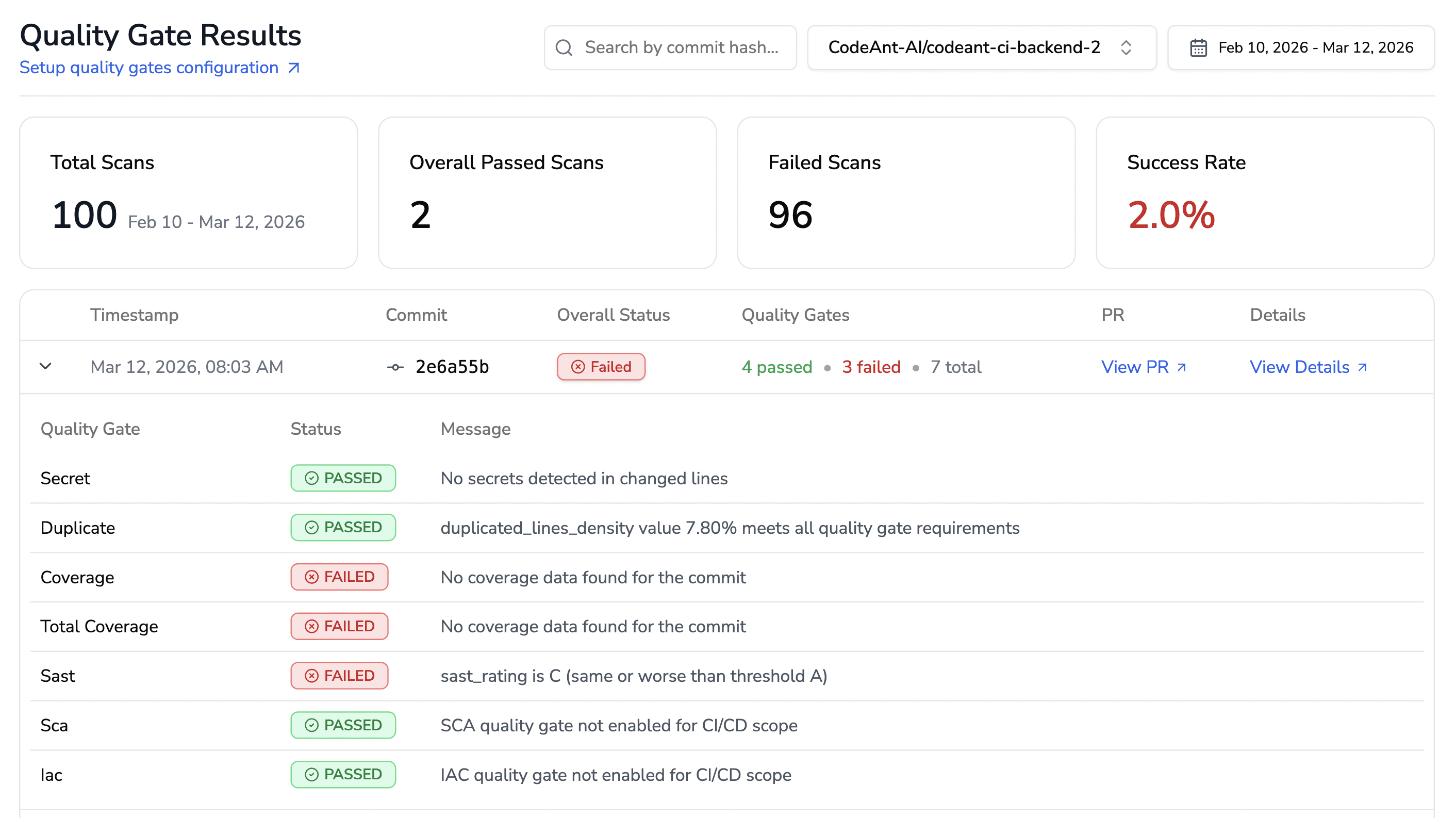
Zero critical security vulnerabilities; any CVSS 7.0+ finding blocks the PR
Zero high-severity bugs; logic errors and null-reference risks flagged as blocking
Secrets detection; any detected credential or API key is an automatic block
Test coverage threshold; enforce minimum coverage on new code paths
CodeAnt AI's quality gates integrate into your branch protection rules. A PR that fails a gate cannot be merged until the issue is resolved or explicitly overridden by a lead.
Step 3: Set up SAST + secrets + IaC in one pipeline
With CodeAnt AI, this isn't a separate step, it's bundled. Every PR automatically gets:
SAST scanning across 30+ languages for known vulnerability patterns
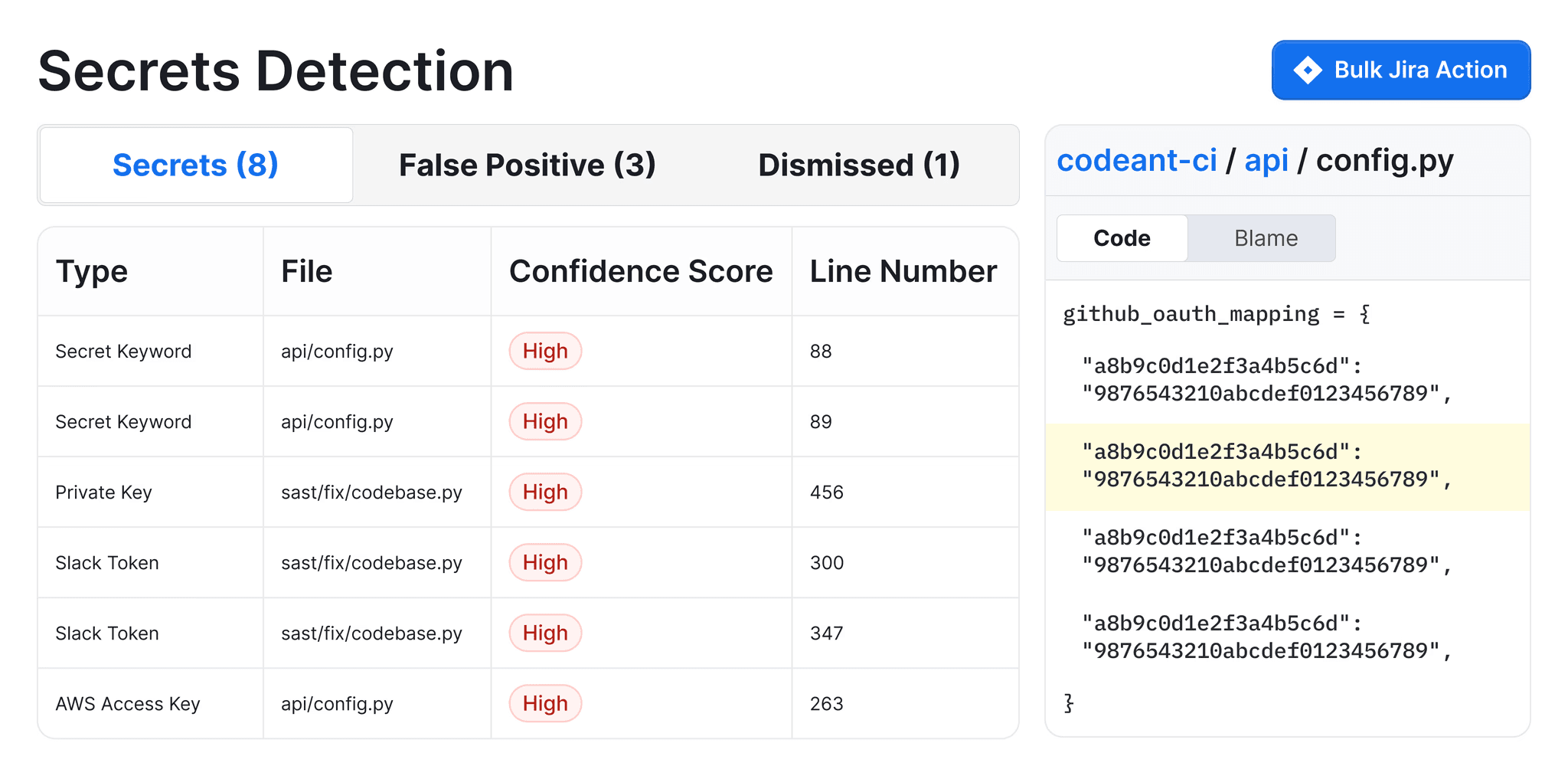
Secrets detection catching hardcoded API keys, AWS credentials, tokens
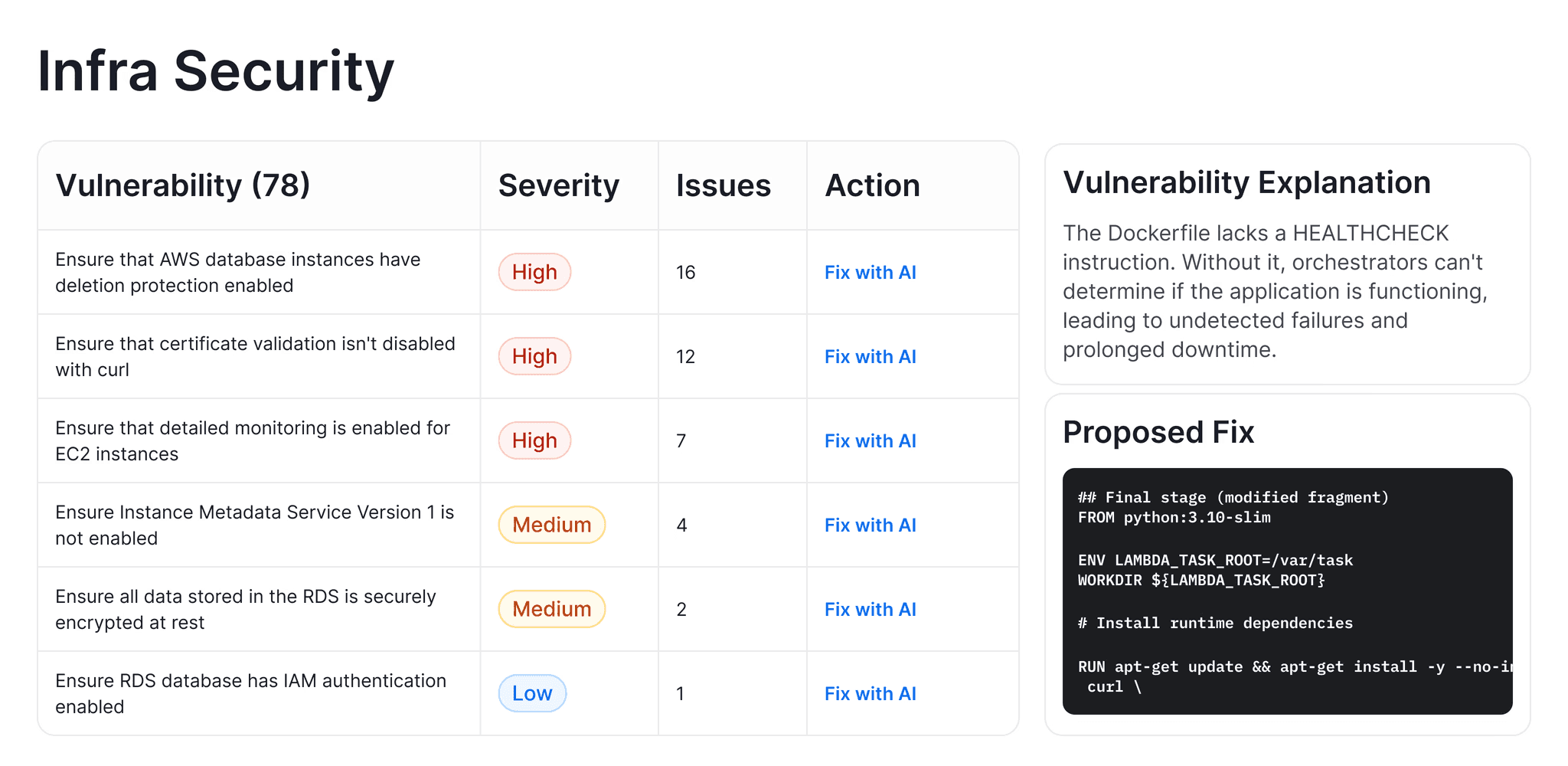
IaC scanning for Kubernetes, Docker, Terraform, and YAML misconfigurations
SCA surfacing vulnerable dependencies with fix suggestions

Each finding includes a severity rating, an explanation of the risk, and, for roughly 80% of findings, a one-click auto-fix that developers can apply directly from the PR comment.
Step 4: Define team-specific review rules
This is where you encode your architectural conventions, the context that AI code generators don't have. CodeAnt AI lets you define custom rules in plain English:
"All database queries must use the QueryBuilder class, never raw SQL strings"
"HTTP calls must go through the RetryableHttpClient wrapper"
"No direct imports from internal service packages outside the designated API layer"
The platform learns from past PR reviews to enforce your team's patterns. Over time, it builds a model of your codebase conventions, the missing context that makes AI-generated code review so challenging. For enterprise-scale deployments, these rules propagate across teams and repositories automatically.
Step 5: Enable Steps of Reproduction
When CodeAnt AI flags an issue, it doesn't just say "potential null reference on line 47." It provides clear reproduction steps, the exact sequence of inputs or conditions that trigger the bug, the expected behavior, and the actual behavior.
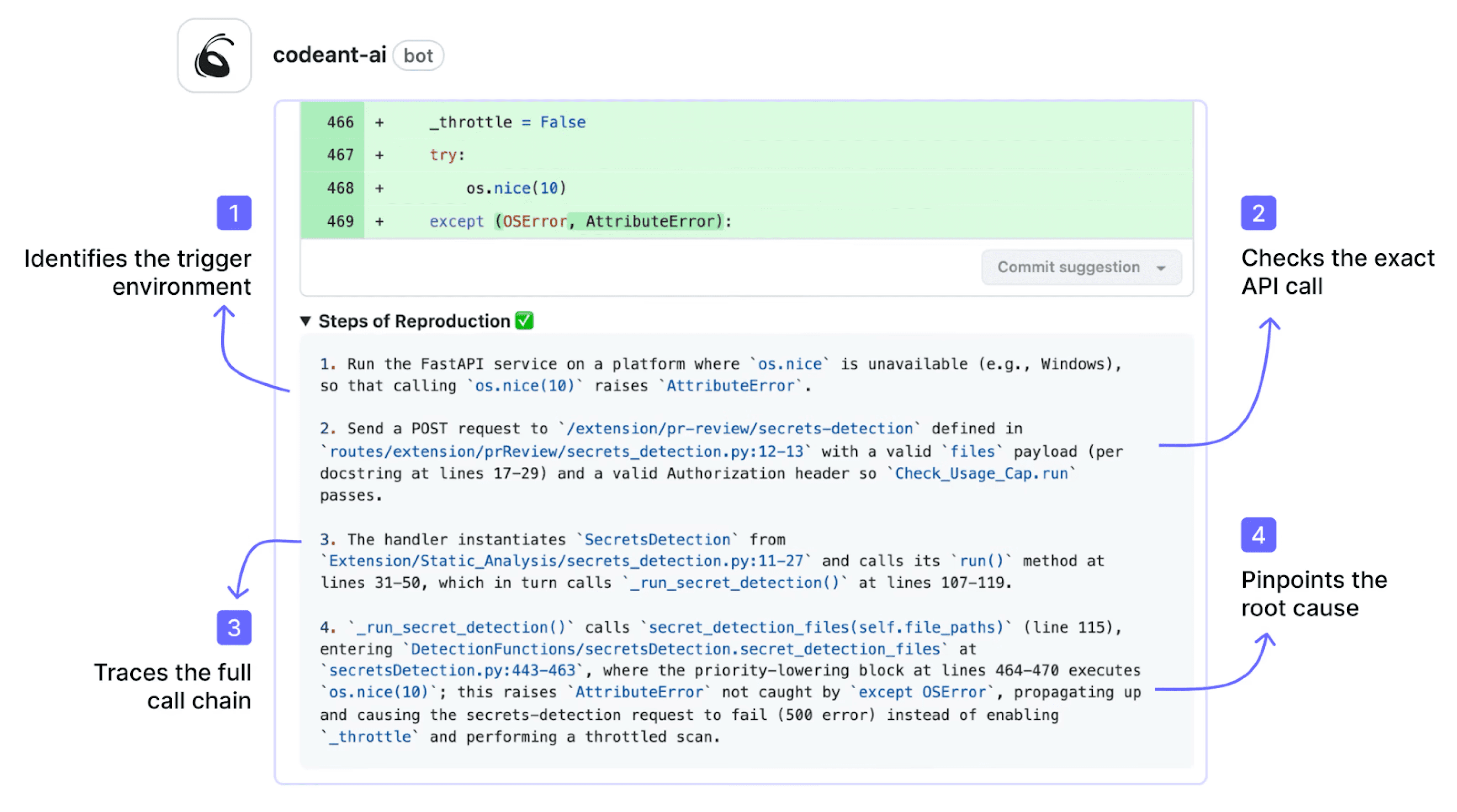
This lets developers verify findings in seconds instead of spending 15 minutes reasoning about whether a flagged issue is real.
This is CodeAnt AI's key differentiator. Most tools tell you what might be wrong. Steps of Reproduction tell you how to prove it.
How to know it's working
Deploying the pipeline is half the job. Measuring its impact is the other half. Track these metrics to know whether your automated review is actually improving code quality.
DORA metrics adapted for AI code review
The 2025 DORA report found that AI adoption "improves throughput but increases delivery instability." Track these to ensure you're getting the throughput without the instability:
Metric | What to watch | Target direction |
|---|---|---|
Deployment frequency | Should stay high or increase | ↑ Higher |
Lead time for changes | Should decrease as review bottleneck clears | ↓ Lower |
Change failure rate | The critical one — should decrease as AI code quality improves | ↓ Lower |
Failed deployment recovery time | Should stay stable or improve | ↓ Lower |
PR review cycle time | Should drop significantly (Commvault saw 98% reduction) | ↓ Lower |
AI-flagged issue resolution rate | Percentage of flagged issues devs actually fix — measures signal quality | ↑ Higher (target 60%+) |
The metrics that actually matter
Change failure rate is your north star. If you're shipping more code faster (thanks to AI generation) but your change failure rate is climbing, the review pipeline isn't catching enough. Faros AI found that bug rates increased 9% per developer with AI adoption, your review pipeline needs to bend that curve back down.
Resolution rate tells you about signal quality. If developers are ignoring 80% of flagged issues, your tool has a false positive problem. Cursor BugBot targets 70%+ resolution rate. If your rate is below 50%, tighten your rules or adjust sensitivity.
Time to first review comment measures how much bottleneck you've removed. Commvault went from 3.5 days to under 1 minute after deploying CodeAnt AI. Bajaj Finserv reduced review time from hours to seconds for 300+ developers, while simultaneously replacing SonarQube and eliminating its unpredictable lines-of-code pricing. Akasa Air flagged 900+ security issues and 100K+ quality issues across 1 million+ lines of code.
You can read more real use cases here.
For more on which metrics to track and the all-in-one guide to code review process in 2026, we maintain an updated guide.
The Review Pipeline Your AI Code Actually Needs
The volume of AI-generated code will only grow. Google's at 25%+. Teams using Copilot are already near 50%. The question isn't whether to automate review, it's whether your automation is built for AI code's specific failure modes.
The gap between AI code generation and AI code review is where bugs, vulnerabilities, and technical debt accumulate. Traditional SAST alone won't close it. Diff-only review won't close it. What closes it is a layered pipeline: deterministic scanning for known patterns, AI-native review with full codebase context, and strict quality gates that enforce standards before merge.
Start a free trial of CodeAnt AI to set up this pipeline on your repos in under five minutes. If your team has 50+ developers and needs on-prem deployment or custom MSA terms, talk to the team, they'll scope an enterprise rollout.

