Code Security
The Security Research Method: Re-Examining Old CVEs to Discover New Vulnerabilities

Sonali Sood

Founding GTM, CodeAnt AI
Security research has a strange paradox. The moment a vulnerability receives a CVE identifier and a patch is released, most of the software ecosystem considers the problem solved.
Security advisories are published.
Dependency scanners update their databases.
Developers upgrade their packages.
The vulnerability is marked “fixed.”
But in practice, that assumption is often wrong. In many cases, the patch fixes only the exact exploit that was reported, not the underlying vulnerability class. Attackers understand this. Security researchers increasingly do too.
This is why a growing number of modern vulnerability discoveries are not coming from completely new bugs.
They are coming from re-examining old CVEs.
That exact process led to the discovery of CVE-2026-28292, a critical remote code execution vulnerability in the widely used Node.js library simple-git, downloaded more than 12 million times per week.
The vulnerability was not caused by missing security controls. The controls already existed. Instead, the patch for earlier vulnerabilities left behind a subtle semantic mismatch between a security filter and the system it was protecting. Re-examining that patch revealed a bypass that allowed attackers to execute arbitrary commands on the host machine.
This article explains the security research methodology behind this discovery and why re-analyzing old CVEs is one of the most powerful techniques in modern vulnerability research.
Why Old CVEs Are a Goldmine for Security Research
When developers fix a vulnerability, they usually focus on the specific proof-of-concept exploit reported by the researcher.
That means patches are often designed to block:
the exact payload used in the exploit
the exact code path demonstrated in the report
the specific configuration scenario where the bug occurred
But attackers rarely use the exact exploit described in the report.
Instead, they ask a different question:
What other inputs reach the same vulnerable code path?
This difference in thinking is what makes old CVEs such valuable research targets.
Researchers are not starting from scratch.
They already know:
which component is sensitive
which code paths are security-critical
which inputs can influence them
That dramatically narrows the search space.
The Patch-Focused Research Strategy
Re-examining CVEs typically follows a structured process.
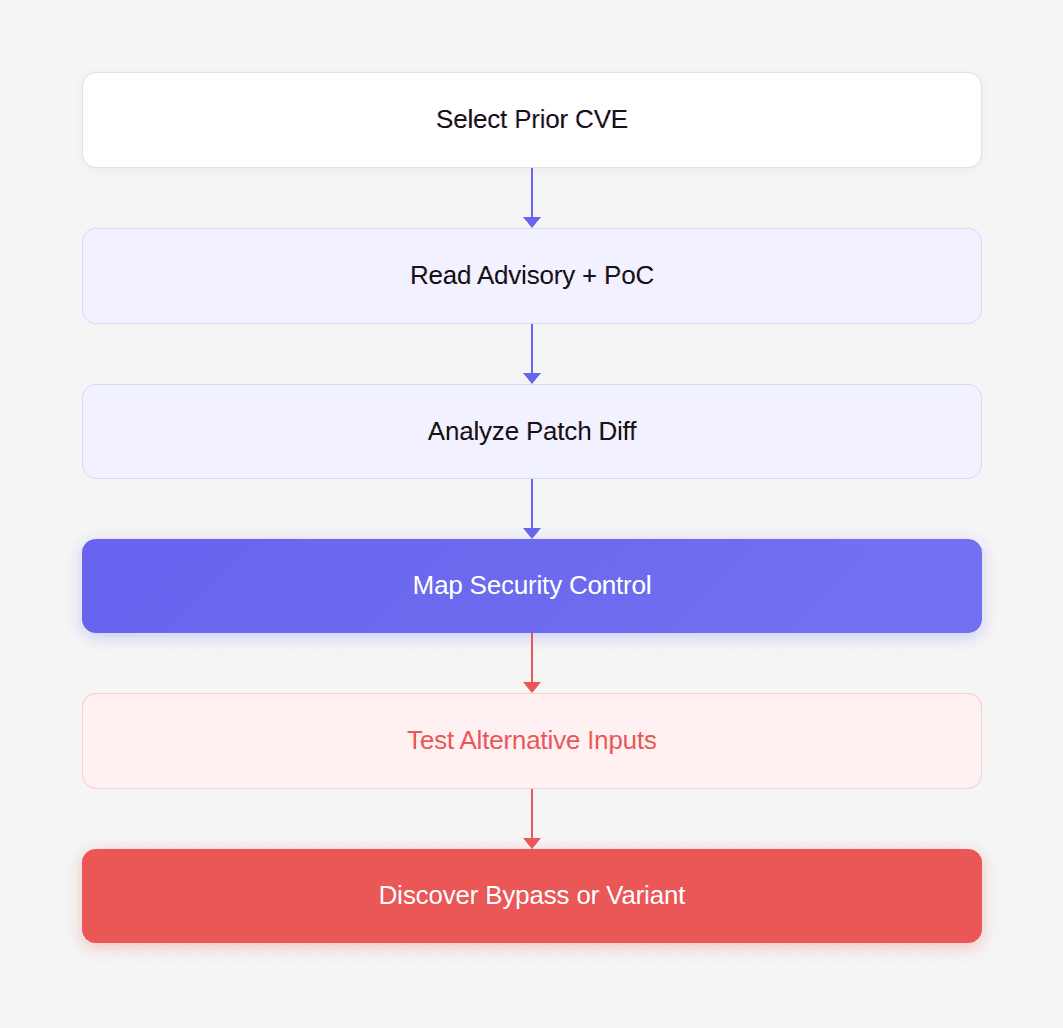
Each step reveals new opportunities to uncover hidden vulnerabilities. This process is sometimes called patch diff analysis.
Step 1: Identify Security-Sensitive Patches
The first step is selecting patches that introduce security controls.
Examples include:
input validation filters
authentication checks
protocol restrictions
sandboxing logic
command execution guards
In the case of simple-git, earlier CVEs had already revealed that Git transport protocols could be abused to execute commands. That meant any code protecting against protocol override was a high-value target for analysis.
Step 2: Study the Patch Diff
Security patches typically modify small sections of code. Those modifications reveal exactly what developers believed the problem was.
Example patch pattern:
This code was intended to block Git configuration overrides such as:
At first glance the patch looks correct. But patch diff analysis asks a different question:
What assumptions does this patch make?
Step 3: Identify Implicit Assumptions
Security patches often rely on implicit assumptions about how input behaves. In the case of CVE-2026-28292, the regex filter assumed:
configuration keys would appear in lowercase
attackers would not modify casing
Those assumptions were incorrect. Git configuration keys are case-insensitive.
Example:
Git internally normalizes the key:
That small detail turned the patch into an exploit surface.
Step 4: Model the Security Boundary
To understand how the vulnerability occurs, researchers must model the interaction between the filter and the protected system. The critical question becomes:
Does the filter enforce the same rules as the system behind it?
If the answer is no, attackers can exploit the mismatch. In CVE-2026-28292, the mismatch was simple:
Component | Behavior |
|---|---|
Regex filter | case-sensitive |
Git configuration parser | case-insensitive |
That difference allowed attackers to bypass the filter.
Step 5: Generate Variant Inputs
Once a potential mismatch is identified, researchers test variations of the original exploit.
Example variants:
Only the lowercase variant was blocked. Everything else bypassed the filter. That observation confirmed the vulnerability.
Step 6: Construct the Exploit Chain
After confirming the bypass, researchers must determine whether it leads to a real security impact. For CVE-2026-28292 the exploit chain looked like this:
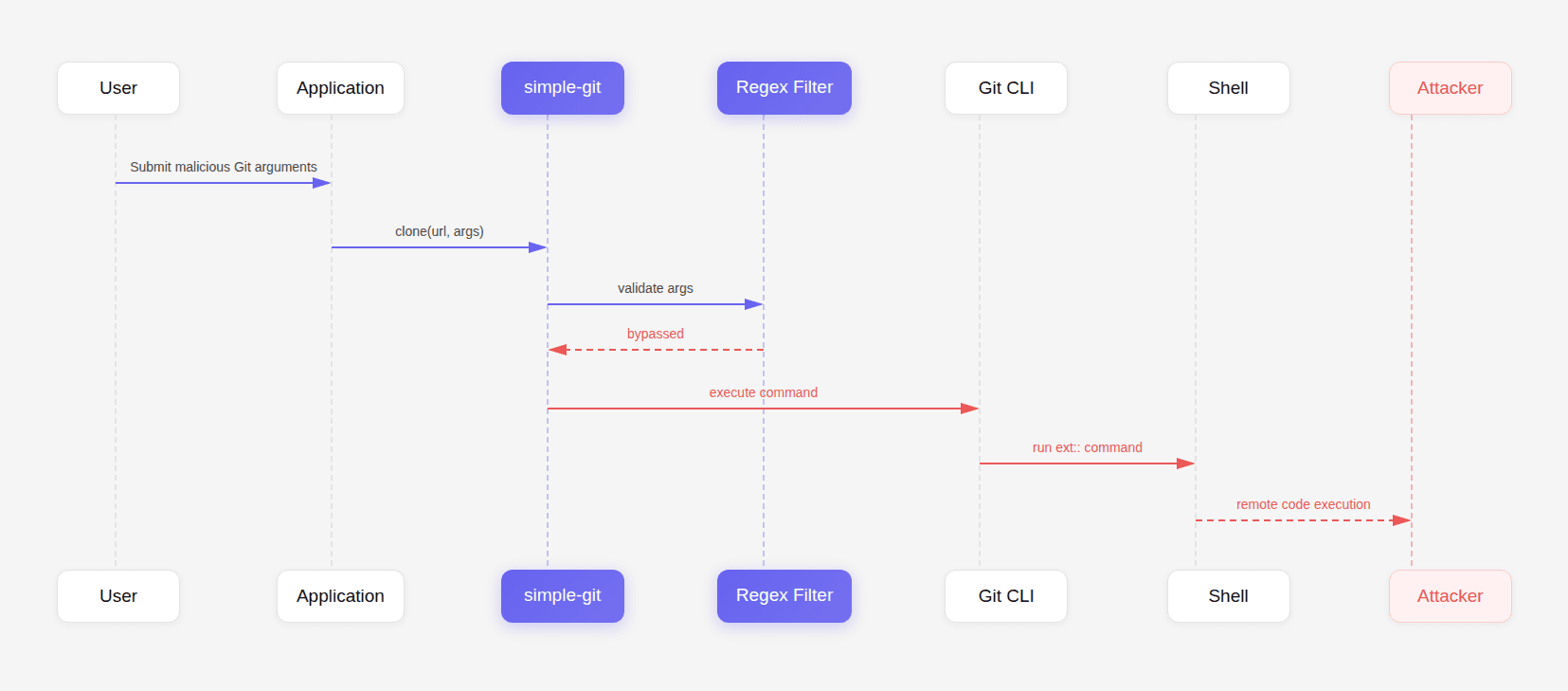
Once the ext:: transport protocol is enabled, Git executes arbitrary commands. This turns the bypass into full remote code execution.
Why Traditional Security Tools Miss These Vulnerabilities
Most automated security tools operate in one of two modes:
Dependency scanning (SCA)
Tools like:
npm audit
Dependabot
Snyk
match package versions against known CVEs.
They cannot detect vulnerabilities before the CVE is published.
Pattern-based static analysis (SAST)
Static analysis tools detect known insecure patterns.
Examples:
SQL injection
unsafe deserialization
command injection
But CVE-2026-28292 was not a known pattern.
It required reasoning about:
Git configuration semantics
regex behavior
input validation boundaries
protocol enablement
That combination is extremely difficult to express as a static rule.
Where AI-Assisted Analysis Changes the Game
The discovery of CVE-2026-28292 came from a security research program using CodeAnt AI’s code reviewer, which analyzes patches and surrounding code paths for semantic inconsistencies.
Instead of looking only for known vulnerability patterns, the AI examines whether a security control actually achieves its intended purpose. In this case, the system flagged something subtle: A case-sensitive regex guarding a case-insensitive system.
That observation triggered a deeper investigation that ultimately uncovered the RCE vulnerability. This approach represents a fundamental shift in code review. For years, automated code review tools have focused on improving developer productivity through style suggestions and minor refactoring advice.
But the real value of code review lies in something far more important. Stopping the one pull request that introduces a catastrophic vulnerability. That is where AI-assisted reasoning is beginning to make a difference.
Why Security Researchers Are Increasingly Auditing Patches
Patch analysis is becoming one of the most productive vulnerability discovery methods for several reasons.
The attack surface is already mapped: The original CVE tells researchers where the sensitive code paths are.
Patches are often minimal: Developers frequently implement the smallest change necessary to block the reported exploit.
Security assumptions are fragile: Small differences in encoding, normalization, or parsing behavior can invalidate a patch.
Complex systems behave differently than expected: Libraries often interact with external tools, operating systems, or protocols that behave in subtle ways.
These factors create opportunities for bypasses.
Common Patch Bypass Patterns
Researchers frequently encounter the same classes of bypasses.
Pattern | Example |
|---|---|
Case sensitivity mismatch | CVE-2026-28292 |
Encoding bypass | URL encoding or Unicode variants |
Alternate input path | different API endpoint |
Logic gap | conditional edge case |
Partial validation | only first parameter checked |
Understanding these patterns dramatically increases the likelihood of finding new vulnerabilities.
Practical Workflow for Auditing Old CVEs
Developers and researchers can replicate this methodology.
Step 1: Collect recent CVEs affecting your ecosystem.
Step 2: Study the patch diff.
Step 3: Identify assumptions in the validation logic.
Step 4: Test variations of the original exploit.
Step 5: Analyze interactions with external systems.
Step 6: Attempt to construct a new exploit chain.
This process often reveals surprising vulnerabilities.
Conclusion: Why Revisiting Old CVEs Is One of the Most Powerful Research Techniques
The discovery of CVE-2026-28292 illustrates a broader reality about software security. Vulnerabilities rarely disappear after a patch is released.
They evolve.
Patches fix the exact exploit that was reported, but attackers rarely reuse that exact exploit. Instead, they look for small variations in the assumptions behind the fix.
A different encoding.
A different casing.
A different input path.
Those variations often reopen the vulnerability. This is why modern security research increasingly focuses on re-examining existing fixes rather than hunting only for completely new bugs.
And this is also where automated code review is beginning to evolve. The most valuable code review tools will not be the ones that generate the most style suggestions. They will be the ones capable of reasoning about how code behaves across multiple systems and detecting the subtle mismatches that lead to real vulnerabilities.
During internal research, CodeAnt AI’s code reviewer flagged the patch logic that eventually led to the discovery of CVE-2026-28292, demonstrating how AI-assisted reasoning can uncover vulnerabilities hiding inside already-patched code. That capability represents an important shift in how we think about code review.
Not as a tool for polishing code. But as a tool for discovering the vulnerabilities nobody has noticed yet.
FAQs
Why do many vulnerabilities get rediscovered after a patch is released?
What makes old CVEs particularly valuable targets for security research?
How did CVE-2026-28292 bypass previous security fixes?
Why do traditional static analysis tools struggle to detect vulnerabilities like this?
How can developers incorporate patch analysis into their own security practices?













