AI Code Review
CodeAnt AI Ranks #1 in Security Patch Detection Benchmark

Sonali Sood

Founding GTM, CodeAnt AI
CODEANT AI · BENCHMARK ANALYSIS
Security patches are one of the most difficult problems for automated code review systems.
They rarely look like obvious vulnerabilities.
Most security patches are small code changes buried inside otherwise normal pull requests. The change may be a single conditional check, an escaping function, or a subtle modification to a validation rule.
To detect them, a review system must understand:
the intent of the patch
the vulnerability it prevents
the surrounding code context
This is why many automated review tools struggle with security patch analysis.
In Martian’s independent AI code review benchmark, which evaluated 17 tools across real pull requests, CodeAnt AI ranked #1 in detecting security patch issues.
The benchmark results are publicly available here: https://codereview.withmartian.com/?model=anthropic_claude-opus-4-5-20251101&mode=offline&change_type=security_patch
This article explains:
why security patch detection is difficult
how the benchmark evaluates this category
why CodeAnt ranked first
what this means for modern AI code review tools
Security Patch Detection Is Harder Than It Looks
When developers hear “security bug,” they often imagine obvious problems:
SQL injection
command injection
insecure deserialization
But most real-world security fixes are far more subtle.
A typical patch might involve something like:
Before the patch, the code may have allowed arbitrary host values.
The change looks trivial.
But in reality it prevents a server-side request forgery vulnerability.
Automated tools must detect that the change is security-related, understand why the validation matters, and determine whether the logic is correct.
This requires reasoning about:
data flow
control flow
security context
input validation
trust boundaries
Traditional rule-based static analyzers often miss these patterns because the issue is not always visible in a single file or function.
AI code review tools attempt to solve this by analyzing code context and developer intent.
But even among AI systems, performance varies widely.
Benchmark Results: Security Patch Detection
Martian’s benchmark isolates pull requests that contain security patch changes and evaluates how well different AI review tools identify them.
The leaderboard for this category shows a clear result.
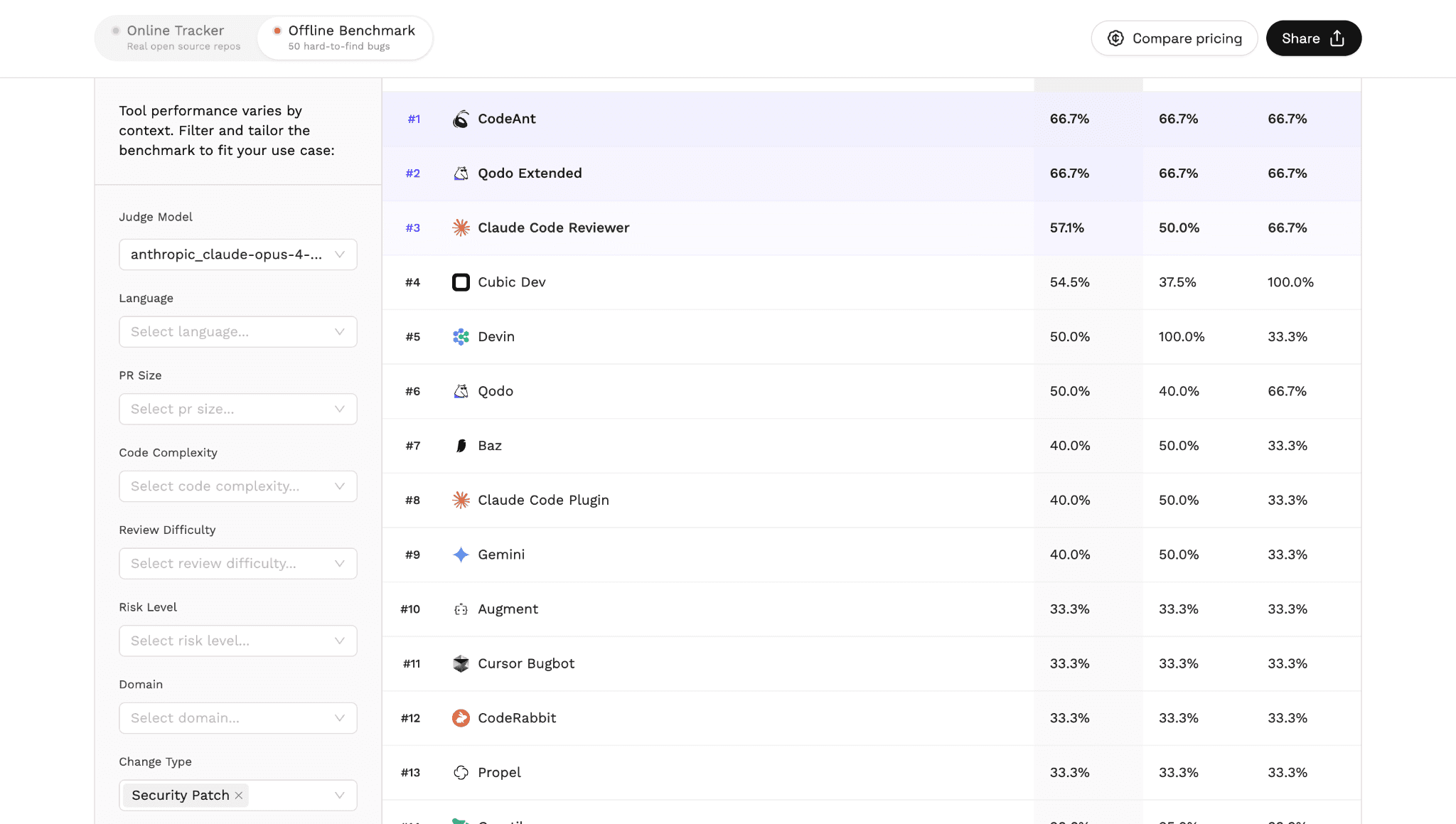
CodeAnt AI ranked #1 in detecting security patch issues.
The benchmark evaluates tools using:
precision
recall
F1 score
These metrics measure how accurately tools identify security-related changes without overwhelming developers with unnecessary alerts.
Unlike synthetic vulnerability datasets, this benchmark evaluates real pull requests from real repositories, making the results far more representative of real engineering workflows.
Why Security Patch Detection Is Difficult for AI Tools
Security patches challenge automated systems for several reasons.
1. The vulnerability may no longer exist in the code
In many cases the patch removes the vulnerable code. A review tool must infer what the vulnerability was before the fix.
2. The change may appear unrelated
Many security fixes look like ordinary refactoring or validation improvements. Without context, the significance of the change can be missed.
3. The vulnerability may depend on application logic
Some issues only become visible when multiple components interact. For example:
authentication checks
permission validation
input sanitization
cryptographic usage
This complexity is why security patch detection is a meaningful benchmark category.
Why CodeAnt Ranked First
In the benchmark results, CodeAnt ranked ahead of all other evaluated tools in detecting security patch issues. Several technical factors likely contribute to this performance.
Context-aware code analysis
CodeAnt analyzes code with repository context rather than evaluating isolated files. This allows the system to detect how changes affect application behavior.
Data flow understanding
Security patches often modify the flow of user input through a system. Analyzing these flows helps identify when a patch addresses a vulnerability.
Intent inference
Many patches communicate intent through commit messages or code comments. AI review systems that incorporate these signals can better understand the purpose of a change.
Balanced precision and recall
Security review tools often fail in one of two ways:
flagging too many false positives
missing real issues
The benchmark shows that CodeAnt maintains a balance between both metrics in this category.
Why Security Patch Detection Matters for Engineering Teams
Security patches are one of the most critical events in a software repository. When developers submit a patch addressing a vulnerability, reviewers must confirm that:
the vulnerability is actually fixed
the patch does not introduce new issues
the change covers all attack paths
Missing a flawed patch can leave systems exposed even after the fix is merged. Automated code review tools can help reviewers by surfacing:
incomplete validation logic
missing sanitization paths
incorrect assumptions about inputs
potential bypass scenarios
Detecting these issues early in the pull request stage prevents vulnerabilities from reaching production.
Security Patch Detection Is Only One Benchmark Category
While security patch detection is an important capability, it is only one dimension of automated code review performance. The Martian benchmark also evaluates tools across other domains, including:
testing issues in pull requests
logging and PII leak detection
large pull request review
CodeAnt also ranks highly in several of these categories.
You can explore the full benchmark here:
→ AI Code Review Benchmark Overview
Additional benchmark breakdowns:
→ Testing Issue Detection Benchmark
→ Logging and PII Leak Detection Benchmark
→ Large Pull Request Review Benchmark
Together these analyses provide a more complete picture of how different AI systems perform across real engineering scenarios.
What This Benchmark Tells Us About AI Code Review
The results reveal an important insight. Automated code review is no longer just about style checks or static analysis. Modern AI review systems are beginning to reason about:
developer intent
application behavior
security implications
Security patch detection is one of the clearest demonstrations of this shift.
Instead of matching patterns, systems must understand why a patch exists and what problem it solves.
Benchmarks like Martian’s provide the first real dataset showing how well current tools are approaching that goal.
The Hardest Security Bugs Are the Ones Hidden in Patches
Security vulnerabilities rarely appear as obvious mistakes. More often, they hide inside subtle logic errors that are only visible once developers attempt to fix them.
Detecting those fixes correctly requires understanding code context, developer intent, and application behavior.
In Martian’s independent benchmark evaluating AI code review tools across real pull requests, CodeAnt AI ranked #1 in security patch detection. That result highlights a broader shift in automated code review. The next generation of tools will not just detect obvious bugs. They will understand why code changes matter.
If you want to see how CodeAnt analyzes security-related pull requests in your own repository, you can install it in minutes and start reviewing pull requests immediately.
FAQs
What is security patch detection in code review?
Why are security patches difficult for AI code review tools?
How did CodeAnt rank #1 in the benchmark?
Why is detecting security patches important during pull request review?
Where can I see the full benchmark results?













