AI Code Review
CodeAnt AI Ranks #2 in Large Pull Request Review Benchmark

Sonali Sood

Founding GTM, CodeAnt AI
CODEANT AI · BENCHMARK ANALYSIS
Small pull requests are relatively easy to review. A reviewer can quickly read the changes, understand the intent, and identify potential issues. Large pull requests are a completely different problem.
When a pull request modifies dozens of files, hundreds of lines of code, or multiple modules of a system, understanding the change requires reconstructing a much larger context. This challenge affects both human reviewers and automated systems.
In Martian’s independent AI code review benchmark, which evaluated 17 tools across real pull requests, CodeAnt AI ranked #2 in reviewing medium and large pull requests.
The benchmark results for this category are available here: https://codereview.withmartian.com/?model=anthropic_claude-opus-4-5-20251101&mode=offline&pr_size=large%2Cmedium
This article explains:
why large pull requests are difficult to review
how the benchmark evaluates large PR analysis
what the results reveal about AI code review capabilities
why CodeAnt performed strongly in this category
Why Large Pull Requests Are Difficult to Review
Large pull requests introduce a fundamental challenge. The reviewer must understand not only individual lines of code but also how the entire change affects the system.
A large PR may include:
multiple feature changes
refactoring across modules
database schema modifications
updates to tests and configuration
Understanding these changes requires reconstructing the developer’s intent and evaluating the impact across the codebase.
For automated systems, the problem is even more complex. Large PRs require the system to analyze:
many files simultaneously
long-range dependencies
interactions between different modules
Traditional static analysis tools often treat files independently, which limits their ability to evaluate cross-file changes. AI code review systems attempt to solve this by analyzing the broader context of the change.
Common Issues Found in Large Pull Requests
Large pull requests often contain subtle issues that are easy to overlook.
Hidden logic regressions
When multiple functions are modified simultaneously, small changes in one file can break behavior elsewhere.
Example:
If a refactor modifies how isAdmin() works, code relying on the original behavior may break in unexpected ways.
Incomplete refactors
During large refactors, developers may update most occurrences of a function or variable but miss some instances. This can introduce inconsistencies that only appear at runtime.
Dependency mismatches
Large PRs sometimes update libraries or internal dependencies. These updates can introduce subtle incompatibilities.
Unintended side effects
A change designed to improve one feature may affect other parts of the system that rely on the original behavior. Because these dependencies may exist across multiple files, they are difficult to detect through simple code inspection.
Benchmark Results: Large Pull Request Review
Martian’s benchmark evaluates how well AI code review tools analyze pull requests of different sizes. The medium and large PR category specifically measures how systems perform when analyzing complex changes affecting multiple parts of a codebase.
The leaderboard for this category shows the following results.
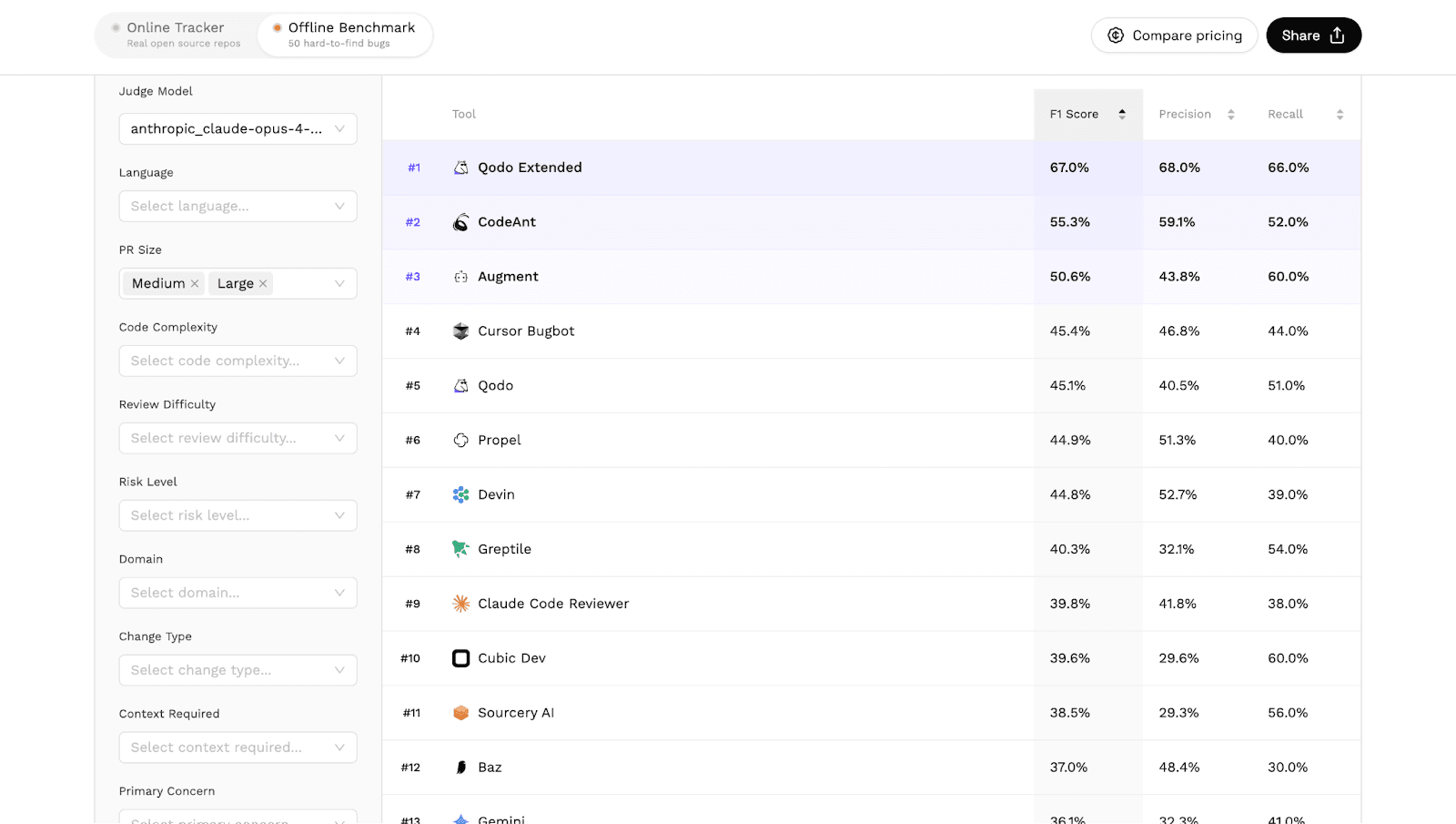
In this category:
CodeAnt AI ranked #2 among all evaluated AI code review tools.
The benchmark evaluates tools using metrics such as:
precision
recall
F1 score
These metrics measure how accurately tools identify meaningful issues in complex pull requests without overwhelming developers with unnecessary comments.
Because the benchmark uses real pull requests from real repositories, the results reflect real-world code review scenarios rather than artificial datasets.
Why Large PR Analysis Is an Important Capability
Many development teams encourage smaller pull requests to simplify review. However, large pull requests remain common in real projects.
Examples include:
feature launches
architectural refactors
dependency upgrades
codebase migrations
In these situations, reviewers must understand complex changes spanning multiple components. Automated review tools can help by highlighting potential issues across the entire pull request. This capability becomes particularly valuable when:
the codebase is large
the reviewer is unfamiliar with the affected modules
the pull request introduces structural changes
Tools capable of analyzing large PRs effectively can significantly reduce review time while improving code quality.
How AI Code Review Helps Analyze Large Changes
AI-based review systems are better suited for large PR analysis than traditional static analysis tools. Instead of evaluating files independently, AI systems can analyze the relationships between different parts of the code.
For example, an AI system can reason about:
how a function change affects other modules
whether a refactor alters existing behavior
whether tests still validate the intended functionality
This ability to reason across multiple files allows AI review systems to surface issues that may otherwise remain hidden.
Why CodeAnt Performed Strongly in This Category
In the medium and large PR benchmark category, CodeAnt ranked second among evaluated tools. This result suggests strong performance in several key capabilities.
Cross-file reasoning
Understanding how changes across multiple files interact.
Context-aware analysis
Evaluating code changes within the broader structure of the repository.
Issue prioritization
Surfacing meaningful problems without overwhelming reviewers with excessive comments.
These capabilities are essential for analyzing complex pull requests where many parts of the system are affected simultaneously.
Large Pull Requests Are Only One Dimension of the Benchmark
The Martian Code Review Bench evaluates AI code review systems across multiple categories.
These include:
security patch detection
testing issue detection
logging and PII leak detection
large pull request analysis
Each category highlights different aspects of automated review performance.
For a complete overview of the benchmark, see:
→ AI Code Review Benchmark Overview
Additional analyses:
→ Security Patch Detection Benchmark
→ Testing Issue Detection Benchmark
→ Logging and PII Leak Detection Benchmark
→ Large Pull Request Review Benchmark
Together these analyses illustrate how AI systems perform across a range of real development scenarios.
What This Benchmark Reveals About AI Code Review
Reviewing large pull requests has always been one of the most time-consuming parts of software development. Human reviewers must reconstruct the context of the change, understand how multiple components interact, and determine whether the modification introduces new issues.
The Martian benchmark demonstrates that modern AI systems are increasingly capable of assisting with this process. While no tool can fully replace human review, systems that effectively analyze complex pull requests can significantly improve the efficiency and reliability of the review process.
The Hardest Reviews Are the Largest Ones
Large pull requests introduce complexity that can overwhelm even experienced reviewers.
Multiple files, cross-module changes, and hidden dependencies make it difficult to fully understand the impact of a change. Automated review systems can help by surfacing issues that might otherwise remain unnoticed.
In Martian’s independent benchmark evaluating AI code review tools across real pull requests, CodeAnt AI ranked #2 in analyzing medium and large pull requests.
This result highlights the growing ability of AI systems to reason about complex code changes and assist developers during large-scale reviews. If you want to see how CodeAnt analyzes complex pull requests in your own repositories, you can install it and start reviewing pull requests within minutes.
FAQs
Why are large pull requests harder to review?
How does AI code review help with large pull requests?
What does CodeAnt’s #2 ranking in the benchmark indicate?
Why are large pull requests common in real projects?
Where can I see the full benchmark results?













