AI Pentesting
What is AI Penetration Testing? Our Complete 2026 Guide

Sonali Sood

Founding GTM, CodeAnt AI
Before "AI pentesting" means anything, the word "penetration testing" has to mean something precise.
Penetration testing, often shortened to pentesting or pen test, is the practice of deliberately attacking a system with the same tools, techniques, and objectives as a real adversary, in order to find exploitable vulnerabilities before someone else does. The key word is exploitable. Not theoretical. Not "this header is missing." Exploitable, meaning a real attacker, with real intent, could use this to extract data, escalate privileges, or cause damage.
The discipline has existed since the 1960s, when the US Department of Defense ran "tiger teams" tasked with breaking into mainframes to expose security gaps. The concept is simple: the best way to know if your defenses hold is to test them against a real attack.
What's changed since the 1960s is everything else. Applications are now distributed across dozens of microservices, served from cloud infrastructure you don't fully control, updated multiple times per day, and exposed through hundreds of API endpoints that didn't exist last quarter. The attack surface of a modern SaaS product is orders of magnitude more complex than anything a tiger team was probing in 1967.
That complexity is the problem penetration testing is trying to solve in 2026. And it's why the traditional model, a consultant with Burp Suite and a week on-site, is no longer sufficient, and why AI-driven approaches are becoming the standard for teams that are serious about security.
Why the Traditional Penetration Testing Model is Broken
Here is the incentive structure of traditional penetration testing.
A company hires a firm for $10,000–$40,000. Both parties negotiate down to something everyone can live with. The firm assigns a consultant with Burp Suite and a two-week window. Both parties want the same outcome: a green report, delivered fast, with no critical findings that would require re-testing before submission to a SOC 2 auditor or enterprise customer.
The firm gets paid whether they find critical vulnerabilities or not. The company gets its compliance checkbox. Nobody in this transaction is financially incentivized to find the issue that would actually cause a breach.
This is how a $1.5 billion industry operates today. And it is why companies that have passed annual penetration tests are still getting breached.
The problem is not the testers. It is the model.
Consider this real scenario. Three findings come back from an engagement:
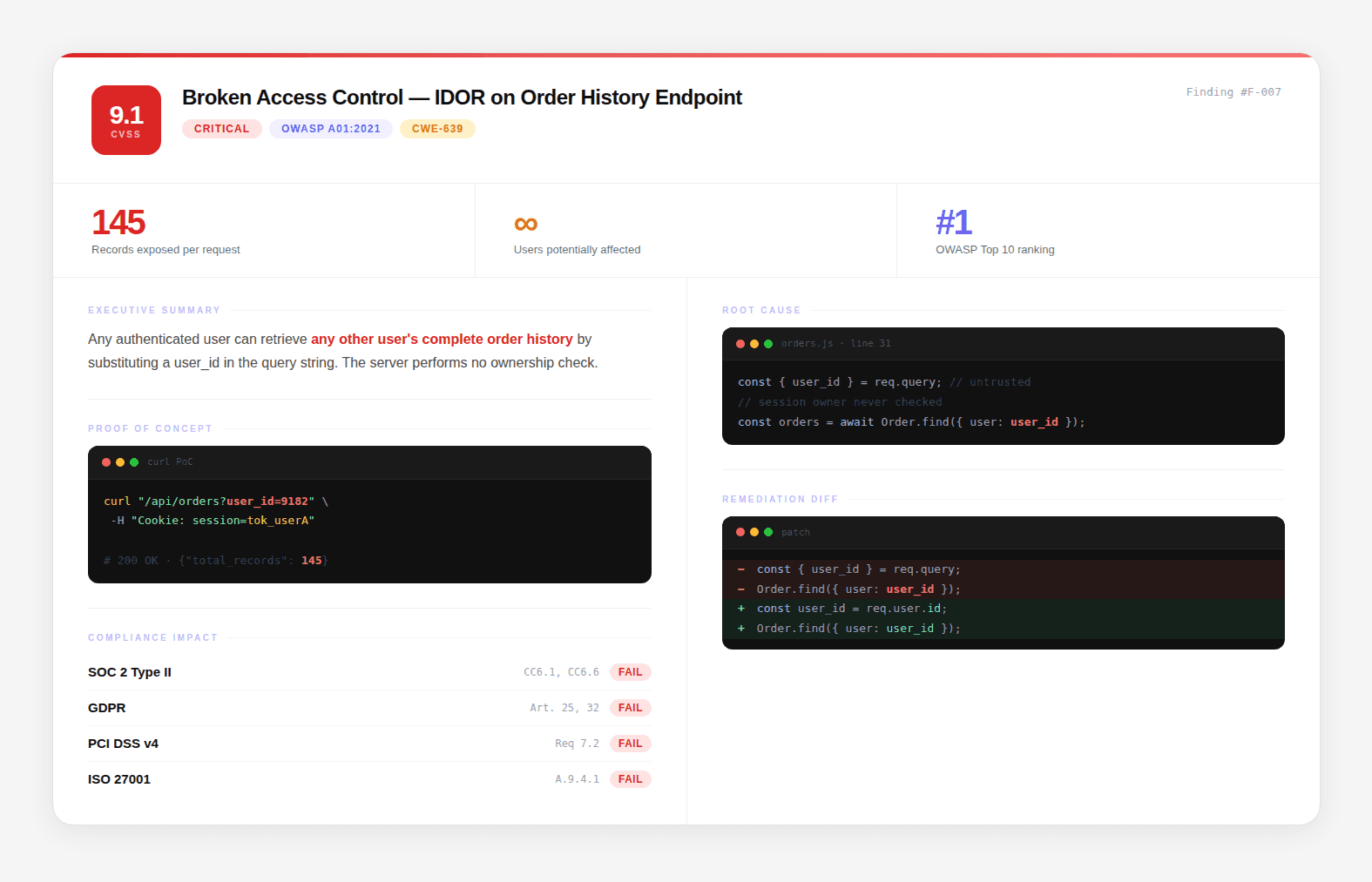
Finding A: Broken object-level authorization on
/api/orders/{id}. No ownership check. Any authenticated user can pass any order ID and get a response. CVSS 6.5.Finding B: Order IDs are sequential and predictable. The full ID space can be enumerated in under 40 seconds. CVSS 5.9.
Finding C: Database queries return rows across all tenants when no tenant scope is applied. Missing filter at the data layer. CVSS 4.1.
Your engineering team puts all three in the backlog. Medium severity. Fix when we get to it.
Chained together: an attacker authenticates as any user, enumerates the full order ID space in 40 seconds, and reads 1.8 million order records across every tenant in the system. Customer names, addresses, payment details, order histories. A full cross-tenant data breach from three findings that would never have been prioritized individually.
Combined CVSS: 9.1. Critical.
Traditional pentesting misses this because it reports findings in isolation. Real attackers do not exploit findings in isolation.
This is the gap AI penetration testing was built to close.
What is AI Penetration Testing?
AI penetration testing is penetration testing where the analysis, reconnaissance, code reading, dataflow tracing, and exploit chain construction are performed by an AI reasoning engine, with security researchers validating findings, handling edge cases, and conducting the remediation walkthrough.
The distinction from traditional pentesting is not "automated vs manual." It is depth of analysis per unit of time.
A human tester looking at an Express.js application might check the obvious middleware configuration, test a handful of endpoints for common auth bypass patterns, and move on. An AI reasoning engine reads the complete middleware stack, traces every route's auth chain from HTTP entry to controller, identifies every path where the chain is broken or inconsistently applied, and does this for the entire application in hours rather than days.
The distinction from scanners is semantic understanding vs pattern matching.
A scanner looks at your application's HTTP responses and asks: does this response look like a known vulnerability pattern? An AI pentesting engine reads your source code and asks: given how this code actually works, the specific middleware stack, the specific auth configuration, the specific data flows, what could a motivated attacker do?
That difference in the question produces a fundamentally different category of findings.
How the AI Reasoning Engine Works
Here is the technical process, step by step:
1. Application Model Construction
The AI builds a complete structural model of the application: every endpoint and the HTTP methods it accepts, every parameter and the type of input it expects, every authentication requirement and how it's enforced, how components communicate internally, what external services are called and with what data.
This isn't static analysis in the traditional sense. It's semantic understanding the AI knows that /api/v2/users/{id}/orders accepts a GET request, requires a Bearer token, expects id to be a UUID, and returns the order history for the user whose ID matches the path parameter. That semantic model is what makes downstream analysis meaningful.
2. Trust Boundary Identification
A trust boundary is any point where the application accepts external input and makes a decision based on it. Where does user-supplied data enter the system? Where does the application trust a value from a client request? Where does it make implicit assumptions about who's calling, assuming, for example, that anyone who can reach /api/admin/users must be an administrator?
Trust boundaries are where security breaks. The AI systematically maps them.
3. Dataflow Tracing
For each trust boundary, the AI traces the data forward through the application, through every function call, every ORM method, every serialization step, every downstream API call, to its final destination.
Consider a Django application with this view:
And this URL configuration:
An external scanner sees a 200 response from /api/docs/1234/ with valid credentials and flags nothing. A dataflow trace catches that the authentication middleware doesn't cover this route, there's no @login_required decorator on the view, and the URL pattern is outside the middleware's configured scope. The endpoint is publicly accessible. Every document ID is reachable by anyone.
4. Attack Chain Construction
Every confirmed finding is evaluated against every other confirmed finding. The AI's question is: given everything I've now confirmed about this application, what's the highest-impact path I can construct?
Example chain:
Neither finding alone warrants urgent escalation. Together, they represent a complete tenant isolation failure.
5. Exploitation and Quantification
Every chain that reaches a sensitive data outcome is exploited with a working proof-of-concept. Records are counted. Data types are classified (PII, PHI, financial data, credentials). Regulatory exposure is assessed. Business impact is quantified in terms the board and the auditor both understand.
What a Real AI Pentest Report Contains
The report is the deliverable. It's what you act on, what you hand to your auditor, and what engineers use to remediate. A good report is an evidence package. A bad report is a PDF with a list of CVEs and a link to OWASP.
Here is what every finding in a real report should contain:
Finding Title and Severity: A precise, descriptive title and CVSS 4.0 score. Not "SQL Injection," "Unauthenticated SQL Injection in Product Search Endpoint Exposing Complete Product Database via Category Parameter."
Executive Summary: One paragraph. Business impact, not technical description. "An unauthenticated attacker can retrieve the name, price, and internal cost of every product in the database by manipulating the category search parameter. This exposes commercially sensitive pricing data to any external party."
Proof of Concept: A working reproduction, a curl command, a Python script, or browser reproduction steps. Any engineer on your team should be able to run it and reproduce the finding in under 5 minutes.
Root Cause: File, Class, Method, Line Not "authentication is missing." The exact location in the codebase where the vulnerability exists.
Remediation: Specific Diff Not "implement input validation." The exact code change that closes the vulnerability:
Compliance Mapping Which specific controls this finding affects:
Standard | Control | Status |
|---|---|---|
SOC 2 | CC6.1, Logical and physical access controls | Fails |
PCI-DSS | Requirement 6.2.4, Software development practices | Fails |
OWASP Top 10 | A03:2021, Injection | Affected |
The Research Credibility That Backs the Methodology
Methodology claims are easy to make. Verifiable research is not. CodeAnt AI's researchers have published 87+ CVEs across npm, PyPI, Maven, and NuGet ecosystems, packages with a combined 1.85 billion monthly downloads. Every CVE has an assigned number, publicly searchable in the National Vulnerability Database.
Selected findings:
CVE | Package | CVSS | Vulnerability Type | Impact |
|---|---|---|---|---|
CVE-2026-29000 | pac4j-jwt | 10.0 | Full authentication bypass | Access any account without credentials |
CVE-2026-28292 | simple-git | 9.8 | Arbitrary command execution | RCE via crafted repository URLs |
MSRC (AutoGen Studio) | AutoGen Studio | 9.8 | Remote code execution (CWE-78) | Shell command injection |
MSRC (AutoGen FunctionTool) | AutoGen | 9.1 | Code execution (CWE-94) | Arbitrary code via function tool |
The significance of this track record is not the number. It's what the number proves: the AI reasoning engine that produces these findings is applied, with full source code access, to your codebase. It finds CVSS 10.0 vulnerabilities in production software that major security scanners did not flag before CVE assignment.
The Vulnerability Landscape: What Attackers Are Actually Exploiting
To understand why penetration testing exists, you need to understand what vulnerabilities actually look like in production systems. They are rarely the obvious things. They are almost always the subtle ones.
How Vulnerabilities Are Classified
The security industry uses the Common Vulnerability Scoring System (CVSS) to rate the severity of discovered vulnerabilities on a 0–10 scale. The current version is CVSS 4.0.
CVSS Score Range | Severity | What It Typically Means |
|---|---|---|
0.0 | None | No security impact |
0.1 – 3.9 | Low | Minimal real-world risk, usually requires unusual conditions |
4.0 – 6.9 | Medium | Exploitable under specific conditions, requires some attacker effort |
7.0 – 8.9 | High | Significant impact, relatively straightforward exploitation |
9.0 – 10.0 | Critical | Remote exploitation, no authentication required, complete data exposure |
A CVSS 10.0 vulnerability means: anyone on the internet, with no credentials and no prior knowledge, can fully compromise your system. These exist in production software right now. Some of them are in packages your application depends on.
CVSS scores are calculated from a set of base metrics:
Metric | What It Measures |
|---|---|
Attack Vector | Network / Adjacent / Local / Physical — how far away can the attacker be? |
Attack Complexity | Low / High — how much work does exploitation require? |
Privileges Required | None / Low / High — what access does the attacker need to start? |
User Interaction | None / Required — does a victim need to click something? |
Scope | Unchanged / Changed — can the impact spread beyond the vulnerable component? |
Confidentiality Impact | None / Low / High — can data be read? |
Integrity Impact | None / Low / High — can data be modified? |
Availability Impact | None / Low / High — can the service be disrupted? |
A finding that scores Network / Low / None / None / Changed / High / High / High hits CVSS 10.0. A real example: CVE-2026-29000 in pac4j-jwt, a full authentication bypass in a widely used Java security library where an attacker could craft a JWT token that bypassed all authentication checks without valid credentials. CVSS 10.0. Affects packages with hundreds of millions of monthly downloads.
The Categories That Cause Actual Breaches
Understanding CVSS is important, but the more operationally important thing is understanding what types of vulnerabilities cause real-world breaches. They fall into patterns:
Broken Access Control: The #1 category in the OWASP Top 10. This includes IDOR (Insecure Direct Object References), where changing a user ID or order ID in a request returns another user's data. It includes privilege escalation, calling an admin endpoint with a standard user token. It includes JWT claim manipulation, modifying your own token to elevate your role. These vulnerabilities don't look broken from the outside. They look like normal API calls returning 200 OK.
Injection: SQL injection, command injection, template injection. These exist when user-controlled input reaches an interpreter without sanitization. Classic SQL injection looks like this in vulnerable code:
An attacker supplies ' OR '1'='1 as the email, turning the query into SELECT * FROM users WHERE email = '' OR '1'='1' — which returns every user record in the database.
The safe version uses parameterized queries:
The vulnerability is in the code. A scanner might find it if the response pattern changes noticeably. An AI pentesting engine finds it by tracing the input, wherever it enters the application, forward to every database call it reaches.
Authentication Flaws: Broken JWT validation, session fixation, authentication bypass via middleware misconfiguration. The most dangerous ones produce no anomalous HTTP responses. They look correct from the outside.
Security Misconfiguration: Exposed admin panels, default credentials, misconfigured cloud storage buckets, overly permissive CORS policies, secrets committed to version control. These are the finding categories that produce the most embarrassing breaches, not because they're sophisticated, but because they're invisible if nobody's looking.
Business Logic Vulnerabilities: The category that no scanner touches. These require understanding what your application is supposed to do. Calling step 5 of a checkout flow directly without completing steps 1–4. Reusing a single-use discount code. Manipulating a price field before payment confirmation. Bypassing a rate limiter by rotating request parameters.
Penetration testing exists to find all of these, in the context of your specific application, before a real attacker does.

How CodeAnt AI Conducts a Penetration Test: The 7-Phase Methodology
Most AI pentesting vendors describe their methodology in marketing language. Here is what actually happens, phase by phase, in a CodeAnt AI engagement.
Phase 1: Reconnaissance and Attack Surface Mapping
Starting from your domain name only. No credentials, no architecture diagrams handed over by your team.
Certificate transparency logs surface subdomains you may have forgotten exist. Internet-wide scan databases identify infrastructure your security team may not know is exposed. DNS records are checked for dangling entries that could enable subdomain takeover. CORS policies, HTTP security headers, TLS configuration, and email security posture, all evaluated before a single line of code is touched.
In a recent engagement with a major Indian utility company, this phase discovered three public-facing Swagger specifications exposing 131 undocumented API endpoints, a SAP NetWeaver 7.50 instance reachable from the internet, and a CORS configuration that reflected any origin with credentials. None of these were in scope when the engagement started, because the client did not know they existed.
Phase 2: Source Code Intelligence
If source code is provided, or discovered through exposed JavaScript bundles, source maps, or public repositories, our agents perform deep analysis. This is not a SAST scanner checking for SQL injection patterns.
Six detection methodologies run in parallel: taint analysis tracing user-controlled data to dangerous sinks, path traversal through string manipulation, regex checks with missing flags or catastrophic backtracking, vulnerable library patterns, numeric edge cases, and end-of-life dependency risks. Full software composition analysis, hardcoded secrets scanning, and infrastructure configuration review, covering container definitions, K8s manifests, CI/CD pipelines, and cloud provider configs, run on every engagement.
Phase 3: JavaScript Bundle Intelligence
Modern web applications ship enormous JavaScript bundles to the browser containing information developers never intended to make public. Our agents download every bundle from every endpoint discovered in Phase 1 and extract: cloud infrastructure URLs, internal API endpoints, serverless function URLs, storage bucket identifiers, authentication configuration details, feature flag states, admin route definitions, and hardcoded credentials.
In one engagement, this phase extracted the full source code of an application including 219 internal API endpoints, 35 carrier configurations, and a complete RBAC model, all from publicly served JavaScript bundles that included source maps. The development team had no idea source maps were being shipped to browsers.
In another engagement, we extracted 26,000 CRM contact records including names, titles, and company affiliations for employees at Fortune 500 companies, embedded directly in a client-facing JavaScript bundle.
Phase 4: Targeted Test Queue Construction
After reconnaissance, source code analysis, and bundle intelligence, agents build a prioritized queue of every test to run against live infrastructure. Every test is informed by what was found in Phases 1–3. If source code contains a SQL injection vulnerability in a specific route handler, we know the exact endpoint, the exact parameter, and the exact payload before sending a single request.
Blackbox testing is not spraying thousands of generic payloads hoping something sticks. It is executing targeted, evidence-driven tests against specific weaknesses already identified.
Phase 5: Blackbox Execution with WAF Evasion
500+ specialized exploit agents execute concurrently. Each is purpose-built for a single vulnerability class. SQL injection agents use time-based blind detection when error-based payloads are blocked. XSS agents escalate through encoding variations when initial payloads are filtered. Authentication bypass agents attempt multiple vectors in sequence: token manipulation, parameter pollution, method override, IP-based access control circumvention.
Hundreds of targeted tests run in parallel against your infrastructure in minutes rather than days.
Phase 6: Attack Chain Construction
All confirmed findings are modeled as a directed graph. Agents identify multi-step chains where individually moderate vulnerabilities combine into critical breach scenarios. Eight known chain patterns are mapped systematically, session theft, GraphQL data exfiltration, credential-to-compromise, XSS session hijack, redirect-to-SSRF, SQL injection privilege escalation, admin console takeover, compound infrastructure degradation, plus novel chain discovery for combinations real attackers would attempt.
A CORS misconfiguration that allows cross-origin requests, combined with a session cookie missing its SameSite flag, combined with a GraphQL endpoint that returns user data, becomes a one-click account takeover. Every chain comes with a working reproduction command, a curl command your engineering team can run in a terminal and see the breach happen in front of them.
Phase 7: Evidence-Based Reporting
Every finding includes: a working reproduction command, the actual data exposed (appropriately redacted but specific enough that severity is unambiguous), a before-and-after code fix at the file, function, and line level, full CVSS 4.0 scoring with justification, and regulatory penalty exposure mapped to SOC 2 Type II, HIPAA, GDPR, PCI-DSS, ISO 27001, and CERT-In.
Full report delivered within 48 hours of engagement start. Unlimited re-scans for every finding until it is fully remediated, no additional cost, no new engagement required.
The Three Test Types: Black Box, White Box, and Gray Box
Every penetration test falls into one of three categories based on what knowledge and access the tester starts with.
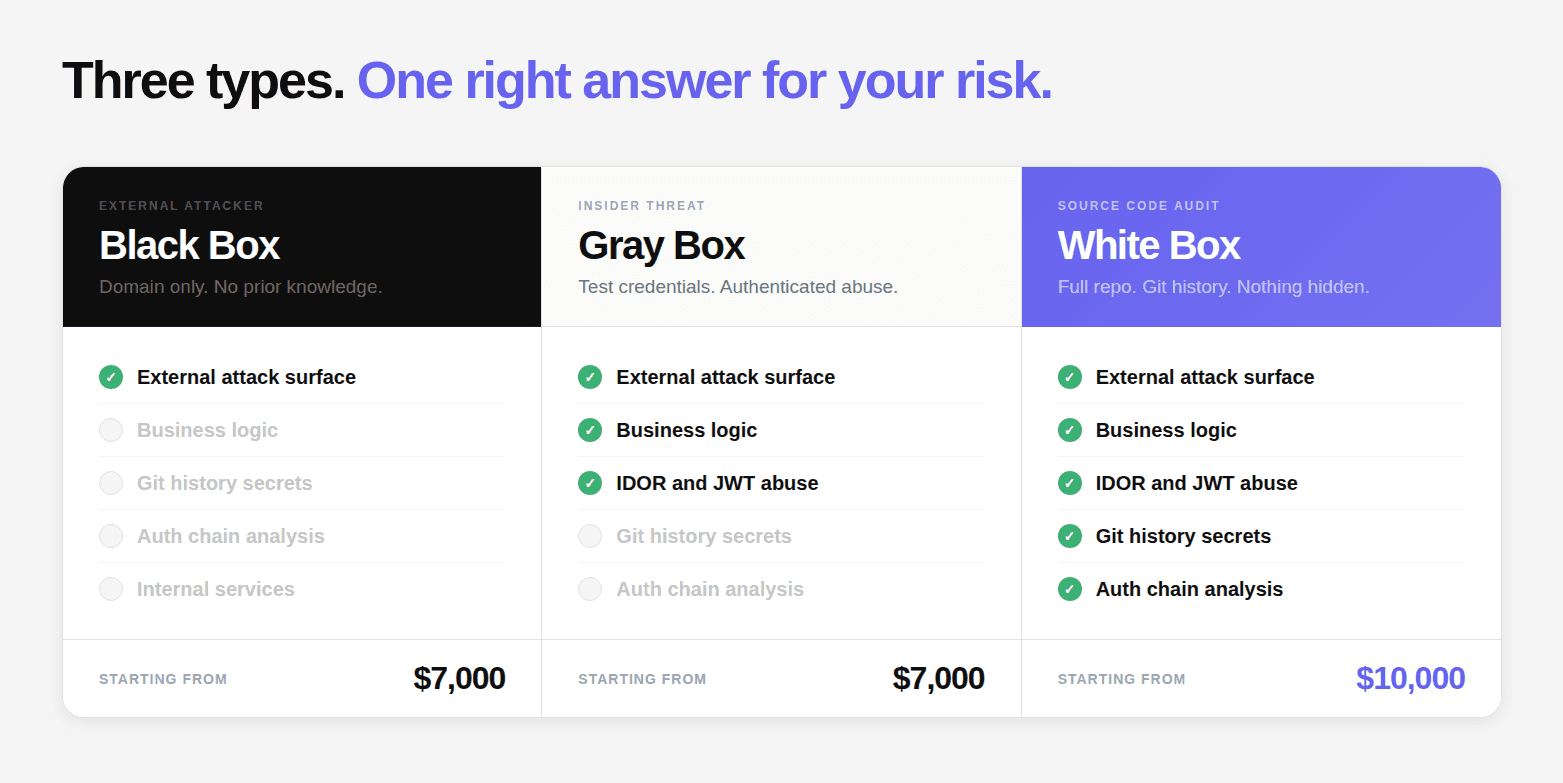
Black Box: The External Attacker Simulation
The tester starts with a single piece of information: your domain. No credentials. No code access. No documentation. This is the most faithful simulation of what an external attacker with no prior knowledge would be able to do.
What black box reliably misses: authentication bypass vulnerabilities buried in middleware configuration that produce normal HTTP responses, business logic flaws in flows that require authentication to reach, secrets in Git history or config files, and vulnerabilities in internal microservices not exposed to the internet.
CodeAnt AI Black Box pricing: $7,000
Gray Box: The Insider Threat Simulation
The tester starts with authenticated access, test credentials for one or more user roles. This simulates the most operationally dangerous threat model: a legitimate user who decides to abuse their access.
Every admin endpoint is tested with non-admin credentials. JWT claim manipulation is tested. Every endpoint accepting a record identifier is tested for IDOR. Business logic flows are tested systematically: price manipulation, discount code reuse, workflow bypass, subscription tier abuse, rate limit evasion, quantity manipulation, concurrent request exploitation.
None of these produce anomalous HTTP response patterns. None match known CVE signatures. They require understanding what the application is supposed to do, and then testing whether it actually enforces that intent at every entry point.
CodeAnt AI Gray Box pricing: $7,000
White Box: The Source Code Audit
The tester has read-only access to the complete repository: source code, configuration files, infrastructure definitions, and version history. This is the only way to find vulnerabilities that are completely invisible from the outside, middleware misconfigurations, auth chain breaks, secrets in configuration files, and dataflow-level injection vulnerabilities that produce no anomalous external response.
Git history is scanned separately from the current HEAD. A credential committed and deleted is still in version control. Dependency reachability analysis determines whether a vulnerable function is actually reachable given the application's dependency usage patterns.
CodeAnt AI White Box pricing: $10,000
Which Test Type Do You Need?
Your Situation | Recommended Approach |
|---|---|
First pentest, no security baseline | Full Assessment (all three) |
Pre-launch, shipping customer data | Gray Box + White Box |
SOC 2 / PCI-DSS audit incoming | Full Assessment |
Recent codebase change, regression check | White Box |
Ongoing continuous security validation | Continuous (monthly) |
Previously pentested, want deeper coverage | White Box |
Acquired a company, assessing their security | Full Assessment |
What a Real AI Pentest Report Contains
The report is what you act on, what you hand to your auditor, and what engineers use to remediate. A good report is an evidence package. A bad report is a PDF with a list of CVEs and a link to OWASP.
Every finding in a CodeAnt AI report contains:
Finding Title and Severity: A precise, descriptive title and CVSS 4.0 score. Not "SQL Injection." "Unauthenticated SQL Injection in Product Search Endpoint Exposing Complete Product Database via Category Parameter."
Executive Summary: One paragraph. Business impact, not technical description. "An unauthenticated attacker can retrieve the name, price, and internal cost of every product in the database by manipulating the category search parameter."
Proof of Concept: A working reproduction. Any engineer on your team should be able to run it and reproduce the finding in under 5 minutes.
Root Cause: File, Class, Method, Line: Not "authentication is missing." The exact location in the codebase where the vulnerability exists.
Remediation: Specific Diff: Not "implement input validation." The exact code change that closes the vulnerability, showing the before and after at the line level.
Compliance Mapping: Which specific controls this finding affects across SOC 2, PCI-DSS, HIPAA, GDPR, ISO 27001, and CERT-In.
You can find a full pentesting report of your company here in less than 24 hours: https://www.codeant.ai/pentesting
The One Capability No External Firm Can Replicate
Every penetration testing firm operates as a black box. They attack your application from the outside. They see what an attacker sees. That is the limit of what they can do.
CodeAnt AI operates across your entire security lifecycle, from the IDE, to pull request review, to CI/CD pipeline, to public exposure mapping, to adversarial simulation. By the time the penetration test runs, we have accumulated deep intelligence about your codebase: every insecure call, every API pattern, every authentication flow, every dependency.
That codebase intelligence powers the Grey Box + Code Memory attack mode where we re-attack using everything learned from your codebase during the defensive phases. No external firm can replicate this. They do not have the context. We do, the 6-step security lifecycle:
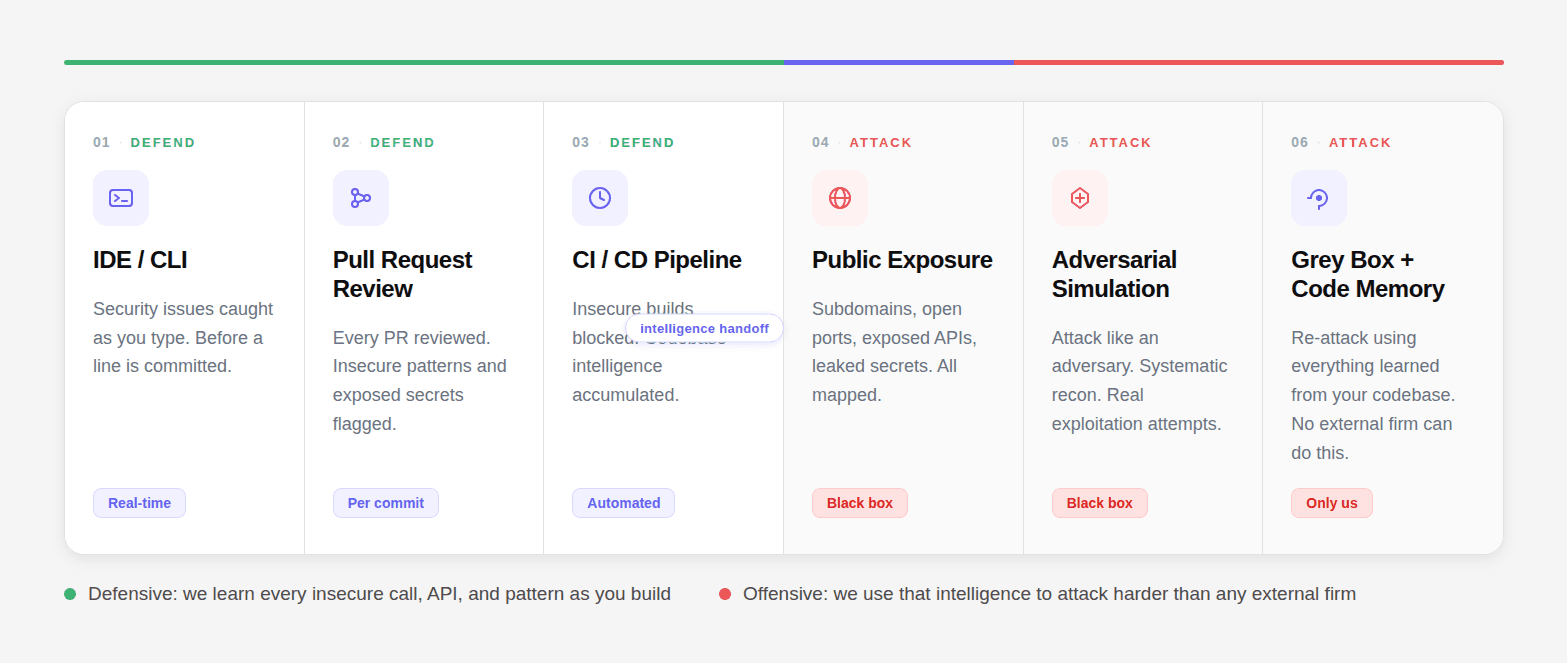
01 DEFEND: IDE/CLI: Security issues caught as you type, before a line is committed.
02 DEFEND: Pull Request Review: Every PR reviewed. Insecure patterns, exposed secrets, vulnerabilities flagged per commit.
03 DEFEND: CI/CD Pipeline: Every build enforced. Insecure builds blocked. Codebase intelligence accumulated.
04 ATTACK: Public Exposure: Subdomains, open ports, exposed APIs, JS bundles, leaked secrets. All mapped.
05 ATTACK: Adversarial Simulation: We attack like an adversary. Systematic recon. Real exploitation attempts.
06 ATTACK: Grey Box + Code Memory: Re-attack using everything learned from your codebase. No external firm can ever do this. Only us.
This is what "Security at every step. Defend from inside. Attack from outside." means in practice.
The business model that changes everything:
Low and medium severity findings are free. You only pay if we find high or critical issues.
That single decision changes the entire incentive structure. We are not paid to generate a long PDF. We are paid when we find the vulnerability that would have caused your breach. Our 87 published CVEs, across npm, PyPI, Maven, and NuGet, affecting packages with over 1.85 billion combined weekly downloads, are evidence of what happens when a security team is actually incentivized to find what matters.
CodeAnt AI vs Aikido vs Astra: An Honest Comparison
The "AI security testing" market is crowded and the marketing language has converged. Here is what these products actually do.
Aikido Security is a developer-facing application security platform, SCA, SAST, IaC scanning, DAST, container scanning, and secrets detection in a unified interface. Their AI pentest feature runs automated DAST-style attack simulations with AI-assisted report generation. It is a genuinely well-built product for continuous monitoring and low-friction developer integration. What it does not do: source code auth flow tracing, exploit chain construction, business logic testing, Git history scanning, or producing a working proof-of-exploit per finding.
Astra Security offers web application pentesting and compliance audits, combining automated scanning with human review of findings. Good for compliance-oriented audits at accessible pricing. What it does not do at depth: source code analysis, dataflow tracing, auth bypass detection at the configuration level, or exploit chaining.
Capability | CodeAnt AI | Aikido | Astra |
|---|---|---|---|
Source code auth flow tracing | ✅ Full | ❌ | ❌ |
Dataflow tracing (HTTP → DB) | ✅ Full | ❌ | ❌ Limited |
Business logic testing | ✅ Structured | ❌ | ⚠️ Limited manual |
Git history secret scanning | ✅ Always | ❌ | ❌ |
Exploit chain construction | ✅ Systematic | ❌ | ❌ |
Proof-of-exploit per finding | ✅ Required | ❌ | ⚠️ Partial |
Published CVE track record | ✅ 87+ CVEs | ❌ | ❌ |
No critical finding = no payment | ✅ | ❌ | ❌ |
Grey Box + Code Memory | ✅ Only us | ❌ | ❌ |
Report in 48 hours | ✅ | ❌ | ❌ |
The Engagement Process: Start to Finish
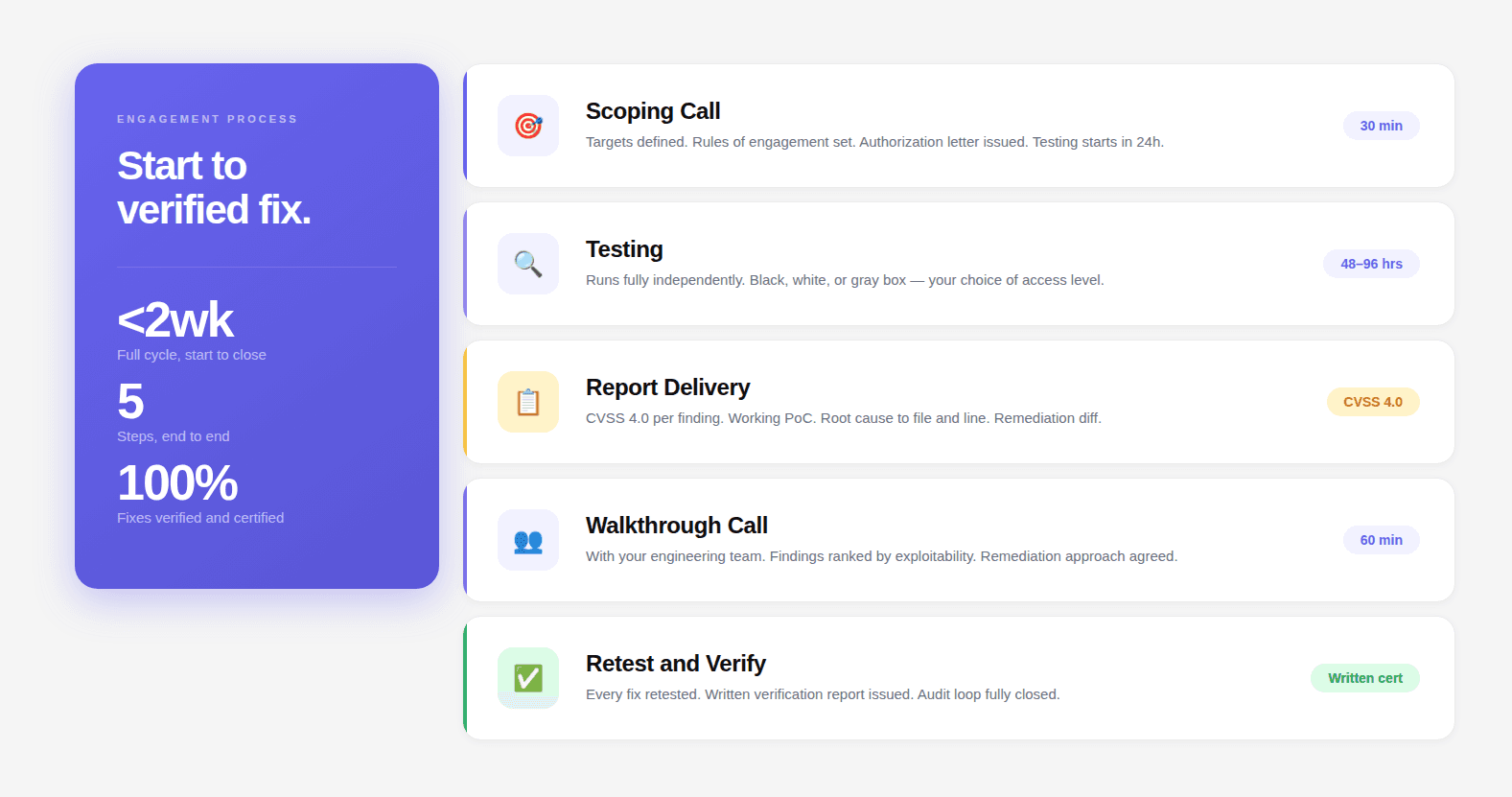
Here is exactly what a CodeAnt AI engagement looks like from first contact to final verification:
Step 1: Scoping Call (30 minutes) Define targets. Choose test type. Set rules of engagement. Receive authorization letter. Testing starts within 24 hours.
Step 2: Testing (48–96 hours) Black box requires nothing from you. White box needs read-only repository access. Gray box needs test credentials for a staging or test environment. The engagement runs independently.
Step 3: Report Delivery CVSS 4.0 per finding. Working proof-of-concept. Root cause to file and line. Compliance impact. Specific remediation diff. Executive summary.
Step 4: Walkthrough Call (60 minutes) With your engineering team. Findings prioritized by exploitability and blast radius. Questions answered. Remediation approach agreed.
Step 5: Retest and Verification Every fix retested. Written verification report issued. Audit loop closed.
The Guarantee: If CodeAnt AI does not find a CVSS 9+ critical vulnerability or an active data leak, you pay nothing. You receive the complete report, all low and medium findings, full methodology documentation, compliance mapping, at zero cost.
This is not a marketing position. It is financially sustainable because the methodology works. The same reasoning engine that produced 87+ published CVEs is applied to your codebase. If it doesn't find something critical, you learn that for free.
→ Book a 30-minute scoping call. Fixed-price quote delivered same day. Testing starts within 24 hours.
Continue reading:
FAQs
What is AI penetration testing?
How long does an AI penetration test take?
How is AI penetration testing different from a vulnerability scanner?
What types of vulnerabilities does AI penetration testing find?
Is AI penetration testing suitable for SOC 2 compliance?













