Why Annual Pentesting Fails Fast-Moving Teams (And What Replaces It)
Sonali Sood
Founding GTM, CodeAnt AI
Most teams still run penetration testing once a year. But their applications don’t change once a year. They change every week, new endpoints, updated authentication flows, third-party integrations, infrastructure changes.
That mismatch creates a structural problem. Security is being tested at one cadence, while risk is being introduced at another.
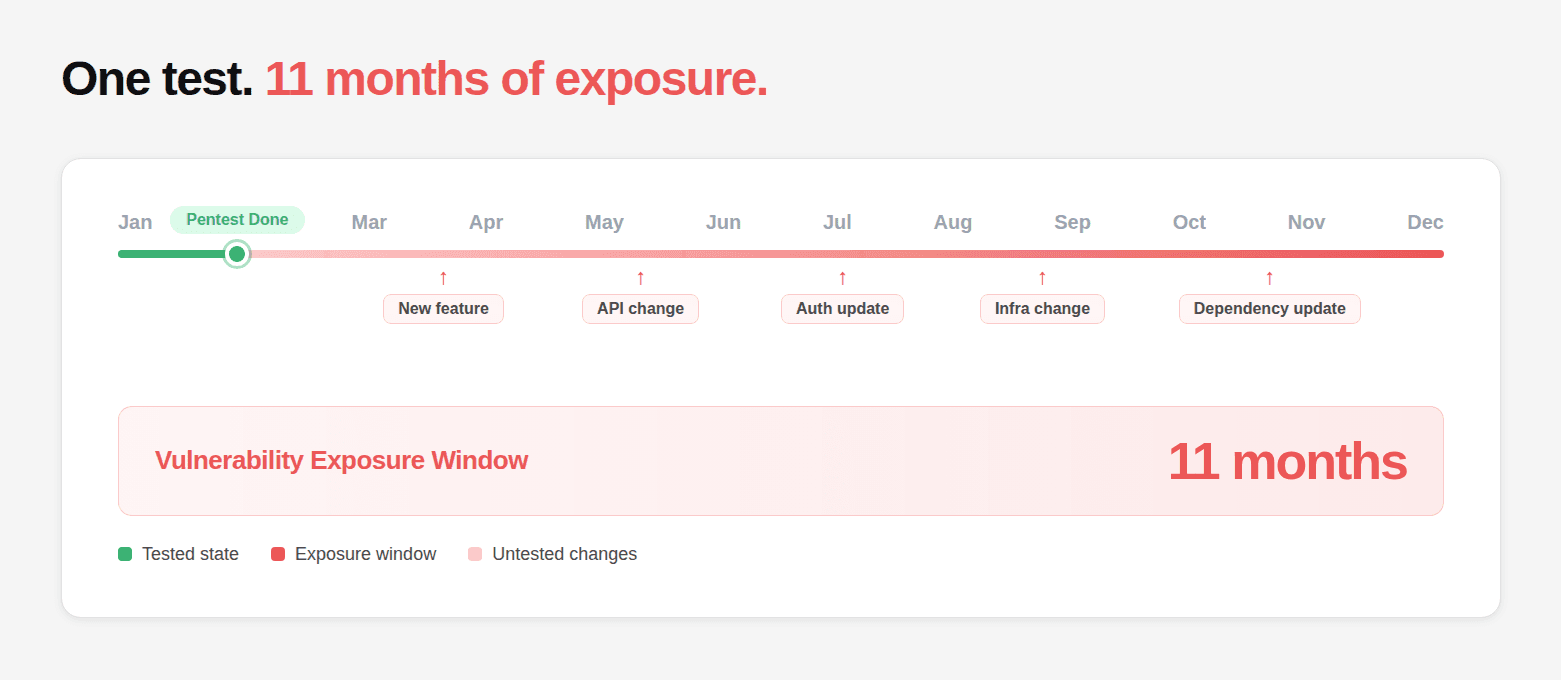
The result is what we can call the deployment velocity gap, the time between when a vulnerability enters the system and when it is actually detected.
In an annual testing model, that gap can stretch for months. A system may be “secure” at the moment of testing, but every change that follows creates new, untested surface area. By the time the next test arrives, the application has already evolved far beyond what was originally evaluated.
This is not a failure of pentesting itself. It’s a mismatch between how often systems change and how often they are tested.
To understand why this gap exists, and why it continues to grow in modern engineering teams, we need to look at how annual penetration testing actually works in practice, and what it does (and does not) cover.
Why Annual Pentesting Made Sense (And Why It No Longer Does)
Annual penetration testing made sense when codebases changed slowly.
Ten years ago, a company might deploy new code quarterly. The same services ran, month over month. Attack vectors shifted gradually. An annual test gave you a reasonably accurate picture of your security posture for most of the year.
That world no longer exists.
Today, a typical SaaS engineering team ships code multiple times per week. New API endpoints get added. Authentication flows get updated. Third-party integrations get bolted on. Infrastructure gets reconfigured. Every one of these changes is a potential new attack surface, and none of them are covered by last year's penetration test.
The problem is not that annual pentesting is bad security work. The problem is that it tests a system that no longer exists by the time the report lands.
Annual pentesting has two hard constraints that cannot be engineered around:
It tests only a moment in time. The engagement captures a snapshot. The application that gets tested on Monday is already different by Friday, new commits, new endpoints, new dependencies. The test is valid for the state of the system during the engagement window. After that, it ages.
It tests only a portion of the system. A consultant with a two-week window can meaningfully probe perhaps 20–30% of a complex modern application's attack surface. Edge cases, rarely triggered flows, and multi-step vulnerabilities often fall outside that window. Nobody tells you which 70–80% didn't get tested.
As deployment velocity increases, both constraints become more damaging.
The Deployment Velocity Gap: How to Measure Your Actual Exposure
The deployment velocity gap is the time between when a vulnerability is introduced into production and when it is detected by security testing.
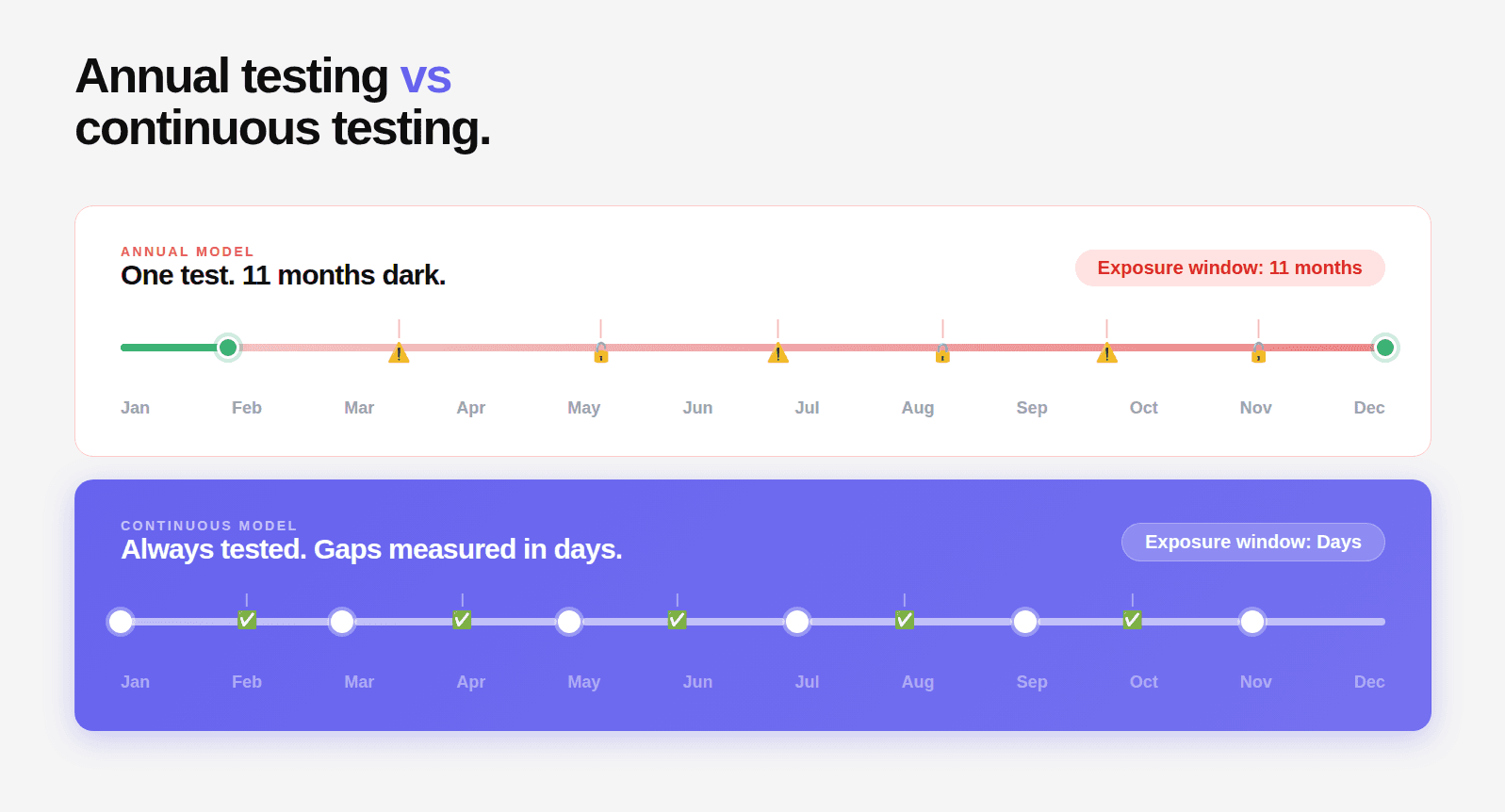
For annual penetration testing programs: maximum gap = 365 days. Average gap = approximately 180 days (half the testing interval, since vulnerabilities are introduced continuously throughout the year, not all at once before the test).
This is not abstract. Here is how to calculate your organization's actual exposure:
def calculate_deployment_velocity_gap(test_interval_days, weekly_deployments): """ Calculate average exposure window given your deployment and testing cadence.
Annual pentesting,shipping 3x per weekannual = calculate_deployment_velocity_gap(365,3)→ average_exposure_window_days:182.5→ untested_deployments:156→ risk_level:CRITICALMonthly pentesting,shipping 3x per weekmonthly = calculate_deployment_velocity_gap(30,3)→ average_exposure_window_days:15→ untested_deployments:12.8→ risk_level:MEDIUM
Annual pentesting,shipping 3x per weekannual = calculate_deployment_velocity_gap(365,3)→ average_exposure_window_days:182.5→ untested_deployments:156→ risk_level:CRITICALMonthly pentesting,shipping 3x per weekmonthly = calculate_deployment_velocity_gap(30,3)→ average_exposure_window_days:15→ untested_deployments:12.8→ risk_level:MEDIUM
Annual pentesting,shipping 3x per weekannual = calculate_deployment_velocity_gap(365,3)→ average_exposure_window_days:182.5→ untested_deployments:156→ risk_level:CRITICALMonthly pentesting,shipping 3x per weekmonthly = calculate_deployment_velocity_gap(30,3)→ average_exposure_window_days:15→ untested_deployments:12.8→ risk_level:MEDIUM
For a team shipping code 3 times per week on an annual testing cadence: 156 deployments go untested between engagements. Each deployment is a potential new vulnerability introduction. The average time before detection is over 6 months.
For a team on monthly continuous pentesting: that drops to 13 deployments and a 15-day average detection window.
The gap is the risk. Closing the gap is what continuous pentesting does.
The Incentive Problem Nobody Talks About
The deployment velocity gap is a technical problem. But there is a second problem underneath it that is harder to fix: the incentive structure of how penetration testing is bought and sold.
Here is how a traditional engagement works:
A company needs a pentest for SOC 2 or a customer audit. They go to a firm and agree on $10,000–$40,000 for a two-week engagement. Both parties have clear incentives:
The company wants the report as fast as possible, with no critical findings, because critical findings mean fixing things before they can submit to the auditor. A green report is the desired outcome.
The firm wants to put in the minimum necessary effort. If they can follow a SOC 2 checklist, mark everything compliant, and deliver a clean PDF in two weeks, everyone is happy and they get paid.
The result: penetration testing becomes a compliance ritual, not a genuine security exercise. Both parties optimize for speed and the appearance of security rather than actual depth of finding.
Low and medium severity findings are free. You only pay if we find high or critical issues.
That single change restructures every incentive in the engagement. We do not get paid to generate a long PDF. We get paid when we find the vulnerability that would have caused your breach. We are therefore motivated to look harder, go deeper, and chain findings together that a traditional firm would report individually as medium-severity and move on.
This is not a marketing position. It is a structural difference in how the business works, and it changes everything about how the engagement is conducted.
The compliance-driven annual test answers: "Were we secure on a specific date?" The operational question is: "Are we secure right now?" These are different questions requiring different answers.
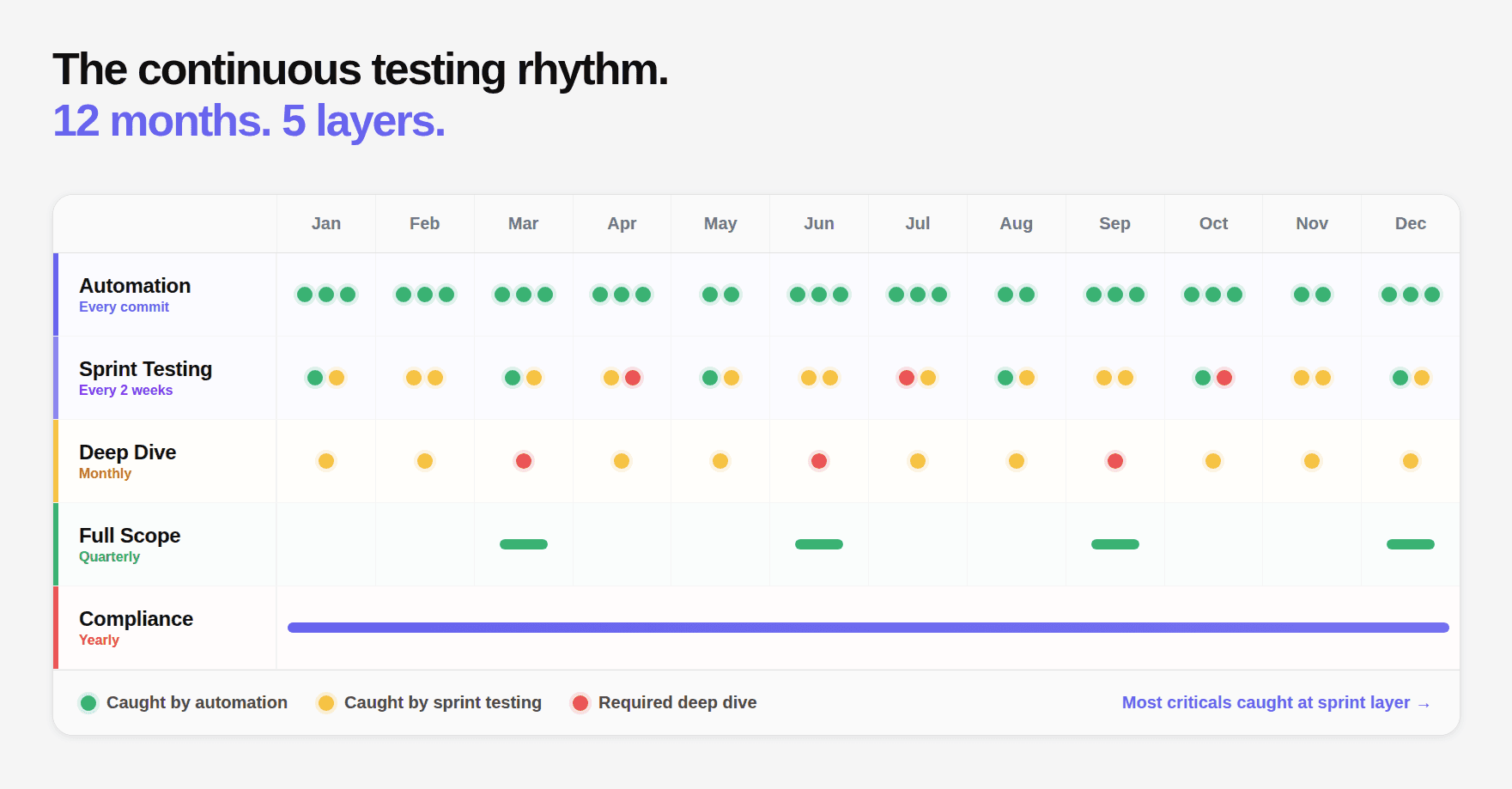
What Continuous Pentesting Actually Means
Continuous pentesting is the practice of running security assessments at the cadence your code changes, not once a year when the auditor asks for it.
What it does not mean: running a scanner on every commit. Fully automated testing cannot replace a penetration test. An AI engine can help enormously, but security researchers still need to validate findings, sign off on reports, and provide the third-party attestation that auditors and enterprise customers require.
What it does mean in practice:
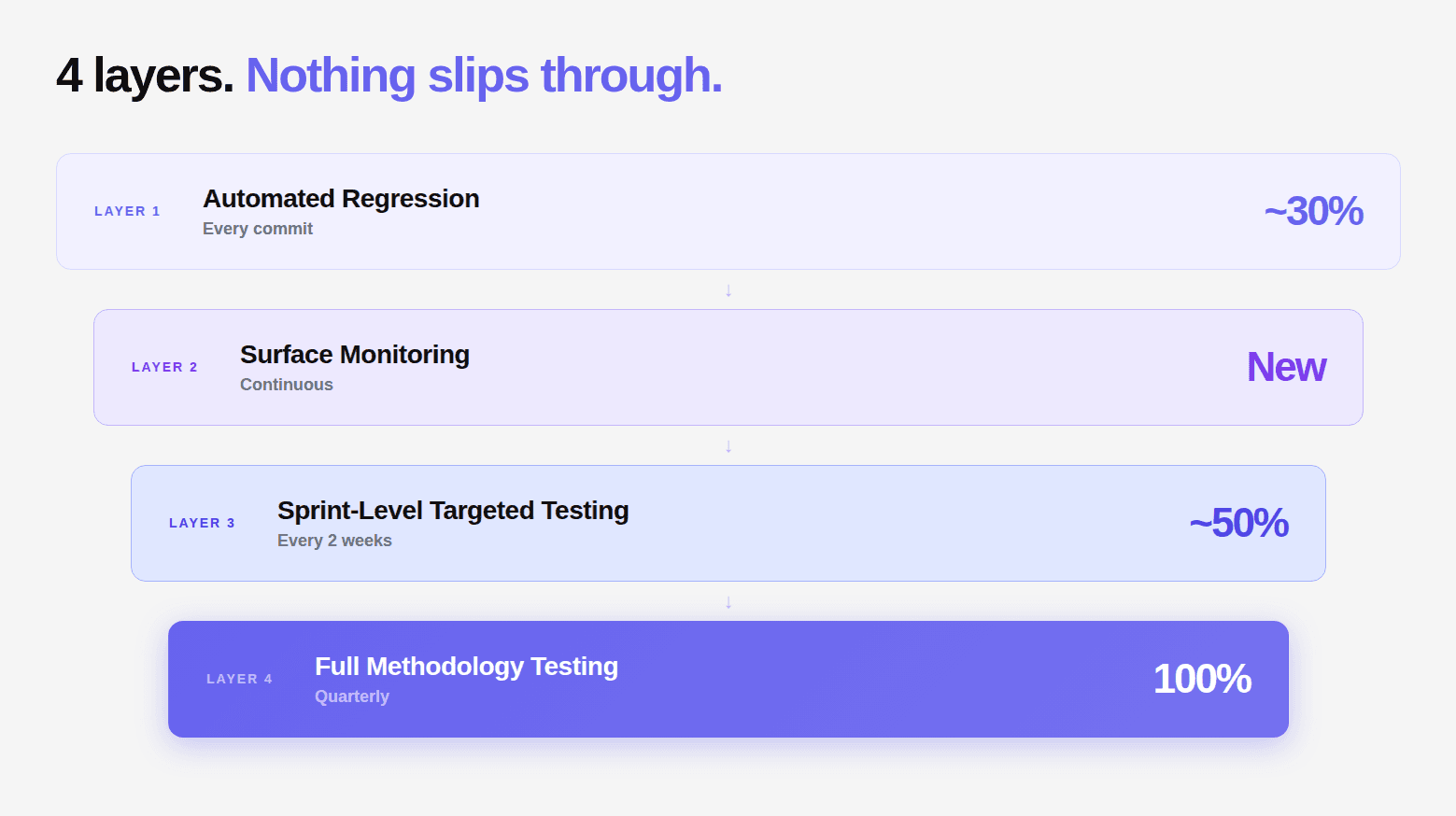
At minimum: monthly pentesting. Every 30 days, a full engagement runs against your current production system. Attack surface that was added in the last 30 days gets tested. New endpoints, updated auth flows, new integrations, all covered within a month of deployment.
At scale: per-release pentesting. Every time a major feature ships, a targeted assessment runs against the new surface area. This is the model the most security-mature companies are moving to.
At the highest level: integrated security lifecycle. Security testing is not a separate engagement — it is woven into the development process. Vulnerabilities are caught at the IDE before they ship, at the PR before they merge, at CI/CD before they deploy, and then verified by a full penetration test after they are live.
The key operational insight: continuous pentesting is only affordable if the per-engagement cost is low enough to run frequently. Traditional firms charge $10,000–$40,000 per engagement. At that price, monthly testing costs $120,000–$480,000 per year. That is not a model most companies can sustain.
This is why the economics of AI-driven pentesting matter. When an engagement runs in 48 hours instead of two weeks, and when the cost structure is pay-only-for-critical-findings, continuous testing becomes financially viable at the cadence modern engineering teams actually need.
How CodeAnt AI Makes Continuous Pentesting Operationally Possible
The reason traditional firms cannot support continuous pentesting is structural: their model requires a human consultant to manually work through a target over one to two weeks. You cannot compress that timeline or reduce the cost to a level that supports monthly testing.
CodeAnt AI's architecture was built from scratch for high-frequency, high-depth engagements.
500+ specialized exploit agents run concurrently. Where a consultant works sequentially through a target, our agents execute hundreds of targeted tests in parallel. What takes a human two weeks takes our system hours.
Every engagement builds on the last. The codebase intelligence accumulated from prior engagements, every insecure call pattern, every API structure, every authentication flow, informs the next test. Each engagement is deeper than the one before it. No external firm can do this. They start from scratch every time.
This is the Grey Box + Code Memory advantage. By the time the penetration test runs, our engine has already learned your codebase from the defensive phases, IDE scanning, PR review, CI/CD analysis. We re-attack using everything we learned. An attacker who has never seen your code does not have this. We do.
48-hour report delivery. Traditional firms take 2–4 weeks from engagement start to report delivery. Our full engagement, reconnaissance, source code analysis, JS bundle intelligence, blackbox execution with WAF evasion, attack chain construction, evidence-based reporting, completes in 48 hours.
Unlimited retests at no additional cost. When a finding is remediated, we verify the fix. If it is not fully closed, we keep testing until it is. No new engagement required, no additional billing.
The practical result: monthly pentesting at a price point that is sustainable, with report turnaround that does not block your engineering team. Check out our agentic pentesting here.
Annual vs Continuous: Side-by-Side Comparison
Annual Pentesting
Continuous Pentesting (CodeAnt AI)
Testing frequency
Once per year
Monthly or per major release
Average vulnerability detection window
~180 days
~15 days
Coverage of new deployments
~0% after test date
~100% within testing cadence
Time to report
2–4 weeks
48 hours
Cost per engagement
$10,000–$40,000
Pay only for high/critical findings
Findings reported in isolation
Yes, individual CVSS scores
No, attack chains constructed
Codebase intelligence
Starts fresh each time
Accumulates across engagements
Retest included
Varies, often additional cost
Unlimited, no additional cost
Compliance evidence quality
Point-in-time snapshot
Continuous audit trail
Suitable for SOC 2 Type II
Minimum bar, often questioned
Full evidence package per auditor requirements
Misaligned incentives
Yes, paid regardless of findings
No, paid only for high/critical
Sprint-Cadence Testing: The Most Operationally Effective Model
For engineering teams shipping every 1–2 weeks, sprint-cadence testing is the model that closes the deployment velocity gap most effectively while remaining operationally feasible.
class SprintSecurityTestingProgram:
"""
Operationalizes sprint-cadence security testing.
Each sprint's changed components are tested before the next sprint begins.
"""def__init__(self,repo_url: str,pentest_team_contact: str):
self.repo_url = repo_urlself.pentest_team = pentest_team_contactself.sprint_history = []defanalyze_sprint_changes(self,sprint_start: datetime.date,sprint_end: datetime.date,merged_prs: list) -> dict:
"""
Analyze what changed in a sprint to determine security testing scope.
"""changed_components = {'authentication': [],# Changes to auth logic'authorization': [],# Changes to access control'api_endpoints': [],# New or modified endpoints'data_access': [],# ORM, database query changes'external_integrations': [],# Third-party API changes'infrastructure': [],# IaC, Kubernetes, CI/CD changes'dependencies': [],# package.json, requirements.txt changes'configuration': [],# Config files, environment changes}security_relevant_prs = []forprinmerged_prs:
files_changed = pr.get('files_changed',[])# Classify changes by security relevanceclassifications = []forfileinfiles_changed:
ifany(patterninfile.lower()forpatternin['auth','login','jwt','token','session','oauth']):
changed_components['authentication'].append(file)classifications.append('authentication')elifany(patterninfile.lower()forpatternin['permission','role','acl','policy','rbac','middleware']):
changed_components['authorization'].append(file)classifications.append('authorization')elifany(patterninfile.lower()forpatternin['routes','views','controllers','handlers','api']):
changed_components['api_endpoints'].append(file)classifications.append('api_endpoints')elifany(patterninfile.lower()forpatternin['models','queries','repository','dao','db','orm']):
changed_components['data_access'].append(file)classifications.append('data_access')eliffilein['package.json','package-lock.json','requirements.txt','Pipfile','pom.xml','build.gradle','go.mod']:
changed_components['dependencies'].append(file)classifications.append('dependencies')elifany(patterninfile.lower()forpatternin['kubernetes','k8s','helm','terraform','bicep','.github/workflows','jenkinsfile','dockerfile']):
changed_components['infrastructure'].append(file)classifications.append('infrastructure')ifclassifications:
security_relevant_prs.append({'pr_number': pr.get('number'),'title': pr.get('title'),'author': pr.get('author'),'security_categories': list(set(classifications)),'files_changed': len(files_changed),'security_relevant_files': [fforfinfiles_changedifany(catinf.lower()forcatin['auth','api','model','route','middleware'])]})# Determine test depth required for this sprintrisk_score = (len(changed_components['authentication']) * 10 + # Highest weightlen(changed_components['authorization']) * 8 +
len(changed_components['api_endpoints']) * 5 +
len(changed_components['data_access']) * 6 +
len(changed_components['infrastructure']) * 7 +
len(changed_components['external_integrations']) * 5 +
len(changed_components['dependencies']) * 3)return{'sprint_start': sprint_start.isoformat(),'sprint_end': sprint_end.isoformat(),'total_prs': len(merged_prs),'security_relevant_prs': len(security_relevant_prs),'changed_components': changed_components,'sprint_risk_score': risk_score,'recommended_test_depth': self.classify_test_depth(risk_score),'estimated_test_hours': self.estimate_test_hours(risk_score),'priority_areas': self.identify_priority_areas(changed_components),'security_relevant_pr_details': security_relevant_prs}defclassify_test_depth(self,risk_score: int) -> str:
ifrisk_score > 100:
return'FULL_DEPTH — Authentication changes require complete auth chain review'elifrisk_score > 50:
return'TARGETED_DEEP — Multiple security-relevant changes require deep testing'elifrisk_score > 20:
return'TARGETED_STANDARD — Specific changed components need focused testing'else:
return'LIGHTWEIGHT — Minor changes, automated testing sufficient'defestimate_test_hours(self,risk_score: int) -> str:
ifrisk_score > 100:
return'8–16 hours'elifrisk_score > 50:
return'4–8 hours'elifrisk_score > 20:
return'2–4 hours'else:
return'1–2 hours'defidentify_priority_areas(self,changed_components: dict) -> list:
priorities = []ifchanged_components['authentication']:
priorities.append({'area': 'Authentication','priority': 1,'reason': 'Auth changes have highest security impact','test_focus': 'JWT validation, session management, MFA bypass, brute force'})ifchanged_components['authorization']:
priorities.append({'area': 'Authorization','priority': 2,'reason': 'Access control changes may introduce privilege escalation','test_focus': 'RBAC, IDOR, cross-tenant access, role bypass'})ifchanged_components['data_access']:
priorities.append({'area': 'Data Access Layer','priority': 3,'reason': 'ORM changes may introduce injection or IDOR','test_focus': 'SQL injection, NoSQL injection, ownership filter presence'})returnsorted(priorities,key=lambdax: x['priority'])
class SprintSecurityTestingProgram:
"""
Operationalizes sprint-cadence security testing.
Each sprint's changed components are tested before the next sprint begins.
"""def__init__(self,repo_url: str,pentest_team_contact: str):
self.repo_url = repo_urlself.pentest_team = pentest_team_contactself.sprint_history = []defanalyze_sprint_changes(self,sprint_start: datetime.date,sprint_end: datetime.date,merged_prs: list) -> dict:
"""
Analyze what changed in a sprint to determine security testing scope.
"""changed_components = {'authentication': [],# Changes to auth logic'authorization': [],# Changes to access control'api_endpoints': [],# New or modified endpoints'data_access': [],# ORM, database query changes'external_integrations': [],# Third-party API changes'infrastructure': [],# IaC, Kubernetes, CI/CD changes'dependencies': [],# package.json, requirements.txt changes'configuration': [],# Config files, environment changes}security_relevant_prs = []forprinmerged_prs:
files_changed = pr.get('files_changed',[])# Classify changes by security relevanceclassifications = []forfileinfiles_changed:
ifany(patterninfile.lower()forpatternin['auth','login','jwt','token','session','oauth']):
changed_components['authentication'].append(file)classifications.append('authentication')elifany(patterninfile.lower()forpatternin['permission','role','acl','policy','rbac','middleware']):
changed_components['authorization'].append(file)classifications.append('authorization')elifany(patterninfile.lower()forpatternin['routes','views','controllers','handlers','api']):
changed_components['api_endpoints'].append(file)classifications.append('api_endpoints')elifany(patterninfile.lower()forpatternin['models','queries','repository','dao','db','orm']):
changed_components['data_access'].append(file)classifications.append('data_access')eliffilein['package.json','package-lock.json','requirements.txt','Pipfile','pom.xml','build.gradle','go.mod']:
changed_components['dependencies'].append(file)classifications.append('dependencies')elifany(patterninfile.lower()forpatternin['kubernetes','k8s','helm','terraform','bicep','.github/workflows','jenkinsfile','dockerfile']):
changed_components['infrastructure'].append(file)classifications.append('infrastructure')ifclassifications:
security_relevant_prs.append({'pr_number': pr.get('number'),'title': pr.get('title'),'author': pr.get('author'),'security_categories': list(set(classifications)),'files_changed': len(files_changed),'security_relevant_files': [fforfinfiles_changedifany(catinf.lower()forcatin['auth','api','model','route','middleware'])]})# Determine test depth required for this sprintrisk_score = (len(changed_components['authentication']) * 10 + # Highest weightlen(changed_components['authorization']) * 8 +
len(changed_components['api_endpoints']) * 5 +
len(changed_components['data_access']) * 6 +
len(changed_components['infrastructure']) * 7 +
len(changed_components['external_integrations']) * 5 +
len(changed_components['dependencies']) * 3)return{'sprint_start': sprint_start.isoformat(),'sprint_end': sprint_end.isoformat(),'total_prs': len(merged_prs),'security_relevant_prs': len(security_relevant_prs),'changed_components': changed_components,'sprint_risk_score': risk_score,'recommended_test_depth': self.classify_test_depth(risk_score),'estimated_test_hours': self.estimate_test_hours(risk_score),'priority_areas': self.identify_priority_areas(changed_components),'security_relevant_pr_details': security_relevant_prs}defclassify_test_depth(self,risk_score: int) -> str:
ifrisk_score > 100:
return'FULL_DEPTH — Authentication changes require complete auth chain review'elifrisk_score > 50:
return'TARGETED_DEEP — Multiple security-relevant changes require deep testing'elifrisk_score > 20:
return'TARGETED_STANDARD — Specific changed components need focused testing'else:
return'LIGHTWEIGHT — Minor changes, automated testing sufficient'defestimate_test_hours(self,risk_score: int) -> str:
ifrisk_score > 100:
return'8–16 hours'elifrisk_score > 50:
return'4–8 hours'elifrisk_score > 20:
return'2–4 hours'else:
return'1–2 hours'defidentify_priority_areas(self,changed_components: dict) -> list:
priorities = []ifchanged_components['authentication']:
priorities.append({'area': 'Authentication','priority': 1,'reason': 'Auth changes have highest security impact','test_focus': 'JWT validation, session management, MFA bypass, brute force'})ifchanged_components['authorization']:
priorities.append({'area': 'Authorization','priority': 2,'reason': 'Access control changes may introduce privilege escalation','test_focus': 'RBAC, IDOR, cross-tenant access, role bypass'})ifchanged_components['data_access']:
priorities.append({'area': 'Data Access Layer','priority': 3,'reason': 'ORM changes may introduce injection or IDOR','test_focus': 'SQL injection, NoSQL injection, ownership filter presence'})returnsorted(priorities,key=lambdax: x['priority'])
class SprintSecurityTestingProgram:
"""
Operationalizes sprint-cadence security testing.
Each sprint's changed components are tested before the next sprint begins.
"""def__init__(self,repo_url: str,pentest_team_contact: str):
self.repo_url = repo_urlself.pentest_team = pentest_team_contactself.sprint_history = []defanalyze_sprint_changes(self,sprint_start: datetime.date,sprint_end: datetime.date,merged_prs: list) -> dict:
"""
Analyze what changed in a sprint to determine security testing scope.
"""changed_components = {'authentication': [],# Changes to auth logic'authorization': [],# Changes to access control'api_endpoints': [],# New or modified endpoints'data_access': [],# ORM, database query changes'external_integrations': [],# Third-party API changes'infrastructure': [],# IaC, Kubernetes, CI/CD changes'dependencies': [],# package.json, requirements.txt changes'configuration': [],# Config files, environment changes}security_relevant_prs = []forprinmerged_prs:
files_changed = pr.get('files_changed',[])# Classify changes by security relevanceclassifications = []forfileinfiles_changed:
ifany(patterninfile.lower()forpatternin['auth','login','jwt','token','session','oauth']):
changed_components['authentication'].append(file)classifications.append('authentication')elifany(patterninfile.lower()forpatternin['permission','role','acl','policy','rbac','middleware']):
changed_components['authorization'].append(file)classifications.append('authorization')elifany(patterninfile.lower()forpatternin['routes','views','controllers','handlers','api']):
changed_components['api_endpoints'].append(file)classifications.append('api_endpoints')elifany(patterninfile.lower()forpatternin['models','queries','repository','dao','db','orm']):
changed_components['data_access'].append(file)classifications.append('data_access')eliffilein['package.json','package-lock.json','requirements.txt','Pipfile','pom.xml','build.gradle','go.mod']:
changed_components['dependencies'].append(file)classifications.append('dependencies')elifany(patterninfile.lower()forpatternin['kubernetes','k8s','helm','terraform','bicep','.github/workflows','jenkinsfile','dockerfile']):
changed_components['infrastructure'].append(file)classifications.append('infrastructure')ifclassifications:
security_relevant_prs.append({'pr_number': pr.get('number'),'title': pr.get('title'),'author': pr.get('author'),'security_categories': list(set(classifications)),'files_changed': len(files_changed),'security_relevant_files': [fforfinfiles_changedifany(catinf.lower()forcatin['auth','api','model','route','middleware'])]})# Determine test depth required for this sprintrisk_score = (len(changed_components['authentication']) * 10 + # Highest weightlen(changed_components['authorization']) * 8 +
len(changed_components['api_endpoints']) * 5 +
len(changed_components['data_access']) * 6 +
len(changed_components['infrastructure']) * 7 +
len(changed_components['external_integrations']) * 5 +
len(changed_components['dependencies']) * 3)return{'sprint_start': sprint_start.isoformat(),'sprint_end': sprint_end.isoformat(),'total_prs': len(merged_prs),'security_relevant_prs': len(security_relevant_prs),'changed_components': changed_components,'sprint_risk_score': risk_score,'recommended_test_depth': self.classify_test_depth(risk_score),'estimated_test_hours': self.estimate_test_hours(risk_score),'priority_areas': self.identify_priority_areas(changed_components),'security_relevant_pr_details': security_relevant_prs}defclassify_test_depth(self,risk_score: int) -> str:
ifrisk_score > 100:
return'FULL_DEPTH — Authentication changes require complete auth chain review'elifrisk_score > 50:
return'TARGETED_DEEP — Multiple security-relevant changes require deep testing'elifrisk_score > 20:
return'TARGETED_STANDARD — Specific changed components need focused testing'else:
return'LIGHTWEIGHT — Minor changes, automated testing sufficient'defestimate_test_hours(self,risk_score: int) -> str:
ifrisk_score > 100:
return'8–16 hours'elifrisk_score > 50:
return'4–8 hours'elifrisk_score > 20:
return'2–4 hours'else:
return'1–2 hours'defidentify_priority_areas(self,changed_components: dict) -> list:
priorities = []ifchanged_components['authentication']:
priorities.append({'area': 'Authentication','priority': 1,'reason': 'Auth changes have highest security impact','test_focus': 'JWT validation, session management, MFA bypass, brute force'})ifchanged_components['authorization']:
priorities.append({'area': 'Authorization','priority': 2,'reason': 'Access control changes may introduce privilege escalation','test_focus': 'RBAC, IDOR, cross-tenant access, role bypass'})ifchanged_components['data_access']:
priorities.append({'area': 'Data Access Layer','priority': 3,'reason': 'ORM changes may introduce injection or IDOR','test_focus': 'SQL injection, NoSQL injection, ownership filter presence'})returnsorted(priorities,key=lambdax: x['priority'])
The Economics: Annual vs Continuous Total Cost of Ownership
The surface-level cost comparison (annual pentest = one invoice) consistently underestimates the true cost of the annual model and overestimates the cost of continuous testing:
defcalculate_tco_comparison(org_profile: dict) -> dict:
"""
Calculate Total Cost of Ownership for annual vs continuous security testing.
Includes direct costs, breach probability adjustment, and remediation costs.
"""# Organization profile inputsannual_revenue = org_profile['annual_revenue']deployment_frequency_per_year = org_profile['deployments_per_year']engineering_team_size = org_profile['engineering_team_size']avg_engineer_hourly_cost = org_profile['avg_engineer_hourly_cost']breach_probability_annual = org_profile['estimated_breach_probability']# e.g., 0.15 = 15%avg_breach_cost = org_profile['avg_breach_cost']# all-in cost if breach occurs# ═══════════════════════════════════════════════════════# ANNUAL PENETRATION TESTING MODEL# ═══════════════════════════════════════════════════════annual_model = {}# Direct costsannual_model['pentest_cost'] = 25000# Typical annual pentest (1 week, 1-2 testers)annual_model['retest_cost'] = 8000# Retest after remediation# Engineering remediation costs# Average: 8 findings, 3 days engineering per findingavg_findings = 8avg_remediation_days = 3annual_model['engineering_remediation_cost'] = (avg_findings * avg_remediation_days * 8 * # 8 hours/dayavg_engineer_hourly_cost)# Emergency response costs (for critical findings discovered late)# Annual model has longer gap → higher probability of undetected critical issue# that then requires emergency responseprob_emergency_response = 0.35# 35% chance of emergency security incidentavg_emergency_response_cost = 50000# War room, hotfix, communicationannual_model['expected_emergency_response_cost'] = (prob_emergency_response * avg_emergency_response_cost)# Alert fatigue / wasted engineering time on non-exploitable findings# Annual test typically has higher percentage of false positives vs continuousannual_model['false_positive_remediation_waste'] = (avg_findings * 0.3 * # 30% false positive rate for annual2 * 8 * # 2 days to discover and document it's a false positiveavg_engineer_hourly_cost)# Breach risk — adjusted for longer exposure window# Annual model has ~180 day average undetected vulnerability window# Breach probability scales with exposure windowexposure_window_days_annual = 180annual_model['adjusted_breach_probability'] = breach_probability_annual * (exposure_window_days_annual / 365)annual_model['expected_breach_cost'] = (annual_model['adjusted_breach_probability'] * avg_breach_cost)annual_model['total_direct_cost'] = (annual_model['pentest_cost'] +
annual_model['retest_cost'] +
annual_model['engineering_remediation_cost'] +
annual_model['expected_emergency_response_cost'] +
annual_model['false_positive_remediation_waste'])annual_model['total_tco'] = (annual_model['total_direct_cost'] +
annual_model['expected_breach_cost'])# ═══════════════════════════════════════════════════════# CONTINUOUS PENETRATION TESTING MODEL# ═══════════════════════════════════════════════════════continuous_model = {}# Direct costs — subscription modelcontinuous_model['monthly_subscription'] = 4500# Typical continuous programcontinuous_model['annual_subscription_cost'] = continuous_model['monthly_subscription'] * 12# Engineering remediation costs — findings caught earlier are cheaper to fix# Studies show: 6x cheaper to fix in development vs production# Continuous testing catches most issues within 2 weeks of introductioncontinuous_avg_findings = 12# More findings per year (nothing escapes for 11 months)continuous_avg_remediation_days = 1.5# Caught earlier = simpler fix (feature branch)continuous_model['engineering_remediation_cost'] = (continuous_avg_findings * continuous_avg_remediation_days * 8 *
avg_engineer_hourly_cost)# Emergency response costs — much lower (issues caught before breach)prob_emergency_response_continuous = 0.08# 8% vs 35% for annualcontinuous_model['expected_emergency_response_cost'] = (prob_emergency_response_continuous * avg_emergency_response_cost)# Near-zero false positive waste — continuous testing is more targetedcontinuous_model['false_positive_remediation_waste'] = (continuous_avg_findings * 0.05 * # 5% false positive rate1 * 8 *
avg_engineer_hourly_cost)# Breach risk — dramatically reduced exposure windowexposure_window_days_continuous = 14# 2-week sprint cadencecontinuous_model['adjusted_breach_probability'] = breach_probability_annual * (exposure_window_days_continuous / 365)continuous_model['expected_breach_cost'] = (continuous_model['adjusted_breach_probability'] * avg_breach_cost)continuous_model['total_direct_cost'] = (continuous_model['annual_subscription_cost'] +
continuous_model['engineering_remediation_cost'] +
continuous_model['expected_emergency_response_cost'] +
continuous_model['false_positive_remediation_waste'])continuous_model['total_tco'] = (continuous_model['total_direct_cost'] +
continuous_model['expected_breach_cost'])# Comparisontco_savings = annual_model['total_tco'] - continuous_model['total_tco']return{'organization_profile': org_profile,'annual_model': annual_model,'continuous_model': continuous_model,'comparison': {'annual_tco': round(annual_model['total_tco']),'continuous_tco': round(continuous_model['total_tco']),'tco_savings': round(tco_savings),'savings_percentage': round((tco_savings / annual_model['total_tco']) * 100,1),'breakeven_required_breach_probability': (annual_model['total_direct_cost'] - continuous_model['total_direct_cost']) / avg_breach_cost,'recommendation': 'Continuous'iftco_savings > 0else'Annual','primary_savings_driver': ('Breach risk reduction'ifcontinuous_model['expected_breach_cost'] <
annual_model['expected_breach_cost'] * 0.5else'Engineering efficiency')}}# Example calculation:example_org = {'annual_revenue': 10_000_000,'deployments_per_year': 52,# Weekly releases'engineering_team_size': 15,'avg_engineer_hourly_cost': 100,'estimated_breach_probability': 0.12,# 12% annual breach probability'avg_breach_cost': 500_000}result = calculate_tco_comparison(example_org)print(f"Annual model TCO: ${result['comparison']['annual_tco']:,}")print(f"Continuous model TCO: ${result['comparison']['continuous_tco']:,}")print(f"Expected savings: ${result['comparison']['tco_savings']:,}")
defcalculate_tco_comparison(org_profile: dict) -> dict:
"""
Calculate Total Cost of Ownership for annual vs continuous security testing.
Includes direct costs, breach probability adjustment, and remediation costs.
"""# Organization profile inputsannual_revenue = org_profile['annual_revenue']deployment_frequency_per_year = org_profile['deployments_per_year']engineering_team_size = org_profile['engineering_team_size']avg_engineer_hourly_cost = org_profile['avg_engineer_hourly_cost']breach_probability_annual = org_profile['estimated_breach_probability']# e.g., 0.15 = 15%avg_breach_cost = org_profile['avg_breach_cost']# all-in cost if breach occurs# ═══════════════════════════════════════════════════════# ANNUAL PENETRATION TESTING MODEL# ═══════════════════════════════════════════════════════annual_model = {}# Direct costsannual_model['pentest_cost'] = 25000# Typical annual pentest (1 week, 1-2 testers)annual_model['retest_cost'] = 8000# Retest after remediation# Engineering remediation costs# Average: 8 findings, 3 days engineering per findingavg_findings = 8avg_remediation_days = 3annual_model['engineering_remediation_cost'] = (avg_findings * avg_remediation_days * 8 * # 8 hours/dayavg_engineer_hourly_cost)# Emergency response costs (for critical findings discovered late)# Annual model has longer gap → higher probability of undetected critical issue# that then requires emergency responseprob_emergency_response = 0.35# 35% chance of emergency security incidentavg_emergency_response_cost = 50000# War room, hotfix, communicationannual_model['expected_emergency_response_cost'] = (prob_emergency_response * avg_emergency_response_cost)# Alert fatigue / wasted engineering time on non-exploitable findings# Annual test typically has higher percentage of false positives vs continuousannual_model['false_positive_remediation_waste'] = (avg_findings * 0.3 * # 30% false positive rate for annual2 * 8 * # 2 days to discover and document it's a false positiveavg_engineer_hourly_cost)# Breach risk — adjusted for longer exposure window# Annual model has ~180 day average undetected vulnerability window# Breach probability scales with exposure windowexposure_window_days_annual = 180annual_model['adjusted_breach_probability'] = breach_probability_annual * (exposure_window_days_annual / 365)annual_model['expected_breach_cost'] = (annual_model['adjusted_breach_probability'] * avg_breach_cost)annual_model['total_direct_cost'] = (annual_model['pentest_cost'] +
annual_model['retest_cost'] +
annual_model['engineering_remediation_cost'] +
annual_model['expected_emergency_response_cost'] +
annual_model['false_positive_remediation_waste'])annual_model['total_tco'] = (annual_model['total_direct_cost'] +
annual_model['expected_breach_cost'])# ═══════════════════════════════════════════════════════# CONTINUOUS PENETRATION TESTING MODEL# ═══════════════════════════════════════════════════════continuous_model = {}# Direct costs — subscription modelcontinuous_model['monthly_subscription'] = 4500# Typical continuous programcontinuous_model['annual_subscription_cost'] = continuous_model['monthly_subscription'] * 12# Engineering remediation costs — findings caught earlier are cheaper to fix# Studies show: 6x cheaper to fix in development vs production# Continuous testing catches most issues within 2 weeks of introductioncontinuous_avg_findings = 12# More findings per year (nothing escapes for 11 months)continuous_avg_remediation_days = 1.5# Caught earlier = simpler fix (feature branch)continuous_model['engineering_remediation_cost'] = (continuous_avg_findings * continuous_avg_remediation_days * 8 *
avg_engineer_hourly_cost)# Emergency response costs — much lower (issues caught before breach)prob_emergency_response_continuous = 0.08# 8% vs 35% for annualcontinuous_model['expected_emergency_response_cost'] = (prob_emergency_response_continuous * avg_emergency_response_cost)# Near-zero false positive waste — continuous testing is more targetedcontinuous_model['false_positive_remediation_waste'] = (continuous_avg_findings * 0.05 * # 5% false positive rate1 * 8 *
avg_engineer_hourly_cost)# Breach risk — dramatically reduced exposure windowexposure_window_days_continuous = 14# 2-week sprint cadencecontinuous_model['adjusted_breach_probability'] = breach_probability_annual * (exposure_window_days_continuous / 365)continuous_model['expected_breach_cost'] = (continuous_model['adjusted_breach_probability'] * avg_breach_cost)continuous_model['total_direct_cost'] = (continuous_model['annual_subscription_cost'] +
continuous_model['engineering_remediation_cost'] +
continuous_model['expected_emergency_response_cost'] +
continuous_model['false_positive_remediation_waste'])continuous_model['total_tco'] = (continuous_model['total_direct_cost'] +
continuous_model['expected_breach_cost'])# Comparisontco_savings = annual_model['total_tco'] - continuous_model['total_tco']return{'organization_profile': org_profile,'annual_model': annual_model,'continuous_model': continuous_model,'comparison': {'annual_tco': round(annual_model['total_tco']),'continuous_tco': round(continuous_model['total_tco']),'tco_savings': round(tco_savings),'savings_percentage': round((tco_savings / annual_model['total_tco']) * 100,1),'breakeven_required_breach_probability': (annual_model['total_direct_cost'] - continuous_model['total_direct_cost']) / avg_breach_cost,'recommendation': 'Continuous'iftco_savings > 0else'Annual','primary_savings_driver': ('Breach risk reduction'ifcontinuous_model['expected_breach_cost'] <
annual_model['expected_breach_cost'] * 0.5else'Engineering efficiency')}}# Example calculation:example_org = {'annual_revenue': 10_000_000,'deployments_per_year': 52,# Weekly releases'engineering_team_size': 15,'avg_engineer_hourly_cost': 100,'estimated_breach_probability': 0.12,# 12% annual breach probability'avg_breach_cost': 500_000}result = calculate_tco_comparison(example_org)print(f"Annual model TCO: ${result['comparison']['annual_tco']:,}")print(f"Continuous model TCO: ${result['comparison']['continuous_tco']:,}")print(f"Expected savings: ${result['comparison']['tco_savings']:,}")
defcalculate_tco_comparison(org_profile: dict) -> dict:
"""
Calculate Total Cost of Ownership for annual vs continuous security testing.
Includes direct costs, breach probability adjustment, and remediation costs.
"""# Organization profile inputsannual_revenue = org_profile['annual_revenue']deployment_frequency_per_year = org_profile['deployments_per_year']engineering_team_size = org_profile['engineering_team_size']avg_engineer_hourly_cost = org_profile['avg_engineer_hourly_cost']breach_probability_annual = org_profile['estimated_breach_probability']# e.g., 0.15 = 15%avg_breach_cost = org_profile['avg_breach_cost']# all-in cost if breach occurs# ═══════════════════════════════════════════════════════# ANNUAL PENETRATION TESTING MODEL# ═══════════════════════════════════════════════════════annual_model = {}# Direct costsannual_model['pentest_cost'] = 25000# Typical annual pentest (1 week, 1-2 testers)annual_model['retest_cost'] = 8000# Retest after remediation# Engineering remediation costs# Average: 8 findings, 3 days engineering per findingavg_findings = 8avg_remediation_days = 3annual_model['engineering_remediation_cost'] = (avg_findings * avg_remediation_days * 8 * # 8 hours/dayavg_engineer_hourly_cost)# Emergency response costs (for critical findings discovered late)# Annual model has longer gap → higher probability of undetected critical issue# that then requires emergency responseprob_emergency_response = 0.35# 35% chance of emergency security incidentavg_emergency_response_cost = 50000# War room, hotfix, communicationannual_model['expected_emergency_response_cost'] = (prob_emergency_response * avg_emergency_response_cost)# Alert fatigue / wasted engineering time on non-exploitable findings# Annual test typically has higher percentage of false positives vs continuousannual_model['false_positive_remediation_waste'] = (avg_findings * 0.3 * # 30% false positive rate for annual2 * 8 * # 2 days to discover and document it's a false positiveavg_engineer_hourly_cost)# Breach risk — adjusted for longer exposure window# Annual model has ~180 day average undetected vulnerability window# Breach probability scales with exposure windowexposure_window_days_annual = 180annual_model['adjusted_breach_probability'] = breach_probability_annual * (exposure_window_days_annual / 365)annual_model['expected_breach_cost'] = (annual_model['adjusted_breach_probability'] * avg_breach_cost)annual_model['total_direct_cost'] = (annual_model['pentest_cost'] +
annual_model['retest_cost'] +
annual_model['engineering_remediation_cost'] +
annual_model['expected_emergency_response_cost'] +
annual_model['false_positive_remediation_waste'])annual_model['total_tco'] = (annual_model['total_direct_cost'] +
annual_model['expected_breach_cost'])# ═══════════════════════════════════════════════════════# CONTINUOUS PENETRATION TESTING MODEL# ═══════════════════════════════════════════════════════continuous_model = {}# Direct costs — subscription modelcontinuous_model['monthly_subscription'] = 4500# Typical continuous programcontinuous_model['annual_subscription_cost'] = continuous_model['monthly_subscription'] * 12# Engineering remediation costs — findings caught earlier are cheaper to fix# Studies show: 6x cheaper to fix in development vs production# Continuous testing catches most issues within 2 weeks of introductioncontinuous_avg_findings = 12# More findings per year (nothing escapes for 11 months)continuous_avg_remediation_days = 1.5# Caught earlier = simpler fix (feature branch)continuous_model['engineering_remediation_cost'] = (continuous_avg_findings * continuous_avg_remediation_days * 8 *
avg_engineer_hourly_cost)# Emergency response costs — much lower (issues caught before breach)prob_emergency_response_continuous = 0.08# 8% vs 35% for annualcontinuous_model['expected_emergency_response_cost'] = (prob_emergency_response_continuous * avg_emergency_response_cost)# Near-zero false positive waste — continuous testing is more targetedcontinuous_model['false_positive_remediation_waste'] = (continuous_avg_findings * 0.05 * # 5% false positive rate1 * 8 *
avg_engineer_hourly_cost)# Breach risk — dramatically reduced exposure windowexposure_window_days_continuous = 14# 2-week sprint cadencecontinuous_model['adjusted_breach_probability'] = breach_probability_annual * (exposure_window_days_continuous / 365)continuous_model['expected_breach_cost'] = (continuous_model['adjusted_breach_probability'] * avg_breach_cost)continuous_model['total_direct_cost'] = (continuous_model['annual_subscription_cost'] +
continuous_model['engineering_remediation_cost'] +
continuous_model['expected_emergency_response_cost'] +
continuous_model['false_positive_remediation_waste'])continuous_model['total_tco'] = (continuous_model['total_direct_cost'] +
continuous_model['expected_breach_cost'])# Comparisontco_savings = annual_model['total_tco'] - continuous_model['total_tco']return{'organization_profile': org_profile,'annual_model': annual_model,'continuous_model': continuous_model,'comparison': {'annual_tco': round(annual_model['total_tco']),'continuous_tco': round(continuous_model['total_tco']),'tco_savings': round(tco_savings),'savings_percentage': round((tco_savings / annual_model['total_tco']) * 100,1),'breakeven_required_breach_probability': (annual_model['total_direct_cost'] - continuous_model['total_direct_cost']) / avg_breach_cost,'recommendation': 'Continuous'iftco_savings > 0else'Annual','primary_savings_driver': ('Breach risk reduction'ifcontinuous_model['expected_breach_cost'] <
annual_model['expected_breach_cost'] * 0.5else'Engineering efficiency')}}# Example calculation:example_org = {'annual_revenue': 10_000_000,'deployments_per_year': 52,# Weekly releases'engineering_team_size': 15,'avg_engineer_hourly_cost': 100,'estimated_breach_probability': 0.12,# 12% annual breach probability'avg_breach_cost': 500_000}result = calculate_tco_comparison(example_org)print(f"Annual model TCO: ${result['comparison']['annual_tco']:,}")print(f"Continuous model TCO: ${result['comparison']['continuous_tco']:,}")print(f"Expected savings: ${result['comparison']['tco_savings']:,}")
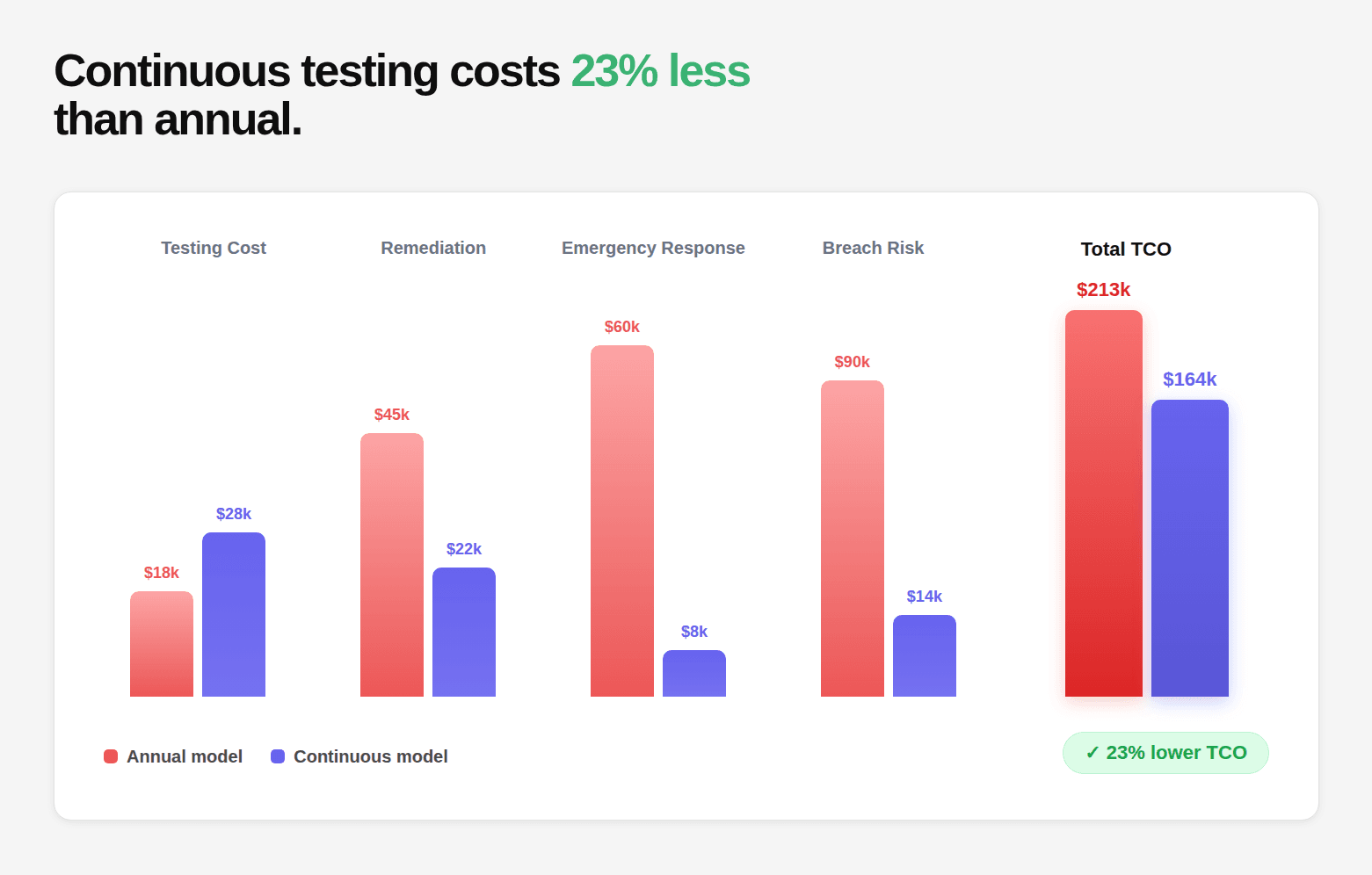
The Economics Summary Table
Cost Category
Annual Model
Continuous Model
Delta
Direct testing cost
$25,000–$50,000
$48,000–$72,000/yr (sub)
+$10K–$25K
Retest cost
$8,000–$15,000
Included in subscription
-$12K
Engineering remediation
$19,200 (8 findings × 3 days)
$14,400 (12 findings × 1.5 days)
-$4,800
False positive waste
$9,600 (30% false positive)
$1,600 (5% false positive)
-$8,000
Emergency response
$17,500 (35% probability)
$4,000 (8% probability)
-$13,500
Expected breach cost ($500K × probability)
$24,657 (180-day window)
$1,644 (14-day window)
-$23,013
Total TCO
~$104,000
~$80,000
-$24,000
These are illustrative figures for a company with $10M ARR, weekly releases, 15 engineers at $100/hr, 12% breach probability, $500K average breach cost.
The Maturity Model: Which Testing Cadence Fits Your Organization
The Security Testing Maturity Framework
Not every organization needs or can operationalize the same testing model. The correct cadence depends on deployment velocity, risk profile, team maturity, and compliance requirements:
Maturity Level
Description
Deployment Velocity
Testing Model
Minimum Frequency
Level 0
No structured security testing
Any
Annual minimum
Annual
Level 1
Compliance-driven testing
Monthly or less
Annual + automated scanning
Annual
Level 2
Risk-aware testing
Bi-weekly
Quarterly + sprint-aware
Quarterly
Level 3
DevSecOps-integrated testing
Weekly
Sprint-cadence + monthly deep
Per-sprint
Level 4
Continuous security program
Daily
Continuous all layers
Ongoing
Level 5
Security-native development
Continuous
Embedded, automated + weekly deep
Real-time
Decision Framework: Annual vs Continuous
Choosing the right testing model depends on three factors:
how fast your system changes
how sensitive your data is
what your compliance requirements demand
Instead of a single answer, use this decision framework.
1. How Often Do You Deploy?
Your deployment frequency directly determines how quickly risk accumulates.
Deployment Frequency
Recommended Model
Why It Matters
What to Invest In
Less than monthly
Annual or semi-annual
Attack surface changes slowly
Strong pre-deployment security reviews
Monthly to bi-weekly
Quarterly (minimum)
New risk accumulates faster than annual coverage
Quarterly external tests + automated regression
Weekly or more
Continuous or sprint-based
Annual testing covers <10% of deployments
Security program aligned with release cadence
2. What Data Do You Handle?
Data sensitivity changes both risk tolerance and testing frequency requirements.
Data Type
Recommended Approach
Why
PII (>10K users), payment data, health data
Quarterly or continuous (minimum annual for compliance)
Breach impact + regulatory exposure is high
Business confidential, moderate PII
Annual minimum, quarterly if deploying frequently
Risk grows with deployment velocity
Internal tools, low sensitivity
Annual may be sufficient
Lower impact if compromised
👉 In high-risk environments, economics shift, breach cost often justifies continuous testing.
3. What Is Your Regulatory Environment?
Compliance sets the minimum, not the optimal level of security.
Framework
Requirement
What It Actually Means
PCI-DSS Level 1/2
Annual pentest required
Continuous testing supplements, not replaces
SOC 2 Type II
Annual expected
Continuous testing strengthens audit posture
HIPAA
Annual risk assessment
Testing frequency is risk-based
ISO 27001
Annual pentest (typical)
Continuous monitoring required
👉 Key insight: Compliance ≠ sufficient security
4. Do You Have a Security Team?
Your ability to act on findings determines how continuous your model can be.
Team Setup
Recommended Model
Why
Dedicated security team (even 1 person)
Continuous testing
Can triage and respond in real time
No dedicated team (shared responsibility)
Sprint-based / monthly cadence
Prevents alert overload
No team + no plans
Quarterly testing
Continuous model will fail operationally
Final Recommendation
If you simplify everything above, the decision comes down to this:
Scenario
Recommended Model
High velocity (weekly+) + sensitive data + budget
Continuous
High velocity (weekly+) + sensitive data + limited budget
Quarterly
Moderate velocity (monthly) + sensitive data
Quarterly
Moderate velocity + low sensitivity
Semi-annual
Low velocity (monthly or less)
Annual
That said, the right testing model is not about preference. It’s about alignment. If your system changes faster than your testing cycle, risk accumulates faster than it is detected.
The Finding SLA Matrix for Continuous Programs
Continuous testing requires clear SLAs, because findings arrive continuously, the team needs defined timelines for each severity:
Severity
CVSS Range
Acknowledgment SLA
Remediation SLA
Retest SLA
Escalation
Critical
9.0–10.0
4 hours
48 hours
Within 24h of fix
C-suite notification
High
7.0–8.9
24 hours
7 days
Within 48h of fix
Security team lead
Medium
4.0–6.9
72 hours
30 days
Within sprint
Engineering manager
Low
0.1–3.9
1 week
90 days
Next quarterly
Backlog
Informational
N/A
2 weeks
Next roadmap
N/A
None
Common Failure Modes in Continuous Testing Programs
Why Continuous Programs Fail After 6 Months
Organizations that start continuous testing programs often abandon them within 6–12 months. The failure patterns are consistent:
Metrics That Define a Successful Continuous Program
The KPI Stack for Continuous Security Testing
class ContinuousSecurityProgramMetrics:
"""Track and report continuous security testing program effectiveness"""defcalculate_program_kpis(self,program_data: dict) -> dict:
findings_data = program_data['findings']test_events = program_data['test_events']deployments = program_data['deployments']# KPI 1: Mean Time to Detection (MTTD)# How long from vulnerability introduction to detection?mttd_values = []forfindinginfindings_data:
iffinding.get('introduction_date')andfinding.get('detection_date'):
days = (finding['detection_date'] - finding['introduction_date']).daysmttd_values.append(days)mttd = sum(mttd_values) / len(mttd_values)ifmttd_valueselseNone# KPI 2: Mean Time to Remediation (MTTR)# How long from detection to confirmed fix?mttr_values = []forfindinginfindings_data:
iffinding.get('detection_date')andfinding.get('remediation_date'):
days = (finding['remediation_date'] - finding['detection_date']).daysmttr_values.append(days)mttr = sum(mttr_values) / len(mttr_values)ifmttr_valueselseNone# KPI 3: Vulnerability Introduction Rate# New security findings per 100 deploymentstotal_findings = len(findings_data)total_deployments = len(deployments)vuln_rate = (total_findings / total_deployments * 100)iftotal_deploymentselse0# KPI 4: Escape Rate# Percentage of vulnerabilities NOT caught before production# (Found by external researchers or incident response, not internal testing)external_discoveries = sum(1forfinfindings_dataiff.get('discovered_by') == 'external')escape_rate = (external_discoveries / total_findings * 100)iftotal_findingselse0# KPI 5: SLA Compliance Rate# Percentage of findings remediated within defined SLAssla_compliant = sum(1forfinfindings_dataiff.get('remediated_within_sla') == True)sla_rate = (sla_compliant / total_findings * 100)iftotal_findingselse0# KPI 6: CVSS Trend# Is the average CVSS of findings going up or down over time?monthly_avg_cvss = {}forfindinginfindings_data:
month = finding['detection_date'].strftime('%Y-%m')ifmonthnotinmonthly_avg_cvss:
monthly_avg_cvss[month] = []monthly_avg_cvss[month].append(finding['cvss'])cvss_trend = {month: sum(scores) / len(scores)formonth,scoresinmonthly_avg_cvss.items()}# KPI 7: Attack Surface Growth Rate# How fast is the untested attack surface growing?surface_snapshots = program_data.get('surface_snapshots',[])iflen(surface_snapshots) >= 2:
first = surface_snapshots[0]last = surface_snapshots[-1]surface_growth = ((len(last['endpoints']) - len(first['endpoints'])) /
len(first['endpoints']) * 100)else:
surface_growth = Nonereturn{'mean_time_to_detection_days': round(mttd,1)ifmttdelse'N/A','mean_time_to_remediation_days': round(mttr,1)ifmttrelse'N/A','vulnerability_introduction_rate_per_100_deployments': round(vuln_rate,2),'escape_rate_percent': round(escape_rate,1),'sla_compliance_rate_percent': round(sla_rate,1),'cvss_trend_by_month': cvss_trend,'attack_surface_growth_percent': round(surface_growth,1)ifsurface_growthelse'N/A','program_health': self.assess_program_health(mttd,mttr,escape_rate,sla_rate),'benchmarks': {'mttd_industry_annual': 180,# days'mttd_industry_continuous': 14,'mttd_your_program': mttd,'mttr_pci_requirement_critical': 1,# day'sla_compliance_target': 95,# percent}}defassess_program_health(self,mttd,mttr,escape_rate,sla_rate) -> str:
score = 0ifmttdandmttd < 14: score += 2elifmttdandmttd < 30: score += 1ifmttrandmttr < 7: score += 2elifmttrandmttr < 30: score += 1ifescape_rate < 5: score += 2elifescape_rate < 15: score += 1ifsla_rate > 95: score += 2elifsla_rate > 80: score += 1ifscore >= 7: return'EXCELLENT'elifscore >= 5: return'GOOD'elifscore >= 3: return'IMPROVING'else: return'NEEDS_ATTENTION'
class ContinuousSecurityProgramMetrics:
"""Track and report continuous security testing program effectiveness"""defcalculate_program_kpis(self,program_data: dict) -> dict:
findings_data = program_data['findings']test_events = program_data['test_events']deployments = program_data['deployments']# KPI 1: Mean Time to Detection (MTTD)# How long from vulnerability introduction to detection?mttd_values = []forfindinginfindings_data:
iffinding.get('introduction_date')andfinding.get('detection_date'):
days = (finding['detection_date'] - finding['introduction_date']).daysmttd_values.append(days)mttd = sum(mttd_values) / len(mttd_values)ifmttd_valueselseNone# KPI 2: Mean Time to Remediation (MTTR)# How long from detection to confirmed fix?mttr_values = []forfindinginfindings_data:
iffinding.get('detection_date')andfinding.get('remediation_date'):
days = (finding['remediation_date'] - finding['detection_date']).daysmttr_values.append(days)mttr = sum(mttr_values) / len(mttr_values)ifmttr_valueselseNone# KPI 3: Vulnerability Introduction Rate# New security findings per 100 deploymentstotal_findings = len(findings_data)total_deployments = len(deployments)vuln_rate = (total_findings / total_deployments * 100)iftotal_deploymentselse0# KPI 4: Escape Rate# Percentage of vulnerabilities NOT caught before production# (Found by external researchers or incident response, not internal testing)external_discoveries = sum(1forfinfindings_dataiff.get('discovered_by') == 'external')escape_rate = (external_discoveries / total_findings * 100)iftotal_findingselse0# KPI 5: SLA Compliance Rate# Percentage of findings remediated within defined SLAssla_compliant = sum(1forfinfindings_dataiff.get('remediated_within_sla') == True)sla_rate = (sla_compliant / total_findings * 100)iftotal_findingselse0# KPI 6: CVSS Trend# Is the average CVSS of findings going up or down over time?monthly_avg_cvss = {}forfindinginfindings_data:
month = finding['detection_date'].strftime('%Y-%m')ifmonthnotinmonthly_avg_cvss:
monthly_avg_cvss[month] = []monthly_avg_cvss[month].append(finding['cvss'])cvss_trend = {month: sum(scores) / len(scores)formonth,scoresinmonthly_avg_cvss.items()}# KPI 7: Attack Surface Growth Rate# How fast is the untested attack surface growing?surface_snapshots = program_data.get('surface_snapshots',[])iflen(surface_snapshots) >= 2:
first = surface_snapshots[0]last = surface_snapshots[-1]surface_growth = ((len(last['endpoints']) - len(first['endpoints'])) /
len(first['endpoints']) * 100)else:
surface_growth = Nonereturn{'mean_time_to_detection_days': round(mttd,1)ifmttdelse'N/A','mean_time_to_remediation_days': round(mttr,1)ifmttrelse'N/A','vulnerability_introduction_rate_per_100_deployments': round(vuln_rate,2),'escape_rate_percent': round(escape_rate,1),'sla_compliance_rate_percent': round(sla_rate,1),'cvss_trend_by_month': cvss_trend,'attack_surface_growth_percent': round(surface_growth,1)ifsurface_growthelse'N/A','program_health': self.assess_program_health(mttd,mttr,escape_rate,sla_rate),'benchmarks': {'mttd_industry_annual': 180,# days'mttd_industry_continuous': 14,'mttd_your_program': mttd,'mttr_pci_requirement_critical': 1,# day'sla_compliance_target': 95,# percent}}defassess_program_health(self,mttd,mttr,escape_rate,sla_rate) -> str:
score = 0ifmttdandmttd < 14: score += 2elifmttdandmttd < 30: score += 1ifmttrandmttr < 7: score += 2elifmttrandmttr < 30: score += 1ifescape_rate < 5: score += 2elifescape_rate < 15: score += 1ifsla_rate > 95: score += 2elifsla_rate > 80: score += 1ifscore >= 7: return'EXCELLENT'elifscore >= 5: return'GOOD'elifscore >= 3: return'IMPROVING'else: return'NEEDS_ATTENTION'
class ContinuousSecurityProgramMetrics:
"""Track and report continuous security testing program effectiveness"""defcalculate_program_kpis(self,program_data: dict) -> dict:
findings_data = program_data['findings']test_events = program_data['test_events']deployments = program_data['deployments']# KPI 1: Mean Time to Detection (MTTD)# How long from vulnerability introduction to detection?mttd_values = []forfindinginfindings_data:
iffinding.get('introduction_date')andfinding.get('detection_date'):
days = (finding['detection_date'] - finding['introduction_date']).daysmttd_values.append(days)mttd = sum(mttd_values) / len(mttd_values)ifmttd_valueselseNone# KPI 2: Mean Time to Remediation (MTTR)# How long from detection to confirmed fix?mttr_values = []forfindinginfindings_data:
iffinding.get('detection_date')andfinding.get('remediation_date'):
days = (finding['remediation_date'] - finding['detection_date']).daysmttr_values.append(days)mttr = sum(mttr_values) / len(mttr_values)ifmttr_valueselseNone# KPI 3: Vulnerability Introduction Rate# New security findings per 100 deploymentstotal_findings = len(findings_data)total_deployments = len(deployments)vuln_rate = (total_findings / total_deployments * 100)iftotal_deploymentselse0# KPI 4: Escape Rate# Percentage of vulnerabilities NOT caught before production# (Found by external researchers or incident response, not internal testing)external_discoveries = sum(1forfinfindings_dataiff.get('discovered_by') == 'external')escape_rate = (external_discoveries / total_findings * 100)iftotal_findingselse0# KPI 5: SLA Compliance Rate# Percentage of findings remediated within defined SLAssla_compliant = sum(1forfinfindings_dataiff.get('remediated_within_sla') == True)sla_rate = (sla_compliant / total_findings * 100)iftotal_findingselse0# KPI 6: CVSS Trend# Is the average CVSS of findings going up or down over time?monthly_avg_cvss = {}forfindinginfindings_data:
month = finding['detection_date'].strftime('%Y-%m')ifmonthnotinmonthly_avg_cvss:
monthly_avg_cvss[month] = []monthly_avg_cvss[month].append(finding['cvss'])cvss_trend = {month: sum(scores) / len(scores)formonth,scoresinmonthly_avg_cvss.items()}# KPI 7: Attack Surface Growth Rate# How fast is the untested attack surface growing?surface_snapshots = program_data.get('surface_snapshots',[])iflen(surface_snapshots) >= 2:
first = surface_snapshots[0]last = surface_snapshots[-1]surface_growth = ((len(last['endpoints']) - len(first['endpoints'])) /
len(first['endpoints']) * 100)else:
surface_growth = Nonereturn{'mean_time_to_detection_days': round(mttd,1)ifmttdelse'N/A','mean_time_to_remediation_days': round(mttr,1)ifmttrelse'N/A','vulnerability_introduction_rate_per_100_deployments': round(vuln_rate,2),'escape_rate_percent': round(escape_rate,1),'sla_compliance_rate_percent': round(sla_rate,1),'cvss_trend_by_month': cvss_trend,'attack_surface_growth_percent': round(surface_growth,1)ifsurface_growthelse'N/A','program_health': self.assess_program_health(mttd,mttr,escape_rate,sla_rate),'benchmarks': {'mttd_industry_annual': 180,# days'mttd_industry_continuous': 14,'mttd_your_program': mttd,'mttr_pci_requirement_critical': 1,# day'sla_compliance_target': 95,# percent}}defassess_program_health(self,mttd,mttr,escape_rate,sla_rate) -> str:
score = 0ifmttdandmttd < 14: score += 2elifmttdandmttd < 30: score += 1ifmttrandmttr < 7: score += 2elifmttrandmttr < 30: score += 1ifescape_rate < 5: score += 2elifescape_rate < 15: score += 1ifsla_rate > 95: score += 2elifsla_rate > 80: score += 1ifscore >= 7: return'EXCELLENT'elifscore >= 5: return'GOOD'elifscore >= 3: return'IMPROVING'else: return'NEEDS_ATTENTION'
The Security Posture Dashboard
Metric
Annual Model Baseline
Continuous Program Target
Why It Matters
Mean Time to Detection
~180 days
<14 days
Determines breach window
Mean Time to Remediation
~45 days (batch quarterly)
<7 days (continuous pipeline)
Reduces risk-open duration
Vulnerability Escape Rate
~25% (found by others first)
<5%
Measures program effectiveness
SLA Compliance Rate
~60%
>95%
Audit evidence quality
False Positive Rate
~40%
<10%
Engineering team trust
Attack Surface Coverage
~70% (tested version drifts)
>95% (weekly updates)
Completeness of protection
CVSS Trend (target: declining)
Uncorrelated
Measurable decline
Program impact evidence
The Gap Closes Every Sprint or It Never Closes
Annual penetration testing assumes your application stays roughly the same all year. It doesn’t. If you ship weekly, that assumption breaks within weeks not months.
What you’re left with is a growing exposure window:
new code is deployed
new attack surface is introduced
new vulnerabilities go untested
This is the deployment velocity gap, and it’s measurable. Continuous penetration testing fixes this by aligning security cadence with deployment cadence.
Instead of testing once and hoping it holds, every change gets evaluated within the same cycle it was introduced.
New sprint → new attack surface
New attack surface → new testing
No change goes untested for long
That’s how the gap actually closes. The impact is straightforward:
Detection time drops from months to days
Undetected vulnerability windows shrink significantly
Security becomes part of delivery, not a checkpoint after it
And unlike annual testing, you’re not relying on a single snapshot. You’re building continuous evidence that your system is secure right now.
CodeAnt AI’s continuous pentesting model is built for teams that ship fast:
Sprint-cadence security testing aligned with releases
Critical findings surfaced within 48 hours
Continuous visibility into your real attack surface