Why Penetration Testing Methodology Matters in 2026
Sonali Sood
Founding GTM, CodeAnt AI
Two pentesting firms quote you the same price for a web application assessment. Both say they use AI. Both promise a comprehensive report. Both have reasonable-sounding websites.
The difference between them, the difference between finding your most critical vulnerability and missing it entirely, is methodology. Specifically: what does the tester actually do, in what sequence, with what tools, and how do they reason about what they find?
Methodology is not a marketing word. It is the operational definition of what happens inside the engagement. A firm with a strong methodology and average tools beats a firm with strong tools and no methodology every time. Tools don't find vulnerabilities. Reasoning about what tools reveal finds vulnerabilities.
This guide walks through the complete methodology of an AI penetration testing engagement, phase by phase.
The Architecture of a Complete AI Pentest Engagement
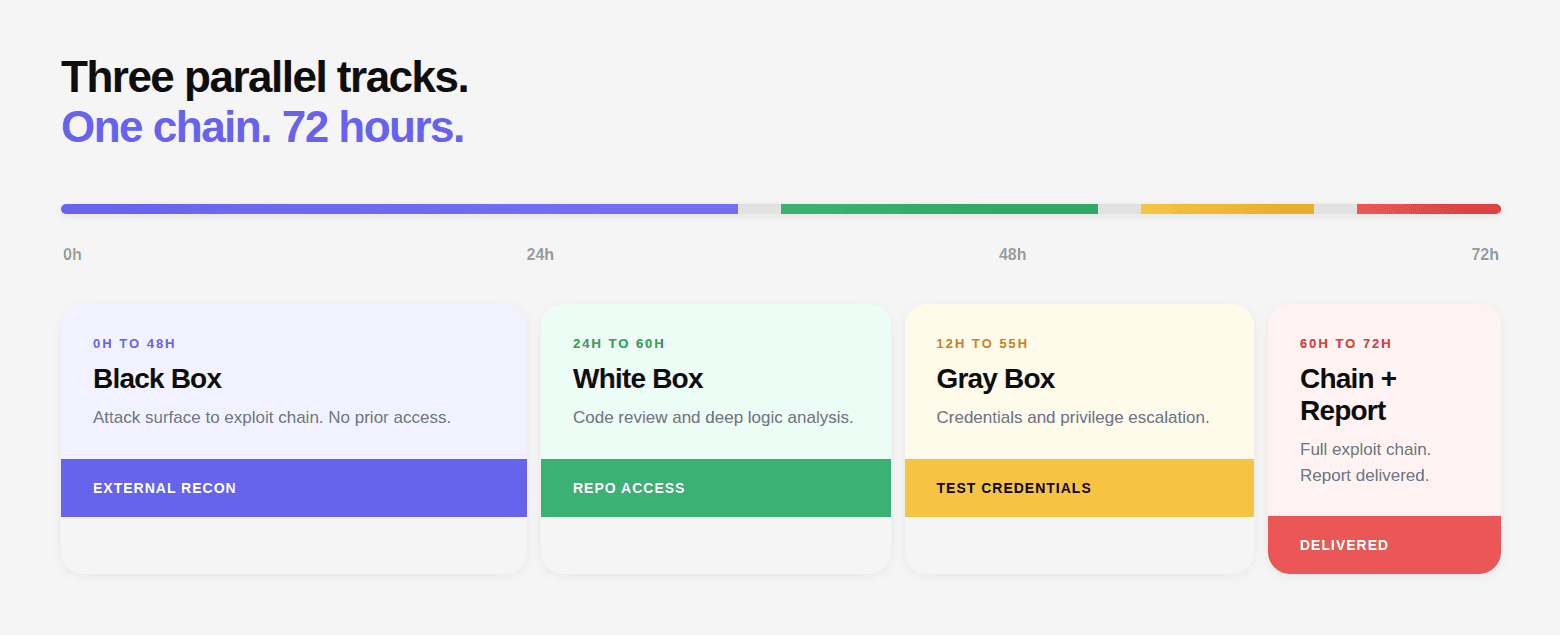
Before going phase by phase, it helps to see the full architecture. A complete AI penetration test, the Full Assessment that covers all three test types, follows this sequence:
Several phases run in parallel. The white box source code analysis starts as soon as repository access is granted and runs concurrently with the black box external testing. The grey box authenticated testing begins once reconnaissance has produced a working map of the attack surface. Chain construction synthesizes findings from all parallel tracks.
The output of each phase feeds subsequent phases. Subdomains found in Phase 1 become targets in Phase 5. Endpoints discovered in Phase 3 JS analysis become targets for authentication bypass testing in Phase 5. Findings from Phase 4 code review inform what chains are possible in Phase 7. The phases are not independent checkboxes, they are an interconnected reasoning process.
Phase 0: Scoping and Authorization: The 30 Minutes That Define Everything
Why Scoping Matters More Than Any Tool
A penetration test without a properly defined scope is not a penetration test. It is liability without accountability. The scope document defines what's being tested, under what rules, with what authorization, and it's the difference between a legitimate security engagement and unauthorized computer access.
The scoping call accomplishes five specific things:
1. Target definition: What exactly is being tested? The production web application? The staging API? Specific microservices? Mobile backend? The scope must be precise, not "our application" but specific domain names, IP ranges, repository URLs, and test account credentials.
2. Test type selection: Black box, white box, grey box, or Full Assessment. This determines what access is needed, what credentials are provided, and what the engagement will and won't find.
3. Rules of engagement: Timing windows. Whether denial-of-service testing is permitted. Whether social engineering is in scope. Whether physical security is included. How critical findings are escalated during the test, do you get a call the moment a CVSS 9+ is confirmed, or do you wait for the final report?
4. Authorization documentation: This is non-negotiable. A signed authorization letter from the organization's legal representative explicitly permitting penetration testing against the defined scope, for the defined period, by the defined testing entity. Without this, the engagement cannot proceed. This document is what distinguishes a penetration tester from an attacker in the eyes of law enforcement.
5. Communication protocol: Who receives the report? Who is the engineering point of contact during the engagement? If the team discovers an active breach in progress, not a test finding but evidence of a real, ongoing attack, what is the escalation path?
After the scoping call: fixed-price quote delivered same day, authorization letter issued, testing begins within 24 hours.
Phase 1: Reconnaissance and External Surface Mapping
Building the Complete Attack Surface Map
Reconnaissance is the foundation everything else is built on. Every target missed in this phase is a potential vulnerability that never gets tested. Thoroughness here is not optional.
The AI begins external reconnaissance immediately after scope is confirmed. The goal: build the most complete possible picture of everything externally accessible before a single vulnerability is probed.
DNS enumeration and subdomain discovery:
The enumeration runs against a wordlist of 150+ common subdomain prefixes, plus any organization-specific terms derived from the company name, products, or technologies identified during initial research.
# DNS brute force — illustrative of the approach# Checking each prefix against the target domainprefixes=(www api app admin portal dashboard staging dev qa uat test
beta preview demo internal monitor jenkins grafana kibana
elastic auth oauth sso login accounts id identity payment
billing checkout status health metrics logs assets cdn files
uploads backup old legacy archive v1 v2 api-v1 api-v2 ...)
for prefix in"${prefixes[@]}"; doresult=$(dig +short "$prefix.company.com")if [ -n"$result" ]; thenecho"FOUND: $prefix.company.com → $result"fidone# Sample output:# FOUND: app.company.com → 52.14.88.123# FOUND: api.company.com → 52.14.88.124# FOUND: staging.company.com → 10.0.0.5 [← internal IP, externally resolvable]# FOUND: jenkins.company.com → 52.14.88.130# FOUND: grafana.company.com → 52.14.88.131# FOUND: old-api.company.com → 52.14.88.119 [← legacy, potentially outdated]
# DNS brute force — illustrative of the approach# Checking each prefix against the target domainprefixes=(www api app admin portal dashboard staging dev qa uat test
beta preview demo internal monitor jenkins grafana kibana
elastic auth oauth sso login accounts id identity payment
billing checkout status health metrics logs assets cdn files
uploads backup old legacy archive v1 v2 api-v1 api-v2 ...)
for prefix in"${prefixes[@]}"; doresult=$(dig +short "$prefix.company.com")if [ -n"$result" ]; thenecho"FOUND: $prefix.company.com → $result"fidone# Sample output:# FOUND: app.company.com → 52.14.88.123# FOUND: api.company.com → 52.14.88.124# FOUND: staging.company.com → 10.0.0.5 [← internal IP, externally resolvable]# FOUND: jenkins.company.com → 52.14.88.130# FOUND: grafana.company.com → 52.14.88.131# FOUND: old-api.company.com → 52.14.88.119 [← legacy, potentially outdated]
# DNS brute force — illustrative of the approach# Checking each prefix against the target domainprefixes=(www api app admin portal dashboard staging dev qa uat test
beta preview demo internal monitor jenkins grafana kibana
elastic auth oauth sso login accounts id identity payment
billing checkout status health metrics logs assets cdn files
uploads backup old legacy archive v1 v2 api-v1 api-v2 ...)
for prefix in"${prefixes[@]}"; doresult=$(dig +short "$prefix.company.com")if [ -n"$result" ]; thenecho"FOUND: $prefix.company.com → $result"fidone# Sample output:# FOUND: app.company.com → 52.14.88.123# FOUND: api.company.com → 52.14.88.124# FOUND: staging.company.com → 10.0.0.5 [← internal IP, externally resolvable]# FOUND: jenkins.company.com → 52.14.88.130# FOUND: grafana.company.com → 52.14.88.131# FOUND: old-api.company.com → 52.14.88.119 [← legacy, potentially outdated]
Certificate Transparency log queries:
CT logs record every TLS certificate ever issued. Querying them surfaces subdomains that DNS brute-forcing misses, because the subdomain existed when the certificate was issued, even if it's no longer in active DNS rotation.
importrequestsdefquery_ct_logs(domain):
# crt.sh aggregates CT log data from all major certificate authoritiesurl = f"<https://crt.sh/?q=%.{domain>}&output=json"response = requests.get(url,timeout=30)ifresponse.status_code == 200:
certificates = response.json()subdomains = set()forcertincertificates:
# name_value contains the domain in the certificatenames = cert['name_value'].split('\\n')fornameinnames:
name = name.strip()ifname.endswith(f'.{domain}')and'*'notinname:
subdomains.add(name)returnsorted(subdomains)# Returns every subdomain that ever had a TLS certificate issued# Including ones removed from DNS but potentially still running a server
importrequestsdefquery_ct_logs(domain):
# crt.sh aggregates CT log data from all major certificate authoritiesurl = f"<https://crt.sh/?q=%.{domain>}&output=json"response = requests.get(url,timeout=30)ifresponse.status_code == 200:
certificates = response.json()subdomains = set()forcertincertificates:
# name_value contains the domain in the certificatenames = cert['name_value'].split('\\n')fornameinnames:
name = name.strip()ifname.endswith(f'.{domain}')and'*'notinname:
subdomains.add(name)returnsorted(subdomains)# Returns every subdomain that ever had a TLS certificate issued# Including ones removed from DNS but potentially still running a server
importrequestsdefquery_ct_logs(domain):
# crt.sh aggregates CT log data from all major certificate authoritiesurl = f"<https://crt.sh/?q=%.{domain>}&output=json"response = requests.get(url,timeout=30)ifresponse.status_code == 200:
certificates = response.json()subdomains = set()forcertincertificates:
# name_value contains the domain in the certificatenames = cert['name_value'].split('\\n')fornameinnames:
name = name.strip()ifname.endswith(f'.{domain}')and'*'notinname:
subdomains.add(name)returnsorted(subdomains)# Returns every subdomain that ever had a TLS certificate issued# Including ones removed from DNS but potentially still running a server
Port scanning:
Every discovered host gets a full port scan. Not just 80 and 443. The complete TCP range, with service identification on every open port.
Discovery
What Gets Checked
High-Priority Finding
Port 6379 open
Redis, authentication required?
Unauthenticated Redis → full data read/write
Port 9200 open
Elasticsearch, authentication?
Unauthenticated → all indices readable
Port 8080/8443
Internal API or admin panel
Admin interface exposed to internet
Port 3000
Grafana, Node dev server
Dashboard or dev environment exposed
Port 9090
Prometheus metrics
All application metrics publicly readable
Port 27017
MongoDB
Database directly accessible
Port 5432
PostgreSQL
Database directly accessible
Port 9229
Node.js inspector
Remote code execution if accessible
Port 22
SSH
Default credentials or key exposure check
Port 8888
Jupyter Notebook
Code execution environment exposed
Every open port that shouldn't be publicly accessible gets documented and tested. An exposed Redis instance without authentication is a critical finding on its own, full read access to every key in the cache, which may include session tokens, API keys, and user data.
Cloud asset enumeration:
Cloud storage buckets, CDN configurations, serverless function endpoints, and managed service interfaces are enumerated separately from the web application surface.
# S3 bucket enumeration — common naming patterns testedimportboto3frombotocore.exceptionsimportClientErrordefcheck_s3_bucket(bucket_name):
s3 = boto3.client('s3',region_name='us-east-1')# Test 1: Can we list the bucket contents without credentials?try:
response = s3.list_objects_v2(Bucket=bucket_name)returnf"PUBLIC READ: {bucket_name} — {response['KeyCount']} objects"exceptClientErrorase:
error_code = e.response['Error']['Code']iferror_code == 'NoSuchBucket':
returnf"NOT FOUND: {bucket_name}"eliferror_code == 'AccessDenied':
returnf"EXISTS but PRIVATE: {bucket_name}"# Naming patterns tested:# company-backups, company-uploads, company-assets, company-logs# company-prod, company-staging, company-dev# app-company, api-company, company-data, company-exports# company.com, company-us-east-1, company-eu-west-1
# S3 bucket enumeration — common naming patterns testedimportboto3frombotocore.exceptionsimportClientErrordefcheck_s3_bucket(bucket_name):
s3 = boto3.client('s3',region_name='us-east-1')# Test 1: Can we list the bucket contents without credentials?try:
response = s3.list_objects_v2(Bucket=bucket_name)returnf"PUBLIC READ: {bucket_name} — {response['KeyCount']} objects"exceptClientErrorase:
error_code = e.response['Error']['Code']iferror_code == 'NoSuchBucket':
returnf"NOT FOUND: {bucket_name}"eliferror_code == 'AccessDenied':
returnf"EXISTS but PRIVATE: {bucket_name}"# Naming patterns tested:# company-backups, company-uploads, company-assets, company-logs# company-prod, company-staging, company-dev# app-company, api-company, company-data, company-exports# company.com, company-us-east-1, company-eu-west-1
# S3 bucket enumeration — common naming patterns testedimportboto3frombotocore.exceptionsimportClientErrordefcheck_s3_bucket(bucket_name):
s3 = boto3.client('s3',region_name='us-east-1')# Test 1: Can we list the bucket contents without credentials?try:
response = s3.list_objects_v2(Bucket=bucket_name)returnf"PUBLIC READ: {bucket_name} — {response['KeyCount']} objects"exceptClientErrorase:
error_code = e.response['Error']['Code']iferror_code == 'NoSuchBucket':
returnf"NOT FOUND: {bucket_name}"eliferror_code == 'AccessDenied':
returnf"EXISTS but PRIVATE: {bucket_name}"# Naming patterns tested:# company-backups, company-uploads, company-assets, company-logs# company-prod, company-staging, company-dev# app-company, api-company, company-data, company-exports# company.com, company-us-east-1, company-eu-west-1
A public S3 bucket containing customer exports or application backups is one of the most commonly found critical findings in black box engagements, and one of the most consistently preventable.
Phase 2: Service Fingerprinting and Configuration Analysis
Characterizing Every Discovered Service
Once the surface is mapped, every discovered service is characterized in detail. This fingerprinting phase builds the information that authentication bypass testing and vulnerability testing will use.
Framework and technology identification: HTTP response headers, error messages, cookie names, URL patterns, and response structure all reveal the technology stack. This matters because different frameworks have different vulnerability patterns and different configuration locations.
Security header analysis: Every domain gets a full HTTP security header audit. Missing or misconfigured headers are documented as findings with compliance impact:
Header
Expected Value
Finding If Missing/Wrong
Strict-Transport-Security
max-age=31536000; includeSubDomains
HTTP downgrade attack possible
Content-Security-Policy
Specific directive list
XSS impact scope unrestricted
X-Frame-Options
DENY or SAMEORIGIN
Clickjacking attacks possible
X-Content-Type-Options
nosniff
MIME sniffing attacks possible
Referrer-Policy
strict-origin-when-cross-origin
Sensitive URLs leak in Referer header
Permissions-Policy
Specific feature restrictions
Browser features unrestricted
SSL/TLS configuration audit: Protocol versions, cipher suites, certificate validity, and HSTS configuration are all checked. Accepting TLS 1.0 or 1.1, using weak cipher suites, or having a certificate chain with intermediate issues are all documented.
Email authentication: SPF, DMARC, and DKIM records are queried for every discovered domain. This assesses domain spoofing viability, whether an attacker could send convincing phishing emails from the target domain to its own users.
# Email authentication checks
dig TXT company.com | grep"v=spf1"# v=spf1 include:_spf.google.com ~all# ~all = soft fail (mark as spam but deliver) — not strict enough# Should be: -all (hard fail — reject)
dig TXT _dmarc.company.com
# v=DMARC1; p=none; rua=mailto:dmarc@company.com# p=none = no enforcement — attacker can spoof the domain freely# Should be: p=reject or p=quarantine# Finding: Domain spoofing viable# An attacker can send email from any @company.com address# with a high delivery rate to company.com users# Phishing precondition confirmed
# Email authentication checks
dig TXT company.com | grep"v=spf1"# v=spf1 include:_spf.google.com ~all# ~all = soft fail (mark as spam but deliver) — not strict enough# Should be: -all (hard fail — reject)
dig TXT _dmarc.company.com
# v=DMARC1; p=none; rua=mailto:dmarc@company.com# p=none = no enforcement — attacker can spoof the domain freely# Should be: p=reject or p=quarantine# Finding: Domain spoofing viable# An attacker can send email from any @company.com address# with a high delivery rate to company.com users# Phishing precondition confirmed
# Email authentication checks
dig TXT company.com | grep"v=spf1"# v=spf1 include:_spf.google.com ~all# ~all = soft fail (mark as spam but deliver) — not strict enough# Should be: -all (hard fail — reject)
dig TXT _dmarc.company.com
# v=DMARC1; p=none; rua=mailto:dmarc@company.com# p=none = no enforcement — attacker can spoof the domain freely# Should be: p=reject or p=quarantine# Finding: Domain spoofing viable# An attacker can send email from any @company.com address# with a high delivery rate to company.com users# Phishing precondition confirmed
Phase 3: JavaScript and Client-Side Analysis
Extracting What the Frontend Knows
Modern web applications serve megabytes of JavaScript to every visitor. This code contains a complete map of the application's API surface, every endpoint the frontend calls, every parameter it sends, every internal service it references. It also, consistently, contains secrets that were never meant to be there.
Bundle download and extraction: Every JavaScript file served by the application is downloaded. For a typical React or Vue SPA, this is between 3 and 20 MB of minified, compiled JavaScript, the compiled output of hundreds of source files, assembled by the build pipeline.
Every confirmed secret is verified before being reported. A Stripe API key gets tested against the Stripe API to determine whether it's a live key, what permissions it has, and what data it can access. An AWS access key gets tested against AWS STS to determine what IAM permissions it grants.
Staging vs. production comparison: If both staging and production bundles are accessible, they're compared. Endpoints present in the staging bundle but absent from the production bundle were removed from the UI, but they may still be deployed on the production API server.
defcompare_bundles(staging_endpoints,production_endpoints):
# Endpoints in staging but not in production bundlestaging_only = set(staging_endpoints) - set(production_endpoints)forendpointinstaging_only:
# These endpoints were removed from the frontend# but test whether they're still accessible on the production APIresult = test_endpoint_accessibility(f"<https://api.company.com>{endpoint}")ifresult.status_code == 200:
print(f"FINDING: {endpoint} removed from UI but still live in production")# This is typically a critical or high finding# The endpoint was intentionally removed — probably for a reason# It's still there and accessible
defcompare_bundles(staging_endpoints,production_endpoints):
# Endpoints in staging but not in production bundlestaging_only = set(staging_endpoints) - set(production_endpoints)forendpointinstaging_only:
# These endpoints were removed from the frontend# but test whether they're still accessible on the production APIresult = test_endpoint_accessibility(f"<https://api.company.com>{endpoint}")ifresult.status_code == 200:
print(f"FINDING: {endpoint} removed from UI but still live in production")# This is typically a critical or high finding# The endpoint was intentionally removed — probably for a reason# It's still there and accessible
defcompare_bundles(staging_endpoints,production_endpoints):
# Endpoints in staging but not in production bundlestaging_only = set(staging_endpoints) - set(production_endpoints)forendpointinstaging_only:
# These endpoints were removed from the frontend# but test whether they're still accessible on the production APIresult = test_endpoint_accessibility(f"<https://api.company.com>{endpoint}")ifresult.status_code == 200:
print(f"FINDING: {endpoint} removed from UI but still live in production")# This is typically a critical or high finding# The endpoint was intentionally removed — probably for a reason# It's still there and accessible
Phase 4: Source Code Analysis: The White Box Track
Reading the Codebase as an Attacker Would
The white box track runs in parallel with the external black box testing. With read-only repository access, the AI reads every authentication configuration, traces every data flow, scans every configuration file, and examines every commit in the repository history.
This phase is where CodeAnt AI's code comprehension capability is most directly applied. Building a code review SaaS product means deep, systematic understanding of how different frameworks implement authentication, where configurations break, and where data flows lead to exploitable sinks.
Authentication configuration deep-read: Every framework-specific authentication configuration is read end to end:
// What the white box analysis reads in a Spring Boot application:// 1. SecurityConfig.java — every filter chain rule// 2. WebSecurityCustomizer — every security exclusion// 3. @PreAuthorize annotations on every controller method// 4. Method security configuration// 5. CORS configuration (WebMvcConfigurer implementations)// 6. JWT filter implementation// 7. UserDetailsService implementation// 8. Custom authentication providers// Finding pattern: This combination is a confirmed bypass
@Beanpublic WebSecurityCustomizer webSecurityCustomizer(){return(web) -> web.ignoring()
.requestMatchers(new AntPathRequestMatcher("/api/v2/**"));// Every /api/v2/* route is completely unprotected// Including /api/v2/admin/*, /api/v2/export/*, etc.}
// What the white box analysis reads in a Spring Boot application:// 1. SecurityConfig.java — every filter chain rule// 2. WebSecurityCustomizer — every security exclusion// 3. @PreAuthorize annotations on every controller method// 4. Method security configuration// 5. CORS configuration (WebMvcConfigurer implementations)// 6. JWT filter implementation// 7. UserDetailsService implementation// 8. Custom authentication providers// Finding pattern: This combination is a confirmed bypass
@Beanpublic WebSecurityCustomizer webSecurityCustomizer(){return(web) -> web.ignoring()
.requestMatchers(new AntPathRequestMatcher("/api/v2/**"));// Every /api/v2/* route is completely unprotected// Including /api/v2/admin/*, /api/v2/export/*, etc.}
// What the white box analysis reads in a Spring Boot application:// 1. SecurityConfig.java — every filter chain rule// 2. WebSecurityCustomizer — every security exclusion// 3. @PreAuthorize annotations on every controller method// 4. Method security configuration// 5. CORS configuration (WebMvcConfigurer implementations)// 6. JWT filter implementation// 7. UserDetailsService implementation// 8. Custom authentication providers// Finding pattern: This combination is a confirmed bypass
@Beanpublic WebSecurityCustomizer webSecurityCustomizer(){return(web) -> web.ignoring()
.requestMatchers(new AntPathRequestMatcher("/api/v2/**"));// Every /api/v2/* route is completely unprotected// Including /api/v2/admin/*, /api/v2/export/*, etc.}
For every auth exclusion found, the analysis immediately asks: what routes exist under this excluded path? Those routes are added to the list of confirmed unprotected endpoints.
Complete dataflow trace, from HTTP entry to every sink: The dataflow analysis traces user-controlled input from the entry point through every function call to its destination. The "sinks" that matter are:
# Dangerous sinks — where user input reaching these causes vulnerabilitiesINJECTION_SINKS = {# SQL injection'cursor.execute': 'SQL — check for string formatting','db.query': 'SQL — check for concatenation','Model.objects.raw': 'Django ORM raw SQL','session.execute': 'SQLAlchemy raw execute',# Command injection'subprocess.run': 'OS command — check for shell=True with user input','subprocess.Popen': 'OS command — check args construction','os.system': 'Shell command — almost always vulnerable','eval': 'Code execution sink',# Path traversal'open(': 'File operation — check path construction','os.path.join': 'Path construction — check for traversal',# SSRF'requests.get': 'HTTP request — check if URL is user-controlled','urllib.request.urlopen': 'HTTP request — check URL source',# Template injection'render_template_string': 'Jinja2 template — user input in template?','Template(': 'Template construction — user input as template?',}
# Dangerous sinks — where user input reaching these causes vulnerabilitiesINJECTION_SINKS = {# SQL injection'cursor.execute': 'SQL — check for string formatting','db.query': 'SQL — check for concatenation','Model.objects.raw': 'Django ORM raw SQL','session.execute': 'SQLAlchemy raw execute',# Command injection'subprocess.run': 'OS command — check for shell=True with user input','subprocess.Popen': 'OS command — check args construction','os.system': 'Shell command — almost always vulnerable','eval': 'Code execution sink',# Path traversal'open(': 'File operation — check path construction','os.path.join': 'Path construction — check for traversal',# SSRF'requests.get': 'HTTP request — check if URL is user-controlled','urllib.request.urlopen': 'HTTP request — check URL source',# Template injection'render_template_string': 'Jinja2 template — user input in template?','Template(': 'Template construction — user input as template?',}
# Dangerous sinks — where user input reaching these causes vulnerabilitiesINJECTION_SINKS = {# SQL injection'cursor.execute': 'SQL — check for string formatting','db.query': 'SQL — check for concatenation','Model.objects.raw': 'Django ORM raw SQL','session.execute': 'SQLAlchemy raw execute',# Command injection'subprocess.run': 'OS command — check for shell=True with user input','subprocess.Popen': 'OS command — check args construction','os.system': 'Shell command — almost always vulnerable','eval': 'Code execution sink',# Path traversal'open(': 'File operation — check path construction','os.path.join': 'Path construction — check for traversal',# SSRF'requests.get': 'HTTP request — check if URL is user-controlled','urllib.request.urlopen': 'HTTP request — check URL source',# Template injection'render_template_string': 'Jinja2 template — user input in template?','Template(': 'Template construction — user input as template?',}
A real dataflow trace finding from the methodology:
# views.py — complete dataflow traceclass ReportView(APIView):
permission_classes = [IsAuthenticated]defpost(self,request):
# Input enters here:report_format = request.data.get('format','pdf')# User input Adate_range = request.data.get('date_range','30d')# User input Btemplate_name = request.data.get('template')# User input C ← dangerous# Input A → safe (allowlisted below)ifreport_formatnotin['pdf','csv','xlsx']:
returnResponse({'error': 'Invalid format'},status=400)# Input B → safe (regex validated)ifnotre.match(r'^\\d+[dwmy]$',date_range):
returnResponse({'error': 'Invalid date range'},status=400)# Input C → VULNERABLE# template_name is passed directly to render_template_string# User can inject: {{ config }}, {{ request.environ }},# {{ ''.__class__.__mro__[1].__subclasses__() }} → RCEreport_content = render_template_string(open(f'templates/{template_name}.html').read(),# ← Path traversal +data=get_report_data(date_range)# Template injection)# Dataflow:# request.data['template'] → template_name →# open(f'templates/{template_name}.html') → path traversal (../../../etc/passwd)# render_template_string(content) → SSTI (Server-Side Template Injection)# Combined: read any file + execute arbitrary Python → RCE# CVSS: 9.8
# views.py — complete dataflow traceclass ReportView(APIView):
permission_classes = [IsAuthenticated]defpost(self,request):
# Input enters here:report_format = request.data.get('format','pdf')# User input Adate_range = request.data.get('date_range','30d')# User input Btemplate_name = request.data.get('template')# User input C ← dangerous# Input A → safe (allowlisted below)ifreport_formatnotin['pdf','csv','xlsx']:
returnResponse({'error': 'Invalid format'},status=400)# Input B → safe (regex validated)ifnotre.match(r'^\\d+[dwmy]$',date_range):
returnResponse({'error': 'Invalid date range'},status=400)# Input C → VULNERABLE# template_name is passed directly to render_template_string# User can inject: {{ config }}, {{ request.environ }},# {{ ''.__class__.__mro__[1].__subclasses__() }} → RCEreport_content = render_template_string(open(f'templates/{template_name}.html').read(),# ← Path traversal +data=get_report_data(date_range)# Template injection)# Dataflow:# request.data['template'] → template_name →# open(f'templates/{template_name}.html') → path traversal (../../../etc/passwd)# render_template_string(content) → SSTI (Server-Side Template Injection)# Combined: read any file + execute arbitrary Python → RCE# CVSS: 9.8
# views.py — complete dataflow traceclass ReportView(APIView):
permission_classes = [IsAuthenticated]defpost(self,request):
# Input enters here:report_format = request.data.get('format','pdf')# User input Adate_range = request.data.get('date_range','30d')# User input Btemplate_name = request.data.get('template')# User input C ← dangerous# Input A → safe (allowlisted below)ifreport_formatnotin['pdf','csv','xlsx']:
returnResponse({'error': 'Invalid format'},status=400)# Input B → safe (regex validated)ifnotre.match(r'^\\d+[dwmy]$',date_range):
returnResponse({'error': 'Invalid date range'},status=400)# Input C → VULNERABLE# template_name is passed directly to render_template_string# User can inject: {{ config }}, {{ request.environ }},# {{ ''.__class__.__mro__[1].__subclasses__() }} → RCEreport_content = render_template_string(open(f'templates/{template_name}.html').read(),# ← Path traversal +data=get_report_data(date_range)# Template injection)# Dataflow:# request.data['template'] → template_name →# open(f'templates/{template_name}.html') → path traversal (../../../etc/passwd)# render_template_string(content) → SSTI (Server-Side Template Injection)# Combined: read any file + execute arbitrary Python → RCE# CVSS: 9.8
Git history scan: Every branch, every tag, every commit is scanned. Not just for secrets, for any change that might indicate a security-relevant historical state:
# Scanning methodology for git history# 1. Search all commits for secret patternsgit log --all-p--follow--"*.env" | grep-E"(password|secret|key|token).*=.*[a-zA-Z0-9]{8,}"# 2. Find commits that deleted sensitive filesgit log --all--diff-filter=D --name-only--format="%H %s" | grep-E"(\\.env|credentials|secrets|config\\.yml)"# 3. Reconstruct deleted files from historygit show <commit_hash>:path/to/deleted/.env
# 4. Scan for credentials in all historical .env contentgit log --all-p--"**/.env""**/.env.*" | grep-E"(DB_PASSWORD|SECRET_KEY|API_KEY|STRIPE|AWS)"# 5. Check CI/CD pipeline files for ever-hardcoded credentialsgit log --all-p--"**/*.yml""**/*.yaml" | grep-E"(password:|secret:|token:)\\s*['\\"]?[a-zA-Z0-9+/]{8,}"
# Scanning methodology for git history# 1. Search all commits for secret patternsgit log --all-p--follow--"*.env" | grep-E"(password|secret|key|token).*=.*[a-zA-Z0-9]{8,}"# 2. Find commits that deleted sensitive filesgit log --all--diff-filter=D --name-only--format="%H %s" | grep-E"(\\.env|credentials|secrets|config\\.yml)"# 3. Reconstruct deleted files from historygit show <commit_hash>:path/to/deleted/.env
# 4. Scan for credentials in all historical .env contentgit log --all-p--"**/.env""**/.env.*" | grep-E"(DB_PASSWORD|SECRET_KEY|API_KEY|STRIPE|AWS)"# 5. Check CI/CD pipeline files for ever-hardcoded credentialsgit log --all-p--"**/*.yml""**/*.yaml" | grep-E"(password:|secret:|token:)\\s*['\\"]?[a-zA-Z0-9+/]{8,}"
# Scanning methodology for git history# 1. Search all commits for secret patternsgit log --all-p--follow--"*.env" | grep-E"(password|secret|key|token).*=.*[a-zA-Z0-9]{8,}"# 2. Find commits that deleted sensitive filesgit log --all--diff-filter=D --name-only--format="%H %s" | grep-E"(\\.env|credentials|secrets|config\\.yml)"# 3. Reconstruct deleted files from historygit show <commit_hash>:path/to/deleted/.env
# 4. Scan for credentials in all historical .env contentgit log --all-p--"**/.env""**/.env.*" | grep-E"(DB_PASSWORD|SECRET_KEY|API_KEY|STRIPE|AWS)"# 5. Check CI/CD pipeline files for ever-hardcoded credentialsgit log --all-p--"**/*.yml""**/*.yaml" | grep-E"(password:|secret:|token:)\\s*['\\"]?[a-zA-Z0-9+/]{8,}"
Every discovered historical secret is verified for current validity. A database password rotated after the deletion is documented as low severity, the secret exists in history but is no longer valid. A database password never rotated after deletion is documented as critical, the secret is active and accessible to anyone who has cloned the repository.
Phase 5: API Authentication Testing
Every Endpoint, Every Bypass Pattern
This phase systematically tests authentication enforcement across every endpoint discovered in Phases 1 and 3. The goal: find every endpoint that responds to requests it shouldn't, whether because authentication is missing, incorrectly enforced, or bypassable through a known technique.
Endpoint inventory and unauthenticated baseline: Every discovered endpoint is hit without credentials. The response is classified and determines the subsequent testing approach:
importrequestsdeftest_endpoint_auth(base_url,endpoint,methods=['GET','POST','PUT','DELETE']):
results = []formethodinmethods:
response = requests.request(method,f"{base_url}{endpoint}",headers={'Content-Type': 'application/json'},json={},timeout=10,allow_redirects=False)classification = classify_response(response)results.append({'endpoint': endpoint,'method': method,'status': response.status_code,'classification': classification,'content_length': len(response.content),'finding': classification == 'UNPROTECTED'})returnresultsdefclassify_response(response):
ifresponse.status_code == 200andlen(response.content) > 0:
return'UNPROTECTED'# Data returned without credentialselifresponse.status_code == 401:
return'AUTH_ENFORCED'# Correctly requiring authenticationelifresponse.status_code == 403:
return'AUTH_ENFORCED_CHECK_BYPASS'# Authenticated but forbidden — test bypasselifresponse.status_code == 302:
return'REDIRECT_CHECK_BYPASS'# Redirect to login — test direct accesselifresponse.status_code == 500:
return'SERVER_ERROR_INVESTIGATE'# Processed before auth checkelse:
return'REVIEW_MANUALLY'
importrequestsdeftest_endpoint_auth(base_url,endpoint,methods=['GET','POST','PUT','DELETE']):
results = []formethodinmethods:
response = requests.request(method,f"{base_url}{endpoint}",headers={'Content-Type': 'application/json'},json={},timeout=10,allow_redirects=False)classification = classify_response(response)results.append({'endpoint': endpoint,'method': method,'status': response.status_code,'classification': classification,'content_length': len(response.content),'finding': classification == 'UNPROTECTED'})returnresultsdefclassify_response(response):
ifresponse.status_code == 200andlen(response.content) > 0:
return'UNPROTECTED'# Data returned without credentialselifresponse.status_code == 401:
return'AUTH_ENFORCED'# Correctly requiring authenticationelifresponse.status_code == 403:
return'AUTH_ENFORCED_CHECK_BYPASS'# Authenticated but forbidden — test bypasselifresponse.status_code == 302:
return'REDIRECT_CHECK_BYPASS'# Redirect to login — test direct accesselifresponse.status_code == 500:
return'SERVER_ERROR_INVESTIGATE'# Processed before auth checkelse:
return'REVIEW_MANUALLY'
importrequestsdeftest_endpoint_auth(base_url,endpoint,methods=['GET','POST','PUT','DELETE']):
results = []formethodinmethods:
response = requests.request(method,f"{base_url}{endpoint}",headers={'Content-Type': 'application/json'},json={},timeout=10,allow_redirects=False)classification = classify_response(response)results.append({'endpoint': endpoint,'method': method,'status': response.status_code,'classification': classification,'content_length': len(response.content),'finding': classification == 'UNPROTECTED'})returnresultsdefclassify_response(response):
ifresponse.status_code == 200andlen(response.content) > 0:
return'UNPROTECTED'# Data returned without credentialselifresponse.status_code == 401:
return'AUTH_ENFORCED'# Correctly requiring authenticationelifresponse.status_code == 403:
return'AUTH_ENFORCED_CHECK_BYPASS'# Authenticated but forbidden — test bypasselifresponse.status_code == 302:
return'REDIRECT_CHECK_BYPASS'# Redirect to login — test direct accesselifresponse.status_code == 500:
return'SERVER_ERROR_INVESTIGATE'# Processed before auth checkelse:
return'REVIEW_MANUALLY'
Systematic bypass pattern testing: For every endpoint that returns anything other than a clean 401, a battery of bypass patterns is tested:
bypass_patterns = [# JWT algorithm confusion{'name': 'JWT none algorithm','header': generate_jwt_none_algorithm(payload={'role': 'admin'}),'description': 'JWT signed with none algorithm — no signature needed'},# Empty/malformed tokens{'name': 'Empty Bearer token','header': 'Bearer ','description': 'Empty token string after Bearer'},{'name': 'Bearer without token','header': 'Bearer','description': 'Just the word Bearer, no token'},{'name': 'Null token','header': 'Bearer null','description': 'Literal string null as token'},# Expired tokens{'name': 'Expired valid token','header': f'Bearer {get_expired_token()}','description': 'Legitimately signed but expired JWT'},# Header manipulation{'name': 'X-Original-URL bypass','custom_headers': {'X-Original-URL': '/api/admin/users'},'description': 'Some reverse proxies route based on this header'},{'name': 'X-Forwarded-Host bypass','custom_headers': {'X-Forwarded-Host': 'internal.company.com'},'description': 'Host-based routing bypass'},# Alternative paths{'name': 'Path traversal variant','path_variants': ['/api/admin/users/../users',# Path normalization bypass'/API/admin/users',# Case variation'/api/admin/users%20',# Encoded whitespace'/api/admin/users/',# Trailing slash'/api/admin/./users',# Dot segment]}]
bypass_patterns = [# JWT algorithm confusion{'name': 'JWT none algorithm','header': generate_jwt_none_algorithm(payload={'role': 'admin'}),'description': 'JWT signed with none algorithm — no signature needed'},# Empty/malformed tokens{'name': 'Empty Bearer token','header': 'Bearer ','description': 'Empty token string after Bearer'},{'name': 'Bearer without token','header': 'Bearer','description': 'Just the word Bearer, no token'},{'name': 'Null token','header': 'Bearer null','description': 'Literal string null as token'},# Expired tokens{'name': 'Expired valid token','header': f'Bearer {get_expired_token()}','description': 'Legitimately signed but expired JWT'},# Header manipulation{'name': 'X-Original-URL bypass','custom_headers': {'X-Original-URL': '/api/admin/users'},'description': 'Some reverse proxies route based on this header'},{'name': 'X-Forwarded-Host bypass','custom_headers': {'X-Forwarded-Host': 'internal.company.com'},'description': 'Host-based routing bypass'},# Alternative paths{'name': 'Path traversal variant','path_variants': ['/api/admin/users/../users',# Path normalization bypass'/API/admin/users',# Case variation'/api/admin/users%20',# Encoded whitespace'/api/admin/users/',# Trailing slash'/api/admin/./users',# Dot segment]}]
bypass_patterns = [# JWT algorithm confusion{'name': 'JWT none algorithm','header': generate_jwt_none_algorithm(payload={'role': 'admin'}),'description': 'JWT signed with none algorithm — no signature needed'},# Empty/malformed tokens{'name': 'Empty Bearer token','header': 'Bearer ','description': 'Empty token string after Bearer'},{'name': 'Bearer without token','header': 'Bearer','description': 'Just the word Bearer, no token'},{'name': 'Null token','header': 'Bearer null','description': 'Literal string null as token'},# Expired tokens{'name': 'Expired valid token','header': f'Bearer {get_expired_token()}','description': 'Legitimately signed but expired JWT'},# Header manipulation{'name': 'X-Original-URL bypass','custom_headers': {'X-Original-URL': '/api/admin/users'},'description': 'Some reverse proxies route based on this header'},{'name': 'X-Forwarded-Host bypass','custom_headers': {'X-Forwarded-Host': 'internal.company.com'},'description': 'Host-based routing bypass'},# Alternative paths{'name': 'Path traversal variant','path_variants': ['/api/admin/users/../users',# Path normalization bypass'/API/admin/users',# Case variation'/api/admin/users%20',# Encoded whitespace'/api/admin/users/',# Trailing slash'/api/admin/./users',# Dot segment]}]
API documentation and introspection testing: Exposed API documentation is a finding in itself, and also a map of endpoints to test:
A publicly accessible /actuator/env is a critical finding. It returns all environment variables, including DATABASE_URL, STRIPE_SECRET_KEY, JWT_SECRET, and every other secret injected via environment variable. A publicly accessible /actuator/heapdump is worse, it's a binary dump of the JVM's heap memory, which can be parsed to extract active credentials and session tokens stored as string objects.
Phase 6: Authenticated Testing: Gray Box Track
The Insider Perspective
With test credentials established during scoping, the gray box track tests what legitimate users can access beyond their intended permissions. This track runs concurrently with the white box analysis after reconnaissance is complete.
Role boundary mapping: The first step is mapping what each role is supposed to be able to do, from the application's own UI and documentation. This establishes the intent that the testing will then systematically violate.
Privilege escalation testing: Every admin endpoint is tested with free-tier and pro-tier credentials. Every pro-tier endpoint is tested with free-tier credentials. This isn't a random probe, it's systematic verification of every role boundary.
deftest_role_boundaries(endpoints_by_required_role,test_credentials):
findings = []forrequired_role,endpointsinendpoints_by_required_role.items():
forendpointinendpoints:
# Test with credentials below the required rolefortest_role,credentialsintest_credentials.items():
ifrole_level(test_role) < role_level(required_role):
response = make_authenticated_request(endpoint,credentials)ifresponse.status_code == 200:
findings.append({'endpoint': endpoint,'required_role': required_role,'accessed_with': test_role,'severity': calculate_severity(endpoint,required_role),'type': 'Broken Access Control'})returnfindings
deftest_role_boundaries(endpoints_by_required_role,test_credentials):
findings = []forrequired_role,endpointsinendpoints_by_required_role.items():
forendpointinendpoints:
# Test with credentials below the required rolefortest_role,credentialsintest_credentials.items():
ifrole_level(test_role) < role_level(required_role):
response = make_authenticated_request(endpoint,credentials)ifresponse.status_code == 200:
findings.append({'endpoint': endpoint,'required_role': required_role,'accessed_with': test_role,'severity': calculate_severity(endpoint,required_role),'type': 'Broken Access Control'})returnfindings
deftest_role_boundaries(endpoints_by_required_role,test_credentials):
findings = []forrequired_role,endpointsinendpoints_by_required_role.items():
forendpointinendpoints:
# Test with credentials below the required rolefortest_role,credentialsintest_credentials.items():
ifrole_level(test_role) < role_level(required_role):
response = make_authenticated_request(endpoint,credentials)ifresponse.status_code == 200:
findings.append({'endpoint': endpoint,'required_role': required_role,'accessed_with': test_role,'severity': calculate_severity(endpoint,required_role),'type': 'Broken Access Control'})returnfindings
IDOR systematic enumeration: Every endpoint accepting an identifier gets systematic enumeration:
deftest_idor_systematic(base_url,endpoints_with_ids,user_a_token,user_b_ids):
"""
Test IDOR by attempting to access User B's resources
while authenticated as User A
"""findings = []forendpoint_template,id_typeinendpoints_with_ids.items():
forresource_idinuser_b_ids[id_type]:
endpoint = endpoint_template.format(id=resource_id)response = requests.get(f"{base_url}{endpoint}",headers={'Authorization': f'Bearer {user_a_token}'})ifresponse.status_code == 200:
data = response.json()# Confirm this is User B's data (not User A's)ifdata.get('user_id') != user_a_id:
findings.append({'endpoint': endpoint,'accessed_id': resource_id,'data_owner': data.get('user_id'),'requesting_user': user_a_id,'severity': 'HIGH','type': 'IDOR — Horizontal Access Control Failure','data_exposed': list(data.keys()),'record_count': 1})returnfindings# Identifier types tested:# - Sequential integers (user_id, order_id, invoice_id)# - UUIDs (document_id, session_id, tenant_id)# - Slugs (report slugs, project slugs)# - Compound identifiers (org_id + resource_id combinations)
deftest_idor_systematic(base_url,endpoints_with_ids,user_a_token,user_b_ids):
"""
Test IDOR by attempting to access User B's resources
while authenticated as User A
"""findings = []forendpoint_template,id_typeinendpoints_with_ids.items():
forresource_idinuser_b_ids[id_type]:
endpoint = endpoint_template.format(id=resource_id)response = requests.get(f"{base_url}{endpoint}",headers={'Authorization': f'Bearer {user_a_token}'})ifresponse.status_code == 200:
data = response.json()# Confirm this is User B's data (not User A's)ifdata.get('user_id') != user_a_id:
findings.append({'endpoint': endpoint,'accessed_id': resource_id,'data_owner': data.get('user_id'),'requesting_user': user_a_id,'severity': 'HIGH','type': 'IDOR — Horizontal Access Control Failure','data_exposed': list(data.keys()),'record_count': 1})returnfindings# Identifier types tested:# - Sequential integers (user_id, order_id, invoice_id)# - UUIDs (document_id, session_id, tenant_id)# - Slugs (report slugs, project slugs)# - Compound identifiers (org_id + resource_id combinations)
deftest_idor_systematic(base_url,endpoints_with_ids,user_a_token,user_b_ids):
"""
Test IDOR by attempting to access User B's resources
while authenticated as User A
"""findings = []forendpoint_template,id_typeinendpoints_with_ids.items():
forresource_idinuser_b_ids[id_type]:
endpoint = endpoint_template.format(id=resource_id)response = requests.get(f"{base_url}{endpoint}",headers={'Authorization': f'Bearer {user_a_token}'})ifresponse.status_code == 200:
data = response.json()# Confirm this is User B's data (not User A's)ifdata.get('user_id') != user_a_id:
findings.append({'endpoint': endpoint,'accessed_id': resource_id,'data_owner': data.get('user_id'),'requesting_user': user_a_id,'severity': 'HIGH','type': 'IDOR — Horizontal Access Control Failure','data_exposed': list(data.keys()),'record_count': 1})returnfindings# Identifier types tested:# - Sequential integers (user_id, order_id, invoice_id)# - UUIDs (document_id, session_id, tenant_id)# - Slugs (report slugs, project slugs)# - Compound identifiers (org_id + resource_id combinations)
Business logic validation: Every critical user flow is walked manually and then tested with adversarial sequences:
# Workflow bypass test — checkout flow# Legitimate sequence:# POST /checkout/cart → POST /checkout/address →# POST /checkout/payment → POST /checkout/confirm# Adversarial sequences tested:bypass_sequences = [# Skip payment entirely['POST /checkout/cart','POST /checkout/confirm'],# Call confirm twice (double-confirm attack)['POST /checkout/cart','POST /checkout/address','POST /checkout/payment','POST /checkout/confirm','POST /checkout/confirm'],# ← second confirm# Skip address step['POST /checkout/cart','POST /checkout/payment','POST /checkout/confirm'],# Concurrent confirm (race condition)# Two simultaneous POST /checkout/confirm requests# with the same cart_id# If not atomic, both might succeed → order confirmed twice]forsequenceinbypass_sequences:
result = execute_sequence(sequence,test_credentials)ifresult['final_status'] == 'order_confirmed':
log_finding('Workflow Bypass',sequence,result)
# Workflow bypass test — checkout flow# Legitimate sequence:# POST /checkout/cart → POST /checkout/address →# POST /checkout/payment → POST /checkout/confirm# Adversarial sequences tested:bypass_sequences = [# Skip payment entirely['POST /checkout/cart','POST /checkout/confirm'],# Call confirm twice (double-confirm attack)['POST /checkout/cart','POST /checkout/address','POST /checkout/payment','POST /checkout/confirm','POST /checkout/confirm'],# ← second confirm# Skip address step['POST /checkout/cart','POST /checkout/payment','POST /checkout/confirm'],# Concurrent confirm (race condition)# Two simultaneous POST /checkout/confirm requests# with the same cart_id# If not atomic, both might succeed → order confirmed twice]forsequenceinbypass_sequences:
result = execute_sequence(sequence,test_credentials)ifresult['final_status'] == 'order_confirmed':
log_finding('Workflow Bypass',sequence,result)
# Workflow bypass test — checkout flow# Legitimate sequence:# POST /checkout/cart → POST /checkout/address →# POST /checkout/payment → POST /checkout/confirm# Adversarial sequences tested:bypass_sequences = [# Skip payment entirely['POST /checkout/cart','POST /checkout/confirm'],# Call confirm twice (double-confirm attack)['POST /checkout/cart','POST /checkout/address','POST /checkout/payment','POST /checkout/confirm','POST /checkout/confirm'],# ← second confirm# Skip address step['POST /checkout/cart','POST /checkout/payment','POST /checkout/confirm'],# Concurrent confirm (race condition)# Two simultaneous POST /checkout/confirm requests# with the same cart_id# If not atomic, both might succeed → order confirmed twice]forsequenceinbypass_sequences:
result = execute_sequence(sequence,test_credentials)ifresult['final_status'] == 'order_confirmed':
log_finding('Workflow Bypass',sequence,result)
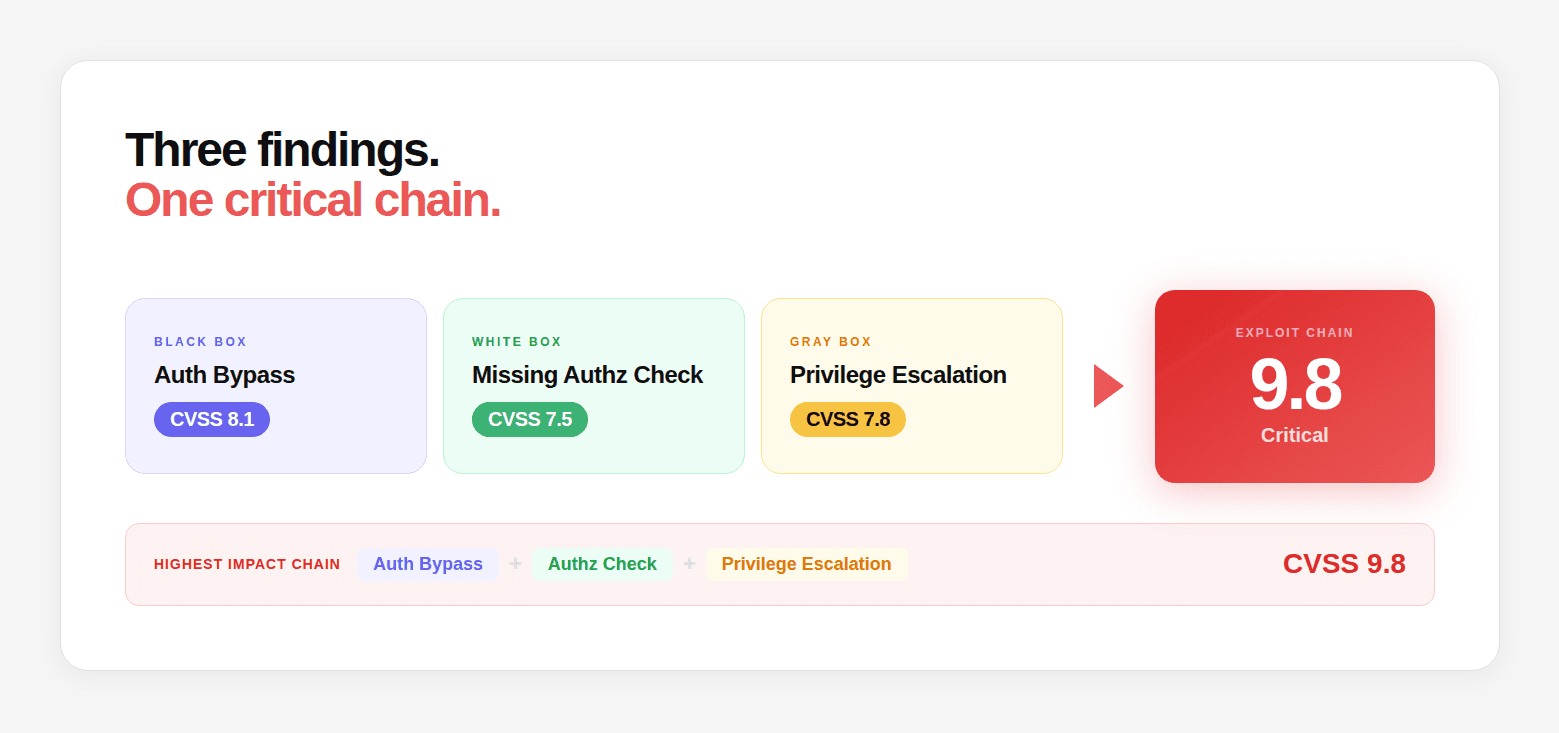
Phase 7: Exploit Chain Construction
Turning Individual Findings Into Maximum Impact Paths
This is the phase that most directly separates AI penetration testing from everything else. Every finding from every track: black box, white box, grey box, is loaded into a unified findings model. The AI then systematically evaluates every possible combination for chain potential.
The chain construction asks three questions about every finding pair:
Does Finding A enable or enhance Finding B? (A provides information or access that makes B more impactful)
Does the combination of A and B produce an impact greater than either alone? (Low + Low = Critical)
What is the minimum chain that achieves the highest-impact outcome?
# Chain evaluation logic — illustrativedefevaluate_chain_potential(findings):
chains = []forfinding_ainfindings:
forfinding_binfindings:
iffinding_a == finding_b:
continue# Check if A enables Bifenables(finding_a,finding_b):
chain_impact = calculate_chain_impact(finding_a,finding_b)ifchain_impact > max(finding_a.cvss,finding_b.cvss):
chains.append({'step_1': finding_a,'step_2': finding_b,'individual_max_cvss': max(finding_a.cvss,finding_b.cvss),'chain_cvss': chain_impact,'uplift': chain_impact - max(finding_a.cvss,finding_b.cvss),'chain_description': describe_chain(finding_a,finding_b)})# Sort by uplift — highest impact chains firstreturnsorted(chains,key=lambdax: x['uplift'],reverse=True)defenables(finding_a,finding_b):
# Does A provide something B needs?# A leaks an identifier that B needs to exploitiffinding_a.leaks_identifierandfinding_b.requires_identifier:
iffinding_a.identifier_type == finding_b.required_identifier_type:
returnTrue# A provides authenticated access that enables Biffinding_a.provides_auth_bypassandfinding_b.requires_auth:
returnTrue# A reveals an endpoint that B testsiffinding_a.reveals_endpointandfinding_b.targets_endpoint:
iffinding_a.revealed_endpoint == finding_b.target_endpoint:
returnTruereturnFalse
# Chain evaluation logic — illustrativedefevaluate_chain_potential(findings):
chains = []forfinding_ainfindings:
forfinding_binfindings:
iffinding_a == finding_b:
continue# Check if A enables Bifenables(finding_a,finding_b):
chain_impact = calculate_chain_impact(finding_a,finding_b)ifchain_impact > max(finding_a.cvss,finding_b.cvss):
chains.append({'step_1': finding_a,'step_2': finding_b,'individual_max_cvss': max(finding_a.cvss,finding_b.cvss),'chain_cvss': chain_impact,'uplift': chain_impact - max(finding_a.cvss,finding_b.cvss),'chain_description': describe_chain(finding_a,finding_b)})# Sort by uplift — highest impact chains firstreturnsorted(chains,key=lambdax: x['uplift'],reverse=True)defenables(finding_a,finding_b):
# Does A provide something B needs?# A leaks an identifier that B needs to exploitiffinding_a.leaks_identifierandfinding_b.requires_identifier:
iffinding_a.identifier_type == finding_b.required_identifier_type:
returnTrue# A provides authenticated access that enables Biffinding_a.provides_auth_bypassandfinding_b.requires_auth:
returnTrue# A reveals an endpoint that B testsiffinding_a.reveals_endpointandfinding_b.targets_endpoint:
iffinding_a.revealed_endpoint == finding_b.target_endpoint:
returnTruereturnFalse
# Chain evaluation logic — illustrativedefevaluate_chain_potential(findings):
chains = []forfinding_ainfindings:
forfinding_binfindings:
iffinding_a == finding_b:
continue# Check if A enables Bifenables(finding_a,finding_b):
chain_impact = calculate_chain_impact(finding_a,finding_b)ifchain_impact > max(finding_a.cvss,finding_b.cvss):
chains.append({'step_1': finding_a,'step_2': finding_b,'individual_max_cvss': max(finding_a.cvss,finding_b.cvss),'chain_cvss': chain_impact,'uplift': chain_impact - max(finding_a.cvss,finding_b.cvss),'chain_description': describe_chain(finding_a,finding_b)})# Sort by uplift — highest impact chains firstreturnsorted(chains,key=lambdax: x['uplift'],reverse=True)defenables(finding_a,finding_b):
# Does A provide something B needs?# A leaks an identifier that B needs to exploitiffinding_a.leaks_identifierandfinding_b.requires_identifier:
iffinding_a.identifier_type == finding_b.required_identifier_type:
returnTrue# A provides authenticated access that enables Biffinding_a.provides_auth_bypassandfinding_b.requires_auth:
returnTrue# A reveals an endpoint that B testsiffinding_a.reveals_endpointandfinding_b.targets_endpoint:
iffinding_a.revealed_endpoint == finding_b.target_endpoint:
returnTruereturnFalse
Every confirmed chain is then exploited with a working proof-of-concept, not just described, but executed. The impact is quantified: how many records were accessible, what data types were exposed, what is the realistic attacker path from zero to maximum data access.
Phase 8: Report Generation
The Deliverable That Engineering Teams and Auditors Both Need
The report is structured to serve two audiences simultaneously: the engineering team remediating the findings, and the auditor verifying that security controls are in place.
Report structure:
Finding severity with exploitability context: CVSS 4.0 score is always provided, but the score is accompanied by the context that changes the remediation priority:
Factor
How It Modifies Priority
Exploitable from internet without authentication
Tier 1 — fix within 24 hours
Working public exploit exists
Tier 1 — fix within 24 hours
CVSS 9+ with active data exposure in production
Tier 1 — immediate escalation during test
CVSS 9+ in non-production only
Tier 2 — fix this sprint
CVSS 7–8.9, no public exploit
Tier 2 — fix this sprint
CVSS 4–6.9, clear exploitation path
Tier 3 — fix this quarter
CVSS 4–6.9, limited exploitation path
Tier 4 — backlog
Phase 9: Walkthrough Call
Turning the Report Into an Action Plan
A report without a walkthrough is just a document. The 60-minute walkthrough call with the engineering team turns findings into a shared understanding of what happened, why it matters, and exactly what to do about it.
The walkthrough covers:
Priority alignment: Not every CVSS 8 is equally urgent. The walkthrough explains the exploitability and blast radius context that determines actual priority: which findings are actively being probed in the wild, which ones are theoretical, which ones are one exploit chain away from a critical breach.
Root cause discussion: For each finding, the engineering team understands not just where the vulnerability is, but why it exists, what pattern or assumption led to it, so that the same pattern can be audited for in other parts of the codebase.
Remediation specifics: The diff in the report is the minimum change. The walkthrough discusses whether additional changes in related code are warranted, and whether the finding indicates a systemic pattern that needs a broader fix.
Questions and edge cases: The engineering team frequently identifies nuances that change the remediation approach. The walkthrough is where those get resolved.
Phase 10: Retest and Verification
Closing the Loop
Every fix gets retested. Not assumed fixed, retested. The retest confirms two things:
The specific finding is remediated: The proof-of-concept no longer works
The fix didn't introduce new vulnerabilities: The changed code is reviewed for regressions
The output of the retest is a written verification report:
Retest Verification Report — [Engagement ID]
Retest Verification Report — [Engagement ID]
Retest Verification Report — [Engagement ID]
The verification report is the document that closes audit loops. SOC 2 and PCI-DSS auditors require evidence that identified vulnerabilities were remediated. The verification report is that evidence.
The Methodology is the Product: Here is How to Test Any Provider's
Penetration testing firms often describe their methodology in marketing language that sounds similar across the industry. The way to evaluate whether a firm's methodology is real is to ask for specifics:
"Walk me through what happens in the first 6 hours of engagement." The answer should cover reconnaissance in detail, DNS enumeration, CT log queries, port scanning, cloud asset discovery. If the answer is "we start with reconnaissance and move to vulnerability testing," that's not a methodology description.
"How do you approach JavaScript bundle analysis? Can you show me an example finding?" If they don't do JS bundle analysis, or if they don't know what you mean, a significant portion of the black box attack surface is being skipped.
"How does your chain analysis work? Can you describe a finding that only appeared as a chain?" If the answer is "we document individual findings and note when they're related," they're not doing systematic chain construction.
"What does your retest report look like?" Ask for a redacted sample. It should document finding-by-finding verification status, what was tested, and what the result was.
"Can you show me a finding with root cause to file and line?" The answer tells you whether white box depth is real or claimed.
The methodology described in this guide is exactly how a CodeAnt AI Full Assessment runs. The same phases. The same parallel tracks. The same chain construction. The same finding format, root cause to file and line, working proof-of-exploit, specific remediation diff, compliance mapping.
The penetration testing market sells engagements. Scoped time windows with a deliverable at the end. A report with findings, a CVSS score per finding, and generic remediation advice.
The right thing to buy is methodology; a defined, repeatable, technically rigorous process that covers the full attack surface, evaluates every finding for chain potential, requires working proof-of-exploit before reporting, traces vulnerabilities to their root cause in your specific code, and verifies that remediations actually work.
The difference between a scanner with a pentest label and a real AI penetration testing engagement is the methodology that runs between "scope confirmed" and "retest complete." Ten phases. Parallel tracks. Interconnected findings. Chain analysis. Researcher validation. Specific diffs.