
AI Pentesting
How AI Penetration Testing Works For Data Leaks

Sonali Sood

Founding GTM, CodeAnt AI
A quick definition before anything else, because one phrase covers two different things. This article is about AI that performs penetration tests against your applications and infrastructure. It is not about testing AI models for safety or prompt injection. Same three words, opposite directions. If you came here to secure an LLM, this is the other discipline.
Autonomous AI penetration testing has moved from conference slideware to production-grade engagement delivery.
This is a deep technical walkthrough of how an AI-driven offensive pipeline operates, from the always-on layer that watches your attack surface 365 days a year, through reconnaissance, exploitation, and multi-step chaining, to a signed customer deliverable that contains the actual extracted records.
It is written for teams who want to understand what AI penetration testing actually means in operational terms rather than as a marketing phrase.
Every claim below maps to a concrete component of the engagement pipeline, a measurable property of the methodology, or an explicit guarantee in the engagement contract.
TL;DR
Security has two clocks. Your attack surface changes every day. A pentest happens once a quarter, or once a year. The gap between those two clocks is where breaches live.
CodeAnt closes the gap with two layers. Attack surface management runs continuously, 365 days a year, mapping every domain, IP, open port, exposed service, and known CVE across more than thirty data sources. Autonomous AI penetration testing then runs a full engagement in roughly thirty to ninety minutes and proves what an attacker can actually take.
The pentest deliverable is not a list of theoretical findings. It is a numbered, human-readable engagement folder containing the real exfiltrated records that prove customer impact, paired with two finished PDF reports.
The system is built around a distinction that ordinary scanners blur: a detected vulnerability is not a confirmed data leak. Customers pay for the second, not the first.
Coverage spans the OWASP API Security Top 10, OWASP Web Top 10, OAuth abuse, JWT cryptographic confusion, GraphQL introspection and depth attacks, SSRF cloud-metadata harvesting, multi-tenant isolation breaches, and supply-chain disclosure paths.
Engagements are bounded by design: a hard cap on extracted bytes (one hundred megabytes total, twenty megabytes per finding), a hard cap on spend, and a per-phase timeout. The system extracts to prove impact, not to exfiltrate a warehouse.
Why a Pentest Alone Leaves You Blind
Manual penetration testing is bottlenecked by three things:
a senior tester's attention
the linear order in which they investigate findings
the difficulty of parallelizing surface coverage
Engagements run for one to four weeks, cost five figures, and surface a finite number of issues before the Statement of Work closes. The depth is high, the throughput is low, and the variance between testers is enormous.
Automated scanners solve throughput but not depth. They detect patterns. They cannot prove impact. A scanner can flag that an endpoint looks vulnerable to insecure direct object reference. It cannot reliably enumerate twenty real customer records to demonstrate the consequence. That gap is the difference between a finding a customer's executive team takes seriously and one their engineering team dismisses as noise.
But there is a second, quieter problem that neither manual testing nor scanning solves: timing. A pentest is a photograph. It captures your security posture on the day it ran. The moment it is delivered, your team ships another release, stands up another subdomain, rotates another certificate, and the photograph is already out of date. In a year of annual testing, you are protected for the week of the test and exposed for the other fifty-one. That is the structural reason CodeAnt runs two layers instead of one.

The Always-On Layer: Attack Surface Management, 365 Days a Year
Here's the section with bullets added where they earn their place, the data-source list, the findings breakdowns, the CVSS-vs-EPSS contrast. The explanatory prose still sits right before each image (that's what ranks), but the dense parts are now scannable. No em dashes, copy-paste ready.
The Always-On Layer: Attack Surface Management, 365 Days a Year
Before a single exploit runs, you have to know what you actually own and expose to the internet. Most organizations do not.

The assets that get you breached are usually the ones nobody remembers:
Subdomains spun up for a campaign and forgotten.
A staging box given a public IP for a demo and never torn down.
A vendor's status page on infrastructure nobody on the security team has ever logged into.
Each one is an attacker's front door, and none of them appear in an asset inventory built from a spreadsheet.
CodeAnt's attack surface management maps the entire external footprint of an organization and keeps mapping it, continuously. Not once a month when a scan is scheduled. Every day, 365 days a year. It correlates intelligence from more than thirty data sources, including:
Certificate transparency logs and passive DNS.
Active DNS resolution and brute-forcing.
Port and service scanning.
Cloud provider fingerprinting and technology stack detection.
The National Vulnerability Database and the CISA Known Exploited Vulnerabilities catalog.
Email-security records (SPF, DKIM, DMARC).
The output is a single, living picture of every domain, every IP, every open port, every exposed service, and every known CVE that touches your name.
This is the difference between testing on a calendar and watching in real time.
A pentest you run once a month tells you what was exploitable on the first of the month.
Attack surface management tells you the moment a new subdomain appears, the moment a database port is exposed, the moment a newly disclosed CVE lands on software you are running.
The dashboards below are from a single engagement.
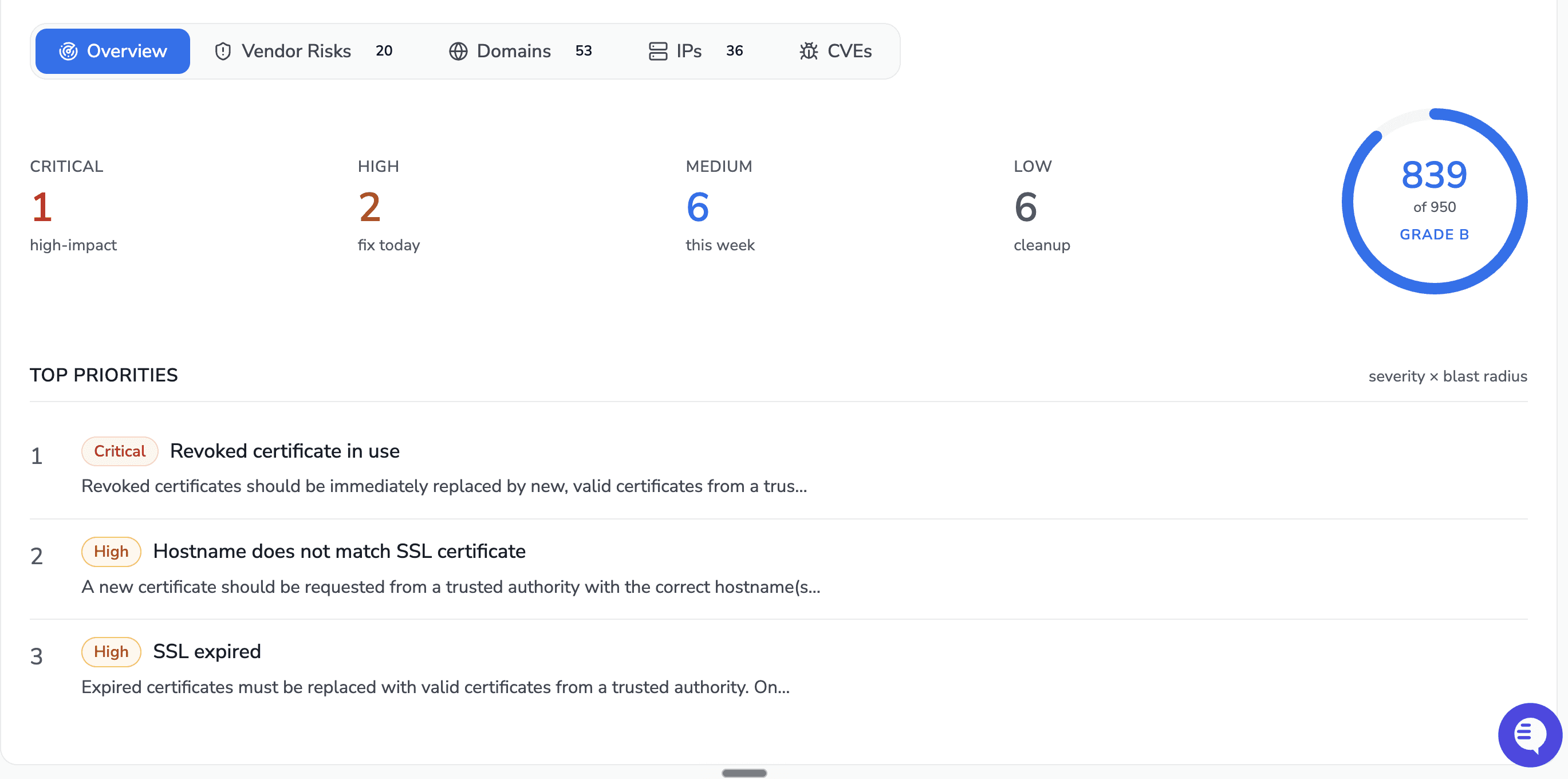
One domain expanded into 59 live subdomains, 90 IP addresses, 109 known CVEs, and 1,288 distinct risk findings, none of which required a person to launch a scan.
The overview dashboard rolls every external asset into one score out of 950 with a letter grade, so a security leader can see posture at a glance and track it over time. Findings are bucketed into critical, high, medium, and low, and top priorities are ranked by severity multiplied by blast radius, not by raw count. In this engagement the headline risks were a missing SSL certificate, an exposed MongoDB port, and an exposed memcached port, each a direct path to data. The weakest hosts and worst-scoring categories, here email security and encryption, tell you where to start.
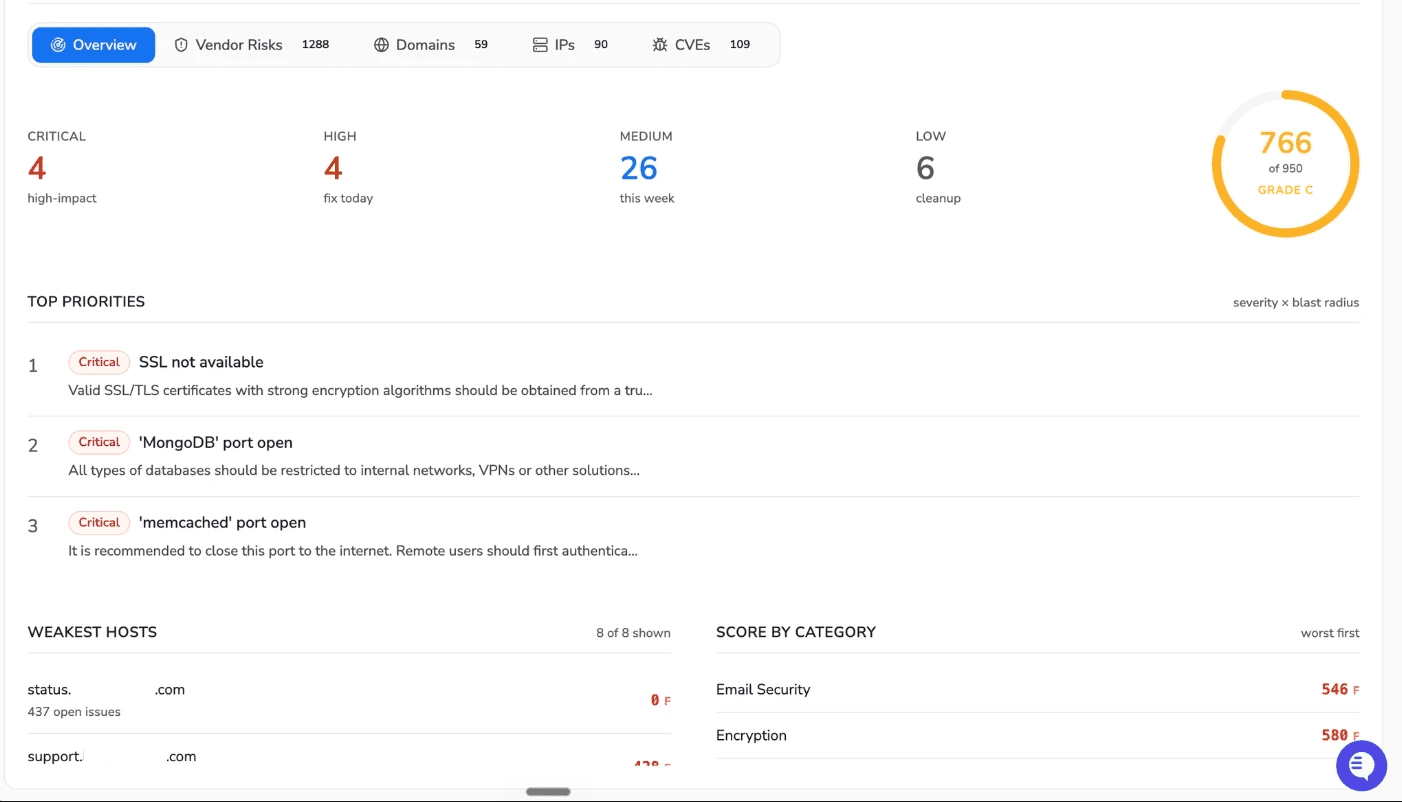
Drilling into the full risk inventory, every finding is typed, categorized, and counted by the number of affected hosts:
Critical: an internet-exposed MongoDB port, an exposed Redis port, an exposed memcached port, and a missing SSL certificate across six hosts.
High: a DMARC policy set to p=none, and HTTP that does not redirect to HTTPS.
This is the work that normally takes a team weeks of manual enumeration to assemble, refreshed automatically every day.

The breadth of discovery is the point. Fifty-nine subdomains surfaced from one root domain, each scored and graded independently, each with its own issue breakdown. The status page host alone carried hundreds of open issues. These are exactly the forgotten assets that never make it into a manual inventory and that attackers find first.
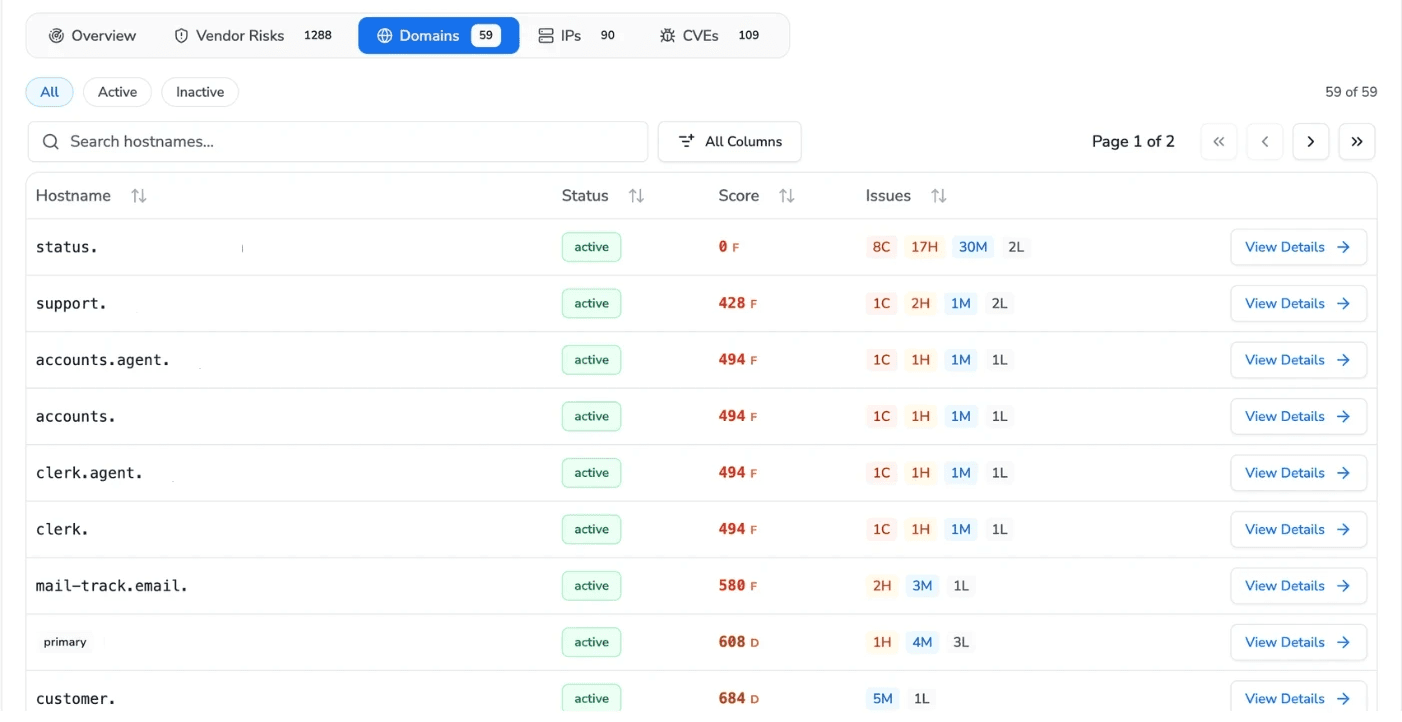
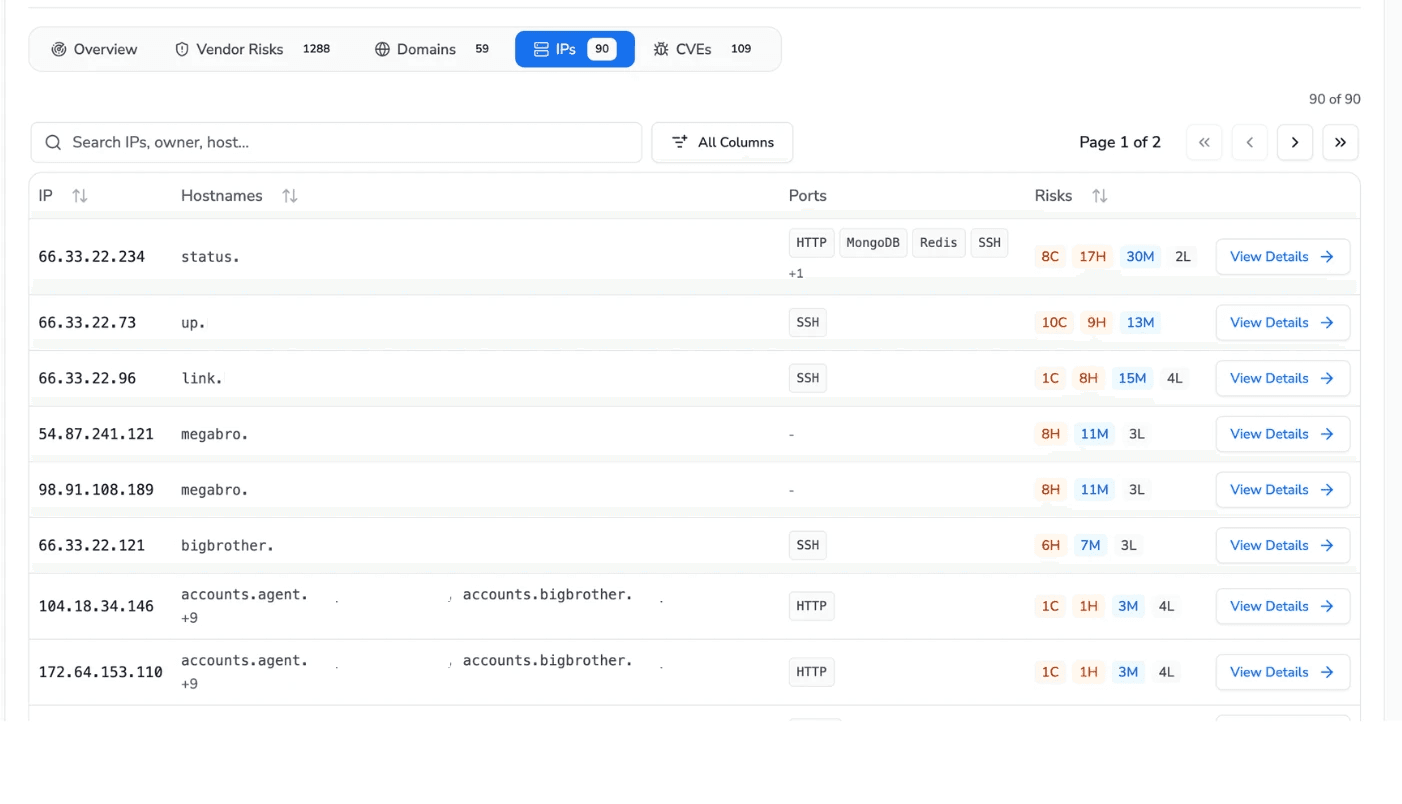
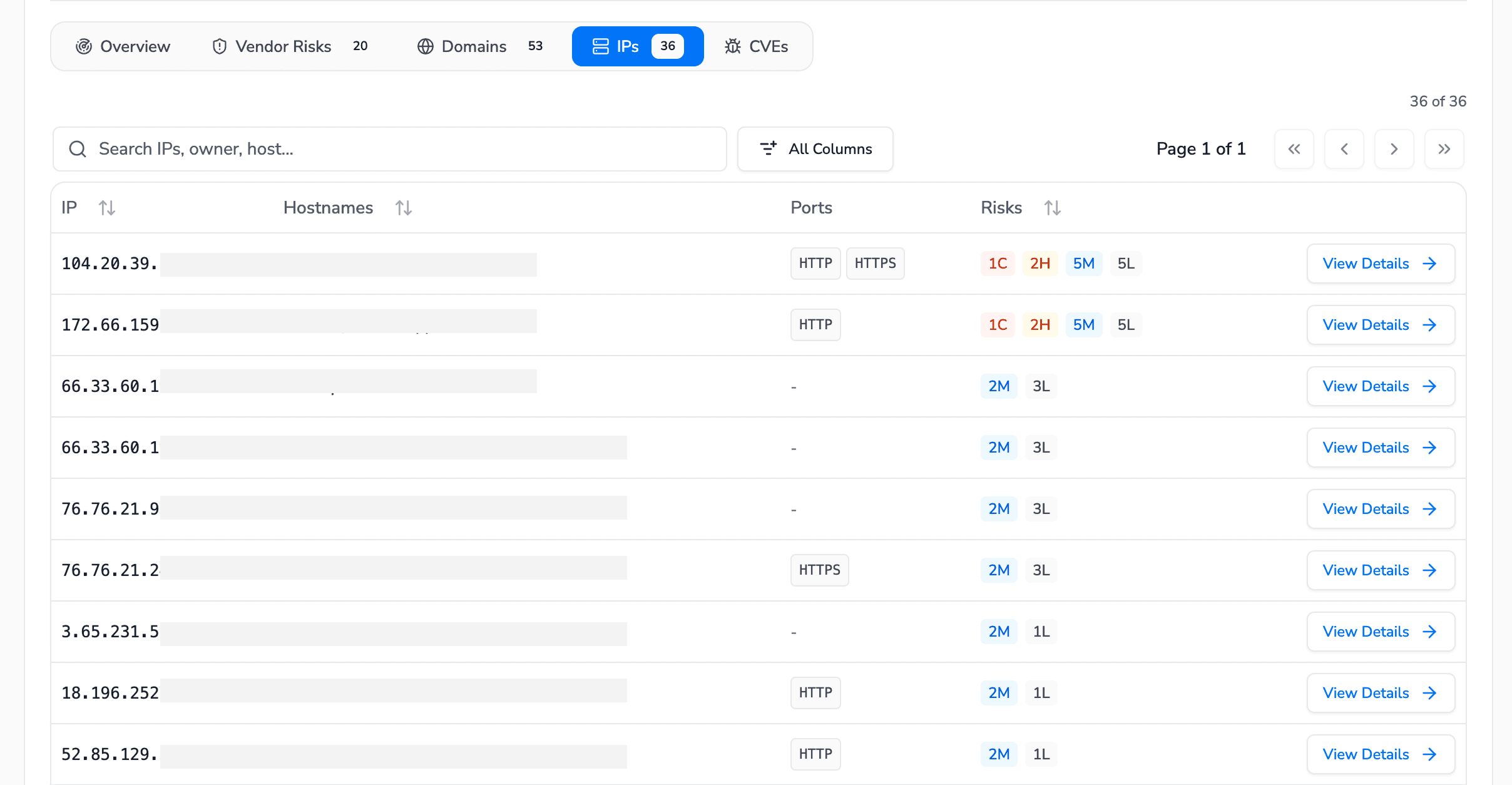
The same continuous mapping extends to the IP and port surface. Ninety IP addresses are tied back to their hostnames, with open ports and per-host risk counts. The exposed database ports visible here, MongoDB and Redis, are the kind of finding that turns into a confirmed data leak in the penetration testing phase. This is exactly how the two layers connect:
The breadth layer finds the exposed port.
The depth layer proves what an attacker can pull through it.
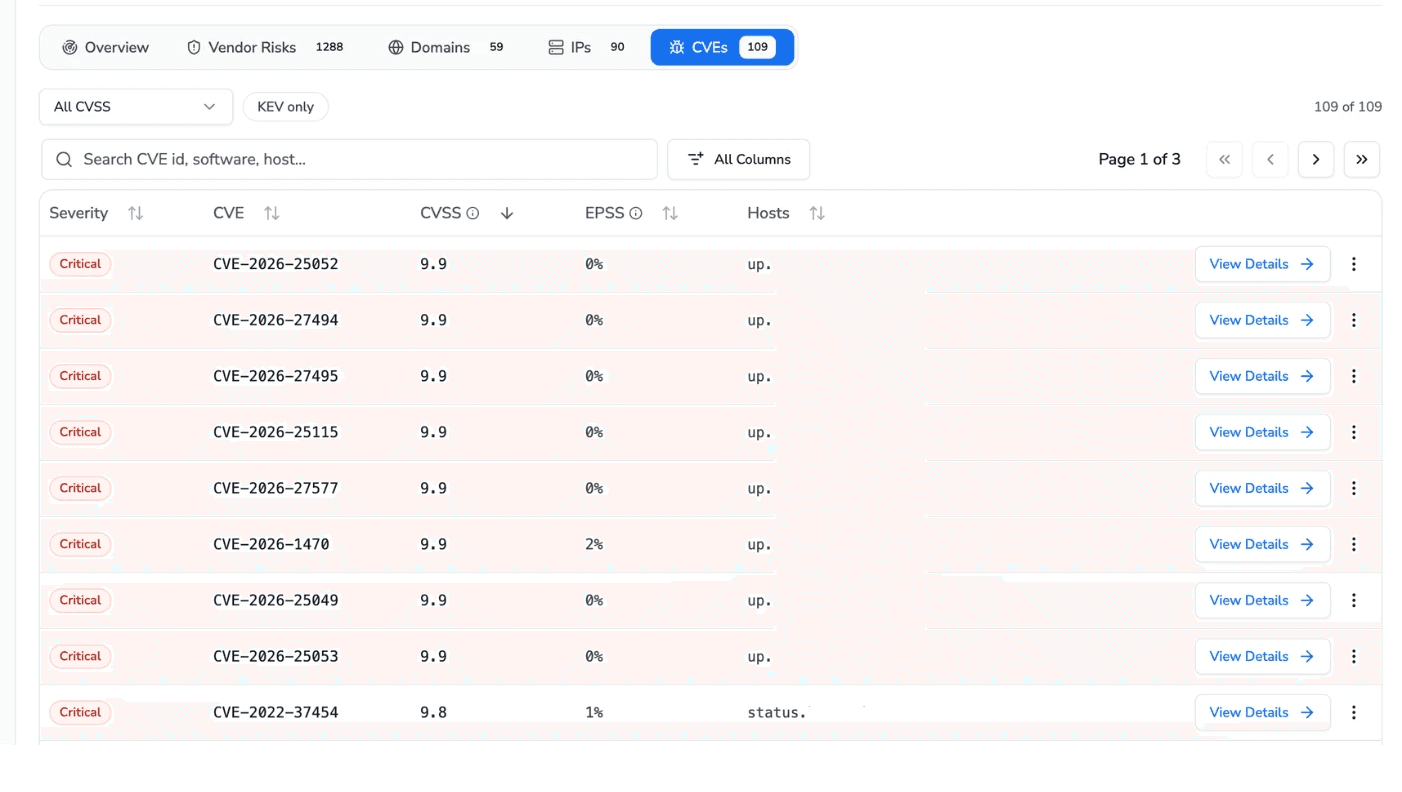
Finally, the CVE intelligence view puts vulnerabilities in context. One hundred and nine known CVEs are listed, each with a CVSS severity score, an EPSS exploit-prediction percentage, and a filter for vulnerabilities in the CISA Known Exploited Vulnerabilities catalog. The two scores answer different questions:
CVSS tells you how bad a vulnerability is in theory.
EPSS tells you how likely it is to be exploited in the wild.
Seeing both together is how a team prioritizes the handful of CVEs that actually matter out of a list of a hundred.
Attack surface management is the breadth layer and the continuous layer. It tells you where you are exposed, on every day of the year. What it does not do, on its own, is prove what an attacker could take. That is the job of the penetration testing engine, and it sits directly on top of this surface intelligence.
From Exposure to Proof: How the AI Pentest Works
Attack surface management hands the penetration testing engine a complete, current map of the target. The engine's job is to turn exposure into evidence. AI pentesting reconciles three properties that previously had to be traded off against each other:
Breadth: broad surface mapping across subdomains, JavaScript bundles, exposed configuration endpoints, source repositories, email-security records, certificate transparency logs, and storage-bucket fingerprints.
Depth: multi-step exploit chains that combine an initial vulnerability with credentials, internal hostnames, or session artifacts harvested elsewhere in the engagement.
Evidence-grade output: actual records, source files, and verified credentials saved to disk in a form a customer's legal team and engineering team can both consume.
The architecture that delivers all three is a phased pipeline of focused autonomous agents, each scoped to a single objective and handed a clean context window.
Architectural Foundations: One Objective Per Agent
The core design decision is simple: do not ask a single agent to do everything. Asking one long-running session to handle reconnaissance, source review, exploitation, extraction, and report writing causes earlier work to drown out later work. Token budgets fill up with subdomain dumps. The model starts reasoning over its own debris.
Instead, an orchestrator drives a sequence of phases, each phase staffed by a freshly spawned agent that sees only the artifacts it needs. The agents communicate through structured files on disk, not through a shared conversation. That has four practical consequences:
Resumability
If a phase crashes, rate limit, network blip, hardware reboot, the engagement resumes from the last completed phase without losing prior work. State is checkpointed after every successful phase.
Auditability
A human can open the engagement folder and read it top to bottom. Every input, intermediate artifact, and output is on disk. There is no opaque conversational state to reconstruct.
Composability
Phases can be re-run independently. If a report needs to be regenerated with a new severity threshold, only the affected phase runs.
Provability
Each phase produces structured JSON artifacts that downstream phases consume mechanically. The pipeline is testable in pieces, and individual phases can be validated against ground-truth corpora.
The phase order is fixed and numbered. Lower-numbered phases never modify the work of higher-numbered phases. That property, combined with checkpointed state, is what makes the whole thing operationally reliable across long-running engagements with hundreds of intermediate artifacts.
The Engagement Folder: Structured Evidence on Disk
Before the phases themselves, it is worth describing what a finished engagement looks like on disk, because the structure is the contract between the autonomous pipeline and the human reviewer.
A finished engagement is a single directory keyed by {company}-{repo-or-na}-{YYYYMMDD}. Inside it, files are strictly numbered so a human reads them top-to-bottom in order of execution:
Two invariants make this layout durable:
Every phase writes only to its own numbered folder. Nothing in a lower-numbered folder is ever modified once it is written. "Delete phase N and re-run" is always safe.
The
data-leaks/tree is the primary evidence source for every downstream artifact. If a finding is not represented there with confirmed extraction, the report classifies it accordingly. The bar for "critical" and "high" is impact-proven, not impact-suspected.
Phase One: Scope Intake and Source Ingestion
The engagement begins with structured intake. The operator provides:
A target domain (protocol, path, and
www.are stripped to leave a canonical registrable host).An optional source-code repository (organization/repo form).
Optional authenticated test credentials.
A free-text business description.
The business description field is more important than it looks. The downstream extraction phase reads it to decide what kind of data to prioritize.
For a fintech, that means transactions, balances, and Know-Your-Customer records.
For a health-tech, it means protected health information.
For an identity or compliance vendor, it means audit logs and verification trails.
Generic agents extract generic evidence; context-aware agents extract evidence that resonates with the customer's specific compliance posture, relevant to SOC 2, ISO 27001, PCI DSS, HIPAA, GDPR, or similar regimes.
When a repository is provided, the clone phase pulls the source, inventories languages, identifies the application's framework, and produces a summary file used as priors by both the recon phase (for likely route patterns) and the whitebox phase (for which static-analysis playbooks to run).
Phase Two: Data-leak-focused Reconnaissance
External reconnaissance is deliberately narrow. The objective is not to inventory every asset, it is to find the assets where customer data lives.
The recon phase produces six categories of structured intelligence:
Subdomain enumeration
Sources fed in parallel include certificate transparency logs, passive DNS aggregators, search-engine fingerprinting, and active brute-force against high-probability wordlists. Each candidate is filtered into an "all" list and an "interesting" list. Interesting candidates match patterns that historically correlate with customer-data exposure: api., app., admin., staging., dev., internal., cms., dashboard., portal., auth., sso., id., console..
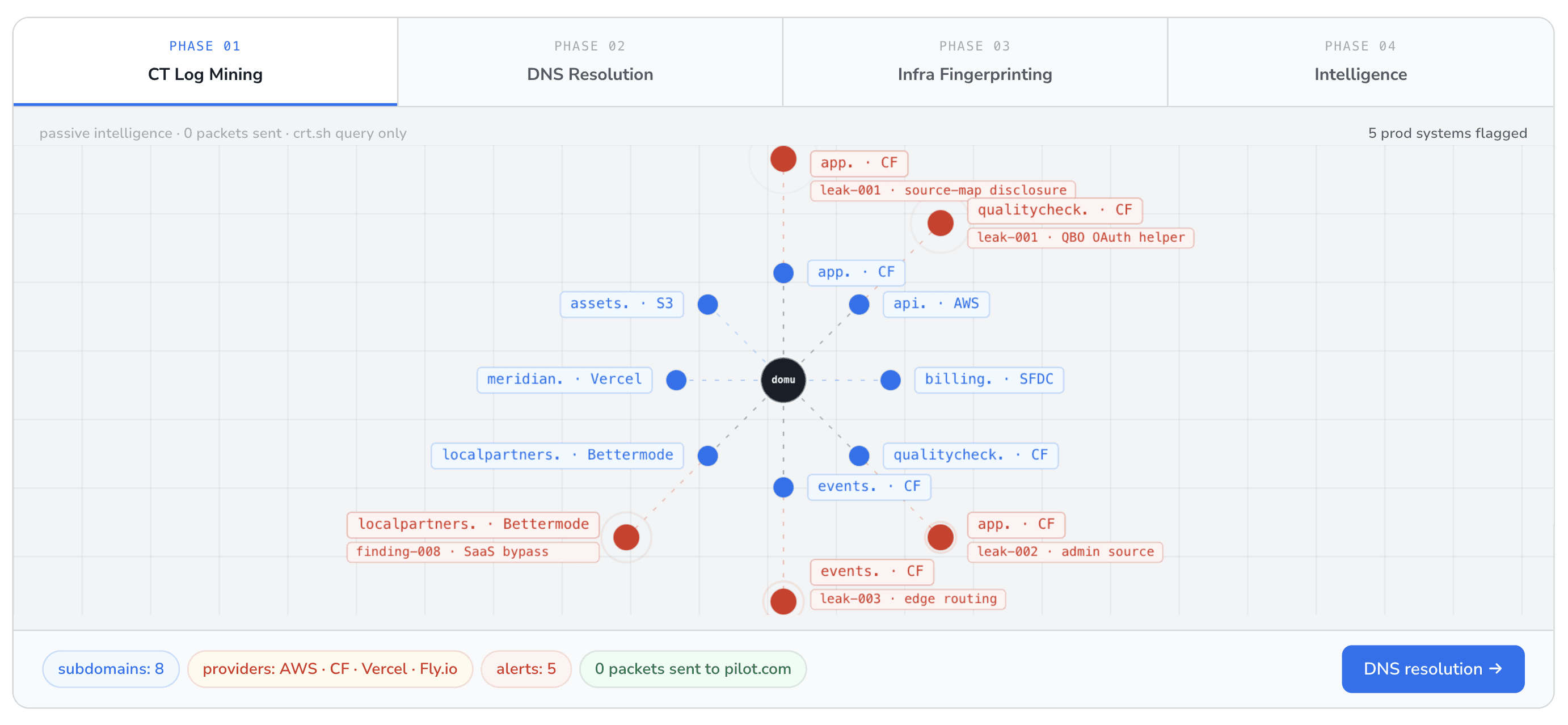
Live host probing
Each interesting subdomain receives HTTP and HTTPS probes. The probe captures status code, server header, technology fingerprint, content length, redirect chain, and TLS certificate metadata. Findings of common framework-level exposures, debug routes, framework administration consoles, and dashboards on default ports, are tagged for later exploitation phases.
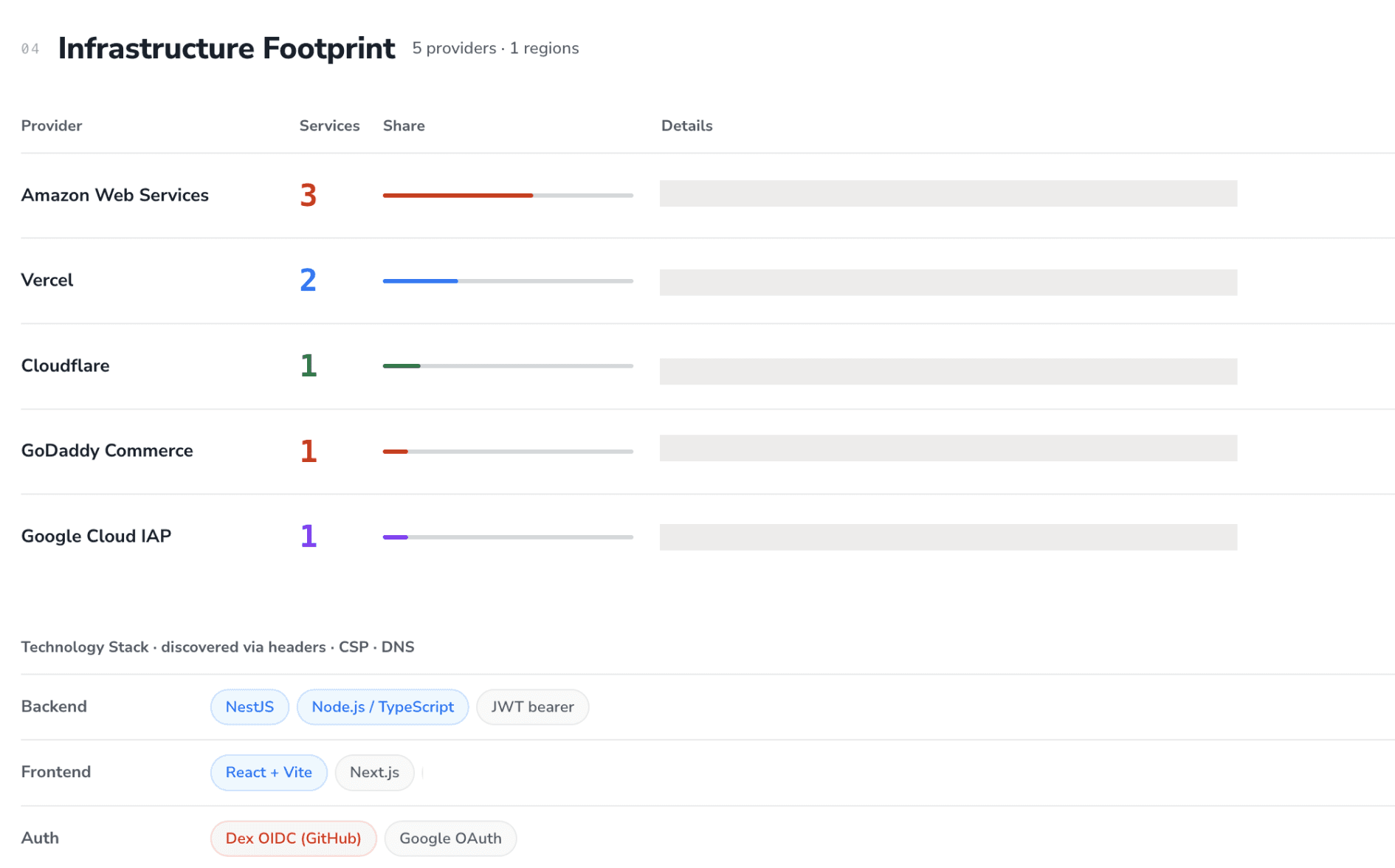
JavaScript bundle mining
Production JavaScript bundles are pulled and statically analyzed for:
API keys and tokens (cloud provider keys, payment processor keys, analytics keys, monitoring keys).
Internal hostnames embedded in production code (the classic source of staging-environment disclosure).
OAuth client identifiers and authentication endpoints.
Feature-flag identifiers that disclose unreleased capability.
Source-map artifacts that leak original source paths.
Mined secrets are classified into three categories before exploitation: public-by-design (single-page-app client identifiers, recaptcha site keys), suspect (keys that pattern-match a sensitive provider but have not been verified live), and confirmed-live (keys that responded successfully to a live identity probe).
Exposed-path probing
A focused wordlist of high-signal misconfiguration paths is fired against every interesting host. The probe set includes:
Environment-variable disclosure routes used by common application frameworks.
Source-control metadata directories that publish repository history when misdeployed.
Backup files and editor artifacts.
Build-tool configuration files in production webroots.
API documentation routes, OpenAPI specifications, GraphQL playgrounds, framework-generated documentation, that should not be reachable unauthenticated in production.
Container-orchestration metadata endpoints and reverse-proxy administration interfaces accidentally bound to public addresses.
Storage-exposure fingerprinting
Cloud storage buckets are enumerated by guessing common prefix and suffix patterns derived from the company name, domain, and any artifacts already seen in the recon phase. Each candidate is checked for public-listing exposure and for public-object exposure.
Source-level route extraction
When a repository is available, application routes are extracted from source. For server frameworks, the extraction reads route declarations; for client frameworks, it reads the routing layer of the front-end framework. Routes are merged with the live-host inventory so the exploitation phase has a complete route surface, not a guess.
The combined recon output feeds the queue construction phase with a normalized list of candidate findings, each annotated with a typed vulnerability class, a target endpoint, an evidence pointer, and a proximity tag describing how close the finding is to actual customer data.
Phase Three: Whitebox Source Review
When source is available, a parallel whitebox phase reviews it against three specific targets:

Secrets review
Hardcoded credentials, tokens, signing keys, connection strings, cloud access keys, OAuth client secrets, and webhook secrets. Each candidate is classified live where possible, for cloud keys, by calling a read-only identity verification API; for code-hosting tokens, by calling a read-only user-info endpoint. Verified-live secrets become high-priority queue entries with reproduction commands already attached.
Injection and authorization flows
Static analysis follows tainted input from request handlers into database query construction, command execution, dynamic evaluation, and authentication decision logic. The output is a list of typed injection candidates: classical SQL injection, blind SQL injection, NoSQL injection, OS command injection, server-side template injection, expression-language injection, broken object-level authorization, broken function-level authorization, and missing-middleware patterns where sensitive routes are mounted without authentication checks.
Resource flows
Server-side request forgery candidates are identified by following user-controlled URL parameters into HTTP-client calls. Path traversal candidates follow user-controlled path components into file-system reads. File-upload candidates trace user-controlled file content into storage writes with insufficient content-type validation. Each candidate is annotated with the protocol or scheme set it would need to abuse, http, https, gopher, dict, file, ftp, ldap and with the cloud metadata endpoint families it would reach if the SSRF is exploitable.
Whitebox findings join the same scored queue as external findings. The system treats a confirmed source-level injection and an externally confirmed injection as the same kind of evidence, with different reproduction paths.
Phase Four: Scoring and Queue Construction
Between detection and exploitation sits a deterministic scoring step. Scoring is intentionally not an AI step, it is pure code. Fast, free, deterministic, auditable.
Every candidate finding receives a score from roughly zero to thirteen, derived from a composition of four factors:
Vulnerability weight
Each vulnerability class carries an intrinsic severity weight that reflects its typical proximity to data. SQL injection ranks at the top, followed by authentication bypass, insecure direct object reference, server-side request forgery, path traversal, file upload, exposed-secret findings, information disclosure, CORS misconfiguration, and headers/cookies at the bottom.
Target weight
The target endpoint contributes weight independently of the vulnerability. An endpoint matching /api/(users|customers|payments|accounts|transactions) weighs more than an endpoint under /api/admin, which weighs more than a generic API root, which weighs more than a static asset. The target-weighting table is encoded explicitly rather than learned because it has to be auditable.
Proximity weight
Each finding is tagged with a proximity-to-data classification. Direct database findings weigh most. Application API findings weigh next. Infrastructure metadata findings, server-side request forgery into a cloud metadata endpoint, weigh least, even though they can be devastating, because by themselves they are one hop away from data rather than zero hops.
Authentication and reachability multipliers
Endpoints behind authentication receive a boost. The reasoning is that authentication is the gatekeeper that protects real data, so a vulnerability behind authentication is more likely to surface real records than the same vulnerability on an unauthenticated public surface. Hosts that did not respond during recon are heavily discounted, there is no point grinding a finding against an unreachable target.
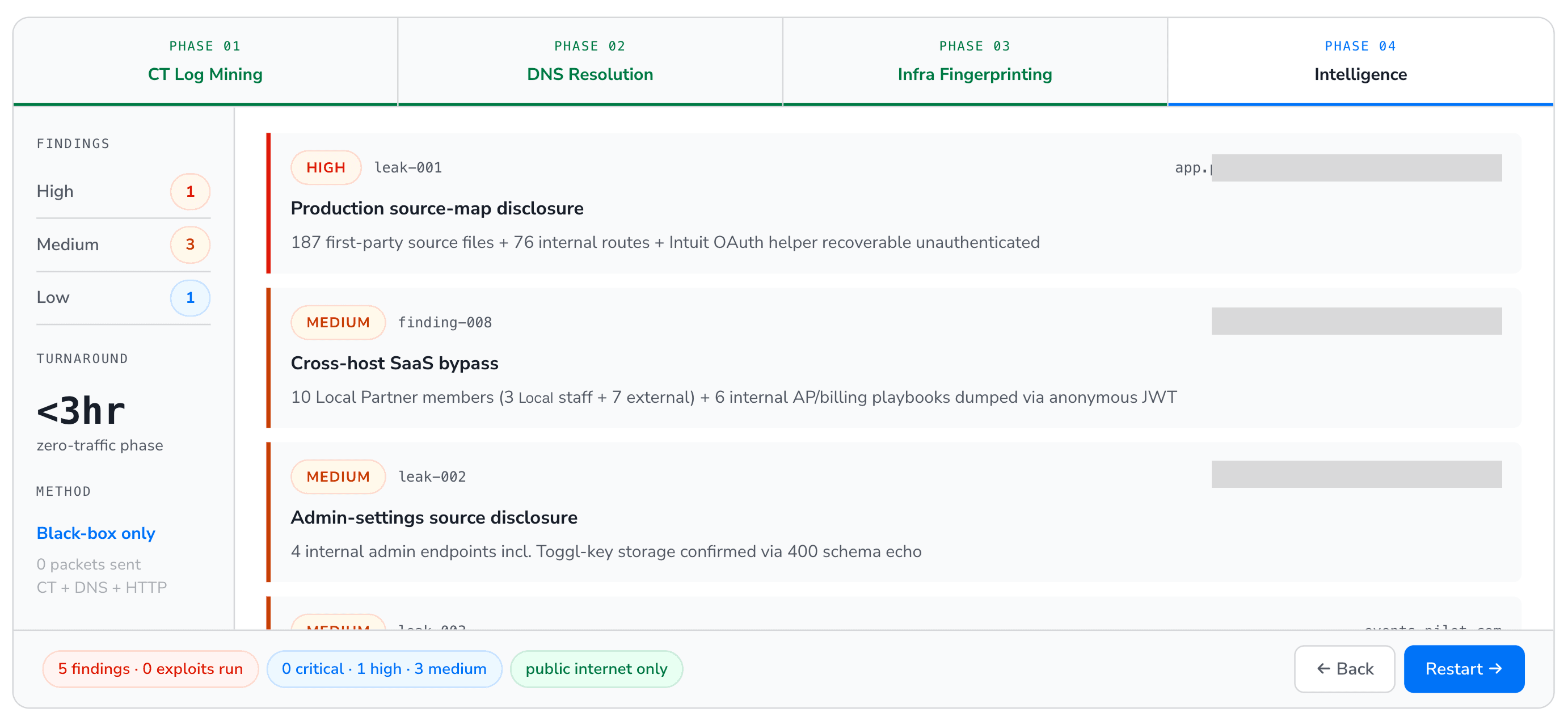
Thresholds and the queue split
Findings are split into two pools by configurable thresholds:
Grind queue: findings above the exploitation threshold; the exploitation phase runs against these.
Deep-dive queue: findings above a (lower) deep-dive threshold; the deep-dive phase runs against these.
Report-only: findings below both thresholds; mentioned in the final report but not extracted.
The deep-dive threshold is intentionally lower than the grind threshold so the deep-dive phase catches findings that the grind queue skipped. This is the system's structural defense against false negatives: a finding can fail the typed-exploitation phase and still get a second pass with a finding-agnostic extraction agent.
Scoring runs on every raw finding before any expensive analysis happens, and it concentrates the expensive analysis on the findings that actually pay off in customer impact. This is what makes a bounded-cost engagement viable.
Phase Five: Typed Exploitation Per Finding
For each finding in the grind queue, an exploitation agent runs with one mandate: confirm the vulnerability and pull initial data. The agent receives a vulnerability-type-specific playbook and the relevant evidence artifacts from prior phases.
Per-class playbooks
The system maintains dedicated exploitation playbooks for each supported vulnerability class. The playbook contains the canonical detection technique set, the canonical exploitation technique set, the canonical initial-extraction approach, and the safe-stop conditions. The supported classes include:
SQL injection: error-based, union-based, boolean-blind, time-based, and second-order; with safe extraction limits and no destructive verbs.
Authentication bypass: JSON Web Token forgery (algorithm-none, HS256-with-RS256-public-key, key-id injection, JSON Web Key injection), session-fixation, missing-middleware exploitation, cookie manipulation.
Insecure direct object reference: horizontal and vertical privilege escalation, identifier rotation, parameter inclusion, GraphQL alias abuse.
Server-side request forgery: cloud metadata harvesting across IMDSv1 and IMDSv2 patterns, internal-service discovery, protocol abuse via
file,gopher,dict,ftp, redirect-based bypasses, DNS-rebinding.Path traversal: UNIX and Windows traversal, encoded variants, null-byte tricks, framework-specific filter bypasses, language wrapper abuse.
File upload: extension manipulation, double-extension tricks, MIME spoofing, magic-byte adjustment, language-handler override, SVG-based cross-site scripting, archive-based path traversal.
Exposed secret: live verification, scope enumeration, secondary endpoint discovery.
Information disclosure: source-map mining, framework-debug abuse, error-message parsing, stack-trace analysis.
CORS misconfiguration: reflected-origin probing, null-origin abuse, credential exposure.
GraphQL: introspection enumeration, alias batching, depth-based denial-of-service avoidance, field suggestion mining.
OAuth and OpenID Connect abuse: Device Flow without verification, dynamic client registration with dangerous redirect URIs, open-redirect via
redirect_uri, audience confusion.
Automatic escalation
When exploitation succeeds, the system automatically escalates to a follow-on extraction step that extends and deepens the initial dump until either a per-finding data ceiling is hit, the point is proven, or the engagement-wide data budget is exhausted. Bytes used are tracked after every extraction; when remaining budget falls below a meaningful threshold, subsequent findings are skipped with a documented marker rather than producing partial garbage.
Hard prohibitions
Every exploitation agent operates under a set of explicit prohibitions encoded at the prompt level:
No destructive operations, no
DROP,DELETE,UPDATE,TRUNCATE,ALTER,CREATE,INSERT.No persistence, no backdoors, no scheduled jobs, no new accounts, no webhook registration.
No lateral movement beyond the documented scope.
No denial-of-service or credential stuffing.
No writing arbitrary files via SQL
INTO OUTFILE, file-upload persistence, or template-injection write primitives.No off-host data egress, every extracted byte stays local to the engagement folder.
These are not soft preferences. They are enforced at the prompt level and reinforced by the orchestrator's tool-call filtering.
Phase Six: Deep-dive Extraction - The Phase That Matters Most
This is the most important phase, and it is the one that justifies the AI pentest label rather than AI scanner. The deep-dive phase is what separates a confirmed vulnerability from a confirmed data leak.
After typed exploitation finishes, a separate finding-agnostic agent runs against every finding that scored above the deep-dive threshold. Its instructions are blunt: extract real data, not metadata. "We confirmed access" is not a leak. "We pulled one hundred and twenty-seven user records with email and phone" is.
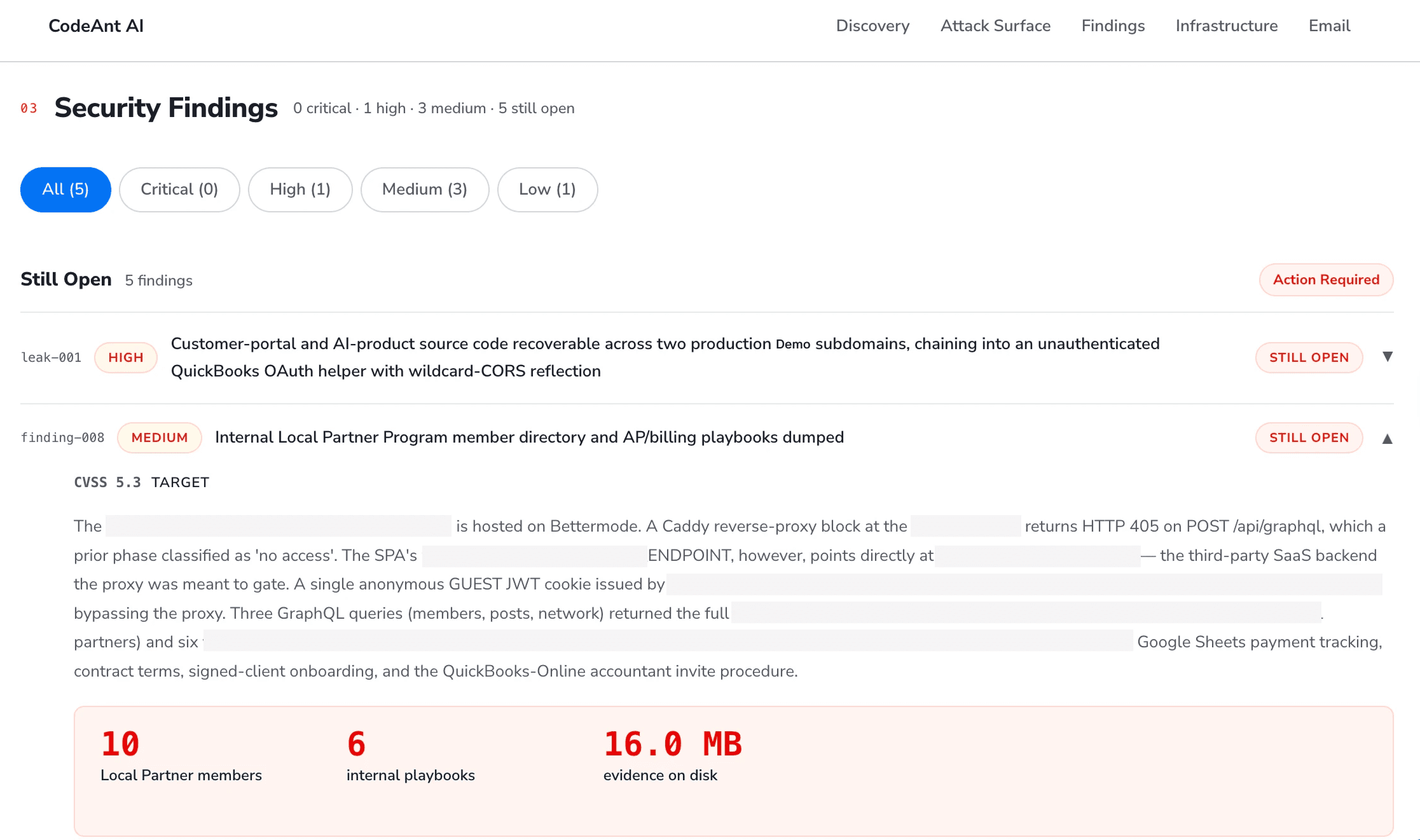
Priority order
The deep-dive agent receives the prior exploitation result as context, what was already tried, what was already pulled, what was already chained, so it does not waste cycles repeating earlier work. Its priority order is explicit:
Chain first. If a prior extraction produced credentials, internal URLs, identifiers, or session tokens, use them to pull data from other findings. The highest-impact data leaks are almost always multi-step chains. A token harvested from a misconfigured JavaScript bundle that unlocks an internal admin API ten redirects away is the kind of evidence that lands engagements.
Gap-fill second. If a prior extraction stopped mid-dump because of a byte cap or a timeout, resume it from where it left off, but only with unique content. The system maintains an extraction index per finding so it does not redundantly re-download the same documentation page six times.
First-pass extraction third. If no prior exploitation ran, typically because the finding entered the queue below the grind threshold but above the deep-dive threshold, execute the type-appropriate playbook from scratch.
Technique budget
The deep-dive agent is allowed to try up to four distinct extraction techniques per finding before giving up. The technique budget is the system's structural defense against early-give-up failure modes. A typed extractor that fails on the first technique gets three more attempts in deep-dive before the finding is marked "no access" with a documented reason.
Data class taxonomy
Every extracted record is classified into a taxonomy that feeds the customer report:
Customer PII: email, phone, full name, address, date of birth, government identifiers.
Credentials: password hashes, API keys, cloud access keys, SSH keys, database connection strings, OAuth client secrets.
Financial records: transactions, invoices, payment methods, balances, tax identifiers.
Health, KYC, AML records: identity verifications, watchlist hits, fraud decisions, compliance audit trails.
Internal business data: administrative panel contents, proprietary source code, internal configurations, database schemas with data, audit logs.
Source code with hardcoded secrets: when source-map artifacts or unstripped bundles reveal private keys, secrets, or internal URLs.
Tenant-isolation violations: proof that one tenant's data is reachable from another tenant's session, the most consequential class of multi-tenant SaaS finding.
Infrastructure topology: DNS misconfigurations, email-security policy gaps, internal hostname disclosure, public-by-design configuration metadata.
Output
The deep-dive phase produces a dedicated data-leaks/ tree containing, for each confirmed leak:
A structured metadata record with vulnerability class, data classes extracted, byte count, and reproduction details.
A runnable reproduction script, a single shell file that the customer's engineering team can re-execute to verify the finding in their own environment.
An
extracted-data/folder with the actual leaked content. Customer PII. Verified credentials. Financial records. KYC trails. Internal configuration. Source files with hardcoded secrets.
The deep-dive phase exists because the line between "vulnerability detected" and "data leak proven" is the line between work the customer is happy to have done and work the customer feels they paid for.
Phase Seven: Synthesis and Internal Reporting
The reporting phase reads the engagement folder as a whole and produces a single internal pentest report. The structure is conventional, executive summary, methodology, findings by severity, attack chains, recommendations, but the source of truth is unconventional: the report draws primarily from the data-leaks/ tree, not from raw vulnerability detection.
Each finding entry contains:
Severity (calibrated against the data classes actually extracted, not the theoretical worst case).
Vulnerability class and affected endpoint.
Reproduction steps with the exact request sequence required.
Sample evidence with appropriate redaction.
Business impact framed against the customer's specific data taxonomy.
Remediation guidance with code-level and configuration-level options.
Severity downgrades are explicit. If a finding looked critical at detection time but the data extracted is public-by-design (a single-page-app OAuth client identifier, for example), the severity is reduced and the reasoning is shown. This is the difference between an honest report and a noisy one.

Phases Eight and Nine: Two PDFs for Two Audiences
The engagement produces two finished PDF deliverables. Both are generated from the same evidence, but they target different points in the customer relationship.
Customer preview PDF
Designed for the pre-contract conversation. Contents:
One high-impact, fully-evidenced data leak with ten to fifteen sample records.
An explicit count of additional findings held back, broken down by severity.
A clear next-step ask, to receive the full report, the engagement must be contracted.
The goal is to make the value of the full engagement concrete without giving away the complete deliverable. The headline leak is selected by a deterministic ranking over the data-leaks/ tree, typically the highest-scoring confirmed leak in the engagement.
Complete internal PDF
The post-contract artifact. Contents:
Every confirmed leak with twenty to forty sample records.
Every detected finding in a structured appendix.
Every extracted file indexed in a second appendix.
Recon intelligence, attack chains, statistics, and remediation guidance.
There is no holdback. The complete PDF is the engagement record the customer's security and engineering teams own from the moment the contract is signed.
Phase Ten: Self-evaluation
The final phase is the pipeline grading itself. A self-evaluation agent reads the entire engagement folder and produces a structured quality score across multiple axes:
Signal-to-noise ratio: confirmed-exploited findings divided by total queue entries.
Surface-finding ratio: findings that are pure surface noise (headers, SSL, cookies, DNS) divided by total findings; lower is better.
Escalation efficiency: findings that escalated from initial exploitation into a multi-step chain.
Time-to-first-critical: wall-clock seconds from engagement start to first confirmed critical extraction.
Tokens-per-critical-finding: token spend divided by confirmed critical extractions; the inverse of cost efficiency.
Evidence quality: proportion of findings that hit their evidence threshold (records, credentials, database content, administrative content, internal data).
Chain depth: maximum number of distinct steps in any confirmed attack chain.
Cross-host replay count: total times a credential or session captured on one host was successfully replayed against a different host.
Budget utilization: bytes extracted divided by engagement byte budget; ideally well under one hundred percent.
Guardrail blocks: count of safety refusals encountered, used to identify prompt-engineering gaps in the operator context.
The result is checked into a long-running evaluation history file so engagement quality can be tracked over time. If a class of finding is being consistently missed, or the cost-per-confirmed-leak drifts in the wrong direction, the history shows it before any customer notices.
This phase is what makes the system improvable rather than merely operational. A pipeline that does not grade itself cannot get measurably better.
What Changes When AI Does the Work
Three things change concretely.
Time
A full engagement that historically took one to four weeks of senior-tester calendar time finishes in roughly thirty to ninety minutes of wall clock. The capacity unlock is roughly two orders of magnitude. That changes what engagement cadence can look like: instead of an annual penetration test scoped against a snapshot of the application from twelve months ago, customers can run a fresh engagement at every release, every major architectural change, or every quarter as a compliance ritual.
Coverage
Because the breadth phases, subdomain enumeration, JavaScript bundle mining, exposed-path probing, route extraction, run in parallel and at machine speed, the surface explored per engagement is substantially larger than a human-led equivalent. The narrow misses that historically only surfaced when a senior tester happened to grep the right bundle now surface as a matter of course.
A typical engagement enumerates between two and five hundred subdomains, probes between fifty and two hundred live hosts, mines between ten and one hundred JavaScript bundles for secrets, probes between two and five hundred exposed-path candidates per host, and extracts between five and forty distinct findings into the typed exploitation phase. These numbers vary with the size of the customer's surface, but the order of magnitude is consistent.
Evidence quality
This is the part that surprises customers most often. The volume of actual extracted data per confirmed finding is higher with the autonomous pipeline than with a typical human engagement, because the agent never gets tired, never gets bored, and never decides that ten records are "probably enough" when twenty would make the case stronger. The byte budget, twenty megabytes per finding, one hundred megabytes per engagement, is the structural reason: it forces the agent to extract aggressively up to the cap, and then stop.
The cost ceiling per engagement is bounded by configuration, and the typical engagement runs well under the cap. That bounded cost, combined with the bounded time, is what makes engagement-as-a-product viable in a way that hourly-billed manual pentesting never was.
What Does Not Change
A few things stay exactly the same as in a traditional engagement, by design:
Authorization is non-negotiable. Every engagement runs against a target that has signed a written Statement of Work granting permission to probe, exploit, and collect proof-of-concept evidence within a documented scope. No SOW, no engagement.
Scope is enforced. Out-of-scope assets are not touched. Credentials harvested from one finding are not pivoted into unrelated infrastructure. Cloud identity-verification calls are limited to read-only "prove the credential is live" operations.
Damage is prohibited. No destructive operations. No persistence. No denial-of-service. No writing arbitrary files. Extracted data stays local to the engagement folder.
Reproduction is required. Every confirmed finding ships with a runnable reproduction so the customer's team can verify the finding in their own environment.
Rate limits are respected. Two requests per second for data extraction, one per second for sensitive operations.
Refusals are logged. When an upstream safety layer blocks a specific payload, the refusal is logged with the exact message and the next planned step is executed. The system does not loop, does not argue with guardrails, does not degrade into generic security advice. Logged refusals feed prompt engineering improvements between engagements.
The result is an engagement that is faster, broader, and deeper than a traditional pentest while preserving the exact contractual, ethical, and operational guardrails customers expect.
Closing: One Surface, Watched Continuously, Proven on Demand
Autonomous AI penetration testing is not a future capability. It is a delivered methodology that ships engagements in roughly thirty to ninety minutes of wall-clock time, produces extracted-data evidence rather than theoretical findings, and operates under the same contractual and ethical guardrails as a traditional engagement.
The architectural ideas that make it work, one objective per agent, structured artifacts on disk between phases, deterministic scoring before expensive analysis, a finding-agnostic deep-dive phase that extracts real data rather than confirming vulnerability, and a self-evaluation phase that grades the pipeline against measurable axes, are the technical foundation under the phrase AI pentesting.
The result is engagement-as-a-product: bounded time, bounded cost, evidence-grade output, run as often as the customer's release cadence requires. That is the shift the live demo was built to make visible.
Try our Autonomous Offensive Security Platform. 500+ agentic pentest agents. Black box, white box, gray box. Get a working exploit or you pay nothing.
FAQs
What happens if a phase fails while performing pentesting via CodeAnt penetration tool?
How does scoring avoid bias with CodeAnt AI pentesting tool?
What kinds of vulnerabilities are out of scope?
How frequently can engagements be run via your pentesting tool?
How does your pentesting system handle false positives?













